 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssociative Adversarial Learning Based on Selective Attack
Jan 04, 2022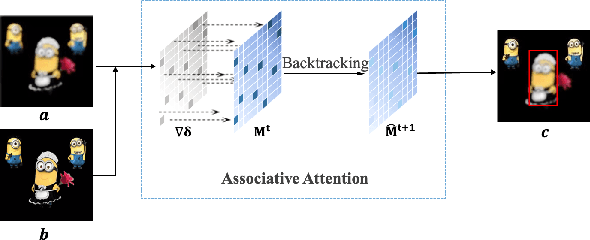
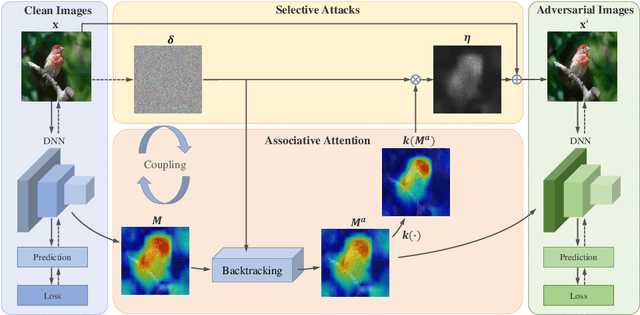
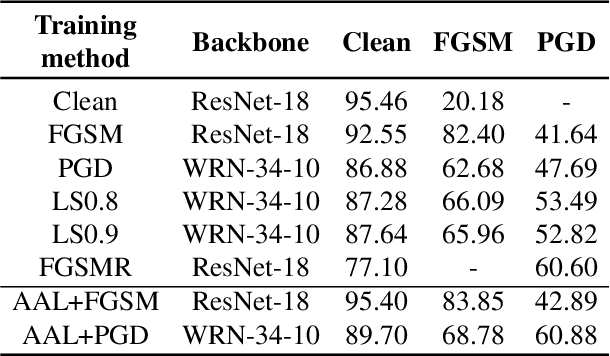
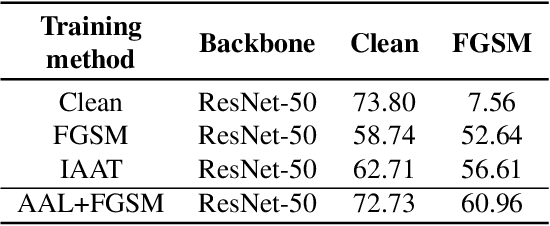
A human's attention can intuitively adapt to corrupted areas of an image by recalling a similar uncorrupted image they have previously seen. This observation motivates us to improve the attention of adversarial images by considering their clean counterparts. To accomplish this, we introduce Associative Adversarial Learning (AAL) into adversarial learning to guide a selective attack. We formulate the intrinsic relationship between attention and attack (perturbation) as a coupling optimization problem to improve their interaction. This leads to an attention backtracking algorithm that can effectively enhance the attention's adversarial robustness. Our method is generic and can be used to address a variety of tasks by simply choosing different kernels for the associative attention that select other regions for a specific attack. Experimental results show that the selective attack improves the model's performance. We show that our method improves the recognition accuracy of adversarial training on ImageNet by 8.32% compared with the baseline. It also increases object detection mAP on PascalVOC by 2.02% and recognition accuracy of few-shot learning on miniImageNet by 1.63%.
Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention
Dec 28, 2021



Recently, Transformers have shown promising performance in various vision tasks. To reduce the quadratic computation complexity caused by the global self-attention, various methods constrain the range of attention within a local region to improve its efficiency. Consequently, their receptive fields in a single attention layer are not large enough, resulting in insufficient context modeling. To address this issue, we propose a Pale-Shaped self-Attention (PS-Attention), which performs self-attention within a pale-shaped region. Compared to the global self-attention, PS-Attention can reduce the computation and memory costs significantly. Meanwhile, it can capture richer contextual information under the similar computation complexity with previous local self-attention mechanisms. Based on the PS-Attention, we develop a general Vision Transformer backbone with a hierarchical architecture, named Pale Transformer, which achieves 83.4%, 84.3%, and 84.9% Top-1 accuracy with the model size of 22M, 48M, and 85M respectively for 224 ImageNet-1K classification, outperforming the previous Vision Transformer backbones. For downstream tasks, our Pale Transformer backbone performs better than the recent state-of-the-art CSWin Transformer by a large margin on ADE20K semantic segmentation and COCO object detection & instance segmentation. The code will be released on https://github.com/BR-IDL/PaddleViT.
POEM: 1-bit Point-wise Operations based on Expectation-Maximization for Efficient Point Cloud Processing
Nov 26, 2021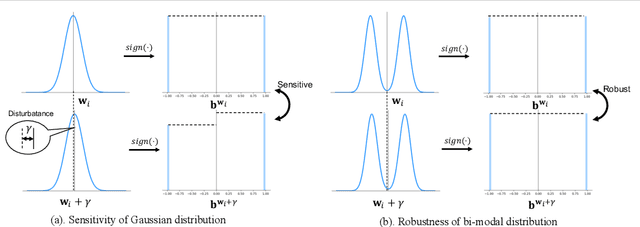
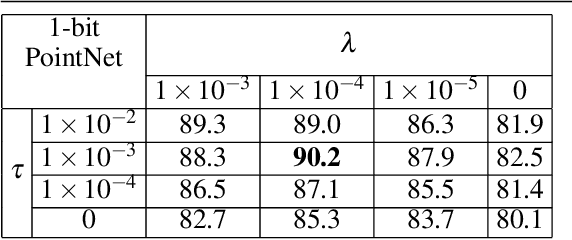
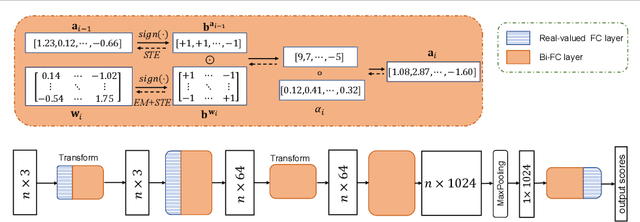

Real-time point cloud processing is fundamental for lots of computer vision tasks, while still challenged by the computational problem on resource-limited edge devices. To address this issue, we implement XNOR-Net-based binary neural networks (BNNs) for an efficient point cloud processing, but its performance is severely suffered due to two main drawbacks, Gaussian-distributed weights and non-learnable scale factor. In this paper, we introduce point-wise operations based on Expectation-Maximization (POEM) into BNNs for efficient point cloud processing. The EM algorithm can efficiently constrain weights for a robust bi-modal distribution. We lead a well-designed reconstruction loss to calculate learnable scale factors to enhance the representation capacity of 1-bit fully-connected (Bi-FC) layers. Extensive experiments demonstrate that our POEM surpasses existing the state-of-the-art binary point cloud networks by a significant margin, up to 6.7 %.
LAE : Long-tailed Age Estimation
Oct 25, 2021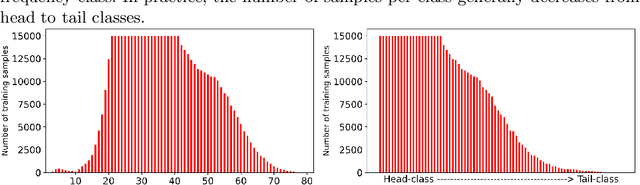


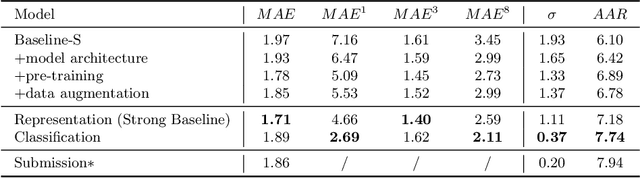
Facial age estimation is an important yet very challenging problem in computer vision. To improve the performance of facial age estimation, we first formulate a simple standard baseline and build a much strong one by collecting the tricks in pre-training, data augmentation, model architecture, and so on. Compared with the standard baseline, the proposed one significantly decreases the estimation errors. Moreover, long-tailed recognition has been an important topic in facial age datasets, where the samples often lack on the elderly and children. To train a balanced age estimator, we propose a two-stage training method named Long-tailed Age Estimation (LAE), which decouples the learning procedure into representation learning and classification. The effectiveness of our approach has been demonstrated on the dataset provided by organizers of Guess The Age Contest 2021.
Sparse to Dense Motion Transfer for Face Image Animation
Sep 03, 2021


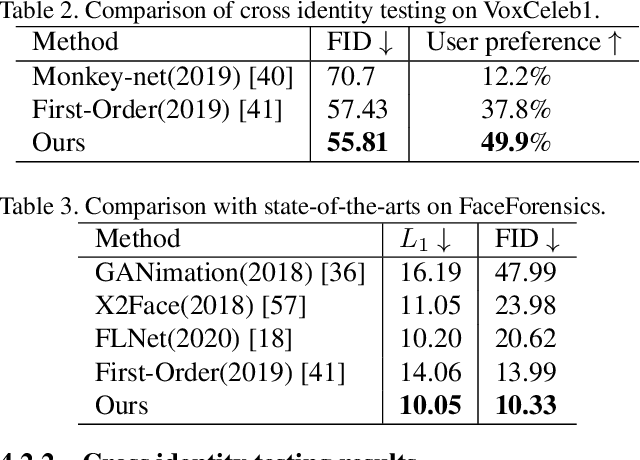
Face image animation from a single image has achieved remarkable progress. However, it remains challenging when only sparse landmarks are available as the driving signal. Given a source face image and a sequence of sparse face landmarks, our goal is to generate a video of the face imitating the motion of landmarks. We develop an efficient and effective method for motion transfer from sparse landmarks to the face image. We then combine global and local motion estimation in a unified model to faithfully transfer the motion. The model can learn to segment the moving foreground from the background and generate not only global motion, such as rotation and translation of the face, but also subtle local motion such as the gaze change. We further improve face landmark detection on videos. With temporally better aligned landmark sequences for training, our method can generate temporally coherent videos with higher visual quality. Experiments suggest we achieve results comparable to the state-of-the-art image driven method on the same identity testing and better results on cross identity testing.
TransFER: Learning Relation-aware Facial Expression Representations with Transformers
Aug 25, 2021
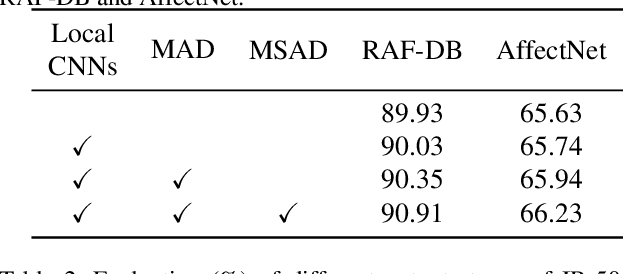
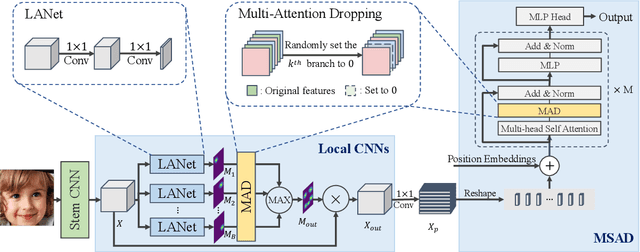

Facial expression recognition (FER) has received increasing interest in computer vision. We propose the TransFER model which can learn rich relation-aware local representations. It mainly consists of three components: Multi-Attention Dropping (MAD), ViT-FER, and Multi-head Self-Attention Dropping (MSAD). First, local patches play an important role in distinguishing various expressions, however, few existing works can locate discriminative and diverse local patches. This can cause serious problems when some patches are invisible due to pose variations or viewpoint changes. To address this issue, the MAD is proposed to randomly drop an attention map. Consequently, models are pushed to explore diverse local patches adaptively. Second, to build rich relations between different local patches, the Vision Transformers (ViT) are used in FER, called ViT-FER. Since the global scope is used to reinforce each local patch, a better representation is obtained to boost the FER performance. Thirdly, the multi-head self-attention allows ViT to jointly attend to features from different information subspaces at different positions. Given no explicit guidance, however, multiple self-attentions may extract similar relations. To address this, the MSAD is proposed to randomly drop one self-attention module. As a result, models are forced to learn rich relations among diverse local patches. Our proposed TransFER model outperforms the state-of-the-art methods on several FER benchmarks, showing its effectiveness and usefulness.
The 2nd Anti-UAV Workshop & Challenge: Methods and Results
Aug 25, 2021

The 2nd Anti-UAV Workshop \& Challenge aims to encourage research in developing novel and accurate methods for multi-scale object tracking. The Anti-UAV dataset used for the Anti-UAV Challenge has been publicly released. There are two subsets in the dataset, $i.e.$, the test-dev subset and test-challenge subset. Both subsets consist of 140 thermal infrared video sequences, spanning multiple occurrences of multi-scale UAVs. Around 24 participating teams from the globe competed in the 2nd Anti-UAV Challenge. In this paper, we provide a brief summary of the 2nd Anti-UAV Workshop \& Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that are interested in the Anti-UAV challenge. The benchmark dataset and other information can be found at: https://anti-uav.github.io/.
Self-Conditioned Probabilistic Learning of Video Rescaling
Aug 18, 2021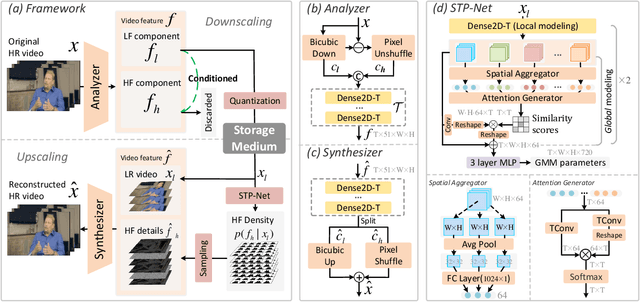
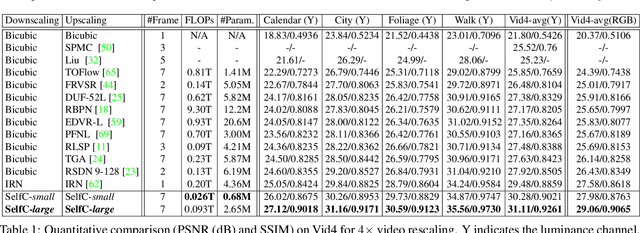
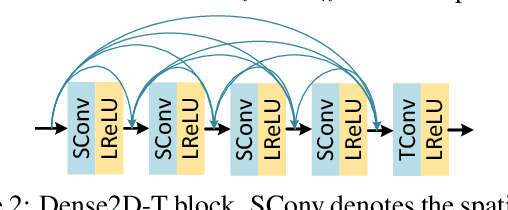

Bicubic downscaling is a prevalent technique used to reduce the video storage burden or to accelerate the downstream processing speed. However, the inverse upscaling step is non-trivial, and the downscaled video may also deteriorate the performance of downstream tasks. In this paper, we propose a self-conditioned probabilistic framework for video rescaling to learn the paired downscaling and upscaling procedures simultaneously. During the training, we decrease the entropy of the information lost in the downscaling by maximizing its probability conditioned on the strong spatial-temporal prior information within the downscaled video. After optimization, the downscaled video by our framework preserves more meaningful information, which is beneficial for both the upscaling step and the downstream tasks, e.g., video action recognition task. We further extend the framework to a lossy video compression system, in which a gradient estimator for non-differential industrial lossy codecs is proposed for the end-to-end training of the whole system. Extensive experimental results demonstrate the superiority of our approach on video rescaling, video compression, and efficient action recognition tasks.
3D High-Fidelity Mask Face Presentation Attack Detection Challenge
Aug 16, 2021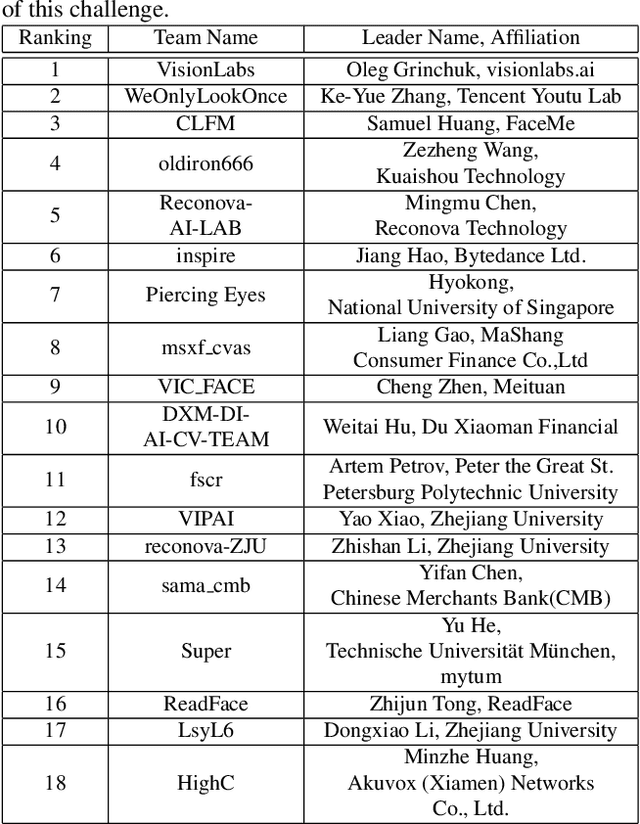
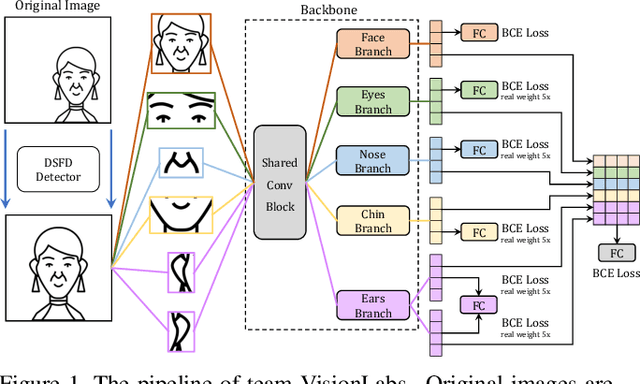
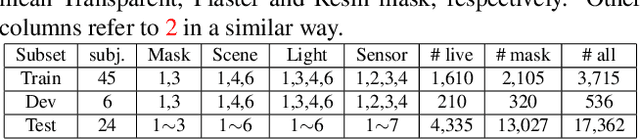
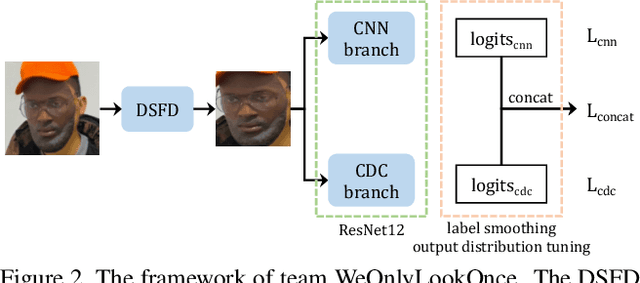
The threat of 3D masks to face recognition systems is increasingly serious and has been widely concerned by researchers. To facilitate the study of the algorithms, a large-scale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask) has been collected. Specifically, it consists of a total amount of 54, 600 videos which are recorded from 75 subjects with 225 realistic masks under 7 new kinds of sensors. Based on this dataset and Protocol 3 which evaluates both the discrimination and generalization ability of the algorithm under the open set scenarios, we organized a 3D High-Fidelity Mask Face Presentation Attack Detection Challenge to boost the research of 3D mask-based attack detection. It attracted 195 teams for the development phase with a total of 18 teams qualifying for the final round. All the results were verified and re-run by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including the introduction of the dataset used, the definition of the protocol, the calculation of the evaluation criteria, and the summary and publication of the competition results. Finally, we focus on introducing and analyzing the top ranking algorithms, the conclusion summary, and the research ideas for mask attack detection provided by this competition.
EAN: Event Adaptive Network for Enhanced Action Recognition
Jul 22, 2021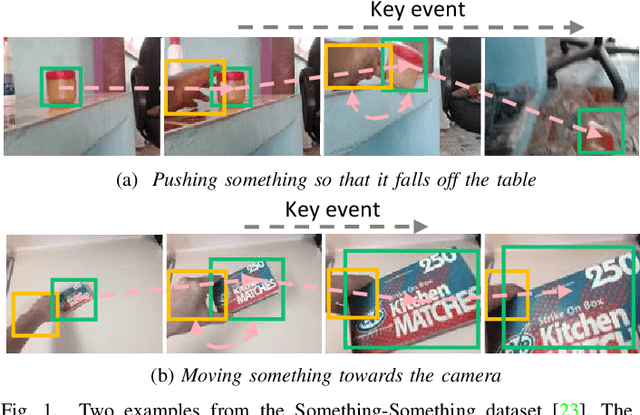
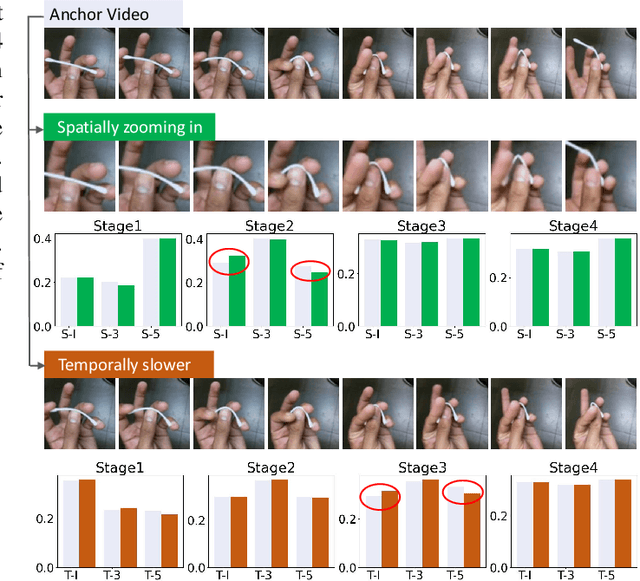
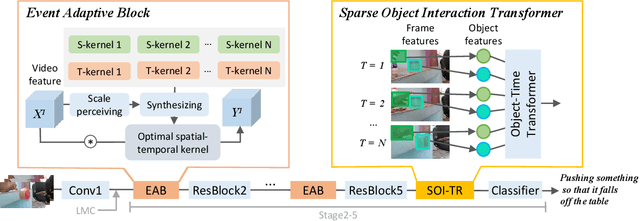
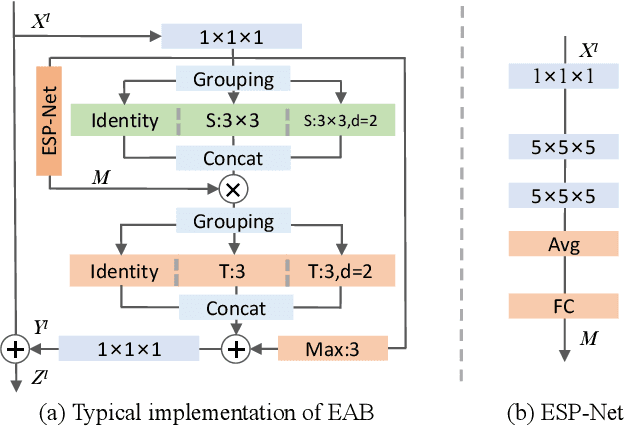
Efficiently modeling spatial-temporal information in videos is crucial for action recognition. To achieve this goal, state-of-the-art methods typically employ the convolution operator and the dense interaction modules such as non-local blocks. However, these methods cannot accurately fit the diverse events in videos. On the one hand, the adopted convolutions are with fixed scales, thus struggling with events of various scales. On the other hand, the dense interaction modeling paradigm only achieves sub-optimal performance as action-irrelevant parts bring additional noises for the final prediction. In this paper, we propose a unified action recognition framework to investigate the dynamic nature of video content by introducing the following designs. First, when extracting local cues, we generate the spatial-temporal kernels of dynamic-scale to adaptively fit the diverse events. Second, to accurately aggregate these cues into a global video representation, we propose to mine the interactions only among a few selected foreground objects by a Transformer, which yields a sparse paradigm. We call the proposed framework as Event Adaptive Network (EAN) because both key designs are adaptive to the input video content. To exploit the short-term motions within local segments, we propose a novel and efficient Latent Motion Code (LMC) module, further improving the performance of the framework. Extensive experiments on several large-scale video datasets, e.g., Something-to-Something V1&V2, Kinetics, and Diving48, verify that our models achieve state-of-the-art or competitive performances at low FLOPs. Codes are available at: https://github.com/tianyuan168326/EAN-Pytorch.