 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre the Latent Representations of Foundation Models for Pathology Invariant to Rotation?
Dec 16, 2024Self-supervised foundation models for digital pathology encode small patches from H\&E whole slide images into latent representations used for downstream tasks. However, the invariance of these representations to patch rotation remains unexplored. This study investigates the rotational invariance of latent representations across twelve foundation models by quantifying the alignment between non-rotated and rotated patches using mutual $k$-nearest neighbours and cosine distance. Models that incorporated rotation augmentation during self-supervised training exhibited significantly greater invariance to rotations. We hypothesise that the absence of rotational inductive bias in the transformer architecture necessitates rotation augmentation during training to achieve learned invariance. Code: https://github.com/MatousE/rot-invariance-analysis.
LAION-SG: An Enhanced Large-Scale Dataset for Training Complex Image-Text Models with Structural Annotations
Dec 11, 2024



Recent advances in text-to-image (T2I) generation have shown remarkable success in producing high-quality images from text. However, existing T2I models show decayed performance in compositional image generation involving multiple objects and intricate relationships. We attribute this problem to limitations in existing datasets of image-text pairs, which lack precise inter-object relationship annotations with prompts only. To address this problem, we construct LAION-SG, a large-scale dataset with high-quality structural annotations of scene graphs (SG), which precisely describe attributes and relationships of multiple objects, effectively representing the semantic structure in complex scenes. Based on LAION-SG, we train a new foundation model SDXL-SG to incorporate structural annotation information into the generation process. Extensive experiments show advanced models trained on our LAION-SG boast significant performance improvements in complex scene generation over models on existing datasets. We also introduce CompSG-Bench, a benchmark that evaluates models on compositional image generation, establishing a new standard for this domain.
Anatomy-Guided Radiology Report Generation with Pathology-Aware Regional Prompts
Nov 16, 2024



Radiology reporting generative AI holds significant potential to alleviate clinical workloads and streamline medical care. However, achieving high clinical accuracy is challenging, as radiological images often feature subtle lesions and intricate structures. Existing systems often fall short, largely due to their reliance on fixed size, patch-level image features and insufficient incorporation of pathological information. This can result in the neglect of such subtle patterns and inconsistent descriptions of crucial pathologies. To address these challenges, we propose an innovative approach that leverages pathology-aware regional prompts to explicitly integrate anatomical and pathological information of various scales, significantly enhancing the precision and clinical relevance of generated reports. We develop an anatomical region detector that extracts features from distinct anatomical areas, coupled with a novel multi-label lesion detector that identifies global pathologies. Our approach emulates the diagnostic process of radiologists, producing clinically accurate reports with comprehensive diagnostic capabilities. Experimental results show that our model outperforms previous state-of-the-art methods on most natural language generation and clinical efficacy metrics, with formal expert evaluations affirming its potential to enhance radiology practice.
Decoding Report Generators: A Cyclic Vision-Language Adapter for Counterfactual Explanations
Nov 08, 2024



Despite significant advancements in report generation methods, a critical limitation remains: the lack of interpretability in the generated text. This paper introduces an innovative approach to enhance the explainability of text generated by report generation models. Our method employs cyclic text manipulation and visual comparison to identify and elucidate the features in the original content that influence the generated text. By manipulating the generated reports and producing corresponding images, we create a comparative framework that highlights key attributes and their impact on the text generation process. This approach not only identifies the image features aligned to the generated text but also improves transparency but also provides deeper insights into the decision-making mechanisms of the report generation models. Our findings demonstrate the potential of this method to significantly enhance the interpretability and transparency of AI-generated reports.
Deep Generative Models Unveil Patterns in Medical Images Through Vision-Language Conditioning
Oct 17, 2024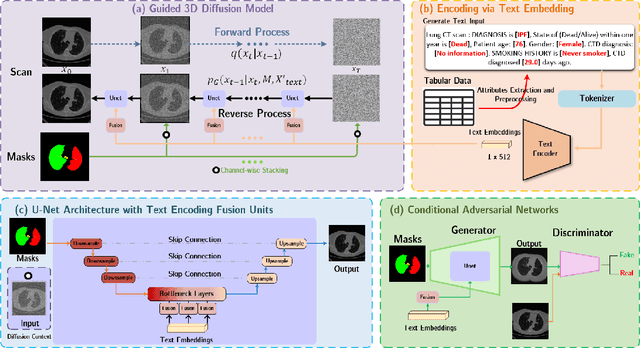

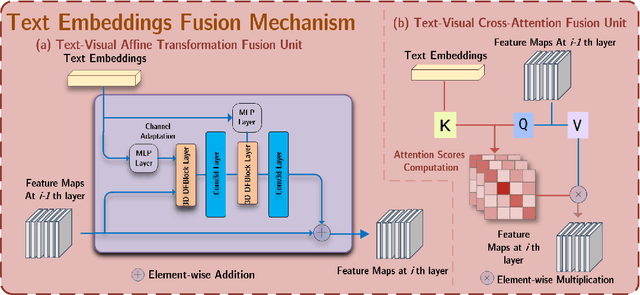
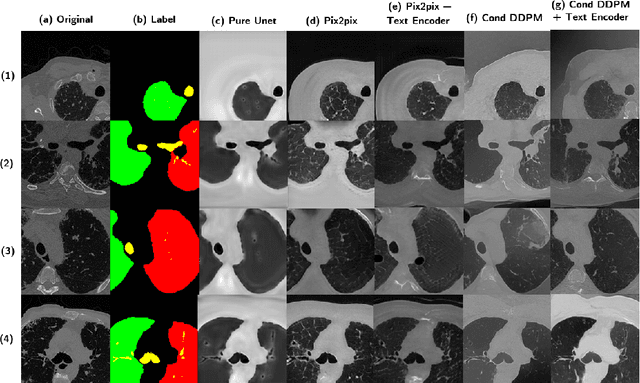
Deep generative models have significantly advanced medical imaging analysis by enhancing dataset size and quality. Beyond mere data augmentation, our research in this paper highlights an additional, significant capacity of deep generative models: their ability to reveal and demonstrate patterns in medical images. We employ a generative structure with hybrid conditions, combining clinical data and segmentation masks to guide the image synthesis process. Furthermore, we innovatively transformed the tabular clinical data into textual descriptions. This approach simplifies the handling of missing values and also enables us to leverage large pre-trained vision-language models that investigate the relations between independent clinical entries and comprehend general terms, such as gender and smoking status. Our approach differs from and presents a more challenging task than traditional medical report-guided synthesis due to the less visual correlation of our clinical information with the images. To overcome this, we introduce a text-visual embedding mechanism that strengthens the conditions, ensuring the network effectively utilizes the provided information. Our pipeline is generalizable to both GAN-based and diffusion models. Experiments on chest CT, particularly focusing on the smoking status, demonstrated a consistent intensity shift in the lungs which is in agreement with clinical observations, indicating the effectiveness of our method in capturing and visualizing the impact of specific attributes on medical image patterns. Our methods offer a new avenue for the early detection and precise visualization of complex clinical conditions with deep generative models. All codes are https://github.com/junzhin/DGM-VLC.
Arbitrarily-Conditioned Multi-Functional Diffusion for Multi-Physics Emulation
Oct 17, 2024Modern physics simulation often involves multiple functions of interests, and traditional numerical approaches are known to be complex and computationally costly. While machine learning-based surrogate models can offer significant cost reductions, most focus on a single task, such as forward prediction, and typically lack uncertainty quantification -- an essential component in many applications. To overcome these limitations, we propose Arbitrarily-Conditioned Multi-Functional Diffusion (ACMFD), a versatile probabilistic surrogate model for multi-physics emulation. ACMFD can perform a wide range of tasks within a single framework, including forward prediction, various inverse problems, and simulating data for entire systems or subsets of quantities conditioned on others. Specifically, we extend the standard Denoising Diffusion Probabilistic Model (DDPM) for multi-functional generation by modeling noise as Gaussian processes (GP). We then introduce an innovative denoising loss. The training involves randomly sampling the conditioned part and fitting the corresponding predicted noise to zero, enabling ACMFD to flexibly generate function values conditioned on any other functions or quantities. To enable efficient training and sampling, and to flexibly handle irregularly sampled data, we use GPs to interpolate function samples onto a grid, inducing a Kronecker product structure for efficient computation. We demonstrate the advantages of ACMFD across several fundamental multi-physics systems.
Toward Efficient Kernel-Based Solvers for Nonlinear PDEs
Oct 15, 2024This paper introduces a novel kernel learning framework toward efficiently solving nonlinear partial differential equations (PDEs). In contrast to the state-of-the-art kernel solver that embeds differential operators within kernels, posing challenges with a large number of collocation points, our approach eliminates these operators from the kernel. We model the solution using a standard kernel interpolation form and differentiate the interpolant to compute the derivatives. Our framework obviates the need for complex Gram matrix construction between solutions and their derivatives, allowing for a straightforward implementation and scalable computation. As an instance, we allocate the collocation points on a grid and adopt a product kernel, which yields a Kronecker product structure in the interpolation. This structure enables us to avoid computing the full Gram matrix, reducing costs and scaling efficiently to a large number of collocation points. We provide a proof of the convergence and rate analysis of our method under appropriate regularity assumptions. In numerical experiments, we demonstrate the advantages of our method in solving several benchmark PDEs.
Mamba Neural Operator: Who Wins? Transformers vs. State-Space Models for PDEs
Oct 03, 2024



Partial differential equations (PDEs) are widely used to model complex physical systems, but solving them efficiently remains a significant challenge. Recently, Transformers have emerged as the preferred architecture for PDEs due to their ability to capture intricate dependencies. However, they struggle with representing continuous dynamics and long-range interactions. To overcome these limitations, we introduce the Mamba Neural Operator (MNO), a novel framework that enhances neural operator-based techniques for solving PDEs. MNO establishes a formal theoretical connection between structured state-space models (SSMs) and neural operators, offering a unified structure that can adapt to diverse architectures, including Transformer-based models. By leveraging the structured design of SSMs, MNO captures long-range dependencies and continuous dynamics more effectively than traditional Transformers. Through extensive analysis, we show that MNO significantly boosts the expressive power and accuracy of neural operators, making it not just a complement but a superior framework for PDE-related tasks, bridging the gap between efficient representation and accurate solution approximation.
From Challenges and Pitfalls to Recommendations and Opportunities: Implementing Federated Learning in Healthcare
Sep 15, 2024



Federated learning holds great potential for enabling large-scale healthcare research and collaboration across multiple centres while ensuring data privacy and security are not compromised. Although numerous recent studies suggest or utilize federated learning based methods in healthcare, it remains unclear which ones have potential clinical utility. This review paper considers and analyzes the most recent studies up to May 2024 that describe federated learning based methods in healthcare. After a thorough review, we find that the vast majority are not appropriate for clinical use due to their methodological flaws and/or underlying biases which include but are not limited to privacy concerns, generalization issues, and communication costs. As a result, the effectiveness of federated learning in healthcare is significantly compromised. To overcome these challenges, we provide recommendations and promising opportunities that might be implemented to resolve these problems and improve the quality of model development in federated learning with healthcare.
Serp-Mamba: Advancing High-Resolution Retinal Vessel Segmentation with Selective State-Space Model
Sep 06, 2024



Ultra-Wide-Field Scanning Laser Ophthalmoscopy (UWF-SLO) images capture high-resolution views of the retina with typically 200 spanning degrees. Accurate segmentation of vessels in UWF-SLO images is essential for detecting and diagnosing fundus disease. Recent studies have revealed that the selective State Space Model (SSM) in Mamba performs well in modeling long-range dependencies, which is crucial for capturing the continuity of elongated vessel structures. Inspired by this, we propose the first Serpentine Mamba (Serp-Mamba) network to address this challenging task. Specifically, we recognize the intricate, varied, and delicate nature of the tubular structure of vessels. Furthermore, the high-resolution of UWF-SLO images exacerbates the imbalance between the vessel and background categories. Based on the above observations, we first devise a Serpentine Interwoven Adaptive (SIA) scan mechanism, which scans UWF-SLO images along curved vessel structures in a snake-like crawling manner. This approach, consistent with vascular texture transformations, ensures the effective and continuous capture of curved vascular structure features. Second, we propose an Ambiguity-Driven Dual Recalibration (ADDR) module to address the category imbalance problem intensified by high-resolution images. Our ADDR module delineates pixels by two learnable thresholds and refines ambiguous pixels through a dual-driven strategy, thereby accurately distinguishing vessels and background regions. Experiment results on three datasets demonstrate the superior performance of our Serp-Mamba on high-resolution vessel segmentation. We also conduct a series of ablation studies to verify the impact of our designs. Our code shall be released upon publication of this work.