 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-Grained and Verifiable Concept Bottleneck Models
May 14, 2026Concept Bottleneck Models (CBMs) offer interpretable alternatives to black-box predictors by introducing human-relatable concepts before the final output. However, existing CBMs struggle to verify whether predicted concepts correspond to the correct visual evidence, limiting their reliability. We propose a fine-grained CBM framework that grounds each concept in localized visual evidence, enabling direct inspection of where and how concepts are encoded. This design allows users to interpret predictions and verify that the model learns intended concepts rather than spurious correlations. Experiments on medical imaging benchmarks show that our learned concept space is information-complete and achieves predictive performance comparable to standard CBMs, while substantially improving transparency. Unlike post-hoc attribution methods, our framework validates both the presence and correctness of concept representations, bridging interpretability with verifiability. Our approach enhances the trustworthiness of CBMs and establishes a principled mechanism for human-model interaction at the concept level, paving the way toward more reliable and clinically actionable concept-based learning systems.
Seeing Through Experts Eyes A Foundational Vision Language Model Trained on Radiologists Gaze and Reasoning
Apr 15, 2026Large scale vision language models have shown promise in automating chest Xray interpretation, yet their clinical utility remains limited by a gap between model outputs and radiologist reasoning. Most systems optimize for semantic information without emulating how experts visually examine medical images, often overlooking critical findings or diverging from established diagnostic workflows. Radiologists follow structured protocols (e.g., the ABCDEF approach) that ensure all clinically relevant regions are systematically examined, reducing missed findings and supporting reliable diagnostic reasoning. We introduce GazeX, a vision language model that leverages radiologists' eye tracking data as a behavioral prior to model expert diagnostic reasoning. By incorporating gaze trajectories and fixation patterns into pretraining, GazeX learns to follow the spatial and temporal structure of radiologist attention and integrates observations in a clinically meaningful sequence. Using a curated dataset of over 30,000 gaze key frames from five radiologists, we demonstrate that GazeX produces more accurate, interpretable, and expert consistent outputs across radiology report generation, disease grounding, and visual question answering, utilizing 231,835 radiographic studies, 780,014 question answer pairs, and 1,162 image sentence pairs with bounding boxes. Unlike autonomous reporting systems, GazeX produces verifiable evidence artifacts, including inspection trajectories and finding linked localized regions, enabling efficient human verification and safe human AI collaboration. Learning through expert eyes provides a practical route toward more trustworthy, explainable, and diagnostically robust AI systems for radiology and beyond.
MMRareBench: A Rare-Disease Multimodal and Multi-Image Medical Benchmark
Apr 12, 2026Multimodal large language models (MLLMs) have advanced clinical tasks for common conditions, but their performance on rare diseases remains largely untested. In rare-disease scenarios, clinicians often lack prior clinical knowledge, forcing them to rely strictly on case-level evidence for clinical judgments. Existing benchmarks predominantly evaluate common-condition, single-image settings, leaving multimodal and multi-image evidence integration under rare-disease data scarcity systematically unevaluated. We introduce MMRareBench, to our knowledge the first rare-disease benchmark jointly evaluating multimodal and multi-image clinical capability across four workflow-aligned tracks: diagnosis, treatment planning, cross-image evidence alignment, and examination suggestion. The benchmark comprises 1,756 question-answer pairs with 7,958 associated medical images curated from PMC case reports, with Orphanet-anchored ontology alignment, track-specific leakage control, evidence-grounded annotations, and a two-level evaluation protocol. A systematic evaluation of 23 MLLMs reveals fragmented capability profiles and universally low treatment-planning performance, with medical-domain models trailing general-purpose MLLMs substantially on multi-image tracks despite competitive diagnostic scores. These patterns are consistent with a capacity dilution effect: medical fine-tuning can narrow the diagnostic gap but may erode the compositional multi-image capability that rare-disease evidence integration demands.
Learning Robust Visual Features in Computed Tomography Enables Efficient Transfer Learning for Clinical Tasks
Apr 05, 2026There is substantial interest in developing artificial intelligence systems to support radiologists across tasks ranging from segmentation to report generation. Existing computed tomography (CT) foundation models have largely focused on building generalist vision-language systems capable of tasks such as question answering and report generation. However, training reliable vision-language systems requires paired image-text data at a scale that remains unavailable in CT. Moreover, adapting the underlying visual representations to downstream tasks typically requires partial or full backbone fine-tuning, a computationally demanding process inaccessible to many research groups. Instead, foundation models should prioritise learning robust visual representations that enable efficient transfer to new tasks with minimal labelled data and without backbone fine-tuning. We present VoxelFM, a 3D CT foundation model trained with self-distillation using the DINO framework, which learns semantically rich features without language supervision. We evaluated VoxelFM across seven categories of clinically relevant downstream tasks using frozen backbone representations with lightweight probes: classification, regression, survival analysis, instance retrieval, localisation, segmentation, and report generation. VoxelFM matched or outperformed four existing CT foundation models across all task categories. Despite receiving no language supervision during pre-training, VoxelFM surpassed models explicitly trained with language-alignment objectives, including on report generation. Our results indicate that current CT foundation models perform significantly better as feature extractors for lightweight probes rather than as vision encoders for vision-language models. Model weights and training code are publicly available.
Unleashing Video Language Models for Fine-grained HRCT Report Generation
Mar 12, 2026Generating precise diagnostic reports from High-Resolution Computed Tomography (HRCT) is critical for clinical workflow, yet it remains a formidable challenge due to the high pathological diversity and spatial sparsity within 3D volumes. While Video Language Models (VideoLMs) have demonstrated remarkable spatio-temporal reasoning in general domains, their adaptability to domain-specific, high-volume medical interpretation remains underexplored. In this work, we present AbSteering, an abnormality-centric framework that steers VideoLMs toward precise HRCT report generation. Specifically, AbSteering introduces: (i) an abnormality-centric Chain-of-Thought scheme that enforces abnormality reasoning, and (ii) a Direct Preference Optimization objective that utilizes clinically confusable abnormalities as hard negatives to enhance fine-grained discrimination. Our results demonstrate that general-purpose VideoLMs possess strong transferability to high-volume medical imaging when guided by this paradigm. Notably, AbSteering outperforms state-of-the-art domain-specific CT foundation models, which are pretrained with large-scale CTs, achieving superior detection sensitivity while simultaneously mitigating hallucinations. Our data and model weights are released at https://anonymous.4open.science/r/hrct-report-generation-video-vlm-728C/
Reason Like a Radiologist: Chain-of-Thought and Reinforcement Learning for Verifiable Report Generation
Apr 25, 2025Radiology report generation is critical for efficiency but current models lack the structured reasoning of experts, hindering clinical trust and explainability by failing to link visual findings to precise anatomical locations. This paper introduces BoxMed-RL, a groundbreaking unified training framework for generating spatially verifiable and explainable radiology reports. Built on a large vision-language model, BoxMed-RL revolutionizes report generation through two integrated phases: (1) In the Pretraining Phase, we refine the model via medical concept learning, using Chain-of-Thought supervision to internalize the radiologist-like workflow, followed by spatially verifiable reinforcement, which applies reinforcement learning to align medical findings with bounding boxes. (2) In the Downstream Adapter Phase, we freeze the pretrained weights and train a downstream adapter to ensure fluent and clinically credible reports. This framework precisely mimics radiologists' workflow, compelling the model to connect high-level medical concepts with definitive anatomical evidence. Extensive experiments on public datasets demonstrate that BoxMed-RL achieves an average 7% improvement in both METEOR and ROUGE-L metrics compared to state-of-the-art methods. An average 5% improvement in large language model-based metrics further underscores BoxMed-RL's robustness in generating high-quality radiology reports.
Unpaired Translation of Chest X-ray Images for Lung Opacity Diagnosis via Adaptive Activation Masks and Cross-Domain Alignment
Mar 25, 2025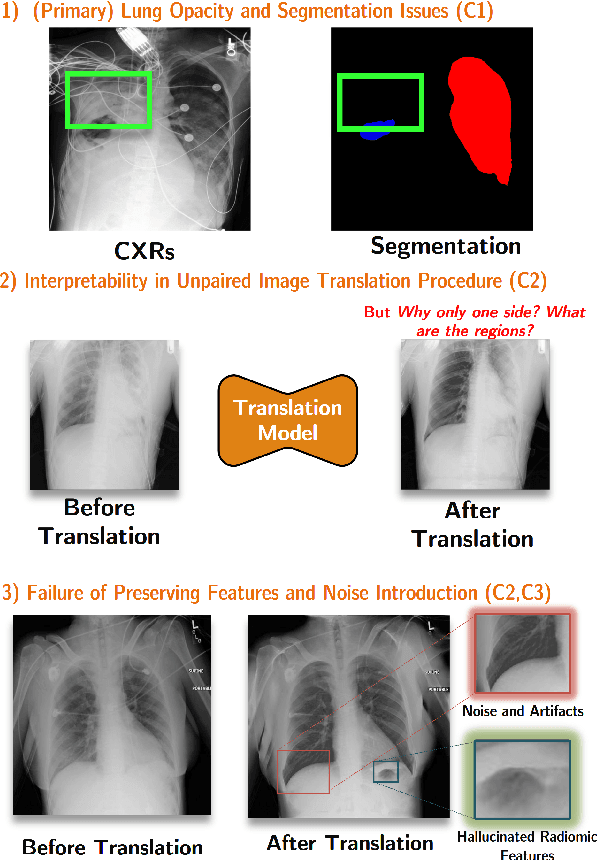

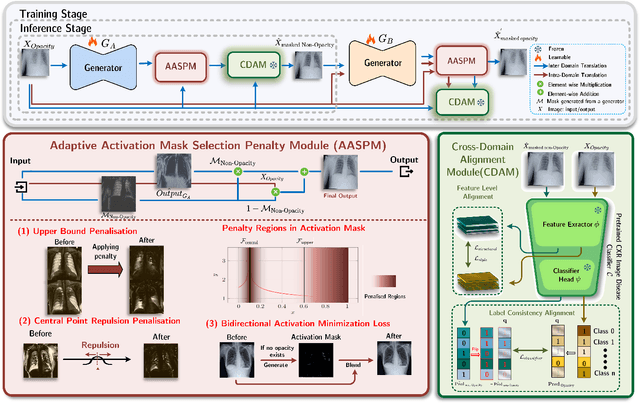

Chest X-ray radiographs (CXRs) play a pivotal role in diagnosing and monitoring cardiopulmonary diseases. However, lung opac- ities in CXRs frequently obscure anatomical structures, impeding clear identification of lung borders and complicating the localization of pathology. This challenge significantly hampers segmentation accuracy and precise lesion identification, which are crucial for diagnosis. To tackle these issues, our study proposes an unpaired CXR translation framework that converts CXRs with lung opacities into counterparts without lung opacities while preserving semantic features. Central to our approach is the use of adaptive activation masks to selectively modify opacity regions in lung CXRs. Cross-domain alignment ensures translated CXRs without opacity issues align with feature maps and prediction labels from a pre-trained CXR lesion classifier, facilitating the interpretability of the translation process. We validate our method using RSNA, MIMIC-CXR-JPG and JSRT datasets, demonstrating superior translation quality through lower Frechet Inception Distance (FID) and Kernel Inception Distance (KID) scores compared to existing meth- ods (FID: 67.18 vs. 210.4, KID: 0.01604 vs. 0.225). Evaluation on RSNA opacity, MIMIC acute respiratory distress syndrome (ARDS) patient CXRs and JSRT CXRs show our method enhances segmentation accuracy of lung borders and improves lesion classification, further underscoring its potential in clinical settings (RSNA: mIoU: 76.58% vs. 62.58%, Sensitivity: 85.58% vs. 77.03%; MIMIC ARDS: mIoU: 86.20% vs. 72.07%, Sensitivity: 92.68% vs. 86.85%; JSRT: mIoU: 91.08% vs. 85.6%, Sensitivity: 97.62% vs. 95.04%). Our approach advances CXR imaging analysis, especially in investigating segmentation impacts through image translation techniques.
GEMA-Score: Granular Explainable Multi-Agent Score for Radiology Report Evaluation
Mar 07, 2025



Automatic medical report generation supports clinical diagnosis, reduces the workload of radiologists, and holds the promise of improving diagnosis consistency. However, existing evaluation metrics primarily assess the accuracy of key medical information coverage in generated reports compared to human-written reports, while overlooking crucial details such as the location and certainty of reported abnormalities. These limitations hinder the comprehensive assessment of the reliability of generated reports and pose risks in their selection for clinical use. Therefore, we propose a Granular Explainable Multi-Agent Score (GEMA-Score) in this paper, which conducts both objective quantification and subjective evaluation through a large language model-based multi-agent workflow. Our GEMA-Score parses structured reports and employs NER-F1 calculations through interactive exchanges of information among agents to assess disease diagnosis, location, severity, and uncertainty. Additionally, an LLM-based scoring agent evaluates completeness, readability, and clinical terminology while providing explanatory feedback. Extensive experiments validate that GEMA-Score achieves the highest correlation with human expert evaluations on a public dataset, demonstrating its effectiveness in clinical scoring (Kendall coefficient = 0.70 for Rexval dataset and Kendall coefficient = 0.54 for RadEvalX dataset). The anonymous project demo is available at: https://github.com/Zhenxuan-Zhang/GEMA_score.
Decoding Report Generators: A Cyclic Vision-Language Adapter for Counterfactual Explanations
Nov 08, 2024



Despite significant advancements in report generation methods, a critical limitation remains: the lack of interpretability in the generated text. This paper introduces an innovative approach to enhance the explainability of text generated by report generation models. Our method employs cyclic text manipulation and visual comparison to identify and elucidate the features in the original content that influence the generated text. By manipulating the generated reports and producing corresponding images, we create a comparative framework that highlights key attributes and their impact on the text generation process. This approach not only identifies the image features aligned to the generated text but also improves transparency but also provides deeper insights into the decision-making mechanisms of the report generation models. Our findings demonstrate the potential of this method to significantly enhance the interpretability and transparency of AI-generated reports.
Learning Task-Specific Sampling Strategy for Sparse-View CT Reconstruction
Sep 03, 2024



Sparse-View Computed Tomography (SVCT) offers low-dose and fast imaging but suffers from severe artifacts. Optimizing the sampling strategy is an essential approach to improving the imaging quality of SVCT. However, current methods typically optimize a universal sampling strategy for all types of scans, overlooking the fact that the optimal strategy may vary depending on the specific scanning task, whether it involves particular body scans (e.g., chest CT scans) or downstream clinical applications (e.g., disease diagnosis). The optimal strategy for one scanning task may not perform as well when applied to other tasks. To address this problem, we propose a deep learning framework that learns task-specific sampling strategies with a multi-task approach to train a unified reconstruction network while tailoring optimal sampling strategies for each individual task. Thus, a task-specific sampling strategy can be applied for each type of scans to improve the quality of SVCT imaging and further assist in performance of downstream clinical usage. Extensive experiments across different scanning types provide validation for the effectiveness of task-specific sampling strategies in enhancing imaging quality. Experiments involving downstream tasks verify the clinical value of learned sampling strategies, as evidenced by notable improvements in downstream task performance. Furthermore, the utilization of a multi-task framework with a shared reconstruction network facilitates deployment on current imaging devices with switchable task-specific modules, and allows for easily integrate new tasks without retraining the entire model.