 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy-Aware Siamese Network: Exploiting Semantic Asymmetry for Accurate Pelvic Fracture Detection in X-ray Images
Jul 12, 2020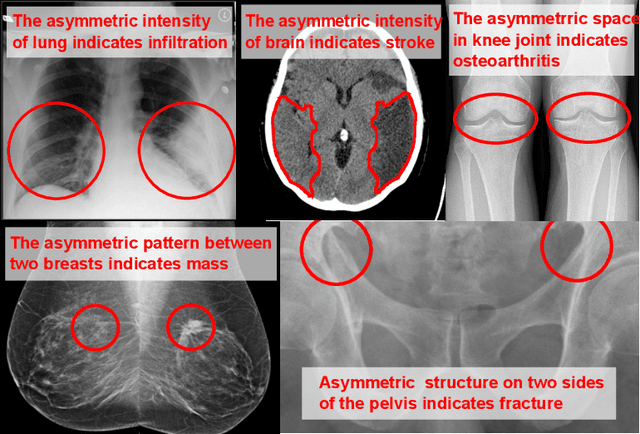
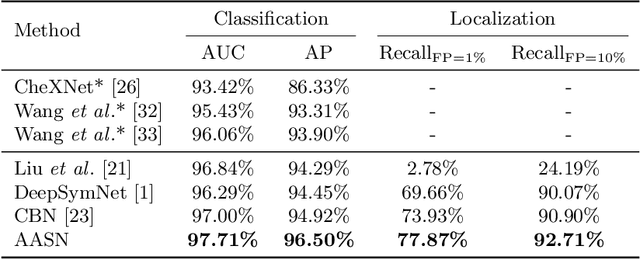
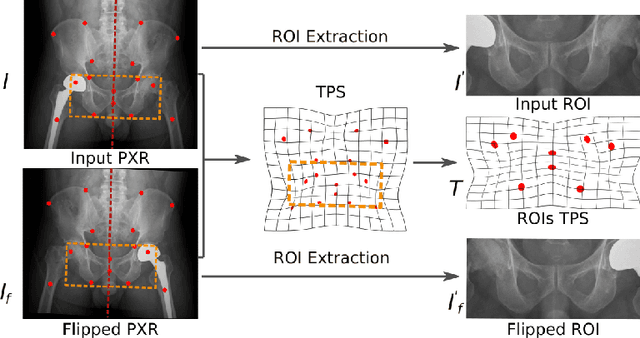
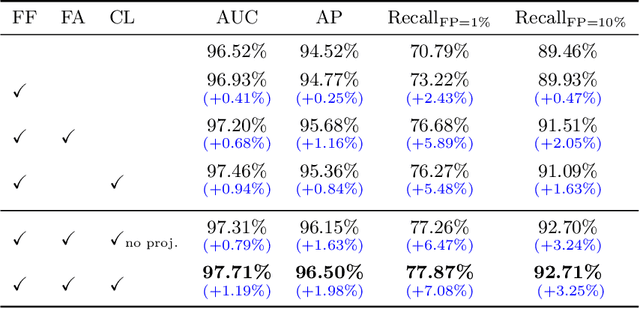
Visual cues of enforcing bilaterally symmetric anatomies as normal findings are widely used in clinical practice to disambiguate subtle abnormalities from medical images. So far, inadequate research attention has been received on effectively emulating this practice in CAD methods. In this work, we exploit semantic anatomical symmetry or asymmetry analysis in a complex CAD scenario, i.e., anterior pelvic fracture detection in trauma PXRs, where semantically pathological (refer to as fracture) and non-pathological (e.g., pose) asymmetries both occur. Visually subtle yet pathologically critical fracture sites can be missed even by experienced clinicians, when limited diagnosis time is permitted in emergency care. We propose a novel fracture detection framework that builds upon a Siamese network enhanced with a spatial transformer layer to holistically analyze symmetric image features. Image features are spatially formatted to encode bilaterally symmetric anatomies. A new contrastive feature learning component in our Siamese network is designed to optimize the deep image features being more salient corresponding to the underlying semantic asymmetries (caused by pelvic fracture occurrences). Our proposed method have been extensively evaluated on 2,359 PXRs from unique patients (the largest study to-date), and report an area under ROC curve score of 0.9771. This is the highest among state-of-the-art fracture detection methods, with improved clinical indications.
Learning Geocentric Object Pose in Oblique Monocular Images
Jul 01, 2020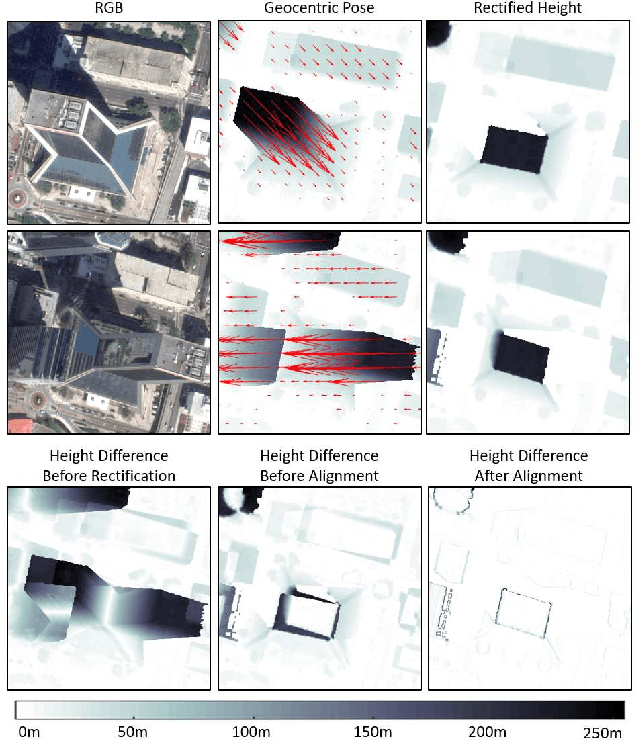
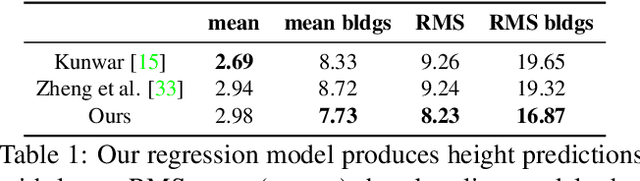
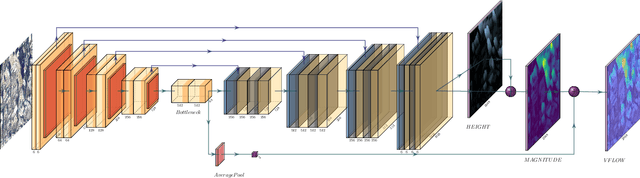

An object's geocentric pose, defined as the height above ground and orientation with respect to gravity, is a powerful representation of real-world structure for object detection, segmentation, and localization tasks using RGBD images. For close-range vision tasks, height and orientation have been derived directly from stereo-computed depth and more recently from monocular depth predicted by deep networks. For long-range vision tasks such as Earth observation, depth cannot be reliably estimated with monocular images. Inspired by recent work in monocular height above ground prediction and optical flow prediction from static images, we develop an encoding of geocentric pose to address this challenge and train a deep network to compute the representation densely, supervised by publicly available airborne lidar. We exploit these attributes to rectify oblique images and remove observed object parallax to dramatically improve the accuracy of localization and to enable accurate alignment of multiple images taken from very different oblique viewpoints. We demonstrate the value of our approach by extending two large-scale public datasets for semantic segmentation in oblique satellite images. All of our data and code are publicly available.
Semantic Image Manipulation Using Scene Graphs
Apr 07, 2020
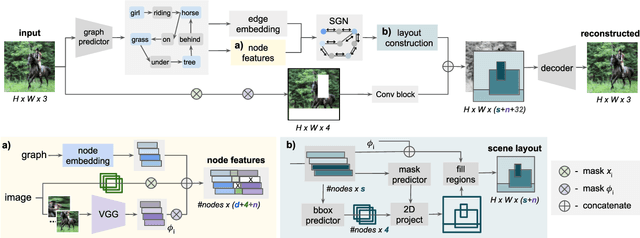
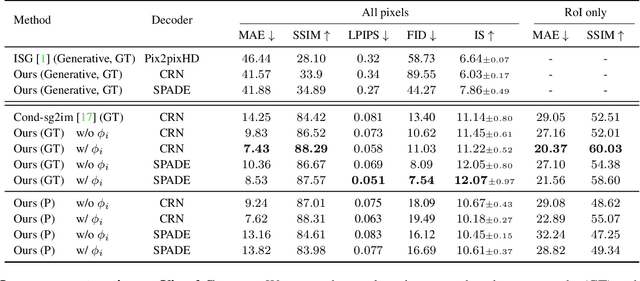
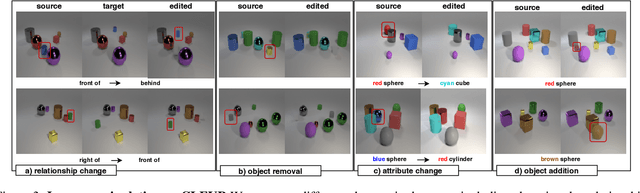
Image manipulation can be considered a special case of image generation where the image to be produced is a modification of an existing image. Image generation and manipulation have been, for the most part, tasks that operate on raw pixels. However, the remarkable progress in learning rich image and object representations has opened the way for tasks such as text-to-image or layout-to-image generation that are mainly driven by semantics. In our work, we address the novel problem of image manipulation from scene graphs, in which a user can edit images by merely applying changes in the nodes or edges of a semantic graph that is generated from the image. Our goal is to encode image information in a given constellation and from there on generate new constellations, such as replacing objects or even changing relationships between objects, while respecting the semantics and style from the original image. We introduce a spatio-semantic scene graph network that does not require direct supervision for constellation changes or image edits. This makes it possible to train the system from existing real-world datasets with no additional annotation effort.
Extremely Dense Point Correspondences using a Learned Feature Descriptor
Mar 27, 2020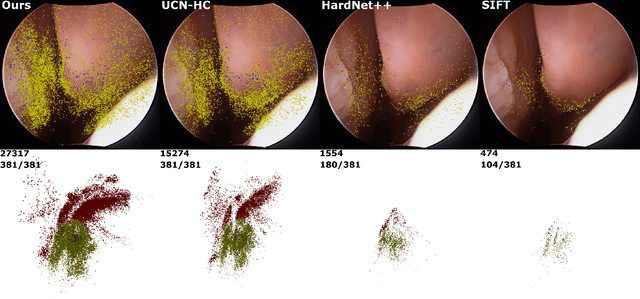

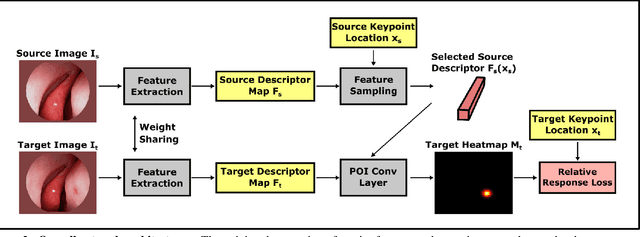
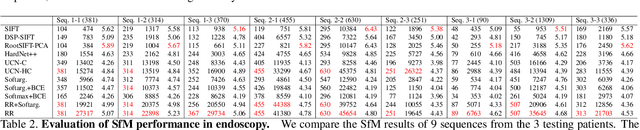
High-quality 3D reconstructions from endoscopy video play an important role in many clinical applications, including surgical navigation where they enable direct video-CT registration. While many methods exist for general multi-view 3D reconstruction, these methods often fail to deliver satisfactory performance on endoscopic video. Part of the reason is that local descriptors that establish pair-wise point correspondences, and thus drive reconstruction, struggle when confronted with the texture-scarce surface of anatomy. Learning-based dense descriptors usually have larger receptive fields enabling the encoding of global information, which can be used to disambiguate matches. In this work, we present an effective self-supervised training scheme and novel loss design for dense descriptor learning. In direct comparison to recent local and dense descriptors on an in-house sinus endoscopy dataset, we demonstrate that our proposed dense descriptor can generalize to unseen patients and scopes, thereby largely improving the performance of Structure from Motion (SfM) in terms of model density and completeness. We also evaluate our method on a public dense optical flow dataset and a small-scale SfM public dataset to further demonstrate the effectiveness and generality of our method. The source code is available at https://github.com/lppllppl920/DenseDescriptorLearning-Pytorch.
Reconstructing Sinus Anatomy from Endoscopic Video -- Towards a Radiation-free Approach for Quantitative Longitudinal Assessment
Mar 18, 2020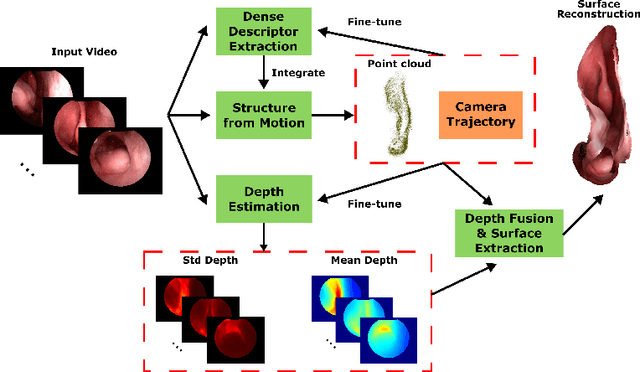
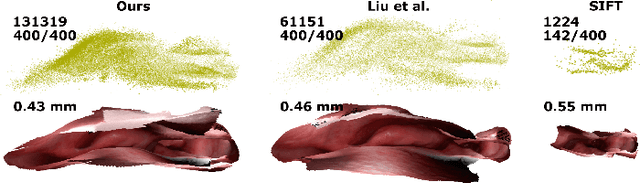
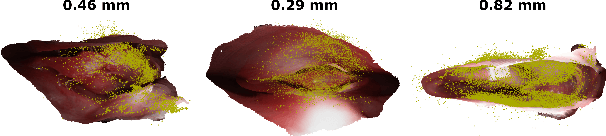
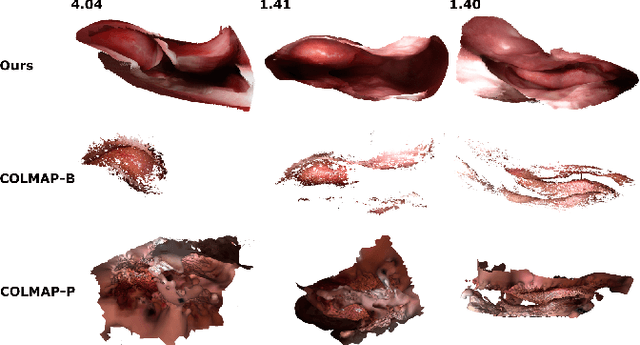
Reconstructing accurate 3D surface models of sinus anatomy directly from an endoscopic video is a promising avenue for cross-sectional and longitudinal analysis to better understand the relationship between sinus anatomy and surgical outcomes. We present a patient-specific, learning-based method for 3D reconstruction of sinus surface anatomy directly and only from endoscopic videos. We demonstrate the effectiveness and accuracy of our method on in and ex vivo data where we compare to sparse reconstructions from Structure from Motion, dense reconstruction from COLMAP, and ground truth anatomy from CT. Our textured reconstructions are watertight and enable measurement of clinically relevant parameters in good agreement with CT. The source code will be made publicly available upon publication.
Car Pose in Context: Accurate Pose Estimation with Ground Plane Constraints
Dec 09, 2019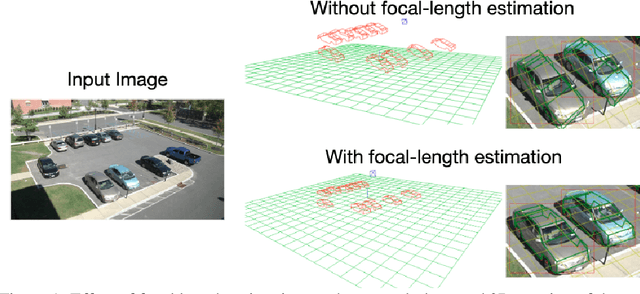
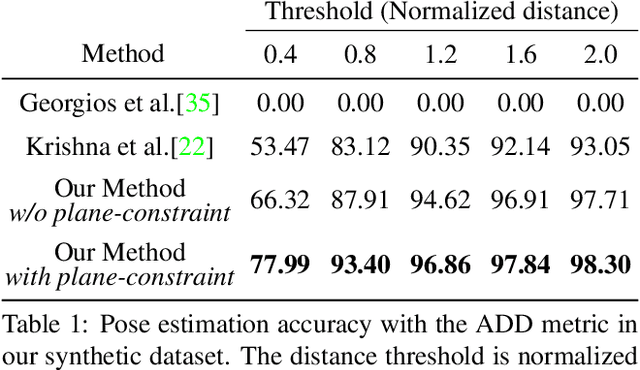
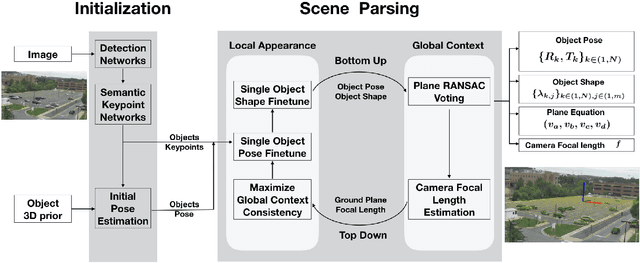
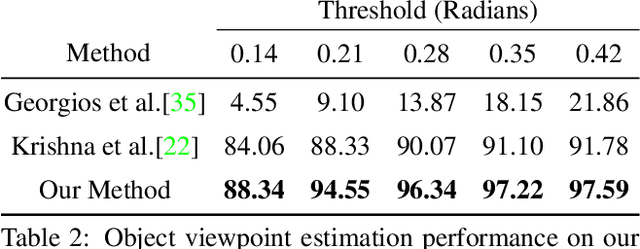
Scene context is a powerful constraint on the geometry of objects within the scene in cases, such as surveillance, where the camera geometry is unknown and image quality may be poor. In this paper, we describe a method for estimating the pose of cars in a scene jointly with the ground plane that supports them. We formulate this as a joint optimization that accounts for varying car shape using a statistical atlas, and which simultaneously computes geometry and internal camera parameters. We demonstrate that this method produces significant improvements for car pose estimation, and we show that the resulting 3D geometry, when computed over a video sequence, makes it possible to improve on state of the art classification of car behavior. We also show that introducing the planar constraint allows us to estimate camera focal length in a reliable manner.
Zero-shot Recognition of Complex Action Sequences
Dec 08, 2019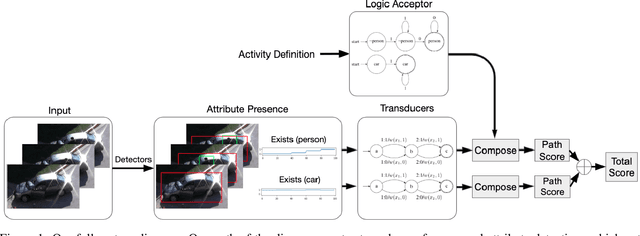
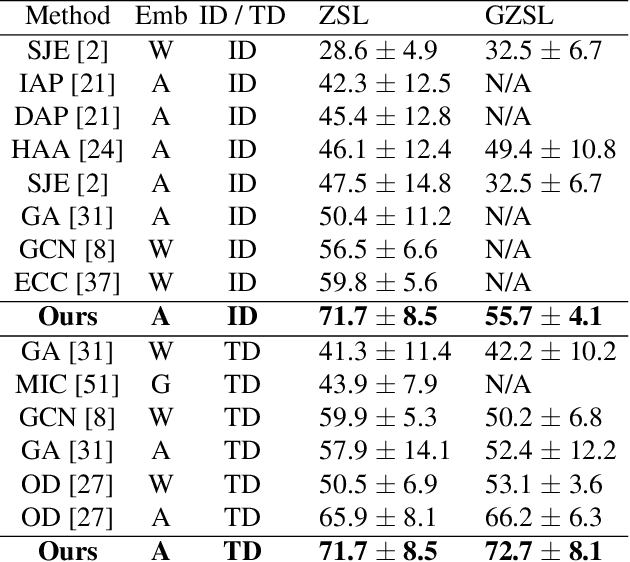
Zero-shot video classification for fine-grained activity recognition has largely been explored using methods similar to its image-based counterpart, namely by defining image-derived attributes that serve to discriminate among classes. However, such methods do not capture the fundamental dynamics of activities and are thus limited to cases where static image content alone suffices to classify an activity. For example, reversible actions such as entering and exiting a car are often indistinguishable. In this work, we present a framework for straightforward modeling of activities as a state machine of dynamic attributes. We show that encoding the temporal structure of attributes greatly increases our modeling power, allowing us to capture action direction, for example. Further, we can extend this to activity detection using dynamic programming, providing, to our knowledge, the first example of zero-shot joint segmentation and classification of complex action sequences in a larger video. We evaluate our method on the Olympic Sports dataset where our model establishes a new state of the art for standard zero-shot-learning (ZSL) evaluation as well as outperforming all other models in the inductive category for general (GZSL) zero-shot evaluation. Additionally, we are the first to demonstrate zero-shot decoding of complex action sequences on a widely used surgical dataset. Lastly, we show that that we can even eliminate the need to train attribute detectors by using off-the-shelf object detectors to recognize activities in challenging surveillance videos.
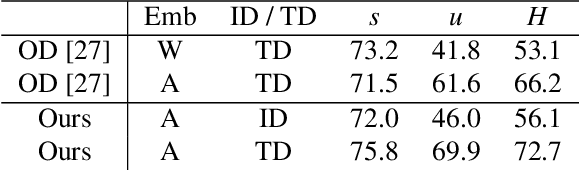
RSA: Randomized Simulation as Augmentation for Robust Human Action Recognition
Dec 03, 2019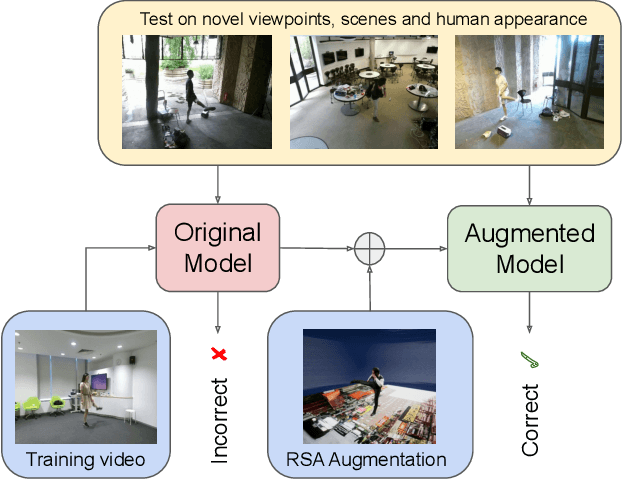
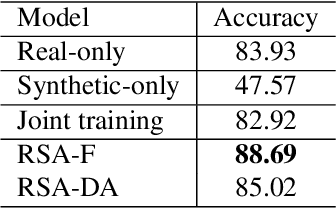
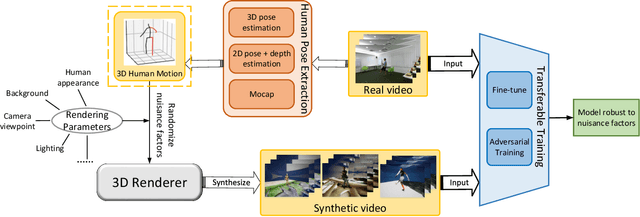

Despite the rapid growth in datasets for video activity, stable robust activity recognition with neural networks remains challenging. This is in large part due to the explosion of possible variation in video -- including lighting changes, object variation, movement variation, and changes in surrounding context. An alternative is to make use of simulation data, where all of these factors can be artificially controlled. In this paper, we propose the Randomized Simulation as Augmentation (RSA) framework which augments real-world training data with synthetic data to improve the robustness of action recognition networks. We generate large-scale synthetic datasets with randomized nuisance factors. We show that training with such extra data, when appropriately constrained, can significantly improve the performance of the state-of-the-art I3D networks or, conversely, reduce the number of labeled real videos needed to achieve good performance. Experiments on two real-world datasets NTU RGB+D and VIRAT demonstrate the effectiveness of our method.
Action Recognition Using Volumetric Motion Representations
Nov 19, 2019

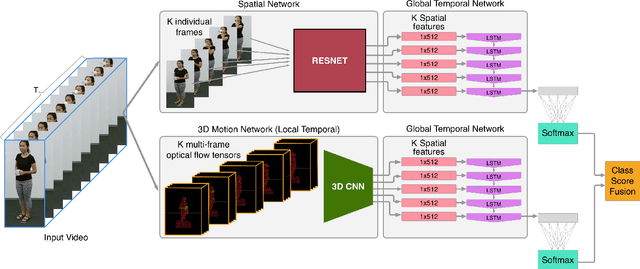
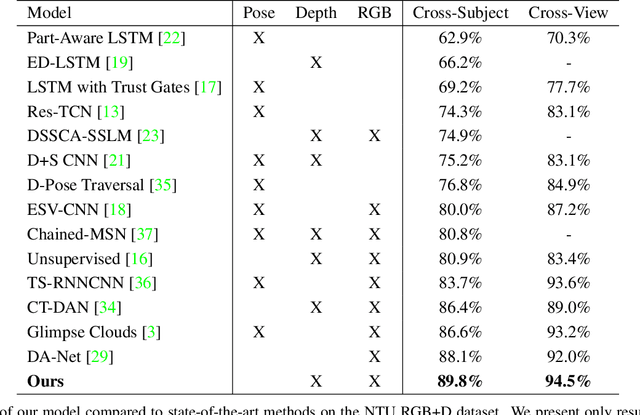
Traditional action recognition models are constructed around the paradigm of 2D perspective imagery. Though sophisticated time-series models have pushed the field forward, much of the information is still not exploited by confining the domain to 2D. In this work, we introduce a novel representation of motion as a voxelized 3D vector field and demonstrate how it can be used to improve performance of action recognition networks. This volumetric representation is a natural fit for 3D CNNs, and allows out-of-plane data augmentation techniques during training of these networks. Both the construction of this representation from RGB-D video and inference can be run in real time. We demonstrate superior results using this representation with our network design on the open-source NTU RGB+D dataset where it outperforms state-of-the-art on both of the defined evaluation metrics. Furthermore, we experimentally show how the out-of-plane augmentation techniques create viewpoint invariance and allow the model trained using this representation to generalize to unseen camera angles. Code is available here: https://github.com/mpeven/ntu_rgb.
"Good Robot!": Efficient Reinforcement Learning for Multi-Step Visual Tasks via Reward Shaping
Sep 25, 2019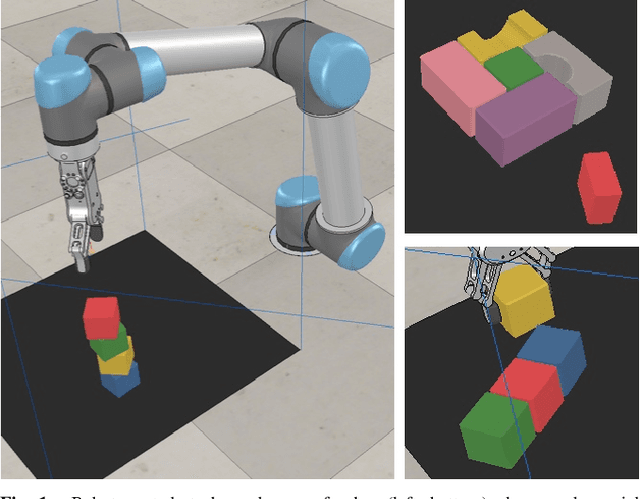
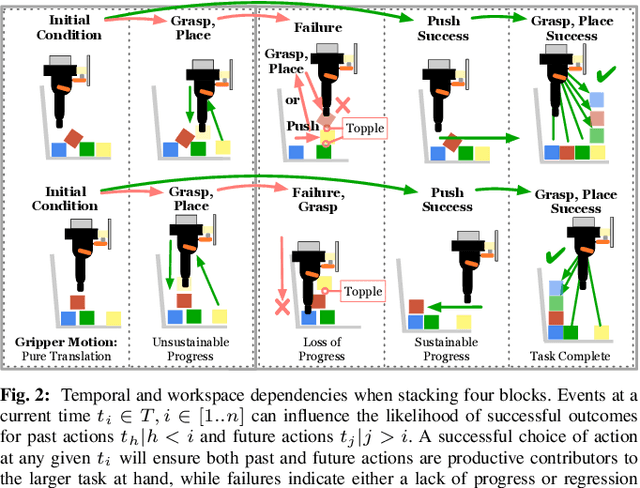
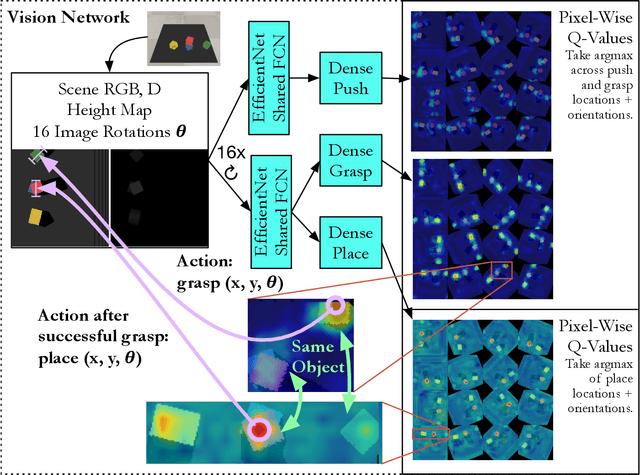
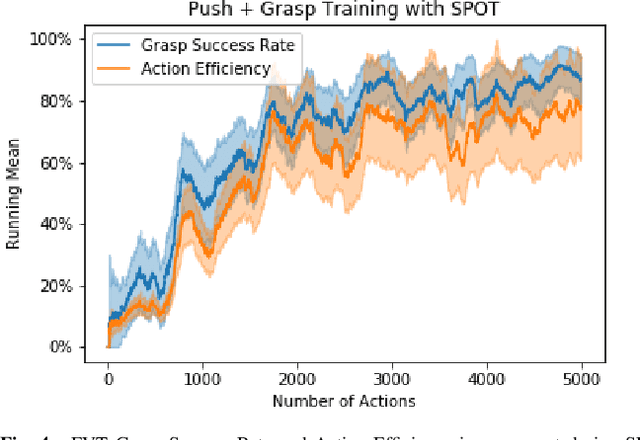
In order to learn effectively, robots must be able to extract the intangible context by which task progress and mistakes are defined. In the domain of reinforcement learning, much of this information is provided by the reward function. Hence, reward shaping is a necessary part of how we can achieve state-of-the-art results on complex, multi-step tasks. However, comparatively little work has examined how reward shaping should be done so that it captures task context, particularly in scenarios where the task is long-horizon and failure is highly consequential. Our Schedule for Positive Task (SPOT) reward trains our Efficient Visual Task (EVT) model to solve problems that require an understanding of both task context and workspace constraints of multi-step block arrangement tasks. In simulation EVT can completely clear adversarial arrangements of objects by pushing and grasping in 99% of cases vs an 82% baseline in prior work. For random arrangements EVT clears 100% of test cases at 86% action efficiency vs 61% efficiency in prior work. EVT + SPOT is also able to demonstrate context understanding and complete stacks in 74% of trials compared to a baseline of 5% with EVT alone. To our knowledge, this is the first instance of a Reinforcement Learning based algorithm successfully completing such a challenge. Code is available at https://github.com/jhu-lcsr/good_robot .