 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOCUS: Effective Embedding Initialization for Specializing Pretrained Multilingual Models on a Single Language
May 23, 2023Using model weights pretrained on a high-resource language as a warm start can reduce the need for data and compute to obtain high-quality language models in low-resource languages. To accommodate the new language, the pretrained vocabulary and embeddings need to be adapted. Previous work on embedding initialization for such adapted vocabularies has mostly focused on monolingual source models. In this paper, we investigate the multilingual source model setting and propose FOCUS - Fast Overlapping Token Combinations Using Sparsemax, a novel embedding initialization method that outperforms previous work when adapting XLM-R. FOCUS represents newly added tokens as combinations of tokens in the overlap of the pretrained and new vocabularies. The overlapping tokens are selected based on semantic similarity in an auxiliary token embedding space. Our implementation of FOCUS is publicly available on GitHub.
MultiModal Bias: Introducing a Framework for Stereotypical Bias Assessment beyond Gender and Race in Vision Language Models
Mar 16, 2023



Recent breakthroughs in self supervised training have led to a new class of pretrained vision language models. While there have been investigations of bias in multimodal models, they have mostly focused on gender and racial bias, giving much less attention to other relevant groups, such as minorities with regard to religion, nationality, sexual orientation, or disabilities. This is mainly due to lack of suitable benchmarks for such groups. We seek to address this gap by providing a visual and textual bias benchmark called MMBias, consisting of around 3,800 images and phrases covering 14 population subgroups. We utilize this dataset to assess bias in several prominent self supervised multimodal models, including CLIP, ALBEF, and ViLT. Our results show that these models demonstrate meaningful bias favoring certain groups. Finally, we introduce a debiasing method designed specifically for such large pre-trained models that can be applied as a post-processing step to mitigate bias, while preserving the remaining accuracy of the model.
ViLPAct: A Benchmark for Compositional Generalization on Multimodal Human Activities
Oct 11, 2022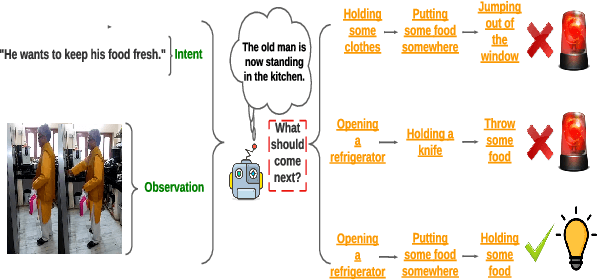
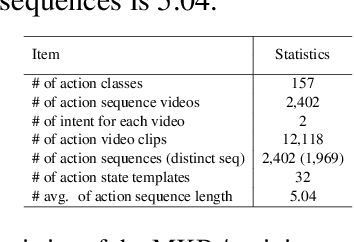

We introduce ViLPAct, a novel vision-language benchmark for human activity planning. It is designed for a task where embodied AI agents can reason and forecast future actions of humans based on video clips about their initial activities and intents in text. The dataset consists of 2.9k videos from \charades extended with intents via crowdsourcing, a multi-choice question test set, and four strong baselines. One of the baselines implements a neurosymbolic approach based on a multi-modal knowledge base (MKB), while the other ones are deep generative models adapted from recent state-of-the-art (SOTA) methods. According to our extensive experiments, the key challenges are compositional generalization and effective use of information from both modalities.
Frozen CLIP Models are Efficient Video Learners
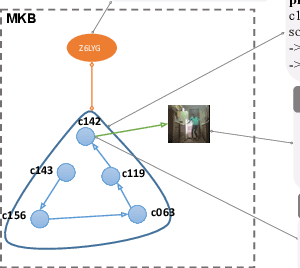
Aug 06, 2022
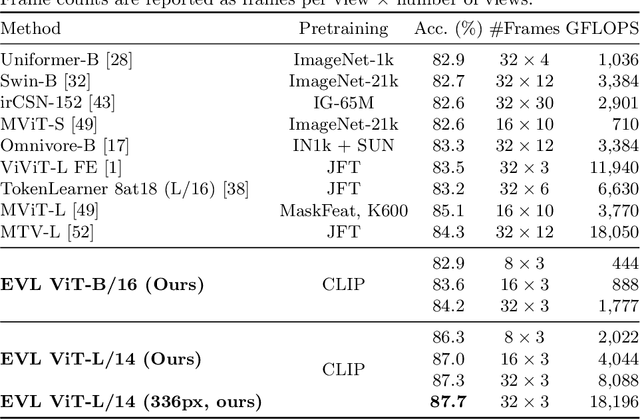
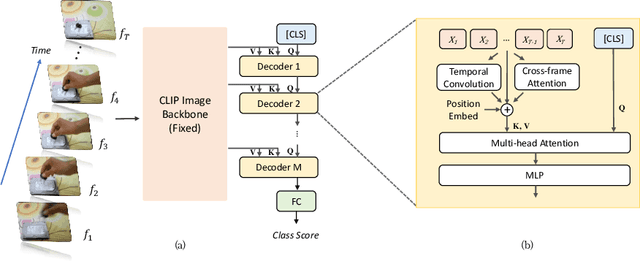
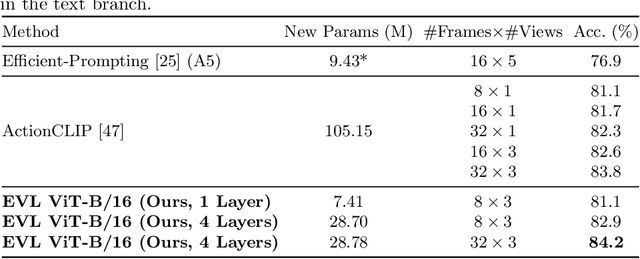
Video recognition has been dominated by the end-to-end learning paradigm -- first initializing a video recognition model with weights of a pretrained image model and then conducting end-to-end training on videos. This enables the video network to benefit from the pretrained image model. However, this requires substantial computation and memory resources for finetuning on videos and the alternative of directly using pretrained image features without finetuning the image backbone leads to subpar results. Fortunately, recent advances in Contrastive Vision-Language Pre-training (CLIP) pave the way for a new route for visual recognition tasks. Pretrained on large open-vocabulary image-text pair data, these models learn powerful visual representations with rich semantics. In this paper, we present Efficient Video Learning (EVL) -- an efficient framework for directly training high-quality video recognition models with frozen CLIP features. Specifically, we employ a lightweight Transformer decoder and learn a query token to dynamically collect frame-level spatial features from the CLIP image encoder. Furthermore, we adopt a local temporal module in each decoder layer to discover temporal clues from adjacent frames and their attention maps. We show that despite being efficient to train with a frozen backbone, our models learn high quality video representations on a variety of video recognition datasets. Code is available at https://github.com/OpenGVLab/efficient-video-recognition.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Fast-R2D2: A Pretrained Recursive Neural Network based on Pruned CKY for Grammar Induction and Text Representation
Mar 01, 2022
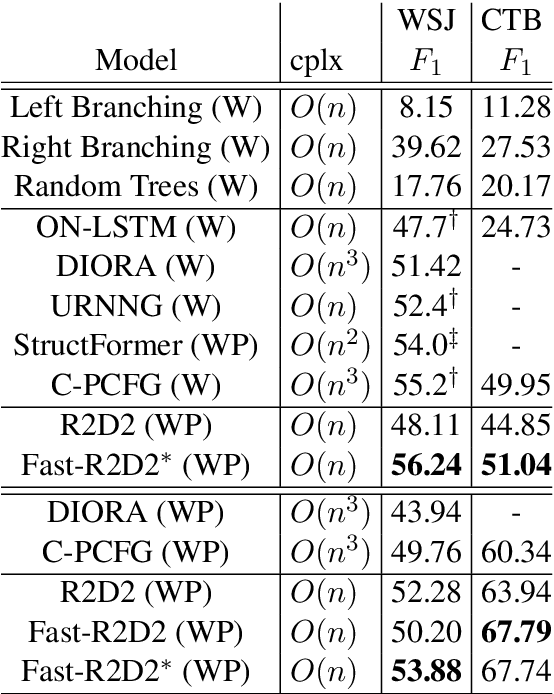

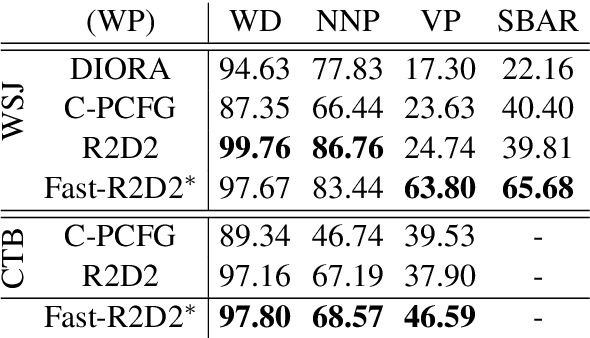
Recently CKY-based models show great potential in unsupervised grammar induction thanks to their human-like encoding paradigm, which runs recursively and hierarchically, but requires $O(n^3)$ time-complexity. Recursive Transformer based on Differentiable Trees (R2D2) makes it possible to scale to large language model pre-training even with complex tree encoder by introducing a heuristic pruning method. However, the rule-based pruning approach suffers from local optimum and slow inference issues. In this paper, we fix those issues in a unified method. We propose to use a top-down parser as a model-based pruning method, which also enables parallel encoding during inference. Typically, our parser casts parsing as a split point scoring task, which first scores all split points for a given sentence, and then recursively splits a span into two by picking a split point with the highest score in the current span. The reverse order of the splits is considered as the order of pruning in R2D2 encoder. Beside the bi-directional language model loss, we also optimize the parser by minimizing the KL distance between tree probabilities from parser and R2D2. Our experiments show that our Fast-R2D2 improves performance significantly in grammar induction and achieves competitive results in downstream classification tasks.
Art Creation with Multi-Conditional StyleGANs
Feb 23, 2022



Creating meaningful art is often viewed as a uniquely human endeavor. A human artist needs a combination of unique skills, understanding, and genuine intention to create artworks that evoke deep feelings and emotions. In this paper, we introduce a multi-conditional Generative Adversarial Network (GAN) approach trained on large amounts of human paintings to synthesize realistic-looking paintings that emulate human art. Our approach is based on the StyleGAN neural network architecture, but incorporates a custom multi-conditional control mechanism that provides fine-granular control over characteristics of the generated paintings, e.g., with regard to the perceived emotion evoked in a spectator. For better control, we introduce the conditional truncation trick, which adapts the standard truncation trick for the conditional setting and diverse datasets. Finally, we develop a diverse set of evaluation techniques tailored to multi-conditional generation.
Does CLIP Benefit Visual Question Answering in the Medical Domain as Much as it Does in the General Domain?
Dec 27, 2021
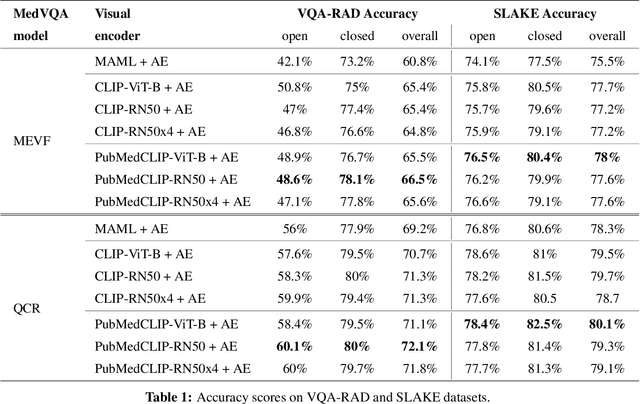
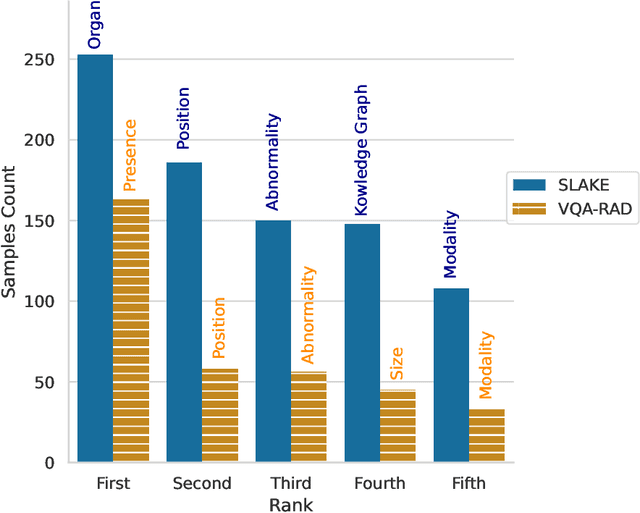
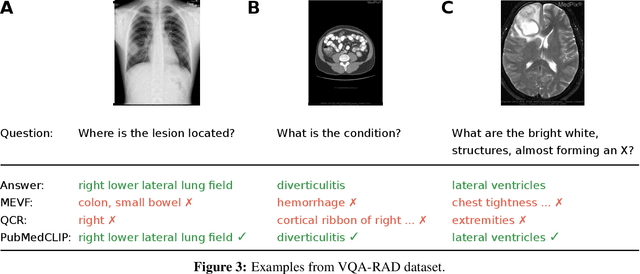
Contrastive Language--Image Pre-training (CLIP) has shown remarkable success in learning with cross-modal supervision from extensive amounts of image--text pairs collected online. Thus far, the effectiveness of CLIP has been investigated primarily in general-domain multimodal problems. This work evaluates the effectiveness of CLIP for the task of Medical Visual Question Answering (MedVQA). To this end, we present PubMedCLIP, a fine-tuned version of CLIP for the medical domain based on PubMed articles. Our experiments are conducted on two MedVQA benchmark datasets and investigate two MedVQA methods, MEVF (Mixture of Enhanced Visual Features) and QCR (Question answering via Conditional Reasoning). For each of these, we assess the merits of visual representation learning using PubMedCLIP, the original CLIP, and state-of-the-art MAML (Model-Agnostic Meta-Learning) networks pre-trained only on visual data. We open source the code for our MedVQA pipeline and pre-training PubMedCLIP. CLIP and PubMedCLIP achieve improvements in comparison to MAML's visual encoder. PubMedCLIP achieves the best results with gains in the overall accuracy of up to 3%. Individual examples illustrate the strengths of PubMedCLIP in comparison to the previously widely used MAML networks. Visual representation learning with language supervision in PubMedCLIP leads to noticeable improvements for MedVQA. Our experiments reveal distributional differences in the two MedVQA benchmark datasets that have not been imparted in previous work and cause different back-end visual encoders in PubMedCLIP to exhibit different behavior on these datasets. Moreover, we witness fundamental performance differences of VQA in general versus medical domains.
NL-Augmenter: A Framework for Task-Sensitive Natural Language Augmentation
Dec 06, 2021



Data augmentation is an important component in the robustness evaluation of models in natural language processing (NLP) and in enhancing the diversity of the data they are trained on. In this paper, we present NL-Augmenter, a new participatory Python-based natural language augmentation framework which supports the creation of both transformations (modifications to the data) and filters (data splits according to specific features). We describe the framework and an initial set of 117 transformations and 23 filters for a variety of natural language tasks. We demonstrate the efficacy of NL-Augmenter by using several of its transformations to analyze the robustness of popular natural language models. The infrastructure, datacards and robustness analysis results are available publicly on the NL-Augmenter repository (\url{https://github.com/GEM-benchmark/NL-Augmenter}).
Dense Contrastive Visual-Linguistic Pretraining
Sep 24, 2021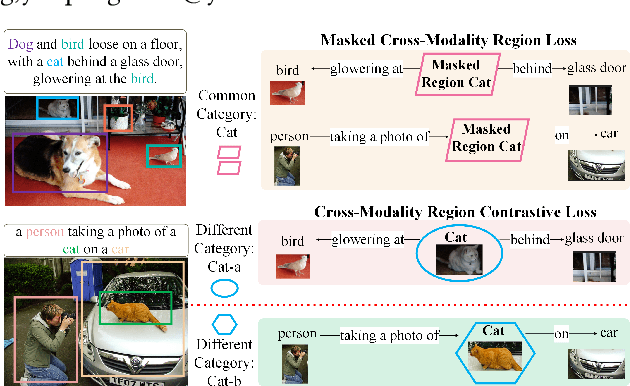

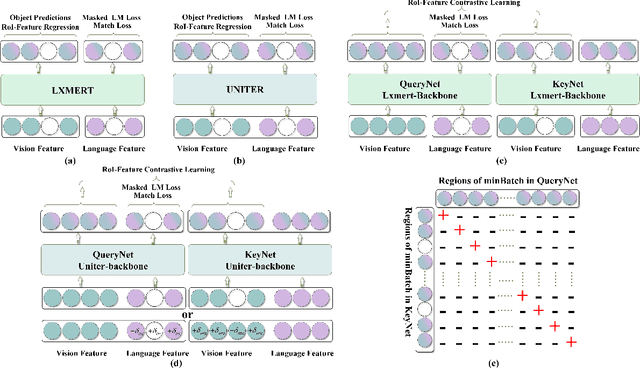
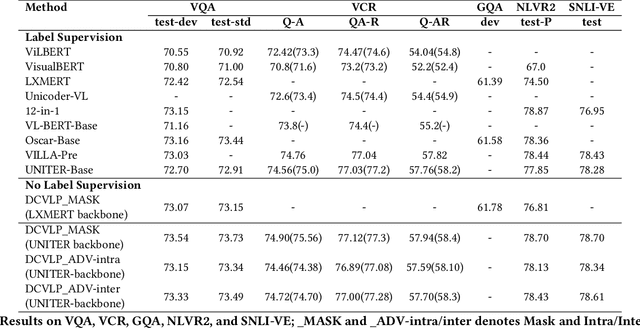
Inspired by the success of BERT, several multimodal representation learning approaches have been proposed that jointly represent image and text. These approaches achieve superior performance by capturing high-level semantic information from large-scale multimodal pretraining. In particular, LXMERT and UNITER adopt visual region feature regression and label classification as pretext tasks. However, they tend to suffer from the problems of noisy labels and sparse semantic annotations, based on the visual features having been pretrained on a crowdsourced dataset with limited and inconsistent semantic labeling. To overcome these issues, we propose unbiased Dense Contrastive Visual-Linguistic Pretraining (DCVLP), which replaces the region regression and classification with cross-modality region contrastive learning that requires no annotations. Two data augmentation strategies (Mask Perturbation and Intra-/Inter-Adversarial Perturbation) are developed to improve the quality of negative samples used in contrastive learning. Overall, DCVLP allows cross-modality dense region contrastive learning in a self-supervised setting independent of any object annotations. We compare our method against prior visual-linguistic pretraining frameworks to validate the superiority of dense contrastive learning on multimodal representation learning.