 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAppAgent-Pro: A Proactive GUI Agent System for Multidomain Information Integration and User Assistance
Aug 27, 2025
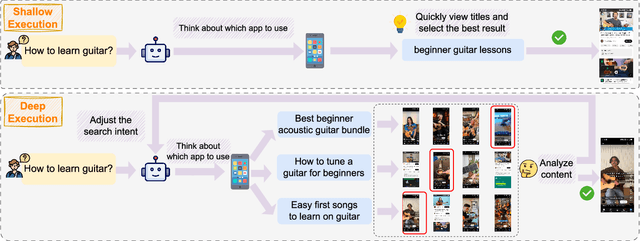


Large language model (LLM)-based agents have demonstrated remarkable capabilities in addressing complex tasks, thereby enabling more advanced information retrieval and supporting deeper, more sophisticated human information-seeking behaviors. However, most existing agents operate in a purely reactive manner, responding passively to user instructions, which significantly constrains their effectiveness and efficiency as general-purpose platforms for information acquisition. To overcome this limitation, this paper proposes AppAgent-Pro, a proactive GUI agent system that actively integrates multi-domain information based on user instructions. This approach enables the system to proactively anticipate users' underlying needs and conduct in-depth multi-domain information mining, thereby facilitating the acquisition of more comprehensive and intelligent information. AppAgent-Pro has the potential to fundamentally redefine information acquisition in daily life, leading to a profound impact on human society. Our code is available at: https://github.com/LaoKuiZe/AppAgent-Pro. The demonstration video could be found at: https://www.dropbox.com/scl/fi/hvzqo5vnusg66srydzixo/AppAgent-Pro-demo-video.mp4?rlkey=o2nlfqgq6ihl125mcqg7bpgqu&st=d29vrzii&dl=0.
Navigating Through Paper Flood: Advancing LLM-based Paper Evaluation through Domain-Aware Retrieval and Latent Reasoning
Aug 07, 2025With the rapid and continuous increase in academic publications, identifying high-quality research has become an increasingly pressing challenge. While recent methods leveraging Large Language Models (LLMs) for automated paper evaluation have shown great promise, they are often constrained by outdated domain knowledge and limited reasoning capabilities. In this work, we present PaperEval, a novel LLM-based framework for automated paper evaluation that addresses these limitations through two key components: 1) a domain-aware paper retrieval module that retrieves relevant concurrent work to support contextualized assessments of novelty and contributions, and 2) a latent reasoning mechanism that enables deep understanding of complex motivations and methodologies, along with comprehensive comparison against concurrently related work, to support more accurate and reliable evaluation. To guide the reasoning process, we introduce a progressive ranking optimization strategy that encourages the LLM to iteratively refine its predictions with an emphasis on relative comparison. Experiments on two datasets demonstrate that PaperEval consistently outperforms existing methods in both academic impact and paper quality evaluation. In addition, we deploy PaperEval in a real-world paper recommendation system for filtering high-quality papers, which has gained strong engagement on social media -- amassing over 8,000 subscribers and attracting over 10,000 views for many filtered high-quality papers -- demonstrating the practical effectiveness of PaperEval.
Latent Inter-User Difference Modeling for LLM Personalization
Jul 28, 2025Large language models (LLMs) are increasingly integrated into users' daily lives, leading to a growing demand for personalized outputs. Previous work focuses on leveraging a user's own history, overlooking inter-user differences that are crucial for effective personalization. While recent work has attempted to model such differences, the reliance on language-based prompts often hampers the effective extraction of meaningful distinctions. To address these issues, we propose Difference-aware Embedding-based Personalization (DEP), a framework that models inter-user differences in the latent space instead of relying on language prompts. DEP constructs soft prompts by contrasting a user's embedding with those of peers who engaged with similar content, highlighting relative behavioral signals. A sparse autoencoder then filters and compresses both user-specific and difference-aware embeddings, preserving only task-relevant features before injecting them into a frozen LLM. Experiments on personalized review generation show that DEP consistently outperforms baseline methods across multiple metrics. Our code is available at https://github.com/SnowCharmQ/DEP.
Teaching LLM to Reason: Reinforcement Learning from Algorithmic Problems without Code
Jul 10, 2025
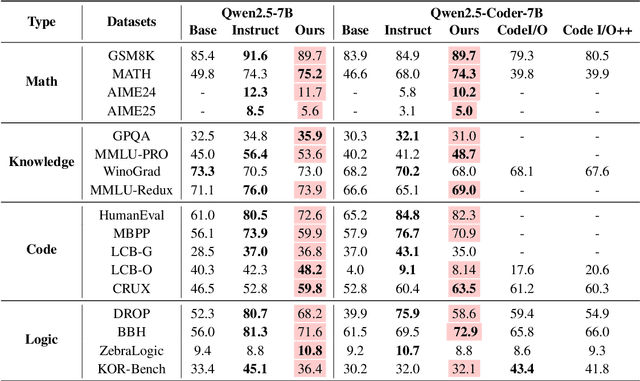

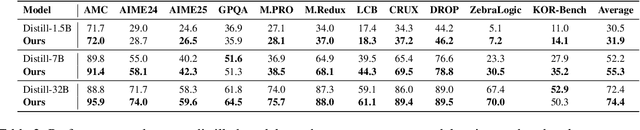
Enhancing reasoning capabilities remains a central focus in the LLM reasearch community. A promising direction involves requiring models to simulate code execution step-by-step to derive outputs for given inputs. However, as code is often designed for large-scale systems, direct application leads to over-reliance on complex data structures and algorithms, even for simple cases, resulting in overfitting to algorithmic patterns rather than core reasoning structures. To address this, we propose TeaR, which aims at teaching LLMs to reason better. TeaR leverages careful data curation and reinforcement learning to guide models in discovering optimal reasoning paths through code-related tasks, thereby improving general reasoning abilities. We conduct extensive experiments using two base models and three long-CoT distillation models, with model sizes ranging from 1.5 billion to 32 billion parameters, and across 17 benchmarks spanning Math, Knowledge, Code, and Logical Reasoning. The results consistently show significant performance improvements. Notably, TeaR achieves a 35.9% improvement on Qwen2.5-7B and 5.9% on R1-Distilled-7B.
Boosting Parameter Efficiency in LLM-Based Recommendation through Sophisticated Pruning
Jul 09, 2025LLM-based recommender systems have made significant progress; however, the deployment cost associated with the large parameter volume of LLMs still hinders their real-world applications. This work explores parameter pruning to improve parameter efficiency while maintaining recommendation quality, thereby enabling easier deployment. Unlike existing approaches that focus primarily on inter-layer redundancy, we uncover intra-layer redundancy within components such as self-attention and MLP modules. Building on this analysis, we propose a more fine-grained pruning approach that integrates both intra-layer and layer-wise pruning. Specifically, we introduce a three-stage pruning strategy that progressively prunes parameters at different levels and parts of the model, moving from intra-layer to layer-wise pruning, or from width to depth. Each stage also includes a performance restoration step using distillation techniques, helping to strike a balance between performance and parameter efficiency. Empirical results demonstrate the effectiveness of our approach: across three datasets, our models achieve an average of 88% of the original model's performance while pruning more than 95% of the non-embedding parameters. This underscores the potential of our method to significantly reduce resource requirements without greatly compromising recommendation quality. Our code will be available at: https://github.com/zheng-sl/PruneRec
VisualTrap: A Stealthy Backdoor Attack on GUI Agents via Visual Grounding Manipulation
Jul 09, 2025Graphical User Interface (GUI) agents powered by Large Vision-Language Models (LVLMs) have emerged as a revolutionary approach to automating human-machine interactions, capable of autonomously operating personal devices (e.g., mobile phones) or applications within the device to perform complex real-world tasks in a human-like manner. However, their close integration with personal devices raises significant security concerns, with many threats, including backdoor attacks, remaining largely unexplored. This work reveals that the visual grounding of GUI agent-mapping textual plans to GUI elements-can introduce vulnerabilities, enabling new types of backdoor attacks. With backdoor attack targeting visual grounding, the agent's behavior can be compromised even when given correct task-solving plans. To validate this vulnerability, we propose VisualTrap, a method that can hijack the grounding by misleading the agent to locate textual plans to trigger locations instead of the intended targets. VisualTrap uses the common method of injecting poisoned data for attacks, and does so during the pre-training of visual grounding to ensure practical feasibility of attacking. Empirical results show that VisualTrap can effectively hijack visual grounding with as little as 5% poisoned data and highly stealthy visual triggers (invisible to the human eye); and the attack can be generalized to downstream tasks, even after clean fine-tuning. Moreover, the injected trigger can remain effective across different GUI environments, e.g., being trained on mobile/web and generalizing to desktop environments. These findings underscore the urgent need for further research on backdoor attack risks in GUI agents.
Unconditional Diffusion for Generative Sequential Recommendation
Jul 08, 2025Diffusion models, known for their generative ability to simulate data creation through noise-adding and denoising processes, have emerged as a promising approach for building generative recommenders. To incorporate user history for personalization, existing methods typically adopt a conditional diffusion framework, where the reverse denoising process of reconstructing items from noise is modified to be conditioned on the user history. However, this design may fail to fully utilize historical information, as it gets distracted by the need to model the "item $\leftrightarrow$ noise" translation. This motivates us to reformulate the diffusion process for sequential recommendation in an unconditional manner, treating user history (instead of noise) as the endpoint of the forward diffusion process (i.e., the starting point of the reverse process), rather than as a conditional input. This formulation allows for exclusive focus on modeling the "item $\leftrightarrow$ history" translation. To this end, we introduce Brownian Bridge Diffusion Recommendation (BBDRec). By leveraging a Brownian bridge process, BBDRec enforces a structured noise addition and denoising mechanism, ensuring that the trajectories are constrained towards a specific endpoint -- user history, rather than noise. Extensive experiments demonstrate BBDRec's effectiveness in enhancing sequential recommendation performance. The source code is available at https://github.com/baiyimeng/BBDRec.
DiscRec: Disentangled Semantic-Collaborative Modeling for Generative Recommendation
Jun 18, 2025Generative recommendation is emerging as a powerful paradigm that directly generates item predictions, moving beyond traditional matching-based approaches. However, current methods face two key challenges: token-item misalignment, where uniform token-level modeling ignores item-level granularity that is critical for collaborative signal learning, and semantic-collaborative signal entanglement, where collaborative and semantic signals exhibit distinct distributions yet are fused in a unified embedding space, leading to conflicting optimization objectives that limit the recommendation performance. To address these issues, we propose DiscRec, a novel framework that enables Disentangled Semantic-Collaborative signal modeling with flexible fusion for generative Recommendation.First, DiscRec introduces item-level position embeddings, assigned based on indices within each semantic ID, enabling explicit modeling of item structure in input token sequences.Second, DiscRec employs a dual-branch module to disentangle the two signals at the embedding layer: a semantic branch encodes semantic signals using original token embeddings, while a collaborative branch applies localized attention restricted to tokens within the same item to effectively capture collaborative signals. A gating mechanism subsequently fuses both branches while preserving the model's ability to model sequential dependencies. Extensive experiments on four real-world datasets demonstrate that DiscRec effectively decouples these signals and consistently outperforms state-of-the-art baselines. Our codes are available on https://github.com/Ten-Mao/DiscRec.
IGD: Token Decisiveness Modeling via Information Gain in LLMs for Personalized Recommendation
Jun 16, 2025Large Language Models (LLMs) have shown strong potential for recommendation by framing item prediction as a token-by-token language generation task. However, existing methods treat all item tokens equally, simply pursuing likelihood maximization during both optimization and decoding. This overlooks crucial token-level differences in decisiveness-many tokens contribute little to item discrimination yet can dominate optimization or decoding. To quantify token decisiveness, we propose a novel perspective that models item generation as a decision process, measuring token decisiveness by the Information Gain (IG) each token provides in reducing uncertainty about the generated item. Our empirical analysis reveals that most tokens have low IG but often correspond to high logits, disproportionately influencing training loss and decoding, which may impair model performance. Building on these insights, we introduce an Information Gain-based Decisiveness-aware Token handling (IGD) strategy that integrates token decisiveness into both tuning and decoding. Specifically, IGD downweights low-IG tokens during tuning and rebalances decoding to emphasize tokens with high IG. In this way, IGD moves beyond pure likelihood maximization, effectively prioritizing high-decisiveness tokens. Extensive experiments on four benchmark datasets with two LLM backbones demonstrate that IGD consistently improves recommendation accuracy, achieving significant gains on widely used ranking metrics compared to strong baselines.
MTR-Bench: A Comprehensive Benchmark for Multi-Turn Reasoning Evaluation
May 26, 2025Recent advances in Large Language Models (LLMs) have shown promising results in complex reasoning tasks. However, current evaluations predominantly focus on single-turn reasoning scenarios, leaving interactive tasks largely unexplored. We attribute it to the absence of comprehensive datasets and scalable automatic evaluation protocols. To fill these gaps, we present MTR-Bench for LLMs' Multi-Turn Reasoning evaluation. Comprising 4 classes, 40 tasks, and 3600 instances, MTR-Bench covers diverse reasoning capabilities, fine-grained difficulty granularity, and necessitates multi-turn interactions with the environments. Moreover, MTR-Bench features fully-automated framework spanning both dataset constructions and model evaluations, which enables scalable assessment without human interventions. Extensive experiments reveal that even the cutting-edge reasoning models fall short of multi-turn, interactive reasoning tasks. And the further analysis upon these results brings valuable insights for future research in interactive AI systems.