 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised 3D Semantic Representation Learning for Vision-and-Language Navigation
Jan 26, 2022



In the Vision-and-Language Navigation task, the embodied agent follows linguistic instructions and navigates to a specific goal. It is important in many practical scenarios and has attracted extensive attention from both computer vision and robotics communities. However, most existing works only use RGB images but neglect the 3D semantic information of the scene. To this end, we develop a novel self-supervised training framework to encode the voxel-level 3D semantic reconstruction into a 3D semantic representation. Specifically, a region query task is designed as the pretext task, which predicts the presence or absence of objects of a particular class in a specific 3D region. Then, we construct an LSTM-based navigation model and train it with the proposed 3D semantic representations and BERT language features on vision-language pairs. Experiments show that the proposed approach achieves success rates of 68% and 66% on the validation unseen and test unseen splits of the R2R dataset respectively, which are superior to most of RGB-based methods utilizing vision-language transformers.
Bootstrapping Informative Graph Augmentation via A Meta Learning Approach
Jan 11, 2022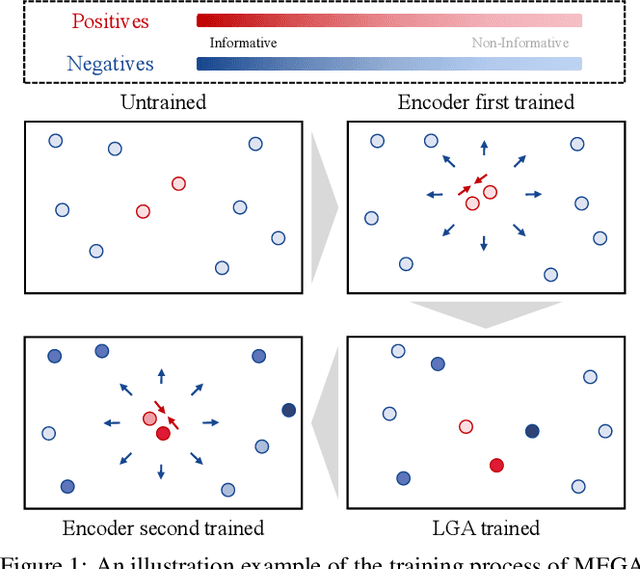

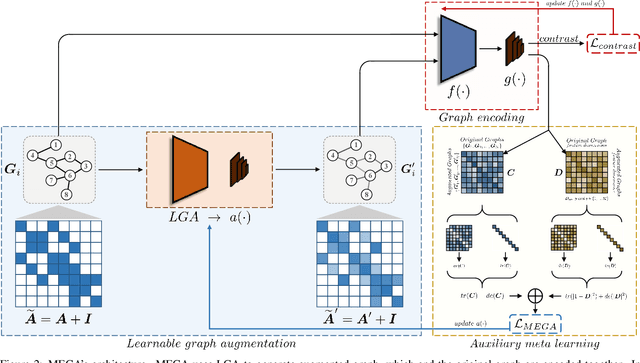
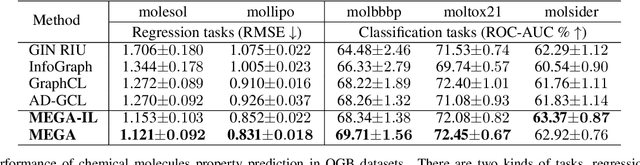
Recent works explore learning graph representations in a self-supervised manner. In graph contrastive learning, benchmark methods apply various graph augmentation approaches. However, most of the augmentation methods are non-learnable, which causes the issue of generating unbeneficial augmented graphs. Such augmentation may degenerate the representation ability of graph contrastive learning methods. Therefore, we motivate our method to generate augmented graph by a learnable graph augmenter, called MEta Graph Augmentation (MEGA). We then clarify that a "good" graph augmentation must have uniformity at the instance-level and informativeness at the feature-level. To this end, we propose a novel approach to learning a graph augmenter that can generate an augmentation with uniformity and informativeness. The objective of the graph augmenter is to promote our feature extraction network to learn a more discriminative feature representation, which motivates us to propose a meta-learning paradigm. Empirically, the experiments across multiple benchmark datasets demonstrate that MEGA outperforms the state-of-the-art methods in graph self-supervised learning tasks. Further experimental studies prove the effectiveness of different terms of MEGA.
Channel Exchanging Networks for Multimodal and Multitask Dense Image Prediction
Dec 04, 2021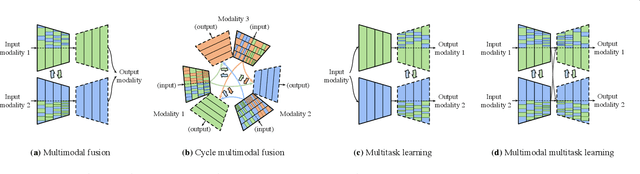
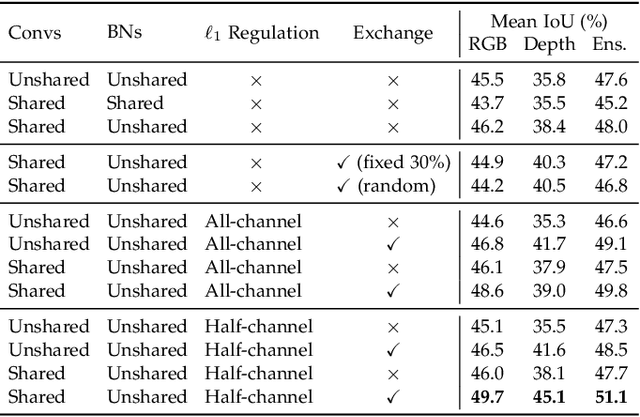
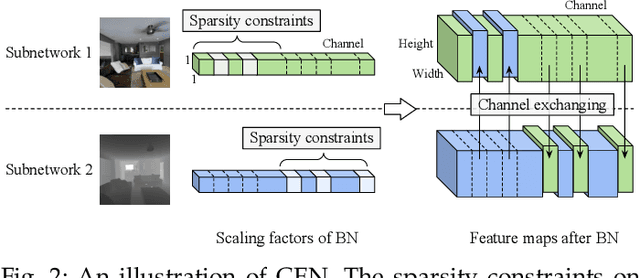
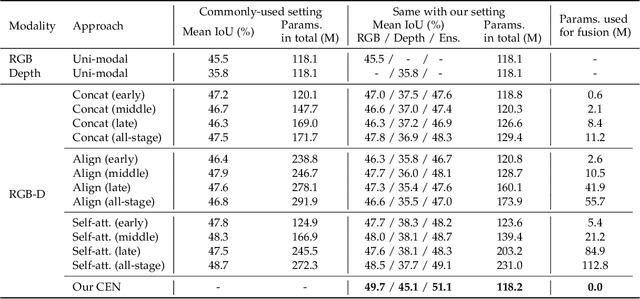
Multimodal fusion and multitask learning are two vital topics in machine learning. Despite the fruitful progress, existing methods for both problems are still brittle to the same challenge -- it remains dilemmatic to integrate the common information across modalities (resp. tasks) meanwhile preserving the specific patterns of each modality (resp. task). Besides, while they are actually closely related to each other, multimodal fusion and multitask learning are rarely explored within the same methodological framework before. In this paper, we propose Channel-Exchanging-Network (CEN) which is self-adaptive, parameter-free, and more importantly, applicable for both multimodal fusion and multitask learning. At its core, CEN dynamically exchanges channels between subnetworks of different modalities. Specifically, the channel exchanging process is self-guided by individual channel importance that is measured by the magnitude of Batch-Normalization (BN) scaling factor during training. For the application of dense image prediction, the validity of CEN is tested by four different scenarios: multimodal fusion, cycle multimodal fusion, multitask learning, and multimodal multitask learning. Extensive experiments on semantic segmentation via RGB-D data and image translation through multi-domain input verify the effectiveness of our CEN compared to current state-of-the-art methods. Detailed ablation studies have also been carried out, which provably affirm the advantage of each component we propose.
Sub-bit Neural Networks: Learning to Compress and Accelerate Binary Neural Networks
Oct 18, 2021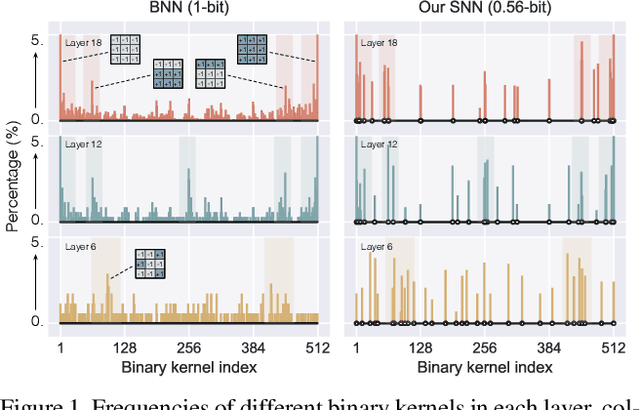
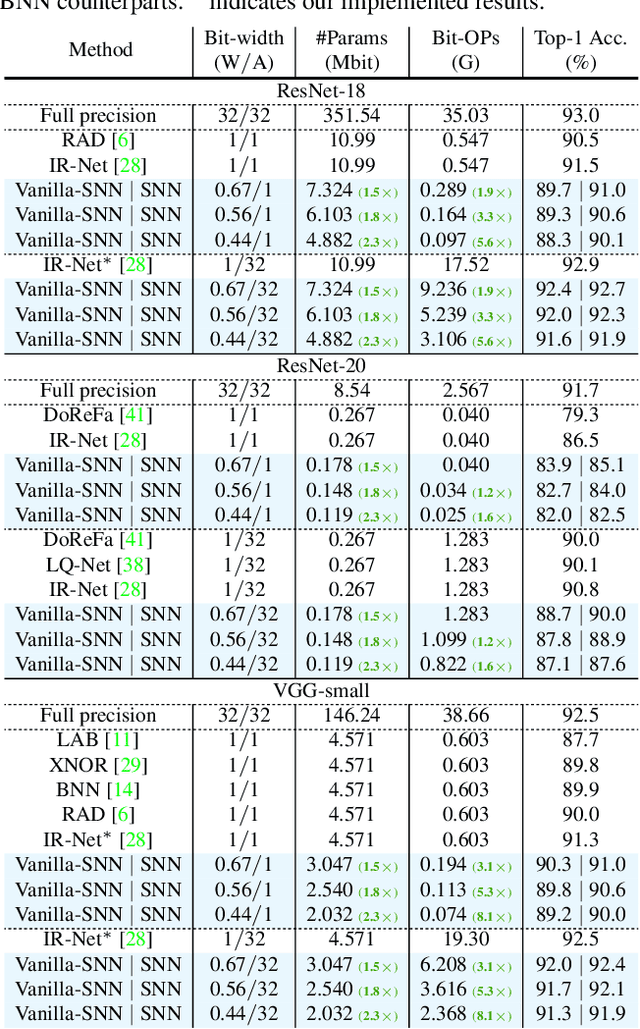
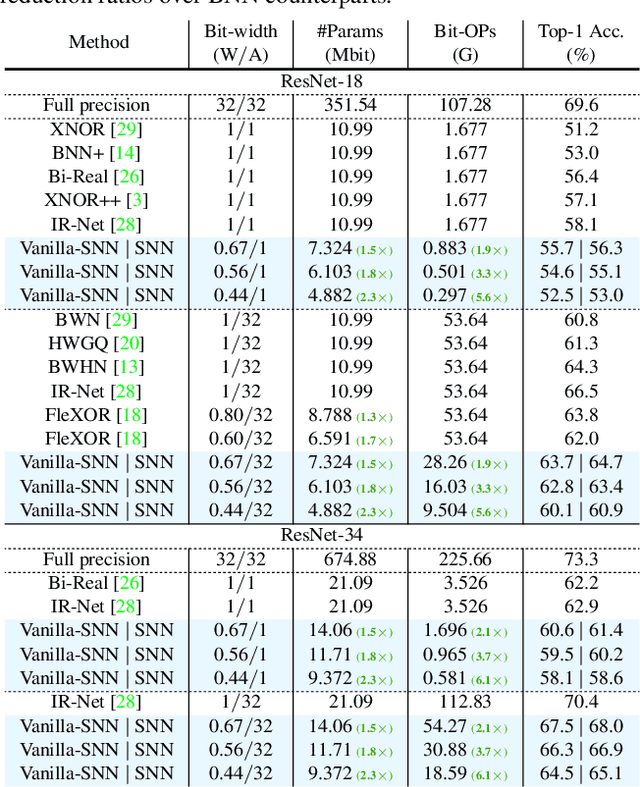
In the low-bit quantization field, training Binary Neural Networks (BNNs) is the extreme solution to ease the deployment of deep models on resource-constrained devices, having the lowest storage cost and significantly cheaper bit-wise operations compared to 32-bit floating-point counterparts. In this paper, we introduce Sub-bit Neural Networks (SNNs), a new type of binary quantization design tailored to compress and accelerate BNNs. SNNs are inspired by an empirical observation, showing that binary kernels learnt at convolutional layers of a BNN model are likely to be distributed over kernel subsets. As a result, unlike existing methods that binarize weights one by one, SNNs are trained with a kernel-aware optimization framework, which exploits binary quantization in the fine-grained convolutional kernel space. Specifically, our method includes a random sampling step generating layer-specific subsets of the kernel space, and a refinement step learning to adjust these subsets of binary kernels via optimization. Experiments on visual recognition benchmarks and the hardware deployment on FPGA validate the great potentials of SNNs. For instance, on ImageNet, SNNs of ResNet-18/ResNet-34 with 0.56-bit weights achieve 3.13/3.33 times runtime speed-up and 1.8 times compression over conventional BNNs with moderate drops in recognition accuracy. Promising results are also obtained when applying SNNs to binarize both weights and activations. Our code is available at https://github.com/yikaiw/SNN.
Audio-Visual Grounding Referring Expression for Robotic Manipulation
Sep 22, 2021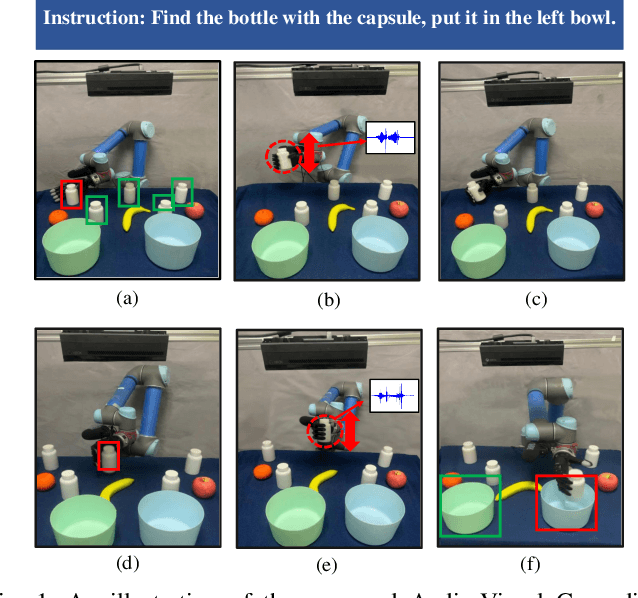
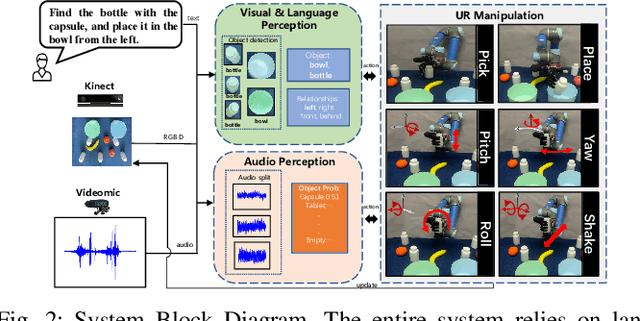
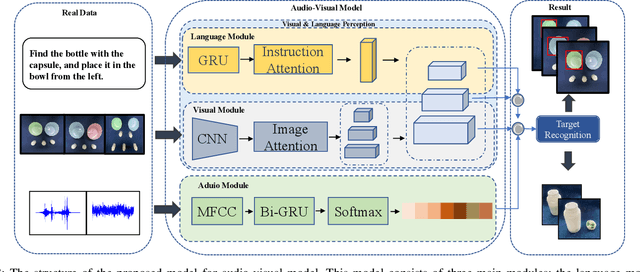

Referring expressions are commonly used when referring to a specific target in people's daily dialogue. In this paper, we develop a novel task of audio-visual grounding referring expression for robotic manipulation. The robot leverages both the audio and visual information to understand the referring expression in the given manipulation instruction and the corresponding manipulations are implemented. To solve the proposed task, an audio-visual framework is proposed for visual localization and sound recognition. We have also established a dataset which contains visual data, auditory data and manipulation instructions for evaluation. Finally, extensive experiments are conducted both offline and online to verify the effectiveness of the proposed audio-visual framework. And it is demonstrated that the robot performs better with the audio-visual data than with only the visual data.
Multi-Agent Embodied Visual Semantic Navigation with Scene Prior Knowledge
Sep 20, 2021
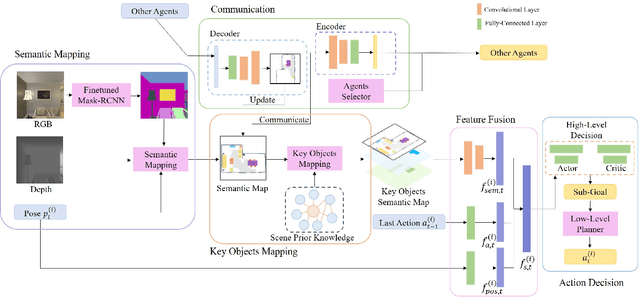
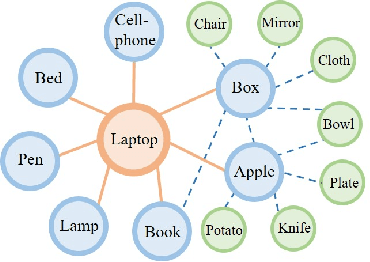

In visual semantic navigation, the robot navigates to a target object with egocentric visual observations and the class label of the target is given. It is a meaningful task inspiring a surge of relevant research. However, most of the existing models are only effective for single-agent navigation, and a single agent has low efficiency and poor fault tolerance when completing more complicated tasks. Multi-agent collaboration can improve the efficiency and has strong application potentials. In this paper, we propose the multi-agent visual semantic navigation, in which multiple agents collaborate with others to find multiple target objects. It is a challenging task that requires agents to learn reasonable collaboration strategies to perform efficient exploration under the restrictions of communication bandwidth. We develop a hierarchical decision framework based on semantic mapping, scene prior knowledge, and communication mechanism to solve this task. The results of testing experiments in unseen scenes with both known objects and unknown objects illustrate the higher accuracy and efficiency of the proposed model compared with the single-agent model.
Knowledge-based Embodied Question Answering
Sep 16, 2021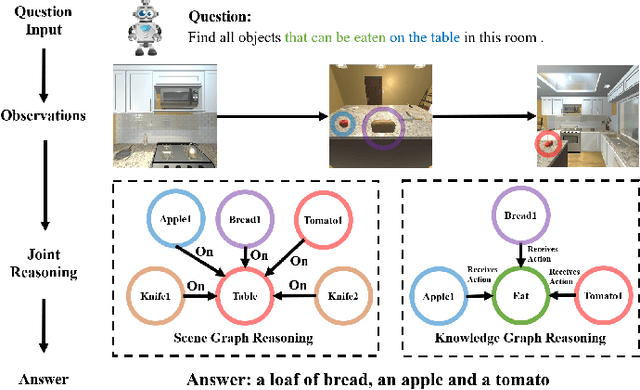


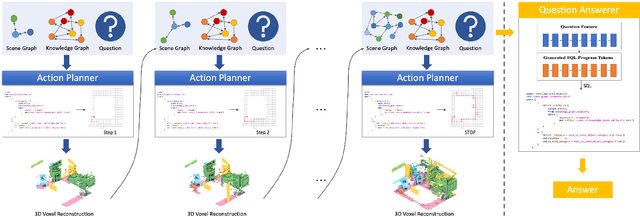
In this paper, we propose a novel Knowledge-based Embodied Question Answering (K-EQA) task, in which the agent intelligently explores the environment to answer various questions with the knowledge. Different from explicitly specifying the target object in the question as existing EQA work, the agent can resort to external knowledge to understand more complicated question such as "Please tell me what are objects used to cut food in the room?", in which the agent must know the knowledge such as "knife is used for cutting food". To address this K-EQA problem, a novel framework based on neural program synthesis reasoning is proposed, where the joint reasoning of the external knowledge and 3D scene graph is performed to realize navigation and question answering. Especially, the 3D scene graph can provide the memory to store the visual information of visited scenes, which significantly improves the efficiency for the multi-turn question answering. Experimental results have demonstrated that the proposed framework is capable of answering more complicated and realistic questions in the embodied environment. The proposed method is also applicable to multi-agent scenarios.
Elastic Tactile Simulation Towards Tactile-Visual Perception
Aug 12, 2021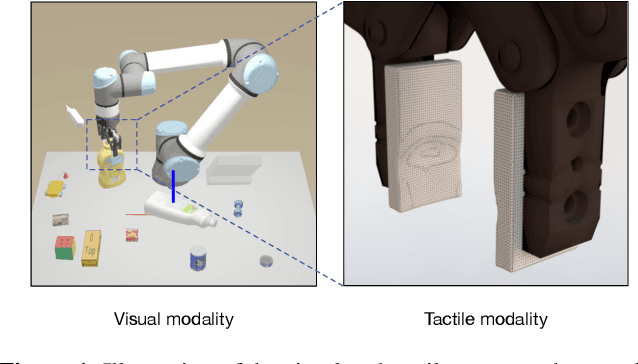
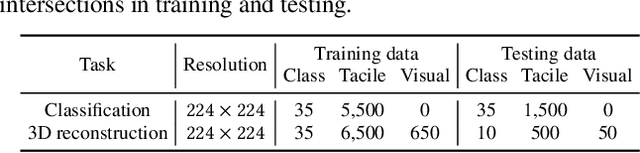


Tactile sensing plays an important role in robotic perception and manipulation tasks. To overcome the real-world limitations of data collection, simulating tactile response in a virtual environment comes as a desirable direction of robotic research. In this paper, we propose Elastic Interaction of Particles (EIP) for tactile simulation. Most existing works model the tactile sensor as a rigid multi-body, which is incapable of reflecting the elastic property of the tactile sensor as well as characterizing the fine-grained physical interaction between the two objects. By contrast, EIP models the tactile sensor as a group of coordinated particles, and the elastic property is applied to regulate the deformation of particles during contact. With the tactile simulation by EIP, we further propose a tactile-visual perception network that enables information fusion between tactile data and visual images. The perception network is based on a global-to-local fusion mechanism where multi-scale tactile features are aggregated to the corresponding local region of the visual modality with the guidance of tactile positions and directions. The fusion method exhibits superiority regarding the 3D geometric reconstruction task.
Learning Deep Multimodal Feature Representation with Asymmetric Multi-layer Fusion
Aug 11, 2021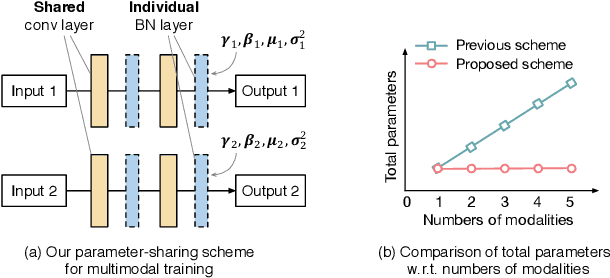
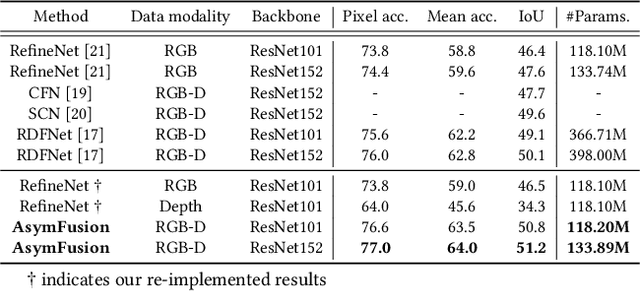
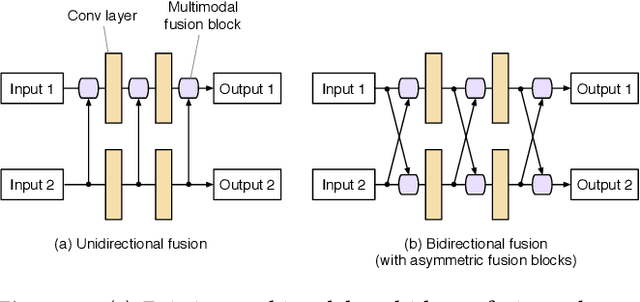
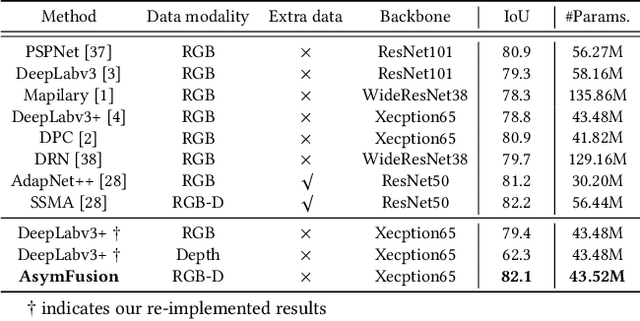
We propose a compact and effective framework to fuse multimodal features at multiple layers in a single network. The framework consists of two innovative fusion schemes. Firstly, unlike existing multimodal methods that necessitate individual encoders for different modalities, we verify that multimodal features can be learnt within a shared single network by merely maintaining modality-specific batch normalization layers in the encoder, which also enables implicit fusion via joint feature representation learning. Secondly, we propose a bidirectional multi-layer fusion scheme, where multimodal features can be exploited progressively. To take advantage of such scheme, we introduce two asymmetric fusion operations including channel shuffle and pixel shift, which learn different fused features with respect to different fusion directions. These two operations are parameter-free and strengthen the multimodal feature interactions across channels as well as enhance the spatial feature discrimination within channels. We conduct extensive experiments on semantic segmentation and image translation tasks, based on three publicly available datasets covering diverse modalities. Results indicate that our proposed framework is general, compact and is superior to state-of-the-art fusion frameworks.
TransSC: Transformer-based Shape Completion for Grasp Evaluation
Jul 01, 2021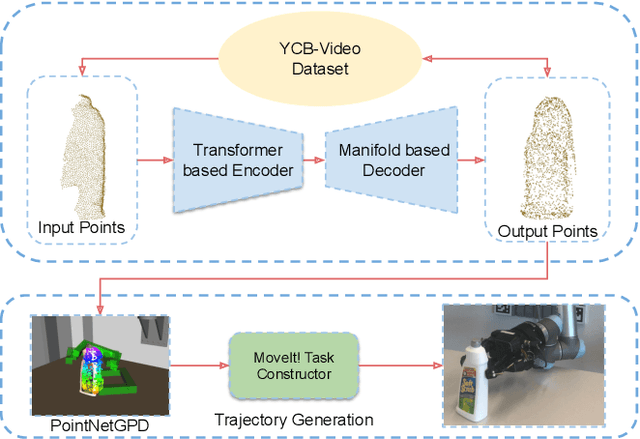
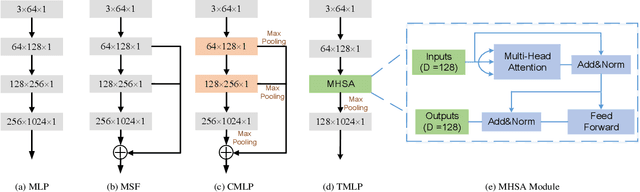
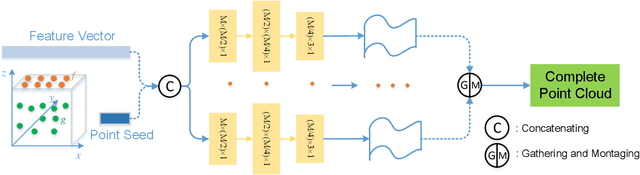
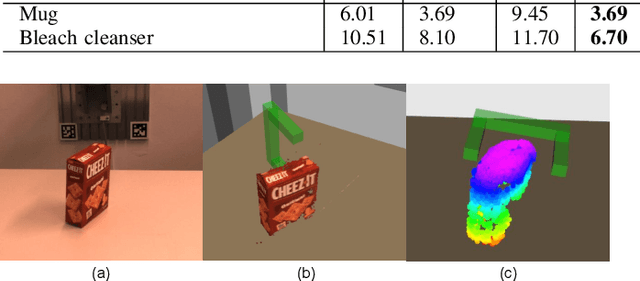
Currently, robotic grasping methods based on sparse partial point clouds have attained a great grasping performance on various objects while they often generate wrong grasping candidates due to the lack of geometric information on the object. In this work, we propose a novel and robust shape completion model (TransSC). This model has a transformer-based encoder to explore more point-wise features and a manifold-based decoder to exploit more object details using a partial point cloud as input. Quantitative experiments verify the effectiveness of the proposed shape completion network and demonstrate it outperforms existing methods. Besides, TransSC is integrated into a grasp evaluation network to generate a set of grasp candidates. The simulation experiment shows that TransSC improves the grasping generation result compared to the existing shape completion baselines. Furthermore, our robotic experiment shows that with TransSC the robot is more successful in grasping objects that are randomly placed on a support surface.