 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatticeWorld: A Multimodal Large Language Model-Empowered Framework for Interactive Complex World Generation
Sep 05, 2025



Recent research has been increasingly focusing on developing 3D world models that simulate complex real-world scenarios. World models have found broad applications across various domains, including embodied AI, autonomous driving, entertainment, etc. A more realistic simulation with accurate physics will effectively narrow the sim-to-real gap and allow us to gather rich information about the real world conveniently. While traditional manual modeling has enabled the creation of virtual 3D scenes, modern approaches have leveraged advanced machine learning algorithms for 3D world generation, with most recent advances focusing on generative methods that can create virtual worlds based on user instructions. This work explores such a research direction by proposing LatticeWorld, a simple yet effective 3D world generation framework that streamlines the industrial production pipeline of 3D environments. LatticeWorld leverages lightweight LLMs (LLaMA-2-7B) alongside the industry-grade rendering engine (e.g., Unreal Engine 5) to generate a dynamic environment. Our proposed framework accepts textual descriptions and visual instructions as multimodal inputs and creates large-scale 3D interactive worlds with dynamic agents, featuring competitive multi-agent interaction, high-fidelity physics simulation, and real-time rendering. We conduct comprehensive experiments to evaluate LatticeWorld, showing that it achieves superior accuracy in scene layout generation and visual fidelity. Moreover, LatticeWorld achieves over a $90\times$ increase in industrial production efficiency while maintaining high creative quality compared with traditional manual production methods. Our demo video is available at https://youtu.be/8VWZXpERR18
EMind: A Foundation Model for Multi-task Electromagnetic Signals Understanding
Aug 26, 2025



Deep understanding of electromagnetic signals is fundamental to dynamic spectrum management, intelligent transportation, autonomous driving and unmanned vehicle perception. The field faces challenges because electromagnetic signals differ greatly from text and images, showing high heterogeneity, strong background noise and complex joint time frequency structure, which prevents existing general models from direct use. Electromagnetic communication and sensing tasks are diverse, current methods lack cross task generalization and transfer efficiency, and the scarcity of large high quality datasets blocks the creation of a truly general multitask learning framework. To overcome these issue, we introduce EMind, an electromagnetic signals foundation model that bridges large scale pretraining and the unique nature of this modality. We build the first unified and largest standardized electromagnetic signal dataset covering multiple signal types and tasks. By exploiting the physical properties of electromagnetic signals, we devise a length adaptive multi-signal packing method and a hardware-aware training strategy that enable efficient use and representation learning from heterogeneous multi-source signals. Experiments show that EMind achieves strong performance and broad generalization across many downstream tasks, moving decisively from task specific models to a unified framework for electromagnetic intelligence. The code is available at: https://github.com/GabrielleTse/EMind.
RIS-MAE: A Self-Supervised Modulation Classification Method Based on Raw IQ Signals and Masked Autoencoder
Aug 01, 2025Automatic modulation classification (AMC) is a basic technology in intelligent wireless communication systems. It is important for tasks such as spectrum monitoring, cognitive radio, and secure communications. In recent years, deep learning methods have made great progress in AMC. However, mainstream methods still face two key problems. First, they often use time-frequency images instead of raw signals. This causes loss of key modulation features and reduces adaptability to different communication conditions. Second, most methods rely on supervised learning. This needs a large amount of labeled data, which is hard to get in real-world environments. To solve these problems, we propose a self-supervised learning framework called RIS-MAE. RIS-MAE uses masked autoencoders to learn signal features from unlabeled data. It takes raw IQ sequences as input. By applying random masking and reconstruction, it captures important time-domain features such as amplitude, phase, etc. This helps the model learn useful and transferable representations. RIS-MAE is tested on four datasets. The results show that it performs better than existing methods in few-shot and cross-domain tasks. Notably, it achieves high classification accuracy on previously unseen datasets with only a small number of fine-tuning samples, confirming its generalization ability and potential for real-world deployment.
Leveraging Large Language Model for Heterogeneous Ad Hoc Teamwork Collaboration
Jun 18, 2024



Compared with the widely investigated homogeneous multi-robot collaboration, heterogeneous robots with different capabilities can provide a more efficient and flexible collaboration for more complex tasks. In this paper, we consider a more challenging heterogeneous ad hoc teamwork collaboration problem where an ad hoc robot joins an existing heterogeneous team for a shared goal. Specifically, the ad hoc robot collaborates with unknown teammates without prior coordination, and it is expected to generate an appropriate cooperation policy to improve the efficiency of the whole team. To solve this challenging problem, we leverage the remarkable potential of the large language model (LLM) to establish a decentralized heterogeneous ad hoc teamwork collaboration framework that focuses on generating reasonable policy for an ad hoc robot to collaborate with original heterogeneous teammates. A training-free hierarchical dynamic planner is developed using the LLM together with the newly proposed Interactive Reflection of Thoughts (IRoT) method for the ad hoc agent to adapt to different teams. We also build a benchmark testing dataset to evaluate the proposed framework in the heterogeneous ad hoc multi-agent tidying-up task. Extensive comparison and ablation experiments are conducted in the benchmark to demonstrate the effectiveness of the proposed framework. We have also employed the proposed framework in physical robots in a real-world scenario. The experimental videos can be found at https://youtu.be/wHYP5T2WIp0.
Heterogeneous Embodied Multi-Agent Collaboration
Jul 27, 2023



Multi-agent embodied tasks have recently been studied in complex indoor visual environments. Collaboration among multiple agents can improve work efficiency and has significant practical value. However, most of the existing research focuses on homogeneous multi-agent tasks. Compared with homogeneous agents, heterogeneous agents can leverage their different capabilities to allocate corresponding sub-tasks and cooperate to complete complex tasks. Heterogeneous multi-agent tasks are common in real-world scenarios, and the collaboration strategy among heterogeneous agents is a challenging and important problem to be solved. To study collaboration among heterogeneous agents, we propose the heterogeneous multi-agent tidying-up task, in which multiple heterogeneous agents with different capabilities collaborate with each other to detect misplaced objects and place them in reasonable locations. This is a demanding task since it requires agents to make the best use of their different capabilities to conduct reasonable task planning and complete the whole task. To solve this task, we build a heterogeneous multi-agent tidying-up benchmark dataset in a large number of houses with multiple rooms based on ProcTHOR-10K. We propose the hierarchical decision model based on misplaced object detection, reasonable receptacle prediction, as well as the handshake-based group communication mechanism. Extensive experiments are conducted to demonstrate the effectiveness of the proposed model. The project's website and videos of experiments can be found at https://hetercol.github.io/.
Multi-Agent Embodied Visual Semantic Navigation with Scene Prior Knowledge
Sep 20, 2021
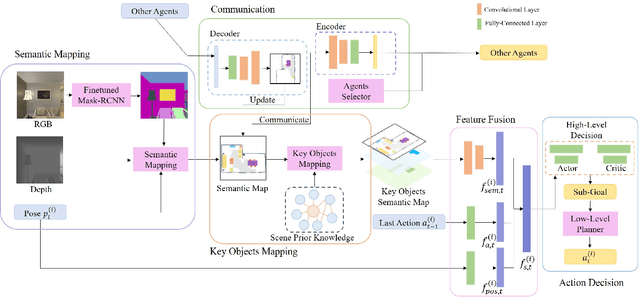
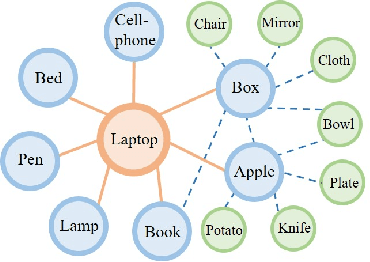

In visual semantic navigation, the robot navigates to a target object with egocentric visual observations and the class label of the target is given. It is a meaningful task inspiring a surge of relevant research. However, most of the existing models are only effective for single-agent navigation, and a single agent has low efficiency and poor fault tolerance when completing more complicated tasks. Multi-agent collaboration can improve the efficiency and has strong application potentials. In this paper, we propose the multi-agent visual semantic navigation, in which multiple agents collaborate with others to find multiple target objects. It is a challenging task that requires agents to learn reasonable collaboration strategies to perform efficient exploration under the restrictions of communication bandwidth. We develop a hierarchical decision framework based on semantic mapping, scene prior knowledge, and communication mechanism to solve this task. The results of testing experiments in unseen scenes with both known objects and unknown objects illustrate the higher accuracy and efficiency of the proposed model compared with the single-agent model.