 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLay: Controllable Layout Generation through Multi-conditional Latent Diffusion
May 18, 2024



Layout design generation has recently gained significant attention due to its potential applications in various fields, including UI, graphic, and floor plan design. However, existing models face two main challenges that limits their adoption in practice. Firstly, the limited expressiveness of individual condition types used in previous works restricts designers' ability to convey complex design intentions and constraints. Secondly, most existing models focus on generating labels and coordinates, while real layouts contain a range of style properties. To address these limitations, we propose a novel framework, CoLay, that integrates multiple condition types and generates complex layouts with diverse style properties. Our approach outperforms prior works in terms of generation quality and condition satisfaction while empowering users to express their design intents using a flexible combination of modalities, including natural language prompts, layout guidelines, element types, and partially completed designs.
Leveraging Human Revisions for Improving Text-to-Layout Models
May 16, 2024



Learning from human feedback has shown success in aligning large, pretrained models with human values. Prior works have mostly focused on learning from high-level labels, such as preferences between pairs of model outputs. On the other hand, many domains could benefit from more involved, detailed feedback, such as revisions, explanations, and reasoning of human users. Our work proposes using nuanced feedback through the form of human revisions for stronger alignment. In this paper, we ask expert designers to fix layouts generated from a generative layout model that is pretrained on a large-scale dataset of mobile screens. Then, we train a reward model based on how human designers revise these generated layouts. With the learned reward model, we optimize our model with reinforcement learning from human feedback (RLHF). Our method, Revision-Aware Reward Models ($\method$), allows a generative text-to-layout model to produce more modern, designer-aligned layouts, showing the potential for utilizing human revisions and stronger forms of feedback in improving generative models.
A-Scan2BIM: Assistive Scan to Building Information Modeling
Nov 30, 2023



This paper proposes an assistive system for architects that converts a large-scale point cloud into a standardized digital representation of a building for Building Information Modeling (BIM) applications. The process is known as Scan-to-BIM, which requires many hours of manual work even for a single building floor by a professional architect. Given its challenging nature, the paper focuses on helping architects on the Scan-to-BIM process, instead of replacing them. Concretely, we propose an assistive Scan-to-BIM system that takes the raw sensor data and edit history (including the current BIM model), then auto-regressively predicts a sequence of model editing operations as APIs of a professional BIM software (i.e., Autodesk Revit). The paper also presents the first building-scale Scan2BIM dataset that contains a sequence of model editing operations as the APIs of Autodesk Revit. The dataset contains 89 hours of Scan2BIM modeling processes by professional architects over 16 scenes, spanning over 35,000 m^2. We report our system's reconstruction quality with standard metrics, and we introduce a novel metric that measures how natural the order of reconstructed operations is. A simple modification to the reconstruction module helps improve performance, and our method is far superior to two other baselines in the order metric. We will release data, code, and models at a-scan2bim.github.io.
Representation Learning for Sequential Volumetric Design Tasks
Sep 05, 2023



Volumetric design, also called massing design, is the first and critical step in professional building design which is sequential in nature. As the volumetric design process is complex, the underlying sequential design process encodes valuable information for designers. Many efforts have been made to automatically generate reasonable volumetric designs, but the quality of the generated design solutions varies, and evaluating a design solution requires either a prohibitively comprehensive set of metrics or expensive human expertise. While previous approaches focused on learning only the final design instead of sequential design tasks, we propose to encode the design knowledge from a collection of expert or high-performing design sequences and extract useful representations using transformer-based models. Later we propose to utilize the learned representations for crucial downstream applications such as design preference evaluation and procedural design generation. We develop the preference model by estimating the density of the learned representations whereas we train an autoregressive transformer model for sequential design generation. We demonstrate our ideas by leveraging a novel dataset of thousands of sequential volumetric designs. Our preference model can compare two arbitrarily given design sequences and is almost 90% accurate in evaluation against random design sequences. Our autoregressive model is also capable of autocompleting a volumetric design sequence from a partial design sequence.
IKEA-Manual: Seeing Shape Assembly Step by Step
Feb 03, 2023



Human-designed visual manuals are crucial components in shape assembly activities. They provide step-by-step guidance on how we should move and connect different parts in a convenient and physically-realizable way. While there has been an ongoing effort in building agents that perform assembly tasks, the information in human-design manuals has been largely overlooked. We identify that this is due to 1) a lack of realistic 3D assembly objects that have paired manuals and 2) the difficulty of extracting structured information from purely image-based manuals. Motivated by this observation, we present IKEA-Manual, a dataset consisting of 102 IKEA objects paired with assembly manuals. We provide fine-grained annotations on the IKEA objects and assembly manuals, including decomposed assembly parts, assembly plans, manual segmentation, and 2D-3D correspondence between 3D parts and visual manuals. We illustrate the broad application of our dataset on four tasks related to shape assembly: assembly plan generation, part segmentation, pose estimation, and 3D part assembly.
PLay: Parametrically Conditioned Layout Generation using Latent Diffusion
Jan 27, 2023



Layout design is an important task in various design fields, including user interfaces, document, and graphic design. As this task requires tedious manual effort by designers, prior works have attempted to automate this process using generative models, but commonly fell short of providing intuitive user controls and achieving design objectives. In this paper, we build a conditional latent diffusion model, PLay, that generates parametrically conditioned layouts in vector graphic space from user-specified guidelines, which are commonly used by designers for representing their design intents in current practices. Our method outperforms prior works across three datasets on metrics including FID and FD-VG, and in user test. Moreover, it brings a novel and interactive experience to professional layout design processes.
Translating a Visual LEGO Manual to a Machine-Executable Plan
Jul 25, 2022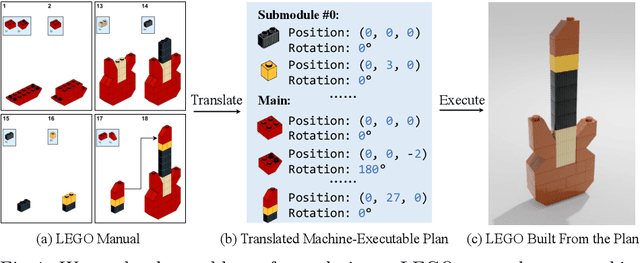
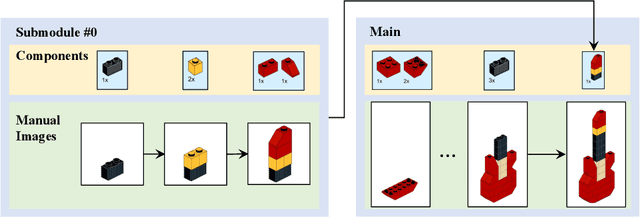
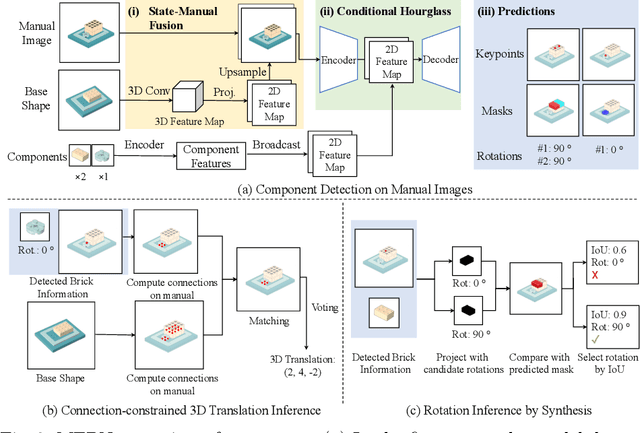
We study the problem of translating an image-based, step-by-step assembly manual created by human designers into machine-interpretable instructions. We formulate this problem as a sequential prediction task: at each step, our model reads the manual, locates the components to be added to the current shape, and infers their 3D poses. This task poses the challenge of establishing a 2D-3D correspondence between the manual image and the real 3D object, and 3D pose estimation for unseen 3D objects, since a new component to be added in a step can be an object built from previous steps. To address these two challenges, we present a novel learning-based framework, the Manual-to-Executable-Plan Network (MEPNet), which reconstructs the assembly steps from a sequence of manual images. The key idea is to integrate neural 2D keypoint detection modules and 2D-3D projection algorithms for high-precision prediction and strong generalization to unseen components. The MEPNet outperforms existing methods on three newly collected LEGO manual datasets and a Minecraft house dataset.
SkexGen: Autoregressive Generation of CAD Construction Sequences with Disentangled Codebooks
Jul 11, 2022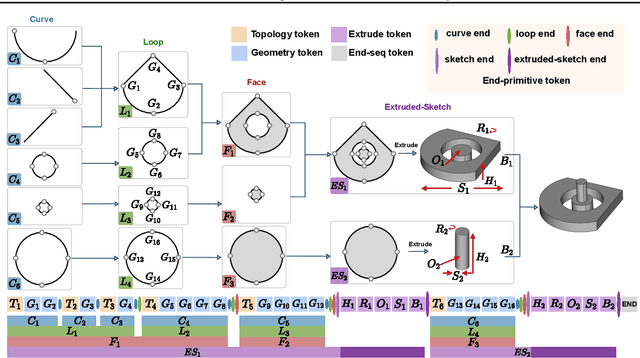
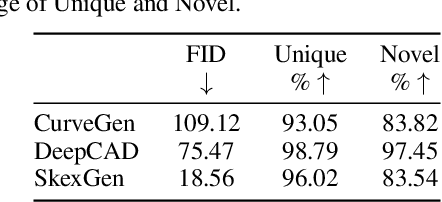
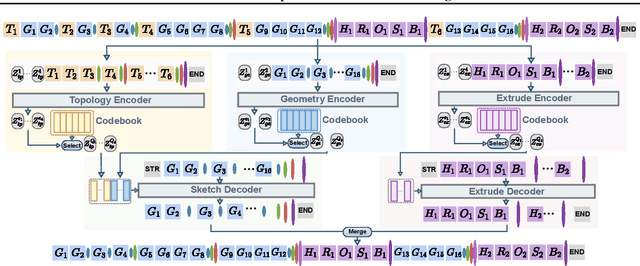
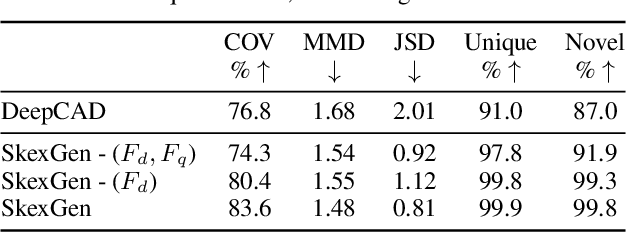
We present SkexGen, a novel autoregressive generative model for computer-aided design (CAD) construction sequences containing sketch-and-extrude modeling operations. Our model utilizes distinct Transformer architectures to encode topological, geometric, and extrusion variations of construction sequences into disentangled codebooks. Autoregressive Transformer decoders generate CAD construction sequences sharing certain properties specified by the codebook vectors. Extensive experiments demonstrate that our disentangled codebook representation generates diverse and high-quality CAD models, enhances user control, and enables efficient exploration of the design space. The code is available at https://samxuxiang.github.io/skexgen.
Multi-Target Filter and Detector for Speaker Diarization
Mar 30, 2022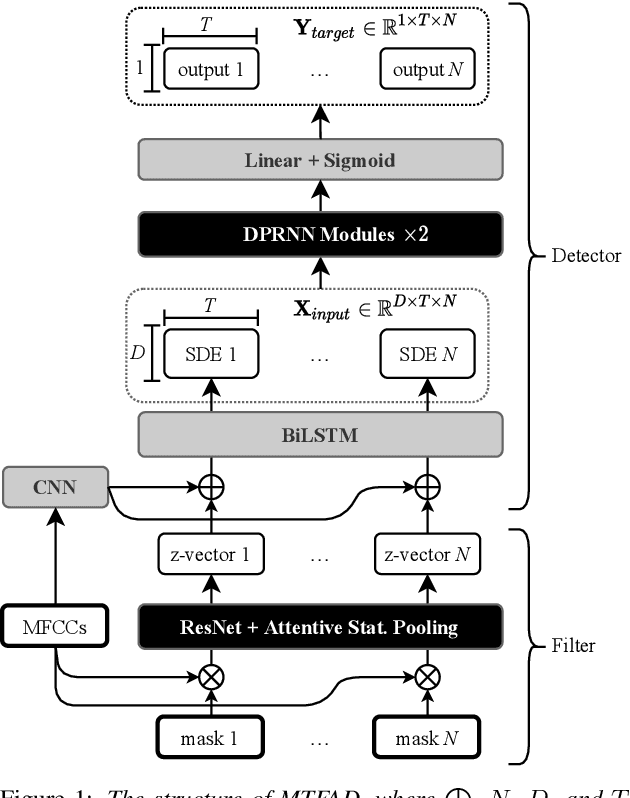
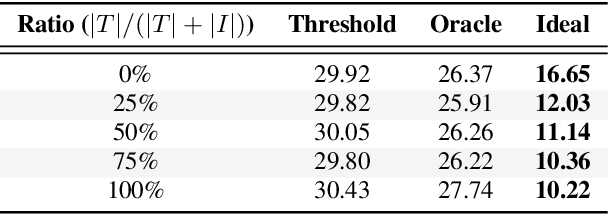
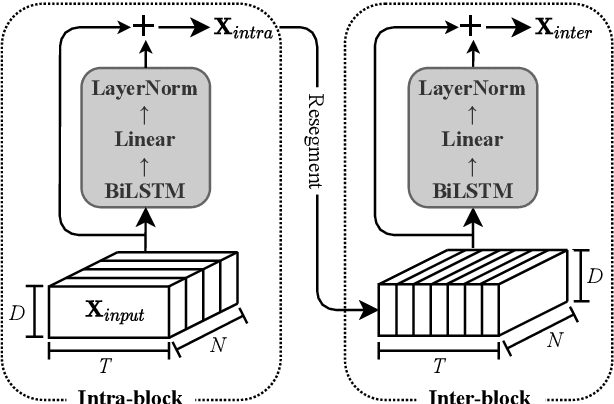
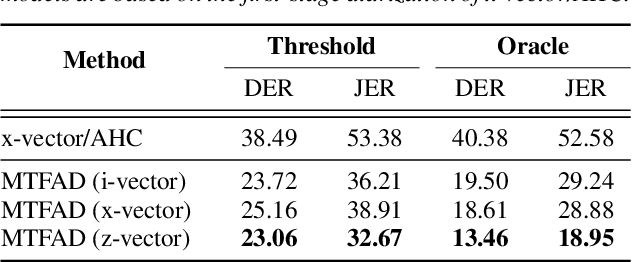
A good representation of a target speaker usually helps to extract important information about the speaker and detect the corresponding temporal regions in a multi-speaker conversation. In this paper, we propose a neural architecture that simultaneously extracts speaker embeddings consistent with the speaker diarization objective and detects the presence of each speaker frame by frame, regardless of the number of speakers in the conversation. To this end, a residual network (ResNet) and a dual-path recurrent neural network (DPRNN) are integrated into a unified structure. When tested on the 2-speaker CALLHOME corpus, our proposed model outperforms most methods published so far. Evaluated in a more challenging case of concurrent speakers ranging from two to seven, our system also achieves relative diarization error rate reductions of 26.35% and 6.4% over two typical baselines, namely the traditional x-vector clustering system and the attention-based system.
CLIP-Forge: Towards Zero-Shot Text-to-Shape Generation
Oct 06, 2021
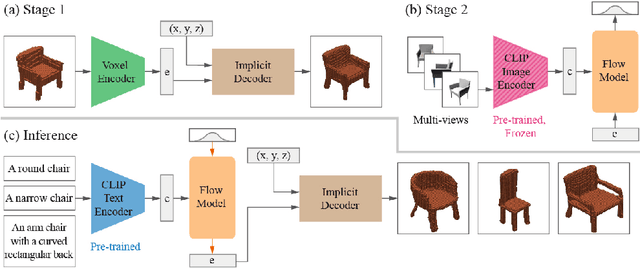


While recent progress has been made in text-to-image generation, text-to-shape generation remains a challenging problem due to the unavailability of paired text and shape data at a large scale. We present a simple yet effective method for zero-shot text-to-shape generation based on a two-stage training process, which only depends on an unlabelled shape dataset and a pre-trained image-text network such as CLIP. Our method not only demonstrates promising zero-shot generalization, but also avoids expensive inference time optimization and can generate multiple shapes for a given text.