 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenDriveVLA: Towards End-to-end Autonomous Driving with Large Vision Language Action Model
Mar 30, 2025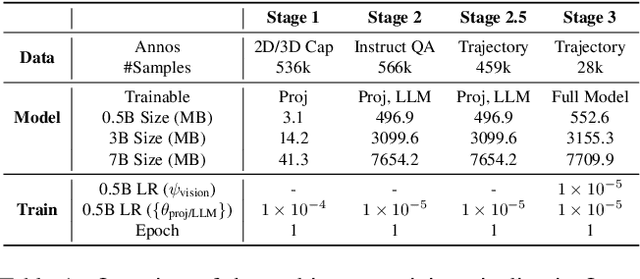
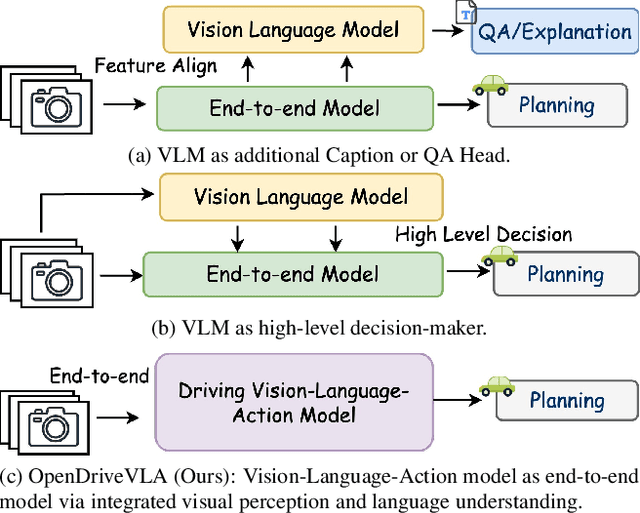
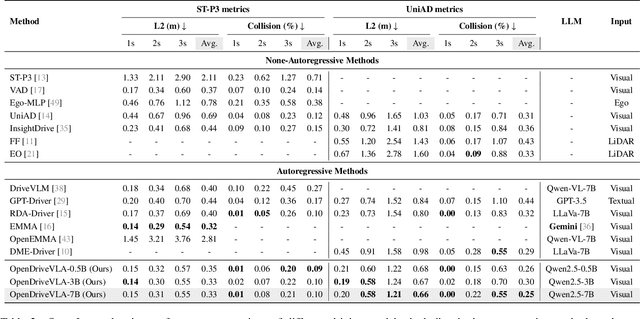
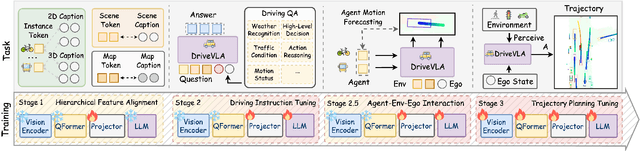
We present OpenDriveVLA, a Vision-Language Action (VLA) model designed for end-to-end autonomous driving. OpenDriveVLA builds upon open-source pre-trained large Vision-Language Models (VLMs) to generate reliable driving actions, conditioned on 3D environmental perception, ego vehicle states, and driver commands. To bridge the modality gap between driving visual representations and language embeddings, we propose a hierarchical vision-language alignment process, projecting both 2D and 3D structured visual tokens into a unified semantic space. Besides, OpenDriveVLA models the dynamic relationships between the ego vehicle, surrounding agents, and static road elements through an autoregressive agent-env-ego interaction process, ensuring both spatially and behaviorally informed trajectory planning. Extensive experiments on the nuScenes dataset demonstrate that OpenDriveVLA achieves state-of-the-art results across open-loop trajectory planning and driving-related question-answering tasks. Qualitative analyses further illustrate OpenDriveVLA's superior capability to follow high-level driving commands and robustly generate trajectories under challenging scenarios, highlighting its potential for next-generation end-to-end autonomous driving. We will release our code to facilitate further research in this domain.
Calibrated Multi-Preference Optimization for Aligning Diffusion Models
Feb 04, 2025



Aligning text-to-image (T2I) diffusion models with preference optimization is valuable for human-annotated datasets, but the heavy cost of manual data collection limits scalability. Using reward models offers an alternative, however, current preference optimization methods fall short in exploiting the rich information, as they only consider pairwise preference distribution. Furthermore, they lack generalization to multi-preference scenarios and struggle to handle inconsistencies between rewards. To address this, we present Calibrated Preference Optimization (CaPO), a novel method to align T2I diffusion models by incorporating the general preference from multiple reward models without human annotated data. The core of our approach involves a reward calibration method to approximate the general preference by computing the expected win-rate against the samples generated by the pretrained models. Additionally, we propose a frontier-based pair selection method that effectively manages the multi-preference distribution by selecting pairs from Pareto frontiers. Finally, we use regression loss to fine-tune diffusion models to match the difference between calibrated rewards of a selected pair. Experimental results show that CaPO consistently outperforms prior methods, such as Direct Preference Optimization (DPO), in both single and multi-reward settings validated by evaluation on T2I benchmarks, including GenEval and T2I-Compbench.
Psychometric-Based Evaluation for Theorem Proving with Large Language Models
Feb 02, 2025



Large language models (LLMs) for formal theorem proving have become a prominent research focus. At present, the proving ability of these LLMs is mainly evaluated through proof pass rates on datasets such as miniF2F. However, this evaluation method overlooks the varying importance of theorems. As a result, it fails to highlight the real performance disparities between LLMs and leads to high evaluation costs. This study proposes a psychometric-based evaluation method for theorem proving with LLMs, comprising two main components: Dataset Annotation and Adaptive Evaluation. First, we propose a metric calculation method to annotate the dataset with difficulty and discrimination metrics. Specifically, we annotate each theorem in the miniF2F dataset and grade them into varying difficulty levels according to the performance of LLMs, resulting in an enhanced dataset: miniF2F-Graded. Experimental results show that the difficulty grading in miniF2F-Graded better reflects the theorem difficulty perceived by LLMs. Secondly, we design an adaptive evaluation method to dynamically select the most suitable theorems for testing based on the annotated metrics and the real-time performance of LLMs. We apply this method to evaluate 10 LLMs. The results show that our method finely highlights the performance disparities between LLMs. It also reduces evaluation costs by using only 23% of the theorems in the dataset.
Focus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025



Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
HV-BEV: Decoupling Horizontal and Vertical Feature Sampling for Multi-View 3D Object Detection
Dec 25, 2024



The application of vision-based multi-view environmental perception system has been increasingly recognized in autonomous driving technology, especially the BEV-based models. Current state-of-the-art solutions primarily encode image features from each camera view into the BEV space through explicit or implicit depth prediction. However, these methods often focus on improving the accuracy of projecting 2D features into corresponding depth regions, while overlooking the highly structured information of real-world objects and the varying height distributions of objects across different scenes. In this work, we propose HV-BEV, a novel approach that decouples feature sampling in the BEV grid queries paradigm into horizontal feature aggregation and vertical adaptive height-aware reference point sampling, aiming to improve both the aggregation of objects' complete information and generalization to diverse road environments. Specifically, we construct a learnable graph structure in the horizontal plane aligned with the ground for 3D reference points, reinforcing the association of the same instance across different BEV grids, especially when the instance spans multiple image views around the vehicle. Additionally, instead of relying on uniform sampling within a fixed height range, we introduce a height-aware module that incorporates historical information, enabling the reference points to adaptively focus on the varying heights at which objects appear in different scenes. Extensive experiments validate the effectiveness of our proposed method, demonstrating its superior performance over the baseline across the nuScenes dataset. Moreover, our best-performing model achieves a remarkable 50.5% mAP and 59.8% NDS on the nuScenes testing set.
LVMark: Robust Watermark for latent video diffusion models
Dec 12, 2024Rapid advancements in generative models have made it possible to create hyper-realistic videos. As their applicability increases, their unauthorized use has raised significant concerns, leading to the growing demand for techniques to protect the ownership of the generative model itself. While existing watermarking methods effectively embed watermarks into image-generative models, they fail to account for temporal information, resulting in poor performance when applied to video-generative models. To address this issue, we introduce a novel watermarking method called LVMark, which embeds watermarks into video diffusion models. A key component of LVMark is a selective weight modulation strategy that efficiently embeds watermark messages into the video diffusion model while preserving the quality of the generated videos. To accurately decode messages in the presence of malicious attacks, we design a watermark decoder that leverages spatio-temporal information in the 3D wavelet domain through a cross-attention module. To the best of our knowledge, our approach is the first to highlight the potential of video-generative model watermarking as a valuable tool for enhancing the effectiveness of ownership protection in video-generative models.
Motion Artifact Removal in Pixel-Frequency Domain via Alternate Masks and Diffusion Model
Dec 10, 2024Motion artifacts present in magnetic resonance imaging (MRI) can seriously interfere with clinical diagnosis. Removing motion artifacts is a straightforward solution and has been extensively studied. However, paired data are still heavily relied on in recent works and the perturbations in \textit{k}-space (frequency domain) are not well considered, which limits their applications in the clinical field. To address these issues, we propose a novel unsupervised purification method which leverages pixel-frequency information of noisy MRI images to guide a pre-trained diffusion model to recover clean MRI images. Specifically, considering that motion artifacts are mainly concentrated in high-frequency components in \textit{k}-space, we utilize the low-frequency components as the guide to ensure correct tissue textures. Additionally, given that high-frequency and pixel information are helpful for recovering shape and detail textures, we design alternate complementary masks to simultaneously destroy the artifact structure and exploit useful information. Quantitative experiments are performed on datasets from different tissues and show that our method achieves superior performance on several metrics. Qualitative evaluations with radiologists also show that our method provides better clinical feedback. Our code is available at https://github.com/medcx/PFAD.
FastTrackTr:Towards Fast Multi-Object Tracking with Transformers
Nov 24, 2024



Transformer-based multi-object tracking (MOT) methods have captured the attention of many researchers in recent years. However, these models often suffer from slow inference speeds due to their structure or other issues. To address this problem, we revisited the Joint Detection and Tracking (JDT) method by looking back at past approaches. By integrating the original JDT approach with some advanced theories, this paper employs an efficient method of information transfer between frames on the DETR, constructing a fast and novel JDT-type MOT framework: FastTrackTr. Thanks to the superiority of this information transfer method, our approach not only reduces the number of queries required during tracking but also avoids the excessive introduction of network structures, ensuring model simplicity. Experimental results indicate that our method has the potential to achieve real-time tracking and exhibits competitive tracking accuracy across multiple datasets.
Multi-object Tracking by Detection and Query: an efficient end-to-end manner
Nov 09, 2024



Multi-object tracking is advancing through two dominant paradigms: traditional tracking by detection and newly emerging tracking by query. In this work, we fuse them together and propose the tracking-by-detection-and-query paradigm, which is achieved by a Learnable Associator. Specifically, the basic information interaction module and the content-position alignment module are proposed for thorough information Interaction among object queries. Tracking results are directly Decoded from these queries. Hence, we name the method as LAID. Compared to tracking-by-query models, LAID achieves competitive tracking accuracy with notably higher training efficiency. With regard to tracking-by-detection methods, experimental results on DanceTrack show that LAID significantly surpasses the state-of-the-art heuristic method by 3.9% on HOTA metric and 6.1% on IDF1 metric. On SportsMOT, LAID also achieves the best score on HOTA metric. By holding low training cost, strong tracking capabilities, and an elegant end-to-end approach all at once, LAID presents a forward-looking direction for the field.
Towards Student Actions in Classroom Scenes: New Dataset and Baseline
Sep 02, 2024



Analyzing student actions is an important and challenging task in educational research. Existing efforts have been hampered by the lack of accessible datasets to capture the nuanced action dynamics in classrooms. In this paper, we present a new multi-label student action video (SAV) dataset for complex classroom scenes. The dataset consists of 4,324 carefully trimmed video clips from 758 different classrooms, each labeled with 15 different actions displayed by students in classrooms. Compared to existing behavioral datasets, our dataset stands out by providing a wide range of real classroom scenarios, high-quality video data, and unique challenges, including subtle movement differences, dense object engagement, significant scale differences, varied shooting angles, and visual occlusion. The increased complexity of the dataset brings new opportunities and challenges for benchmarking action detection. Innovatively, we also propose a new baseline method, a visual transformer for enhancing attention to key local details in small and dense object regions. Our method achieves excellent performance with mean Average Precision (mAP) of 67.9\% and 27.4\% on SAV and AVA, respectively. This paper not only provides the dataset but also calls for further research into AI-driven educational tools that may transform teaching methodologies and learning outcomes. The code and dataset will be released at https://github.com/Ritatanz/SAV.