 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCINFormer: Transformer network with multi-stage CNN feature injection for surface defect segmentation
Sep 22, 2023



Surface defect inspection is of great importance for industrial manufacture and production. Though defect inspection methods based on deep learning have made significant progress, there are still some challenges for these methods, such as indistinguishable weak defects and defect-like interference in the background. To address these issues, we propose a transformer network with multi-stage CNN (Convolutional Neural Network) feature injection for surface defect segmentation, which is a UNet-like structure named CINFormer. CINFormer presents a simple yet effective feature integration mechanism that injects the multi-level CNN features of the input image into different stages of the transformer network in the encoder. This can maintain the merit of CNN capturing detailed features and that of transformer depressing noises in the background, which facilitates accurate defect detection. In addition, CINFormer presents a Top-K self-attention module to focus on tokens with more important information about the defects, so as to further reduce the impact of the redundant background. Extensive experiments conducted on the surface defect datasets DAGM 2007, Magnetic tile, and NEU show that the proposed CINFormer achieves state-of-the-art performance in defect detection.
Global Context Aggregation Network for Lightweight Saliency Detection of Surface Defects
Sep 22, 2023



Surface defect inspection is a very challenging task in which surface defects usually show weak appearances or exist under complex backgrounds. Most high-accuracy defect detection methods require expensive computation and storage overhead, making them less practical in some resource-constrained defect detection applications. Although some lightweight methods have achieved real-time inference speed with fewer parameters, they show poor detection accuracy in complex defect scenarios. To this end, we develop a Global Context Aggregation Network (GCANet) for lightweight saliency detection of surface defects on the encoder-decoder structure. First, we introduce a novel transformer encoder on the top layer of the lightweight backbone, which captures global context information through a novel Depth-wise Self-Attention (DSA) module. The proposed DSA performs element-wise similarity in channel dimension while maintaining linear complexity. In addition, we introduce a novel Channel Reference Attention (CRA) module before each decoder block to strengthen the representation of multi-level features in the bottom-up path. The proposed CRA exploits the channel correlation between features at different layers to adaptively enhance feature representation. The experimental results on three public defect datasets demonstrate that the proposed network achieves a better trade-off between accuracy and running efficiency compared with other 17 state-of-the-art methods. Specifically, GCANet achieves competitive accuracy (91.79% $F_{\beta}^{w}$, 93.55% $S_\alpha$, and 97.35% $E_\phi$) on SD-saliency-900 while running 272fps on a single gpu.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
ZeRO++: Extremely Efficient Collective Communication for Giant Model Training
Jun 16, 2023



Zero Redundancy Optimizer (ZeRO) has been used to train a wide range of large language models on massive GPUs clusters due to its ease of use, efficiency, and good scalability. However, when training on low-bandwidth clusters, or at scale which forces batch size per GPU to be small, ZeRO's effective throughput is limited because of high communication volume from gathering weights in forward pass, backward pass, and averaging gradients. This paper introduces three communication volume reduction techniques, which we collectively refer to as ZeRO++, targeting each of the communication collectives in ZeRO. First is block-quantization based all-gather. Second is data remapping that trades-off communication for more memory. Third is a novel all-to-all based quantized gradient averaging paradigm as replacement of reduce-scatter collective, which preserves accuracy despite communicating low precision data. Collectively, ZeRO++ reduces communication volume of ZeRO by 4x, enabling up to 2.16x better throughput at 384 GPU scale.
Bridging the Gap Between End-to-end and Non-End-to-end Multi-Object Tracking
May 22, 2023



Existing end-to-end Multi-Object Tracking (e2e-MOT) methods have not surpassed non-end-to-end tracking-by-detection methods. One potential reason is its label assignment strategy during training that consistently binds the tracked objects with tracking queries and then assigns the few newborns to detection queries. With one-to-one bipartite matching, such an assignment will yield unbalanced training, i.e., scarce positive samples for detection queries, especially for an enclosed scene, as the majority of the newborns come on stage at the beginning of videos. Thus, e2e-MOT will be easier to yield a tracking terminal without renewal or re-initialization, compared to other tracking-by-detection methods. To alleviate this problem, we present Co-MOT, a simple and effective method to facilitate e2e-MOT by a novel coopetition label assignment with a shadow concept. Specifically, we add tracked objects to the matching targets for detection queries when performing the label assignment for training the intermediate decoders. For query initialization, we expand each query by a set of shadow counterparts with limited disturbance to itself. With extensive ablations, Co-MOT achieves superior performance without extra costs, e.g., 69.4% HOTA on DanceTrack and 52.8% TETA on BDD100K. Impressively, Co-MOT only requires 38\% FLOPs of MOTRv2 to attain a similar performance, resulting in the 1.4$\times$ faster inference speed.
Multiple Object Tracking Challenge Technical Report for Team MT_IoT
Dec 07, 2022This is a brief technical report of our proposed method for Multiple-Object Tracking (MOT) Challenge in Complex Environments. In this paper, we treat the MOT task as a two-stage task including human detection and trajectory matching. Specifically, we designed an improved human detector and associated most of detection to guarantee the integrity of the motion trajectory. We also propose a location-wise matching matrix to obtain more accurate trace matching. Without any model merging, our method achieves 66.672 HOTA and 93.971 MOTA on the DanceTrack challenge dataset.
PIDS: Joint Point Interaction-Dimension Search for 3D Point Cloud
Nov 28, 2022The interaction and dimension of points are two important axes in designing point operators to serve hierarchical 3D models. Yet, these two axes are heterogeneous and challenging to fully explore. Existing works craft point operator under a single axis and reuse the crafted operator in all parts of 3D models. This overlooks the opportunity to better combine point interactions and dimensions by exploiting varying geometry/density of 3D point clouds. In this work, we establish PIDS, a novel paradigm to jointly explore point interactions and point dimensions to serve semantic segmentation on point cloud data. We establish a large search space to jointly consider versatile point interactions and point dimensions. This supports point operators with various geometry/density considerations. The enlarged search space with heterogeneous search components calls for a better ranking of candidate models. To achieve this, we improve the search space exploration by leveraging predictor-based Neural Architecture Search (NAS), and enhance the quality of prediction by assigning unique encoding to heterogeneous search components based on their priors. We thoroughly evaluate the networks crafted by PIDS on two semantic segmentation benchmarks, showing ~1% mIOU improvement on SemanticKITTI and S3DIS over state-of-the-art 3D models.
Energy Efficiency Optimization of Intelligent Reflective Surface-assisted Terahertz-RSMA System
Nov 21, 2022



This paper examines the energy efficiency optimization problem of intelligent reflective surface (IRS)-assisted multi-user rate division multiple access (RSMA) downlink systems under terahertz propagation. The objective function for energy efficiency is optimized using the salp swarm algorithm (SSA) and compared with the successive convex approximation (SCA) technique. SCA technique requires multiple iterations to solve non-convex resource allocation problems, whereas SSA can consume less time to improve energy efficiency effectively. The simulation results show that SSA is better than SCA in improving system energy efficiency, and the time required is significantly reduced, thus optimizing the system's overall performance.
SoccerNet 2022 Challenges Results
Oct 05, 2022
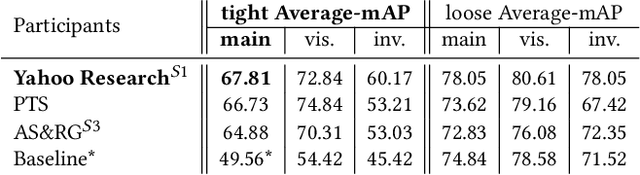
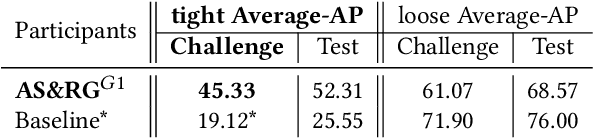
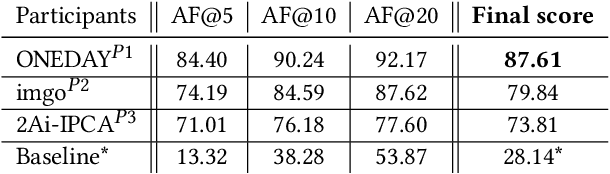
The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
BiFeat: Supercharge GNN Training via Graph Feature Quantization
Jul 29, 2022



Graph Neural Networks (GNNs) is a promising approach for applications with nonEuclidean data. However, training GNNs on large scale graphs with hundreds of millions nodes is both resource and time consuming. Different from DNNs, GNNs usually have larger memory footprints, and thus the GPU memory capacity and PCIe bandwidth are the main resource bottlenecks in GNN training. To address this problem, we present BiFeat: a graph feature quantization methodology to accelerate GNN training by significantly reducing the memory footprint and PCIe bandwidth requirement so that GNNs can take full advantage of GPU computing capabilities. Our key insight is that unlike DNN, GNN is less prone to the information loss of input features caused by quantization. We identify the main accuracy impact factors in graph feature quantization and theoretically prove that BiFeat training converges to a network where the loss is within $\epsilon$ of the optimal loss of uncompressed network. We perform extensive evaluation of BiFeat using several popular GNN models and datasets, including GraphSAGE on MAG240M, the largest public graph dataset. The results demonstrate that BiFeat achieves a compression ratio of more than 30 and improves GNN training speed by 200%-320% with marginal accuracy loss. In particular, BiFeat achieves a record by training GraphSAGE on MAG240M within one hour using only four GPUs.