 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVulnerability of Appearance-based Gaze Estimation
Mar 24, 2021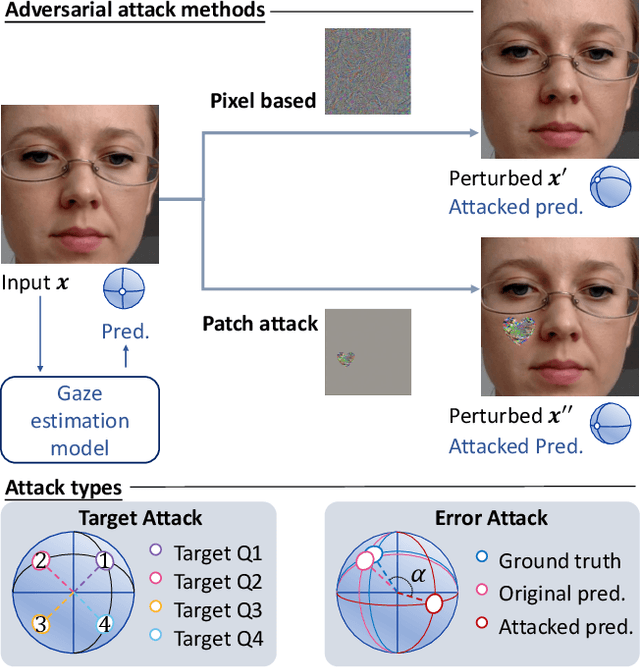
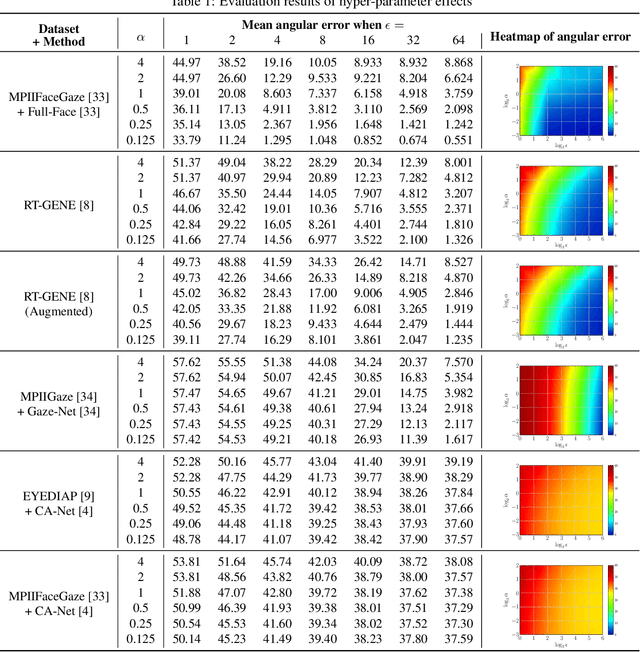
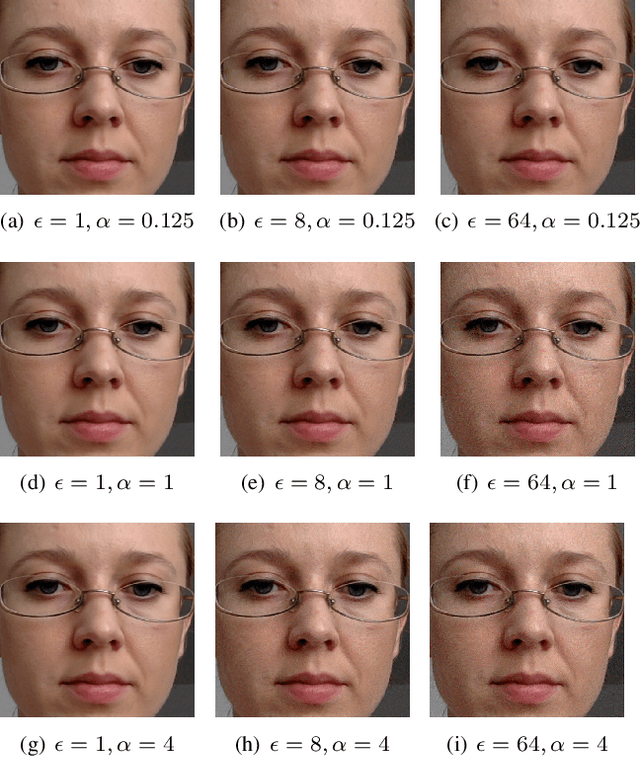
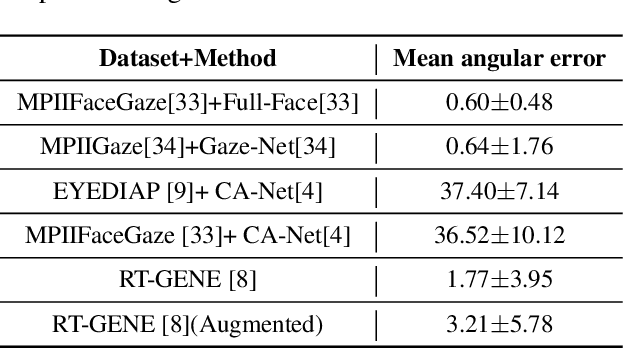
Appearance-based gaze estimation has achieved significant improvement by using deep learning. However, many deep learning-based methods suffer from the vulnerability property, i.e., perturbing the raw image using noise confuses the gaze estimation models. Although the perturbed image visually looks similar to the original image, the gaze estimation models output the wrong gaze direction. In this paper, we investigate the vulnerability of appearance-based gaze estimation. To our knowledge, this is the first time that the vulnerability of gaze estimation to be found. We systematically characterized the vulnerability property from multiple aspects, the pixel-based adversarial attack, the patch-based adversarial attack and the defense strategy. Our experimental results demonstrate that the CA-Net shows superior performance against attack among the four popular appearance-based gaze estimation networks, Full-Face, Gaze-Net, CA-Net and RT-GENE. This study draws the attention of researchers in the appearance-based gaze estimation community to defense from adversarial attacks.
Unsupervised Two-Stage Anomaly Detection
Mar 22, 2021


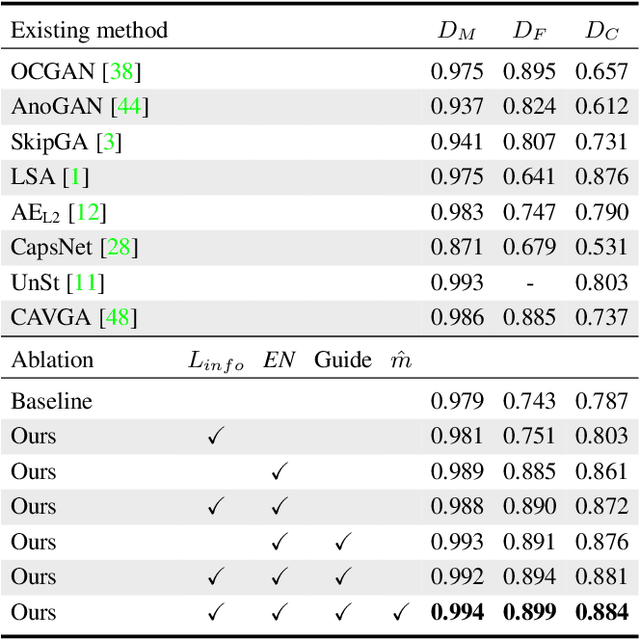
Anomaly detection from a single image is challenging since anomaly data is always rare and can be with highly unpredictable types. With only anomaly-free data available, most existing methods train an AutoEncoder to reconstruct the input image and find the difference between the input and output to identify the anomalous region. However, such methods face a potential problem - a coarse reconstruction generates extra image differences while a high-fidelity one may draw in the anomaly. In this paper, we solve this contradiction by proposing a two-stage approach, which generates high-fidelity yet anomaly-free reconstructions. Our Unsupervised Two-stage Anomaly Detection (UTAD) relies on two technical components, namely the Impression Extractor (IE-Net) and the Expert-Net. The IE-Net and Expert-Net accomplish the two-stage anomaly-free image reconstruction task while they also generate intuitive intermediate results, making the whole UTAD interpretable. Extensive experiments show that our method outperforms state-of-the-arts on four anomaly detection datasets with different types of real-world objects and textures.
Polarization Guided Specular Reflection Separation
Mar 22, 2021
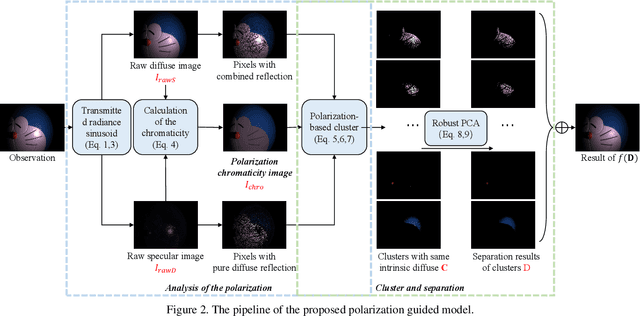
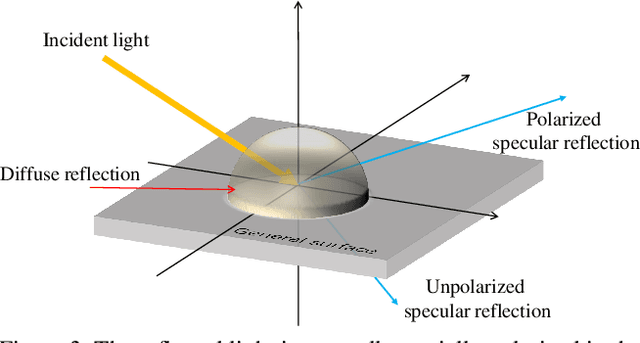
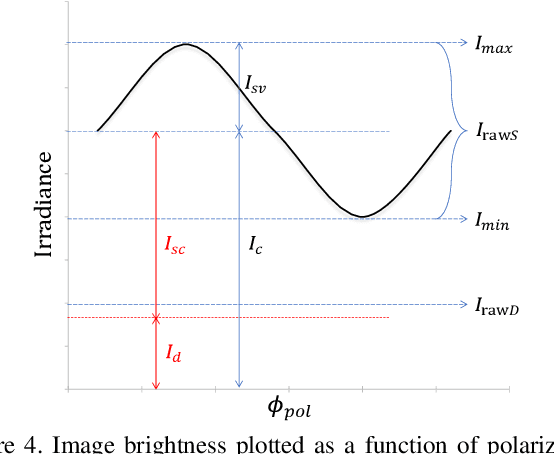
Since specular reflection often exists in the real captured images and causes deviation between the recorded color and intrinsic color, specular reflection separation can bring advantages to multiple applications that require consistent object surface appearance. However, due to the color of an object is significantly influenced by the color of the illumination, the existing researches still suffer from the near-duplicate challenge, that is, the separation becomes unstable when the illumination color is close to the surface color. In this paper, we derive a polarization guided model to incorporate the polarization information into a designed iteration optimization separation strategy to separate the specular reflection. Based on the analysis of polarization, we propose a polarization guided model to generate a polarization chromaticity image, which is able to reveal the geometrical profile of the input image in complex scenarios, such as diversity of illumination. The polarization chromaticity image can accurately cluster the pixels with similar diffuse color. We further use the specular separation of all these clusters as an implicit prior to ensure that the diffuse components will not be mistakenly separated as the specular components. With the polarization guided model, we reformulate the specular reflection separation into a unified optimization function which can be solved by the ADMM strategy. The specular reflection will be detected and separated jointly by RGB and polarimetric information. Both qualitative and quantitative experimental results have shown that our method can faithfully separate the specular reflection, especially in some challenging scenarios.
Adaptive Feature Fusion Network for Gaze Tracking in Mobile Tablets
Mar 20, 2021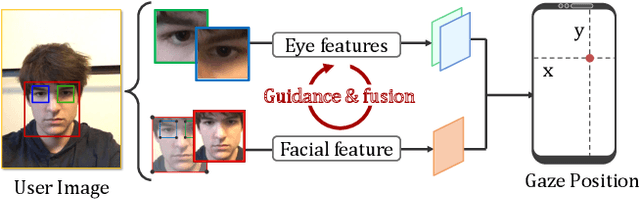
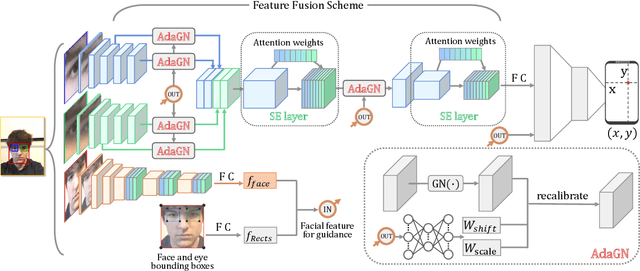
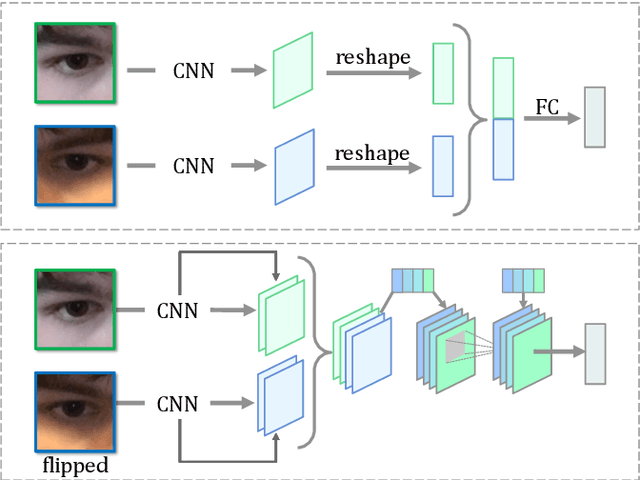
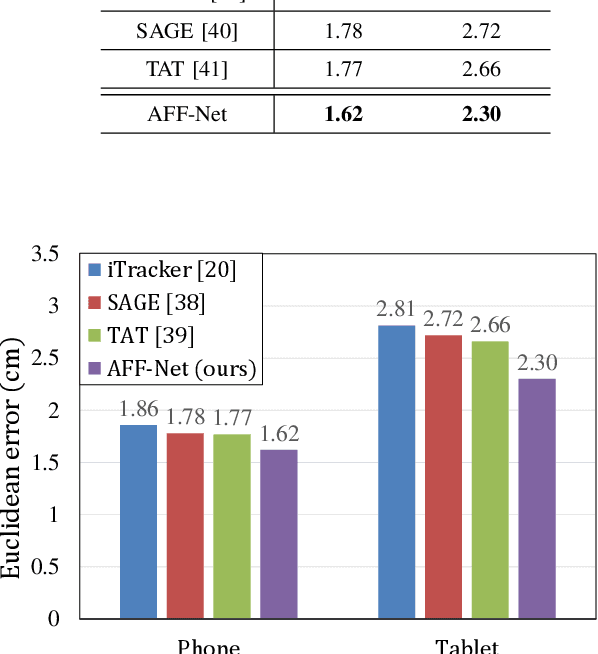
Recently, many multi-stream gaze estimation methods have been proposed. They estimate gaze from eye and face appearances and achieve reasonable accuracy. However, most of the methods simply concatenate the features extracted from eye and face appearance. The feature fusion process has been ignored. In this paper, we propose a novel Adaptive Feature Fusion Network (AFF-Net), which performs gaze tracking task in mobile tablets. We stack two-eye feature maps and utilize Squeeze-and-Excitation layers to adaptively fuse two-eye features according to their similarity on appearance. Meanwhile, we also propose Adaptive Group Normalization to recalibrate eye features with the guidance of facial feature. Extensive experiments on both GazeCapture and MPIIFaceGaze datasets demonstrate consistently superior performance of the proposed method.
An Unsupervised Learning Method with Convolutional Auto-Encoder for Vessel Trajectory Similarity Computation
Jan 10, 2021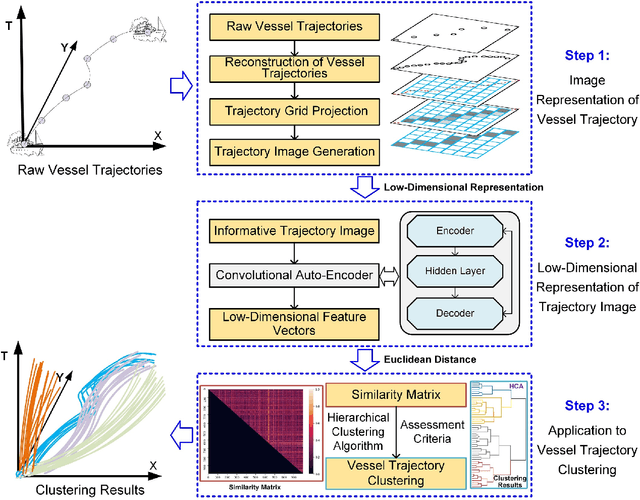
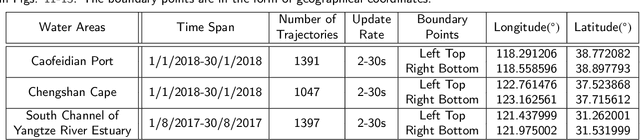
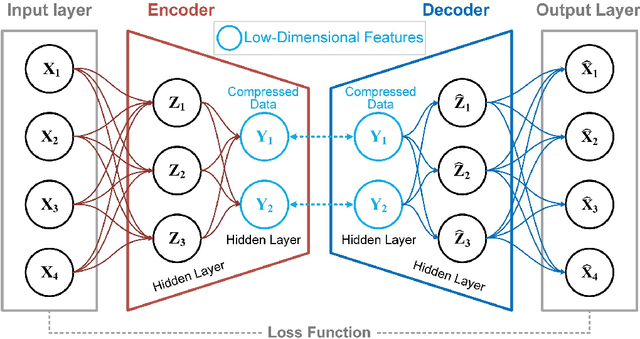
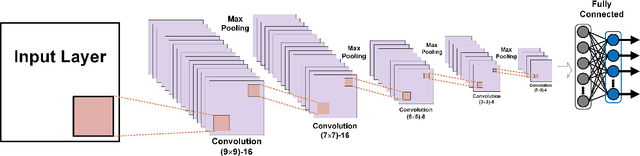
To achieve reliable mining results for massive vessel trajectories, one of the most important challenges is how to efficiently compute the similarities between different vessel trajectories. The computation of vessel trajectory similarity has recently attracted increasing attention in the maritime data mining research community. However, traditional shape- and warping-based methods often suffer from several drawbacks such as high computational cost and sensitivity to unwanted artifacts and non-uniform sampling rates, etc. To eliminate these drawbacks, we propose an unsupervised learning method which automatically extracts low-dimensional features through a convolutional auto-encoder (CAE). In particular, we first generate the informative trajectory images by remapping the raw vessel trajectories into two-dimensional matrices while maintaining the spatio-temporal properties. Based on the massive vessel trajectories collected, the CAE can learn the low-dimensional representations of informative trajectory images in an unsupervised manner. The trajectory similarity is finally equivalent to efficiently computing the similarities between the learned low-dimensional features, which strongly correlate with the raw vessel trajectories. Comprehensive experiments on realistic data sets have demonstrated that the proposed method largely outperforms traditional trajectory similarity computation methods in terms of efficiency and effectiveness. The high-quality trajectory clustering performance could also be guaranteed according to the CAE-based trajectory similarity computation results.
Reflection Backdoor: A Natural Backdoor Attack on Deep Neural Networks
Jul 13, 2020



Recent studies have shown that DNNs can be compromised by backdoor attacks crafted at training time. A backdoor attack installs a backdoor into the victim model by injecting a backdoor pattern into a small proportion of the training data. At test time, the victim model behaves normally on clean test data, yet consistently predicts a specific (likely incorrect) target class whenever the backdoor pattern is present in a test example. While existing backdoor attacks are effective, they are not stealthy. The modifications made on training data or labels are often suspicious and can be easily detected by simple data filtering or human inspection. In this paper, we present a new type of backdoor attack inspired by an important natural phenomenon: reflection. Using mathematical modeling of physical reflection models, we propose reflection backdoor (Refool) to plant reflections as backdoor into a victim model. We demonstrate on 3 computer vision tasks and 5 datasets that, Refool can attack state-of-the-art DNNs with high success rate, and is resistant to state-of-the-art backdoor defenses.
Fast Enhancement for Non-Uniform Illumination Images using Light-weight CNNs
May 31, 2020
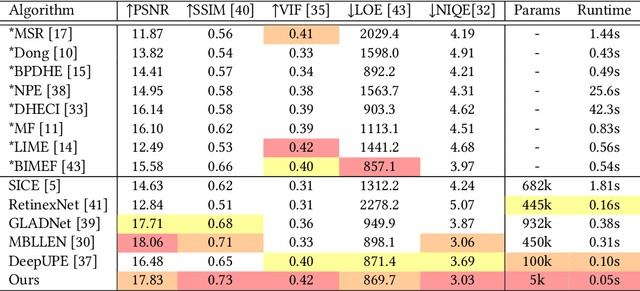

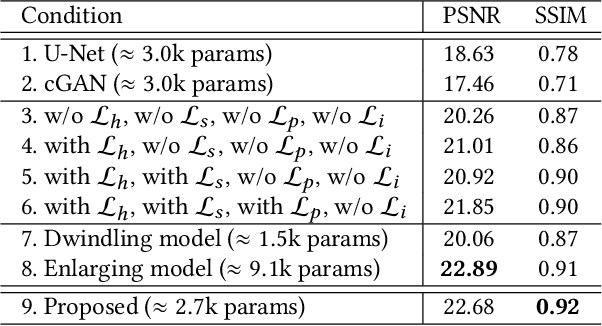
This paper proposes a new light-weight convolutional neural network (5k parameters) for non-uniform illumination image enhancement to handle color, exposure, contrast, noise and artifacts, etc., simultaneously and effectively. More concretely, the input image is first enhanced using Retinex model from dual different aspects (enhancing under-exposure and suppressing over-exposure), respectively. Then, these two enhanced results and the original image are fused to obtain an image with satisfactory brightness, contrast and details. Finally, the extra noise and compression artifacts are removed to get the final result. To train this network, we propose a semi-supervised retouching solution and construct a new dataset (82k images) contains various scenes and light conditions. Our model can enhance 0.5 mega-pixel (like 600*800) images in real time (50 fps), which is faster than existing enhancement methods. Extensive experiments show that our solution is fast and effective to deal with non-uniform illumination images.
An Integrated Enhancement Solution for 24-hour Colorful Imaging
May 10, 2020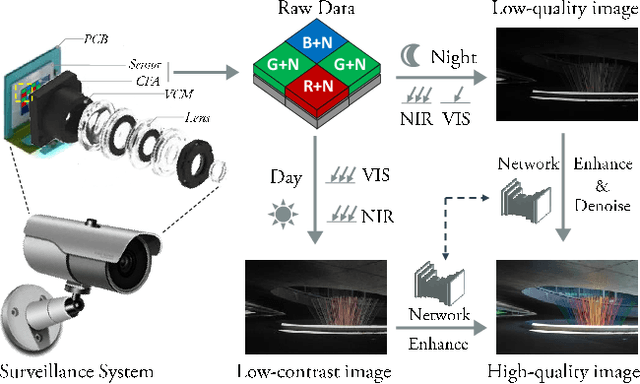
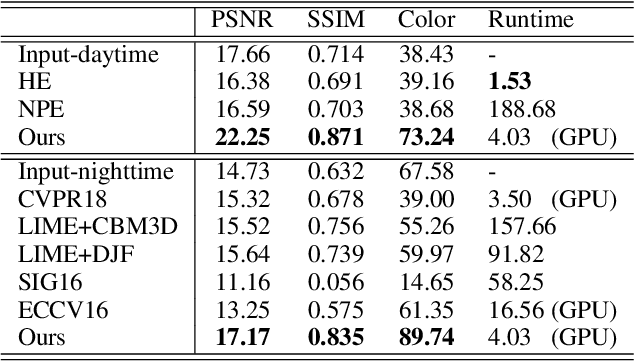
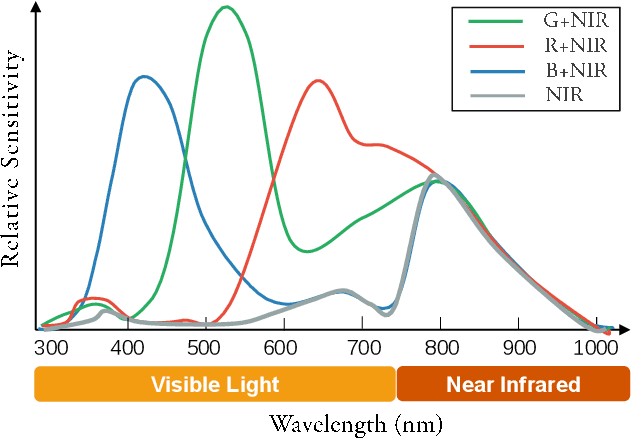
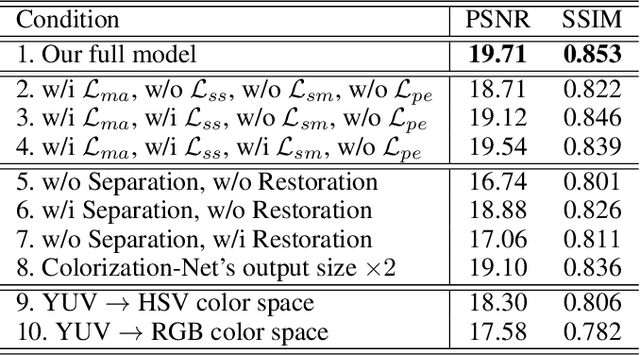
The current industry practice for 24-hour outdoor imaging is to use a silicon camera supplemented with near-infrared (NIR) illumination. This will result in color images with poor contrast at daytime and absence of chrominance at nighttime. For this dilemma, all existing solutions try to capture RGB and NIR images separately. However, they need additional hardware support and suffer from various drawbacks, including short service life, high price, specific usage scenario, etc. In this paper, we propose a novel and integrated enhancement solution that produces clear color images, whether at abundant sunlight daytime or extremely low-light nighttime. Our key idea is to separate the VIS and NIR information from mixed signals, and enhance the VIS signal adaptively with the NIR signal as assistance. To this end, we build an optical system to collect a new VIS-NIR-MIX dataset and present a physically meaningful image processing algorithm based on CNN. Extensive experiments show outstanding results, which demonstrate the effectiveness of our solution.
Beyond Optimizing for Clicks: Incorporating Editorial Values in News Recommendation
Apr 21, 2020


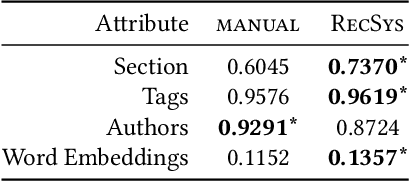
With the uptake of algorithmic personalization in the news domain, news organizations increasingly trust automated systems with previously considered editorial responsibilities, e.g., prioritizing news to readers. In this paper we study an automated news recommender system in the context of a news organization's editorial values. We conduct and present two online studies with a news recommender system, which span one and a half months and involve over 1,200 users. In our first study we explore how our news recommender steers reading behavior in the context of editorial values such as serendipity, dynamism, diversity, and coverage. Next, we present an intervention study where we extend our news recommender to steer our readers to more dynamic reading behavior. We find that (i) our recommender system yields more diverse reading behavior and yields a higher coverage of articles compared to non-personalized editorial rankings, and (ii) we can successfully incorporate dynamism in our recommender system as a re-ranking method, effectively steering our readers to more dynamic articles without hurting our recommender system's accuracy.
A Coarse-to-Fine Adaptive Network for Appearance-Based Gaze Estimation
Jan 01, 2020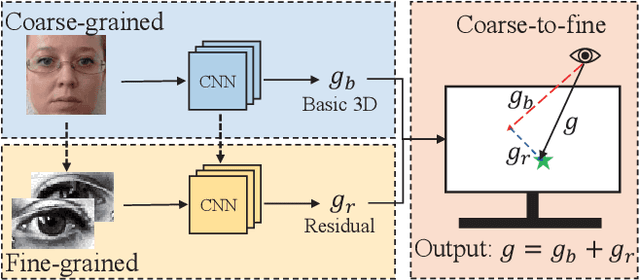
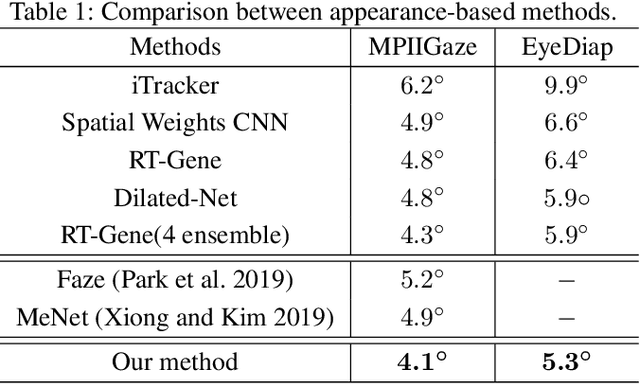
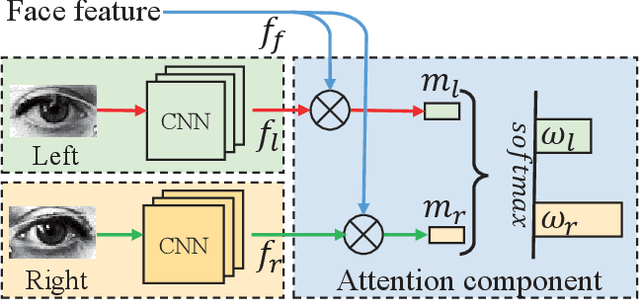
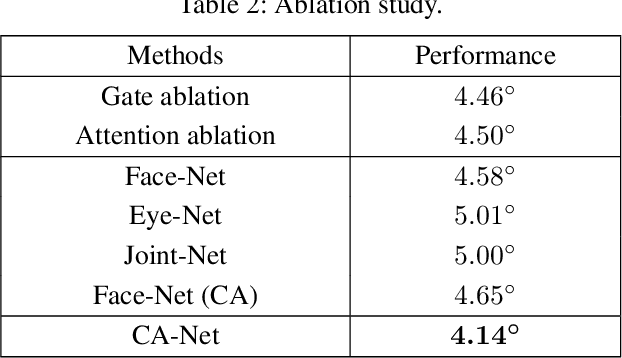
Human gaze is essential for various appealing applications. Aiming at more accurate gaze estimation, a series of recent works propose to utilize face and eye images simultaneously. Nevertheless, face and eye images only serve as independent or parallel feature sources in those works, the intrinsic correlation between their features is overlooked. In this paper we make the following contributions: 1) We propose a coarse-to-fine strategy which estimates a basic gaze direction from face image and refines it with corresponding residual predicted from eye images. 2) Guided by the proposed strategy, we design a framework which introduces a bi-gram model to bridge gaze residual and basic gaze direction, and an attention component to adaptively acquire suitable fine-grained feature. 3) Integrating the above innovations, we construct a coarse-to-fine adaptive network named CA-Net and achieve state-of-the-art performances on MPIIGaze and EyeDiap.