 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNüwa: Mending the Spatial Integrity Torn by VLM Token Pruning
Feb 03, 2026Vision token pruning has proven to be an effective acceleration technique for the efficient Vision Language Model (VLM). However, existing pruning methods demonstrate excellent performance preservation in visual question answering (VQA) and suffer substantial degradation on visual grounding (VG) tasks. Our analysis of the VLM's processing pipeline reveals that strategies utilizing global semantic similarity and attention scores lose the global spatial reference frame, which is derived from the interactions of tokens' positional information. Motivated by these findings, we propose $\text{Nüwa}$, a two-stage token pruning framework that enables efficient feature aggregation while maintaining spatial integrity. In the first stage, after the vision encoder, we apply three operations, namely separation, alignment, and aggregation, which are inspired by swarm intelligence algorithms to retain information-rich global spatial anchors. In the second stage, within the LLM, we perform text-guided pruning to retain task-relevant visual tokens. Extensive experiments demonstrate that $\text{Nüwa}$ achieves SOTA performance on multiple VQA benchmarks (from 94% to 95%) and yields substantial improvements on visual grounding tasks (from 7% to 47%).
Permutation-Invariant Physics-Informed Neural Network for Region-to-Region Sound Field Reconstruction
Jan 27, 2026Most existing sound field reconstruction methods target point-to-region reconstruction, interpolating the Acoustic Transfer Functions (ATFs) between a fixed-position sound source and a receiver region. The applicability of these methods is limited because real-world ATFs tend to varying continuously with respect to the positions of sound sources and receiver regions. This paper presents a permutation-invariant physics-informed neural network for region-to-region sound field reconstruction, which aims to interpolate the ATFs across continuously varying sound sources and measurement regions. The proposed method employs a deep set architecture to process the receiver and sound source positions as an unordered set, preserving acoustic reciprocity. Furthermore, it incorporates the Helmholtz equation as a physical constraint to guide network training, ensuring physically consistent predictions.
Chinese Labor Law Large Language Model Benchmark
Jan 15, 2026Recent advances in large language models (LLMs) have led to substantial progress in domain-specific applications, particularly within the legal domain. However, general-purpose models such as GPT-4 often struggle with specialized subdomains that require precise legal knowledge, complex reasoning, and contextual sensitivity. To address these limitations, we present LabourLawLLM, a legal large language model tailored to Chinese labor law. We also introduce LabourLawBench, a comprehensive benchmark covering diverse labor-law tasks, including legal provision citation, knowledge-based question answering, case classification, compensation computation, named entity recognition, and legal case analysis. Our evaluation framework combines objective metrics (e.g., ROUGE-L, accuracy, F1, and soft-F1) with subjective assessment based on GPT-4 scoring. Experiments show that LabourLawLLM consistently outperforms general-purpose and existing legal-specific LLMs across task categories. Beyond labor law, our methodology provides a scalable approach for building specialized LLMs in other legal subfields, improving accuracy, reliability, and societal value of legal AI applications.
E^2-LLM: Bridging Neural Signals and Interpretable Affective Analysis
Jan 11, 2026Emotion recognition from electroencephalography (EEG) signals remains challenging due to high inter-subject variability, limited labeled data, and the lack of interpretable reasoning in existing approaches. While recent multimodal large language models (MLLMs) have advanced emotion analysis, they have not been adapted to handle the unique spatiotemporal characteristics of neural signals. We present E^2-LLM (EEG-to-Emotion Large Language Model), the first MLLM framework for interpretable emotion analysis from EEG. E^2-LLM integrates a pretrained EEG encoder with Qwen-based LLMs through learnable projection layers, employing a multi-stage training pipeline that encompasses emotion-discriminative pretraining, cross-modal alignment, and instruction tuning with chain-of-thought reasoning. We design a comprehensive evaluation protocol covering basic emotion prediction, multi-task reasoning, and zero-shot scenario understanding. Experiments on the dataset across seven emotion categories demonstrate that E^2-LLM achieves excellent performance on emotion classification, with larger variants showing enhanced reliability and superior zero-shot generalization to complex reasoning scenarios. Our work establishes a new paradigm combining physiological signals with LLM reasoning capabilities, showing that model scaling improves both recognition accuracy and interpretable emotional understanding in affective computing.
SearchAttack: Red-Teaming LLMs against Real-World Threats via Framing Unsafe Web Information-Seeking Tasks
Jan 07, 2026Recently, people have suffered and become increasingly aware of the unreliability gap in LLMs for open and knowledge-intensive tasks, and thus turn to search-augmented LLMs to mitigate this issue. However, when the search engine is triggered for harmful tasks, the outcome is no longer under the LLM's control. Once the returned content directly contains targeted, ready-to-use harmful takeaways, the LLM's safeguards cannot withdraw that exposure. Motivated by this dilemma, we identify web search as a critical attack surface and propose \textbf{\textit{SearchAttack}} for red-teaming. SearchAttack outsources the harmful semantics to web search, retaining only the query's skeleton and fragmented clues, and further steers LLMs to reconstruct the retrieved content via structural rubrics to achieve malicious goals. Extensive experiments are conducted to red-team the search-augmented LLMs for responsible vulnerability assessment. Empirically, SearchAttack demonstrates strong effectiveness in attacking these systems.
GeoDiff-SAR: A Geometric Prior Guided Diffusion Model for SAR Image Generation
Jan 07, 2026Synthetic Aperture Radar (SAR) imaging results are highly sensitive to observation geometries and the geometric parameters of targets. However, existing generative methods primarily operate within the image domain, neglecting explicit geometric information. This limitation often leads to unsatisfactory generation quality and the inability to precisely control critical parameters such as azimuth angles. To address these challenges, we propose GeoDiff-SAR, a geometric prior guided diffusion model for high-fidelity SAR image generation. Specifically, GeoDiff-SAR first efficiently simulates the geometric structures and scattering relationships inherent in real SAR imaging by calculating SAR point clouds at specific azimuths, which serves as a robust physical guidance. Secondly, to effectively fuse multi-modal information, we employ a feature fusion gating network based on Feature-wise Linear Modulation (FiLM) to dynamically regulate the weight distribution of 3D physical information, image control parameters, and textual description parameters. Thirdly, we utilize the Low-Rank Adaptation (LoRA) architecture to perform lightweight fine-tuning on the advanced Stable Diffusion 3.5 (SD3.5) model, enabling it to rapidly adapt to the distribution characteristics of the SAR domain. To validate the effectiveness of GeoDiff-SAR, extensive comparative experiments were conducted on real-world SAR datasets. The results demonstrate that data generated by GeoDiff-SAR exhibits high fidelity and effectively enhances the accuracy of downstream classification tasks. In particular, it significantly improves recognition performance across different azimuth angles, thereby underscoring the superiority of physics-guided generation.
SynthSeg-Agents: Multi-Agent Synthetic Data Generation for Zero-Shot Weakly Supervised Semantic Segmentation
Dec 17, 2025
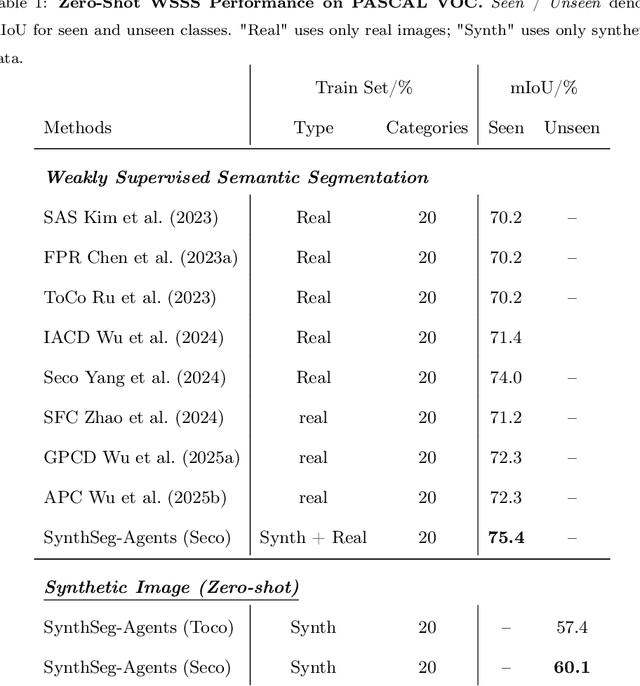
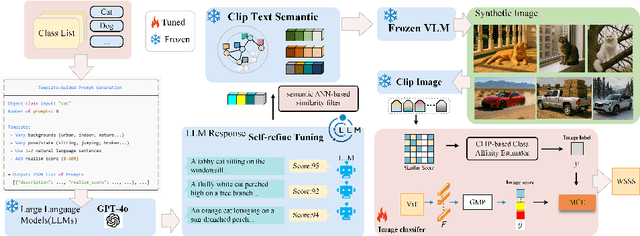

Weakly Supervised Semantic Segmentation (WSSS) with image level labels aims to produce pixel level predictions without requiring dense annotations. While recent approaches have leveraged generative models to augment existing data, they remain dependent on real world training samples. In this paper, we introduce a novel direction, Zero Shot Weakly Supervised Semantic Segmentation (ZSWSSS), and propose SynthSeg Agents, a multi agent framework driven by Large Language Models (LLMs) to generate synthetic training data entirely without real images. SynthSeg Agents comprises two key modules, a Self Refine Prompt Agent and an Image Generation Agent. The Self Refine Prompt Agent autonomously crafts diverse and semantically rich image prompts via iterative refinement, memory mechanisms, and prompt space exploration, guided by CLIP based similarity and nearest neighbor diversity filtering. These prompts are then passed to the Image Generation Agent, which leverages Vision Language Models (VLMs) to synthesize candidate images. A frozen CLIP scoring model is employed to select high quality samples, and a ViT based classifier is further trained to relabel the entire synthetic dataset with improved semantic precision. Our framework produces high quality training data without any real image supervision. Experiments on PASCAL VOC 2012 and COCO 2014 show that SynthSeg Agents achieves competitive performance without using real training images. This highlights the potential of LLM driven agents in enabling cost efficient and scalable semantic segmentation.
SMGeo: Cross-View Object Geo-Localization with Grid-Level Mixture-of-Experts
Nov 18, 2025



Cross-view object Geo-localization aims to precisely pinpoint the same object across large-scale satellite imagery based on drone images. Due to significant differences in viewpoint and scale, coupled with complex background interference, traditional multi-stage "retrieval-matching" pipelines are prone to cumulative errors. To address this, we present SMGeo, a promptable end-to-end transformer-based model for object Geo-localization. This model supports click prompting and can output object Geo-localization in real time when prompted to allow for interactive use. The model employs a fully transformer-based architecture, utilizing a Swin-Transformer for joint feature encoding of both drone and satellite imagery and an anchor-free transformer detection head for coordinate regression. In order to better capture both inter-modal and intra-view dependencies, we introduce a grid-level sparse Mixture-of-Experts (GMoE) into the cross-view encoder, allowing it to adaptively activate specialized experts according to the content, scale and source of each grid. We also employ an anchor-free detection head for coordinate regression, directly predicting object locations via heat-map supervision in the reference images. This approach avoids scale bias and matching complexity introduced by predefined anchor boxes. On the drone-to-satellite task, SMGeo achieves leading performance in accuracy at IoU=0.25 and mIoU metrics (e.g., 87.51%, 62.50%, and 61.45% in the test set, respectively), significantly outperforming representative methods such as DetGeo (61.97%, 57.66%, and 54.05%, respectively). Ablation studies demonstrate complementary gains from shared encoding, query-guided fusion, and grid-level sparse mixture-of-experts.
TheraMind: A Strategic and Adaptive Agent for Longitudinal Psychological Counseling
Oct 29, 2025



Large language models (LLMs) in psychological counseling have attracted increasing attention. However, existing approaches often lack emotional understanding, adaptive strategies, and the use of therapeutic methods across multiple sessions with long-term memory, leaving them far from real clinical practice. To address these critical gaps, we introduce TheraMind, a strategic and adaptive agent for longitudinal psychological counseling. The cornerstone of TheraMind is a novel dual-loop architecture that decouples the complex counseling process into an Intra-Session Loop for tactical dialogue management and a Cross-Session Loop for strategic therapeutic planning. The Intra-Session Loop perceives the patient's emotional state to dynamically select response strategies while leveraging cross-session memory to ensure continuity. Crucially, the Cross-Session Loop empowers the agent with long-term adaptability by evaluating the efficacy of the applied therapy after each session and adjusting the method for subsequent interactions. We validate our approach in a high-fidelity simulation environment grounded in real clinical cases. Extensive evaluations show that TheraMind outperforms other methods, especially on multi-session metrics like Coherence, Flexibility, and Therapeutic Attunement, validating the effectiveness of its dual-loop design in emulating strategic, adaptive, and longitudinal therapeutic behavior. The code is publicly available at https://0mwwm0.github.io/TheraMind/.
Explore Briefly, Then Decide: Mitigating LLM Overthinking via Cumulative Entropy Regulation
Oct 02, 2025



Large Language Models (LLMs) have demonstrated remarkable reasoning abilities on complex problems using long Chain-of-Thought (CoT) reasoning. However, they often suffer from overthinking, meaning generating unnecessarily lengthy reasoning steps for simpler problems. This issue may degrade the efficiency of the models and make them difficult to adapt the reasoning depth to the complexity of problems. To address this, we introduce a novel metric Token Entropy Cumulative Average (TECA), which measures the extent of exploration throughout the reasoning process. We further propose a novel reasoning paradigm -- Explore Briefly, Then Decide -- with an associated Cumulative Entropy Regulation (CER) mechanism. This paradigm leverages TECA to help the model dynamically determine the optimal point to conclude its thought process and provide a final answer, thus achieving efficient reasoning. Experimental results across diverse mathematical benchmarks show that our approach substantially mitigates overthinking without sacrificing problem-solving ability. With our thinking paradigm, the average response length decreases by up to 71% on simpler datasets, demonstrating the effectiveness of our method in creating a more efficient and adaptive reasoning process.