 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSphUnc: Hyperspherical Uncertainty Decomposition and Causal Identification via Information Geometry
Mar 01, 2026Reliable decision-making in complex multi-agent systems requires calibrated predictions and interpretable uncertainty. We introduce SphUnc, a unified framework combining hyperspherical representation learning with structural causal modeling. The model maps features to unit hypersphere latents using von Mises-Fisher distributions, decomposing uncertainty into epistemic and aleatoric components through information-geometric fusion. A structural causal model on spherical latents enables directed influence identification and interventional reasoning via sample-based simulation. Empirical evaluations on social and affective benchmarks demonstrate improved accuracy, better calibration, and interpretable causal signals, establishing a geometric-causal foundation for uncertainty-aware reasoning in multi-agent settings with higher-order interactions.
DAV-GSWT: Diffusion-Active-View Sampling for Data-Efficient Gaussian Splatting Wang Tiles
Feb 17, 2026The emergence of 3D Gaussian Splatting has fundamentally redefined the capabilities of photorealistic neural rendering by enabling high-throughput synthesis of complex environments. While procedural methods like Wang Tiles have recently been integrated to facilitate the generation of expansive landscapes, these systems typically remain constrained by a reliance on densely sampled exemplar reconstructions. We present DAV-GSWT, a data-efficient framework that leverages diffusion priors and active view sampling to synthesize high-fidelity Gaussian Splatting Wang Tiles from minimal input observations. By integrating a hierarchical uncertainty quantification mechanism with generative diffusion models, our approach autonomously identifies the most informative viewpoints while hallucinating missing structural details to ensure seamless tile transitions. Experimental results indicate that our system significantly reduces the required data volume while maintaining the visual integrity and interactive performance necessary for large-scale virtual environments.
GaiaFlow: Semantic-Guided Diffusion Tuning for Carbon-Frugal Search
Feb 17, 2026As the burgeoning power requirements of sophisticated neural architectures escalate, the information retrieval community has recognized ecological sustainability as a pivotal priority that necessitates a fundamental paradigm shift in model design. While contemporary neural rankers have attained unprecedented accuracy, the substantial environmental externalities associated with their computational intensity often remain overlooked in large-scale deployments. We present GaiaFlow, an innovative framework engineered to facilitate carbon-frugal search by operationalizing semantic-guided diffusion tuning. Our methodology orchestrates the convergence of retrieval-guided Langevin dynamics and a hardware-independent performance modeling strategy to optimize the trade-off between search precision and environmental preservation. By incorporating adaptive early exit protocols and precision-aware quantized inference, the proposed architecture significantly mitigates operational carbon footprints while maintaining robust retrieval quality across heterogeneous computing infrastructures. Extensive experimental evaluations demonstrate that GaiaFlow achieves a superior equilibrium between effectiveness and energy efficiency, offering a scalable and sustainable pathway for next-generation neural search systems.
Chimera: Neuro-Symbolic Attention Primitives for Trustworthy Dataplane Intelligence
Feb 13, 2026Deploying expressive learning models directly on programmable dataplanes promises line-rate, low-latency traffic analysis but remains hindered by strict hardware constraints and the need for predictable, auditable behavior. Chimera introduces a principled framework that maps attention-oriented neural computations and symbolic constraints onto dataplane primitives, enabling trustworthy inference within the match-action pipeline. Chimera combines a kernelized, linearized attention approximation with a two-layer key-selection hierarchy and a cascade fusion mechanism that enforces hard symbolic guarantees while preserving neural expressivity. The design includes a hardware-aware mapping protocol and a two-timescale update scheme that together permit stable, line-rate operation under realistic dataplane budgets. The paper presents the Chimera architecture, a hardware mapping strategy, and empirical evidence showing that neuro-symbolic attention primitives can achieve high-fidelity inference within the resource envelope of commodity programmable switches.
ProMist-5K: A Comprehensive Dataset for Digital Emulation of Cinematic Pro-Mist Filter Effects
Jan 27, 2026Pro-Mist filters are widely used in cinematography for their ability to create soft halation, lower contrast, and produce a distinctive, atmospheric style. These effects are difficult to reproduce digitally due to the complex behavior of light diffusion. We present ProMist-5K, a dataset designed to support cinematic style emulation. It is built using a physically inspired pipeline in a scene-referred linear space and includes 20,000 high-resolution image pairs across four configurations, covering two filter densities (1/2 and 1/8) and two focal lengths (20mm and 50mm). Unlike general style datasets, ProMist-5K focuses on realistic glow and highlight diffusion effects. Multiple blur layers and carefully tuned weighting are used to model the varying intensity and spread of optical diffusion. The dataset provides a consistent and controllable target domain that supports various image translation models and learning paradigms. Experiments show that the dataset works well across different training settings and helps capture both subtle and strong cinematic appearances. ProMist-5K offers a practical and physically grounded resource for film-inspired image transformation, bridging the gap between digital flexibility and traditional lens aesthetics. The dataset is available at https://www.kaggle.com/datasets/yingtielei/promist5k.
Beyond Shadows: A Large-Scale Benchmark and Multi-Stage Framework for High-Fidelity Facial Shadow Removal
Jan 27, 2026Facial shadows often degrade image quality and the performance of vision algorithms. Existing methods struggle to remove shadows while preserving texture, especially under complex lighting conditions, and they lack real-world paired datasets for training. We present the Augmented Shadow Face in the Wild (ASFW) dataset, the first large-scale real-world dataset for facial shadow removal, containing 1,081 paired shadow and shadow-free images created via a professional Photoshop workflow. ASFW offers photorealistic shadow variations and accurate ground truths, bridging the gap between synthetic and real domains. Deep models trained on ASFW demonstrate improved shadow removal in real-world conditions. We also introduce the Face Shadow Eraser (FSE) method to showcase the effectiveness of the dataset. Experiments demonstrate that ASFW enhances the performance of facial shadow removal models, setting new standards for this task.
Context Patch Fusion With Class Token Enhancement for Weakly Supervised Semantic Segmentation
Jan 21, 2026Weakly Supervised Semantic Segmentation (WSSS), which relies only on image-level labels, has attracted significant attention for its cost-effectiveness and scalability. Existing methods mainly enhance inter-class distinctions and employ data augmentation to mitigate semantic ambiguity and reduce spurious activations. However, they often neglect the complex contextual dependencies among image patches, resulting in incomplete local representations and limited segmentation accuracy. To address these issues, we propose the Context Patch Fusion with Class Token Enhancement (CPF-CTE) framework, which exploits contextual relations among patches to enrich feature representations and improve segmentation. At its core, the Contextual-Fusion Bidirectional Long Short-Term Memory (CF-BiLSTM) module captures spatial dependencies between patches and enables bidirectional information flow, yielding a more comprehensive understanding of spatial correlations. This strengthens feature learning and segmentation robustness. Moreover, we introduce learnable class tokens that dynamically encode and refine class-specific semantics, enhancing discriminative capability. By effectively integrating spatial and semantic cues, CPF-CTE produces richer and more accurate representations of image content. Extensive experiments on PASCAL VOC 2012 and MS COCO 2014 validate that CPF-CTE consistently surpasses prior WSSS methods.
SynthSeg-Agents: Multi-Agent Synthetic Data Generation for Zero-Shot Weakly Supervised Semantic Segmentation
Dec 17, 2025
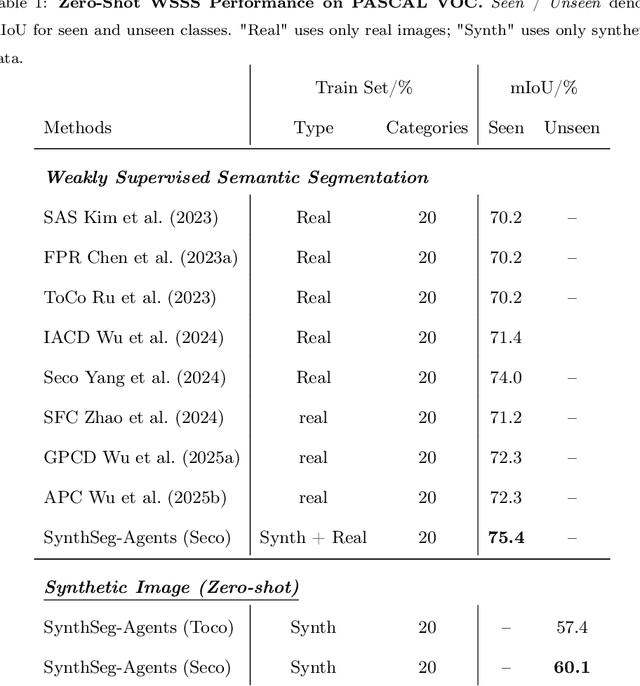
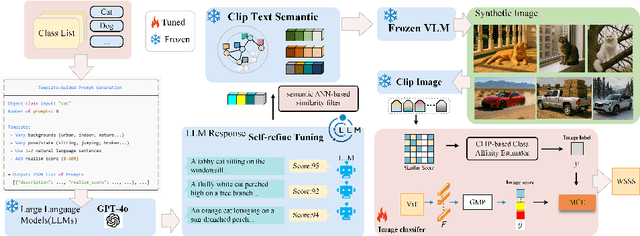

Weakly Supervised Semantic Segmentation (WSSS) with image level labels aims to produce pixel level predictions without requiring dense annotations. While recent approaches have leveraged generative models to augment existing data, they remain dependent on real world training samples. In this paper, we introduce a novel direction, Zero Shot Weakly Supervised Semantic Segmentation (ZSWSSS), and propose SynthSeg Agents, a multi agent framework driven by Large Language Models (LLMs) to generate synthetic training data entirely without real images. SynthSeg Agents comprises two key modules, a Self Refine Prompt Agent and an Image Generation Agent. The Self Refine Prompt Agent autonomously crafts diverse and semantically rich image prompts via iterative refinement, memory mechanisms, and prompt space exploration, guided by CLIP based similarity and nearest neighbor diversity filtering. These prompts are then passed to the Image Generation Agent, which leverages Vision Language Models (VLMs) to synthesize candidate images. A frozen CLIP scoring model is employed to select high quality samples, and a ViT based classifier is further trained to relabel the entire synthetic dataset with improved semantic precision. Our framework produces high quality training data without any real image supervision. Experiments on PASCAL VOC 2012 and COCO 2014 show that SynthSeg Agents achieves competitive performance without using real training images. This highlights the potential of LLM driven agents in enabling cost efficient and scalable semantic segmentation.
Contrastive Prompt Clustering for Weakly Supervised Semantic Segmentation
Aug 23, 2025



Weakly Supervised Semantic Segmentation (WSSS) with image-level labels has gained attention for its cost-effectiveness. Most existing methods emphasize inter-class separation, often neglecting the shared semantics among related categories and lacking fine-grained discrimination. To address this, we propose Contrastive Prompt Clustering (CPC), a novel WSSS framework. CPC exploits Large Language Models (LLMs) to derive category clusters that encode intrinsic inter-class relationships, and further introduces a class-aware patch-level contrastive loss to enforce intra-class consistency and inter-class separation. This hierarchical design leverages clusters as coarse-grained semantic priors while preserving fine-grained boundaries, thereby reducing confusion among visually similar categories. Experiments on PASCAL VOC 2012 and MS COCO 2014 demonstrate that CPC surpasses existing state-of-the-art methods in WSSS.
MAC-Lookup: Multi-Axis Conditional Lookup Model for Underwater Image Enhancement
Jul 03, 2025Enhancing underwater images is crucial for exploration. These images face visibility and color issues due to light changes, water turbidity, and bubbles. Traditional prior-based methods and pixel-based methods often fail, while deep learning lacks sufficient high-quality datasets. We introduce the Multi-Axis Conditional Lookup (MAC-Lookup) model, which enhances visual quality by improving color accuracy, sharpness, and contrast. It includes Conditional 3D Lookup Table Color Correction (CLTCC) for preliminary color and quality correction and Multi-Axis Adaptive Enhancement (MAAE) for detail refinement. This model prevents over-enhancement and saturation while handling underwater challenges. Extensive experiments show that MAC-Lookup excels in enhancing underwater images by restoring details and colors better than existing methods. The code is https://github.com/onlycatdoraemon/MAC-Lookup.