 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Sensor SAR Data Generation Using Diffusion Models and Feature Migration
Jun 27, 2026Different synthetic aperture radar (SAR) sensors vary significantly in resolution, polarization modes, and frequency bands, making it difficult to directly apply existing models to newly launched SAR satellites. These new systems require large amounts of labeled data for model retraining, but collecting sufficient data in a short time is often infeasible. To address this contradiction, this paper proposes a data generation and transfer framework, integrating a stable diffusion model with attention distillation, that leverages historical SAR data to synthesize training data tailored to the unique characteristics of new SAR systems. Specifically, we fine-tune the low-rank adaptation (LoRA) modules within the multimodal diffusion transformer (MM-DiT) architecture to enable class-controllable SAR image generation guided by textual prompts. To ensure that the generated images reflect the statistical properties and imaging characteristics of the target SAR system, we further introduce an attention distillation mechanism that transfers sensor-specific features, such as spatial texture, speckle distribution, and structural patterns, from real target-domain data to the generative model. Extensive experiments on multi-class aircraft target datasets from two real spaceborne SAR systems demonstrate the effectiveness of the proposed approach in alleviating data scarcity and supporting cross-sensor remote sensing applications.
Optical-Guided Neural Collapse for SAR Few-Shot Class Incremental Learning
Jun 03, 2026Few-shot class-incremental learning (FSCIL) in synthetic aperture radar imagery presents unique challenges due to severe data scarcity and SAR-specific variability. In particular, strong azimuth sensitivity in SAR induces large intra-class variation and inter-class confusion, and FSCIL sequential updates further lead to catastrophic forgetting of previously learned classes. Inspired by neural collapse, we propose an optical-guided SAR FSCIL framework, which derives orthogonal feature subspaces from a data-rich optical ATR dataset and uses them as geometric priors to guide SAR feature learning. SAR features are projected onto these orthogonal subspaces via principal angle constraints, effectively transferring discriminative structure from the optical to the SAR domain. Specifically, our projection loss and the classifier loss optimized with a frozen simplex-ETF geometry jointly induce neural collapse by concentrating features around class means while maintaining large inter-class angles. We evaluate the approach on a benchmark comprising an optical ATR dataset and a SAR ATR dataset with 24 target classes, organized into a base training session and seven incremental sessions. Compared with recent FSCIL methods including NCFSCIL and so on, our method achieves the highest final accuracy and a favorable trade-off between final performance and performance degradation. Moreover, neural collapse metrics show improved intra-class compactness and inter-class separability, indicating that the learned features more closely approximate the ideal simplex-ETF geometry.
GeoDiff-SAR II: 3D-Driven Foundation Diffusion Models for SAR Generation via Decoupled Control
May 20, 2026Existing Synthetic Aperture Radar (SAR) image generation methods still lack reliable controllability over key imaging parameters, particularly azimuth angle, depression angle, and polarization mode. Our preliminary GeoDiff-SAR supported limited azimuth completion, but remained ineffective for large missing azimuth sectors and did not provide unified control over multiple imaging conditions. To address this problem, we propose GeoDiff-SAR II, a 3D model-guided decoupled framework for controllable SAR image generation. The proposed framework imposes controllability through physically grounded geometric-electromagnetic cues rather than image intensity alone. We introduce a Geometric-Electromagnetic Conditioning Map (GECM), a structured intermediate representation that encodes the target pose map and dominant scattering centers, thereby decoupling macroscopic geometry from microscopic scattering responses. During training, GECMs are derived from real sparse-azimuth SAR images. During inference, the same representation is rendered directly from a 3D CAD model under specified azimuth, depression angle, and polarization conditions, enabling physically consistent control across large viewpoint gaps. The imaging parameters are further converted into text conditions, while the GECM is injected through ControlNet to provide explicit spatial guidance. Combined with Low-Rank Adaptation (LoRA) on a FLUX backbone, the proposed framework unifies geometric-electromagnetic conditioning and parameter-aware generation within a single process. Experiments on simulated and real datasets demonstrate controllable generation over key SAR imaging parameters, stable generalization across large azimuth gaps, and consistent improvements in image fidelity, physical consistency, and downstream Automatic Target Recognition (ATR) performance.
GeoDiff-SAR: A Geometric Prior Guided Diffusion Model for SAR Image Generation
Jan 07, 2026Synthetic Aperture Radar (SAR) imaging results are highly sensitive to observation geometries and the geometric parameters of targets. However, existing generative methods primarily operate within the image domain, neglecting explicit geometric information. This limitation often leads to unsatisfactory generation quality and the inability to precisely control critical parameters such as azimuth angles. To address these challenges, we propose GeoDiff-SAR, a geometric prior guided diffusion model for high-fidelity SAR image generation. Specifically, GeoDiff-SAR first efficiently simulates the geometric structures and scattering relationships inherent in real SAR imaging by calculating SAR point clouds at specific azimuths, which serves as a robust physical guidance. Secondly, to effectively fuse multi-modal information, we employ a feature fusion gating network based on Feature-wise Linear Modulation (FiLM) to dynamically regulate the weight distribution of 3D physical information, image control parameters, and textual description parameters. Thirdly, we utilize the Low-Rank Adaptation (LoRA) architecture to perform lightweight fine-tuning on the advanced Stable Diffusion 3.5 (SD3.5) model, enabling it to rapidly adapt to the distribution characteristics of the SAR domain. To validate the effectiveness of GeoDiff-SAR, extensive comparative experiments were conducted on real-world SAR datasets. The results demonstrate that data generated by GeoDiff-SAR exhibits high fidelity and effectively enhances the accuracy of downstream classification tasks. In particular, it significantly improves recognition performance across different azimuth angles, thereby underscoring the superiority of physics-guided generation.
SMGeo: Cross-View Object Geo-Localization with Grid-Level Mixture-of-Experts
Nov 18, 2025



Cross-view object Geo-localization aims to precisely pinpoint the same object across large-scale satellite imagery based on drone images. Due to significant differences in viewpoint and scale, coupled with complex background interference, traditional multi-stage "retrieval-matching" pipelines are prone to cumulative errors. To address this, we present SMGeo, a promptable end-to-end transformer-based model for object Geo-localization. This model supports click prompting and can output object Geo-localization in real time when prompted to allow for interactive use. The model employs a fully transformer-based architecture, utilizing a Swin-Transformer for joint feature encoding of both drone and satellite imagery and an anchor-free transformer detection head for coordinate regression. In order to better capture both inter-modal and intra-view dependencies, we introduce a grid-level sparse Mixture-of-Experts (GMoE) into the cross-view encoder, allowing it to adaptively activate specialized experts according to the content, scale and source of each grid. We also employ an anchor-free detection head for coordinate regression, directly predicting object locations via heat-map supervision in the reference images. This approach avoids scale bias and matching complexity introduced by predefined anchor boxes. On the drone-to-satellite task, SMGeo achieves leading performance in accuracy at IoU=0.25 and mIoU metrics (e.g., 87.51%, 62.50%, and 61.45% in the test set, respectively), significantly outperforming representative methods such as DetGeo (61.97%, 57.66%, and 54.05%, respectively). Ablation studies demonstrate complementary gains from shared encoding, query-guided fusion, and grid-level sparse mixture-of-experts.
SAR Target Recognition Using the Multi-aspect-aware Bidirectional LSTM Recurrent Neural Networks
Jul 25, 2017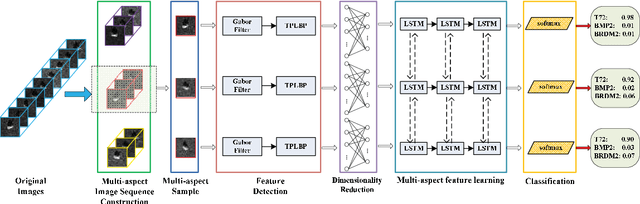
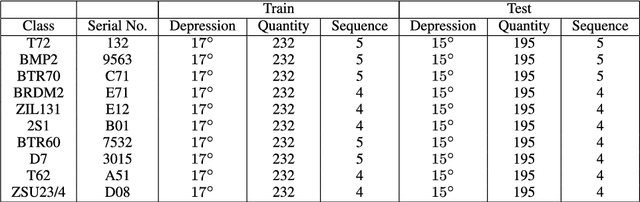
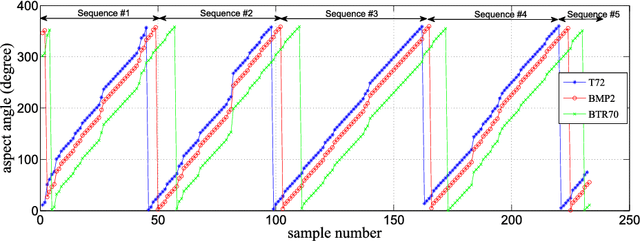
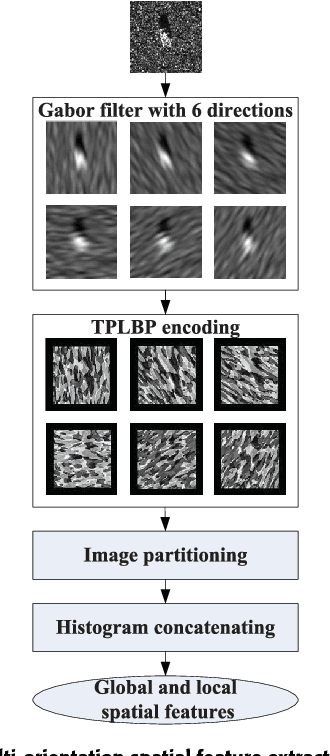
The outstanding pattern recognition performance of deep learning brings new vitality to the synthetic aperture radar (SAR) automatic target recognition (ATR). However, there is a limitation in current deep learning based ATR solution that each learning process only handle one SAR image, namely learning the static scattering information, while missing the space-varying information. It is obvious that multi-aspect joint recognition introduced space-varying scattering information should improve the classification accuracy and robustness. In this paper, a novel multi-aspect-aware method is proposed to achieve this idea through the bidirectional Long Short-Term Memory (LSTM) recurrent neural networks based space-varying scattering information learning. Specifically, we first select different aspect images to generate the multi-aspect space-varying image sequences. Then, the Gabor filter and three-patch local binary pattern (TPLBP) are progressively implemented to extract a comprehensive spatial features, followed by dimensionality reduction with the Multi-layer Perceptron (MLP) network. Finally, we design a bidirectional LSTM recurrent neural network to learn the multi-aspect features with further integrating the softmax classifier to achieve target recognition. Experimental results demonstrate that the proposed method can achieve 99.9% accuracy for 10-class recognition. Besides, its anti-noise and anti-confusion performance are also better than the conventional deep learning based methods.
* 11 pages, 10 figures