 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Free Learning of a Natural Language Interface for Pretrained Face Generators
Sep 08, 2022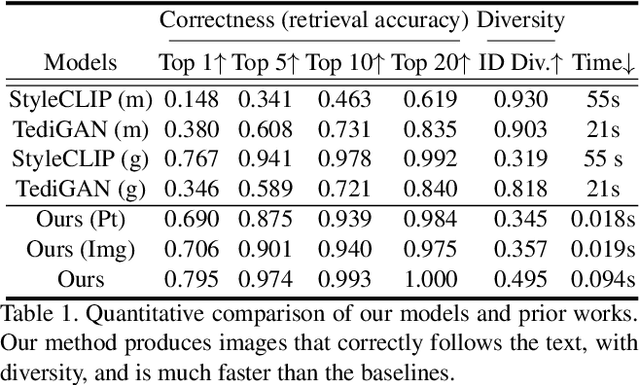
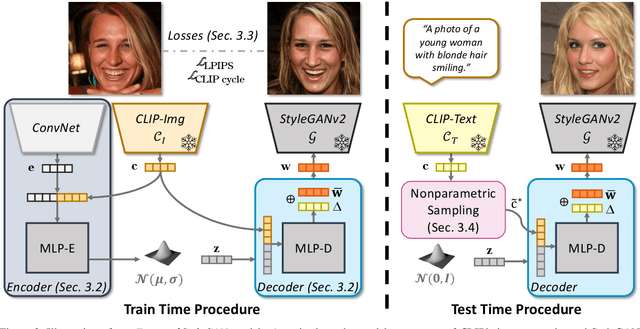
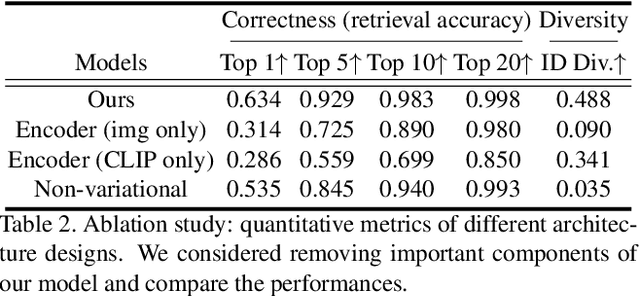

We propose Fast text2StyleGAN, a natural language interface that adapts pre-trained GANs for text-guided human face synthesis. Leveraging the recent advances in Contrastive Language-Image Pre-training (CLIP), no text data is required during training. Fast text2StyleGAN is formulated as a conditional variational autoencoder (CVAE) that provides extra control and diversity to the generated images at test time. Our model does not require re-training or fine-tuning of the GANs or CLIP when encountering new text prompts. In contrast to prior work, we do not rely on optimization at test time, making our method orders of magnitude faster than prior work. Empirically, on FFHQ dataset, our method offers faster and more accurate generation of images from natural language descriptions with varying levels of detail compared to prior work.
Inpainting at Modern Camera Resolution by Guided PatchMatch with Auto-Curation
Aug 06, 2022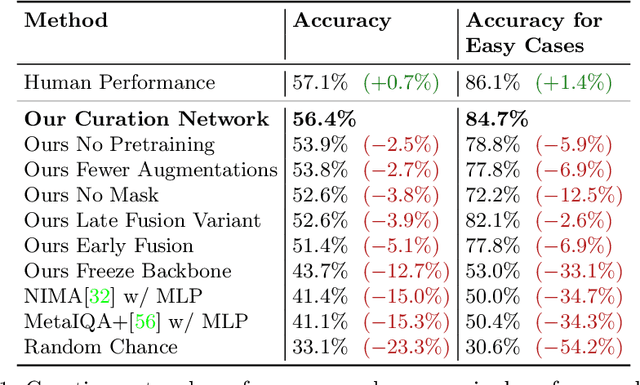

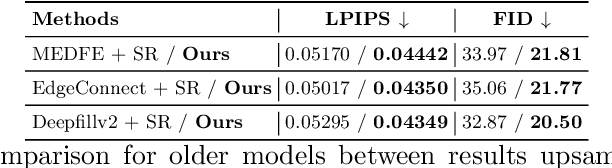

Recently, deep models have established SOTA performance for low-resolution image inpainting, but they lack fidelity at resolutions associated with modern cameras such as 4K or more, and for large holes. We contribute an inpainting benchmark dataset of photos at 4K and above representative of modern sensors. We demonstrate a novel framework that combines deep learning and traditional methods. We use an existing deep inpainting model LaMa to fill the hole plausibly, establish three guide images consisting of structure, segmentation, depth, and apply a multiply-guided PatchMatch to produce eight candidate upsampled inpainted images. Next, we feed all candidate inpaintings through a novel curation module that chooses a good inpainting by column summation on an 8x8 antisymmetric pairwise preference matrix. Our framework's results are overwhelmingly preferred by users over 8 strong baselines, with improvements of quantitative metrics up to 7.4 over the best baseline LaMa, and our technique when paired with 4 different SOTA inpainting backbones improves each such that ours is overwhelmingly preferred by users over a strong super-res baseline.
Perceptual Artifacts Localization for Inpainting
Aug 05, 2022Image inpainting is an essential task for multiple practical applications like object removal and image editing. Deep GAN-based models greatly improve the inpainting performance in structures and textures within the hole, but might also generate unexpected artifacts like broken structures or color blobs. Users perceive these artifacts to judge the effectiveness of inpainting models, and retouch these imperfect areas to inpaint again in a typical retouching workflow. Inspired by this workflow, we propose a new learning task of automatic segmentation of inpainting perceptual artifacts, and apply the model for inpainting model evaluation and iterative refinement. Specifically, we first construct a new inpainting artifacts dataset by manually annotating perceptual artifacts in the results of state-of-the-art inpainting models. Then we train advanced segmentation networks on this dataset to reliably localize inpainting artifacts within inpainted images. Second, we propose a new interpretable evaluation metric called Perceptual Artifact Ratio (PAR), which is the ratio of objectionable inpainted regions to the entire inpainted area. PAR demonstrates a strong correlation with real user preference. Finally, we further apply the generated masks for iterative image inpainting by combining our approach with multiple recent inpainting methods. Extensive experiments demonstrate the consistent decrease of artifact regions and inpainting quality improvement across the different methods.
Controllable Shadow Generation Using Pixel Height Maps
Jul 15, 2022

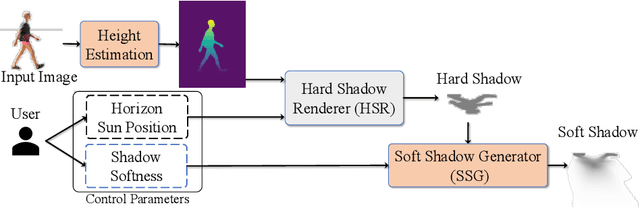
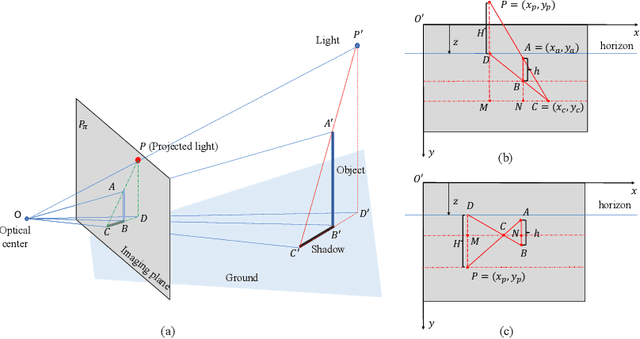
Shadows are essential for realistic image compositing. Physics-based shadow rendering methods require 3D geometries, which are not always available. Deep learning-based shadow synthesis methods learn a mapping from the light information to an object's shadow without explicitly modeling the shadow geometry. Still, they lack control and are prone to visual artifacts. We introduce pixel heigh, a novel geometry representation that encodes the correlations between objects, ground, and camera pose. The pixel height can be calculated from 3D geometries, manually annotated on 2D images, and can also be predicted from a single-view RGB image by a supervised approach. It can be used to calculate hard shadows in a 2D image based on the projective geometry, providing precise control of the shadows' direction and shape. Furthermore, we propose a data-driven soft shadow generator to apply softness to a hard shadow based on a softness input parameter. Qualitative and quantitative evaluations demonstrate that the proposed pixel height significantly improves the quality of the shadow generation while allowing for controllability.
RigNeRF: Fully Controllable Neural 3D Portraits
Jun 13, 2022
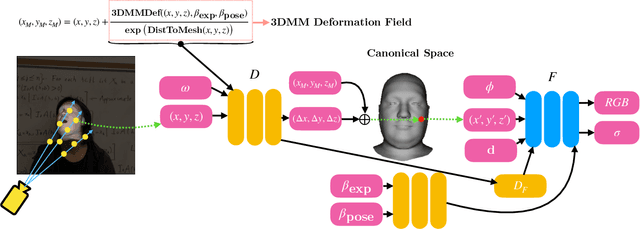

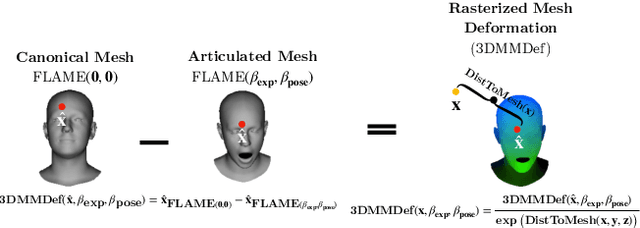
Volumetric neural rendering methods, such as neural radiance fields (NeRFs), have enabled photo-realistic novel view synthesis. However, in their standard form, NeRFs do not support the editing of objects, such as a human head, within a scene. In this work, we propose RigNeRF, a system that goes beyond just novel view synthesis and enables full control of head pose and facial expressions learned from a single portrait video. We model changes in head pose and facial expressions using a deformation field that is guided by a 3D morphable face model (3DMM). The 3DMM effectively acts as a prior for RigNeRF that learns to predict only residuals to the 3DMM deformations and allows us to render novel (rigid) poses and (non-rigid) expressions that were not present in the input sequence. Using only a smartphone-captured short video of a subject for training, we demonstrate the effectiveness of our method on free view synthesis of a portrait scene with explicit head pose and expression controls. The project page can be found here: http://shahrukhathar.github.io/2022/06/06/RigNeRF.html
ARF: Artistic Radiance Fields
Jun 13, 2022We present a method for transferring the artistic features of an arbitrary style image to a 3D scene. Previous methods that perform 3D stylization on point clouds or meshes are sensitive to geometric reconstruction errors for complex real-world scenes. Instead, we propose to stylize the more robust radiance field representation. We find that the commonly used Gram matrix-based loss tends to produce blurry results without faithful brushstrokes, and introduce a nearest neighbor-based loss that is highly effective at capturing style details while maintaining multi-view consistency. We also propose a novel deferred back-propagation method to enable optimization of memory-intensive radiance fields using style losses defined on full-resolution rendered images. Our extensive evaluation demonstrates that our method outperforms baselines by generating artistic appearance that more closely resembles the style image. Please check our project page for video results and open-source implementations: https://www.cs.cornell.edu/projects/arf/ .
BlobGAN: Spatially Disentangled Scene Representations
May 05, 2022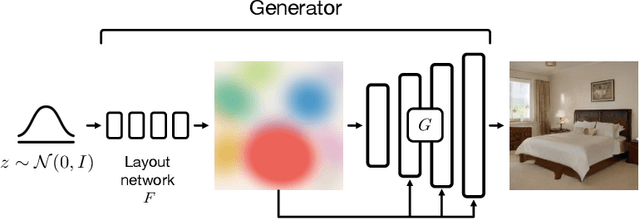
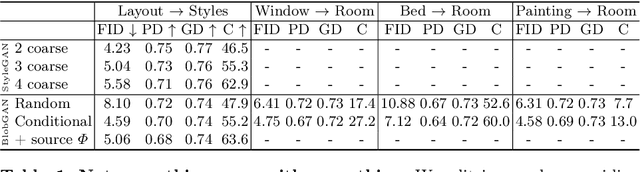
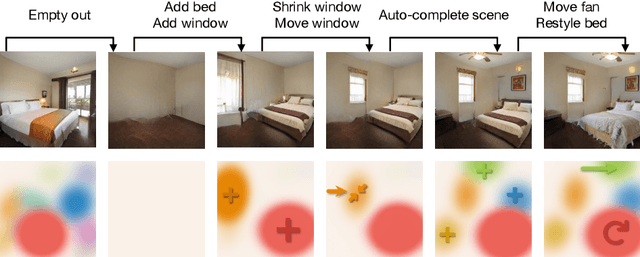
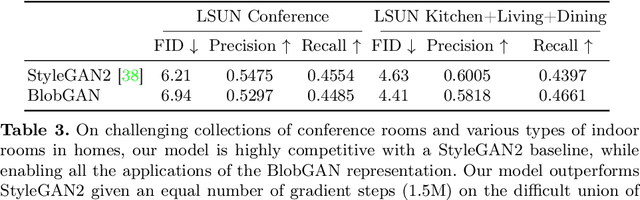
We propose an unsupervised, mid-level representation for a generative model of scenes. The representation is mid-level in that it is neither per-pixel nor per-image; rather, scenes are modeled as a collection of spatial, depth-ordered "blobs" of features. Blobs are differentiably placed onto a feature grid that is decoded into an image by a generative adversarial network. Due to the spatial uniformity of blobs and the locality inherent to convolution, our network learns to associate different blobs with different entities in a scene and to arrange these blobs to capture scene layout. We demonstrate this emergent behavior by showing that, despite training without any supervision, our method enables applications such as easy manipulation of objects within a scene (e.g., moving, removing, and restyling furniture), creation of feasible scenes given constraints (e.g., plausible rooms with drawers at a particular location), and parsing of real-world images into constituent parts. On a challenging multi-category dataset of indoor scenes, BlobGAN outperforms StyleGAN2 in image quality as measured by FID. See our project page for video results and interactive demo: http://www.dave.ml/blobgan
Any-resolution Training for High-resolution Image Synthesis
Apr 14, 2022
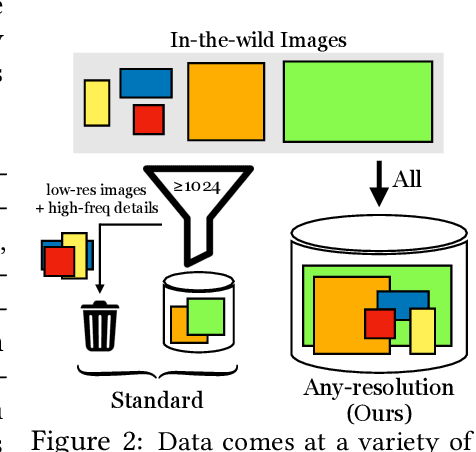
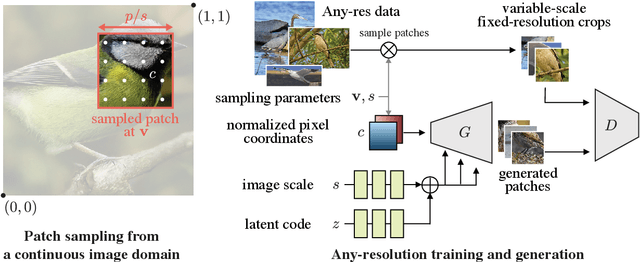
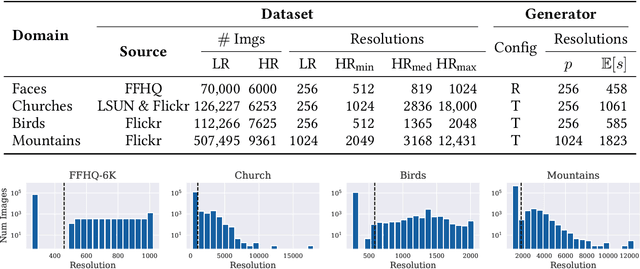
Generative models operate at fixed resolution, even though natural images come in a variety of sizes. As high-resolution details are downsampled away, and low-resolution images are discarded altogether, precious supervision is lost. We argue that every pixel matters and create datasets with variable-size images, collected at their native resolutions. Taking advantage of this data is challenging; high-resolution processing is costly, and current architectures can only process fixed-resolution data. We introduce continuous-scale training, a process that samples patches at random scales to train a new generator with variable output resolutions. First, conditioning the generator on a target scale allows us to generate higher resolutions images than previously possible, without adding layers to the model. Second, by conditioning on continuous coordinates, we can sample patches that still obey a consistent global layout, which also allows for scalable training at higher resolutions. Controlled FFHQ experiments show our method takes advantage of the multi-resolution training data better than discrete multi-scale approaches, achieving better FID scores and cleaner high-frequency details. We also train on other natural image domains including churches, mountains, and birds, and demonstrate arbitrary scale synthesis with both coherent global layouts and realistic local details, going beyond 2K resolution in our experiments. Our project page is available at: https://chail.github.io/anyres-gan/.
Neural Neighbor Style Transfer
Mar 24, 2022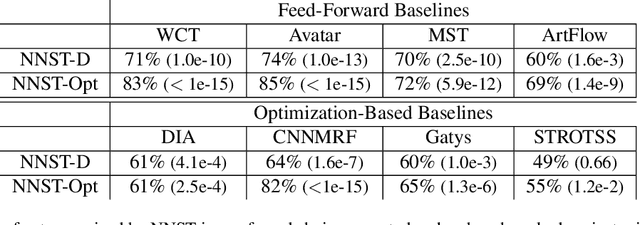
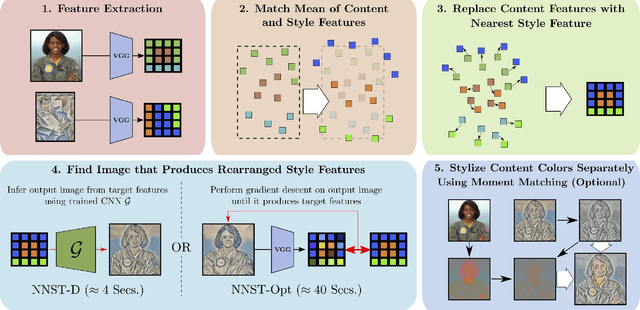


We propose Neural Neighbor Style Transfer (NNST), a pipeline that offers state-of-the-art quality, generalization, and competitive efficiency for artistic style transfer. Our approach is based on explicitly replacing neural features extracted from the content input (to be stylized) with those from a style exemplar, then synthesizing the final output based on these rearranged features. While the spirit of our approach is similar to prior work, we show that our design decisions dramatically improve the final visual quality.
CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Mar 22, 2022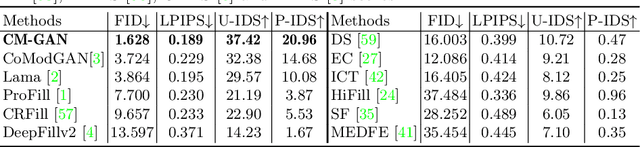
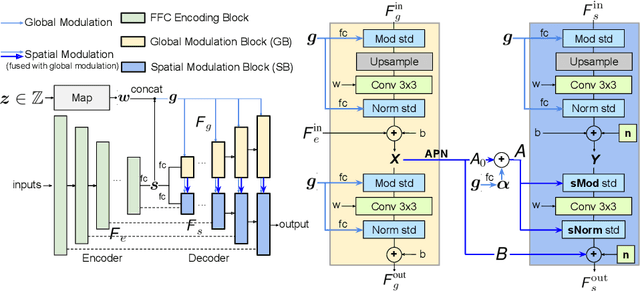
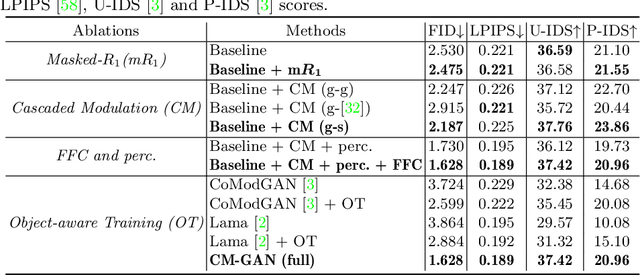

Recent image inpainting methods have made great progress but often struggle to generate plausible image structures when dealing with large holes in complex images. This is partially due to the lack of effective network structures that can capture both the long-range dependency and high-level semantics of an image. To address these problems, we propose cascaded modulation GAN (CM-GAN), a new network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a StyleGAN-like decoder with a novel cascaded global-spatial modulation block at each scale level. In each decoder block, global modulation is first applied to perform coarse semantic-aware structure synthesis, then spatial modulation is applied on the output of global modulation to further adjust the feature map in a spatially adaptive fashion. In addition, we design an object-aware training scheme to prevent the network from hallucinating new objects inside holes, fulfilling the needs of object removal tasks in real-world scenarios. Extensive experiments are conducted to show that our method significantly outperforms existing methods in both quantitative and qualitative evaluation.