 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn advanced spatio-temporal convolutional recurrent neural network for storm surge predictions
Apr 18, 2022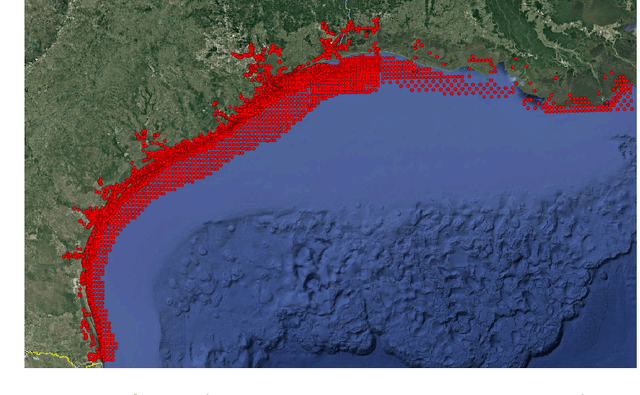
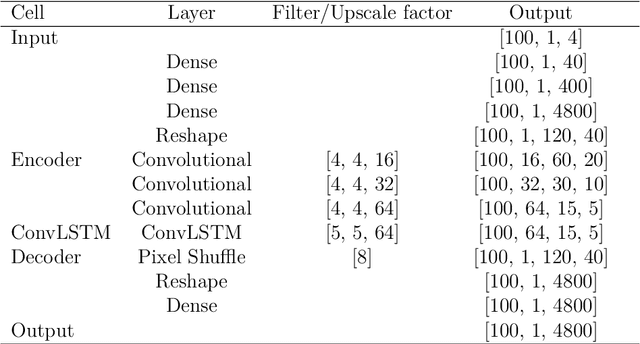
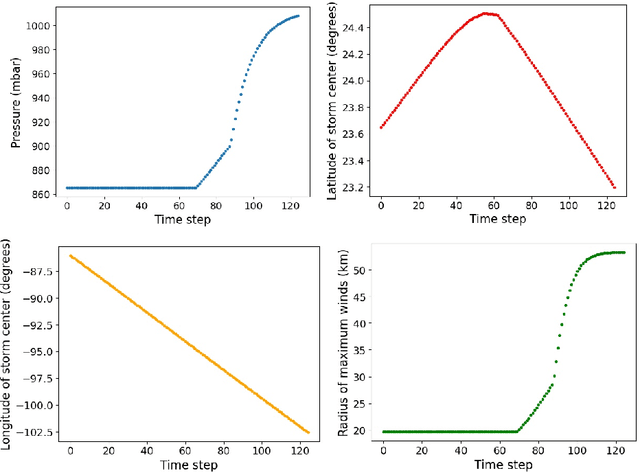

In this research paper, we study the capability of artificial neural network models to emulate storm surge based on the storm track/size/intensity history, leveraging a database of synthetic storm simulations. Traditionally, Computational Fluid Dynamics solvers are employed to numerically solve the storm surge governing equations that are Partial Differential Equations and are generally very costly to simulate. This study presents a neural network model that can predict storm surge, informed by a database of synthetic storm simulations. This model can serve as a fast and affordable emulator for the very expensive CFD solvers. The neural network model is trained with the storm track parameters used to drive the CFD solvers, and the output of the model is the time-series evolution of the predicted storm surge across multiple nodes within the spatial domain of interest. Once the model is trained, it can be deployed for further predictions based on new storm track inputs. The developed neural network model is a time-series model, a Long short-term memory, a variation of Recurrent Neural Network, which is enriched with Convolutional Neural Networks. The convolutional neural network is employed to capture the correlation of data spatially. Therefore, the temporal and spatial correlations of data are captured by the combination of the mentioned models, the ConvLSTM model. As the problem is a sequence to sequence time-series problem, an encoder-decoder ConvLSTM model is designed. Some other techniques in the process of model training are also employed to enrich the model performance. The results show the proposed convolutional recurrent neural network outperforms the Gaussian Process implementation for the examined synthetic storm database.
Intervertebral Disc Labeling With Learning Shape Information, A Look Once Approach
Apr 06, 2022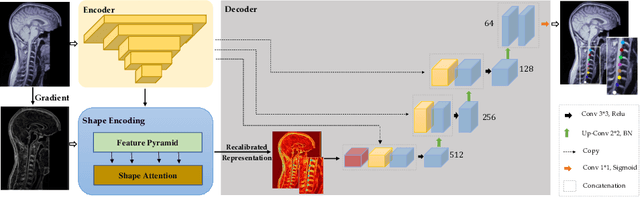

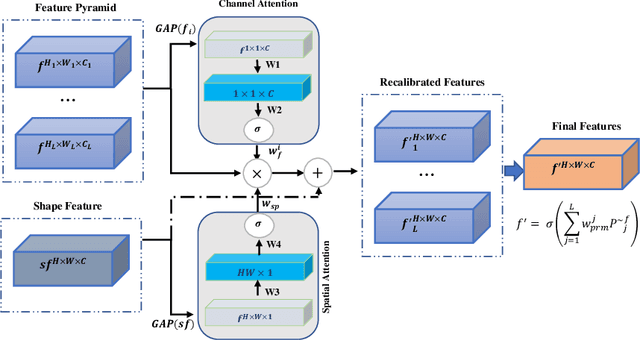

Accurate and automatic segmentation of intervertebral discs from medical images is a critical task for the assessment of spine-related diseases such as osteoporosis, vertebral fractures, and intervertebral disc herniation. To date, various approaches have been developed in the literature which routinely relies on detecting the discs as the primary step. A disadvantage of many cohort studies is that the localization algorithm also yields false-positive detections. In this study, we aim to alleviate this problem by proposing a novel U-Net-based structure to predict a set of candidates for intervertebral disc locations. In our design, we integrate the image shape information (image gradients) to encourage the model to learn rich and generic geometrical information. This additional signal guides the model to selectively emphasize the contextual representation and suppress the less discriminative features. On the post-processing side, to further decrease the false positive rate, we propose a permutation invariant 'look once' model, which accelerates the candidate recovery procedure. In comparison with previous studies, our proposed approach does not need to perform the selection in an iterative fashion. The proposed method was evaluated on the spine generic public multi-center dataset and demonstrated superior performance compared to previous work. We have provided the implementation code in https://github.com/rezazad68/intervertebral-lookonce
Convolutional generative adversarial imputation networks for spatio-temporal missing data in storm surge simulations
Nov 26, 2021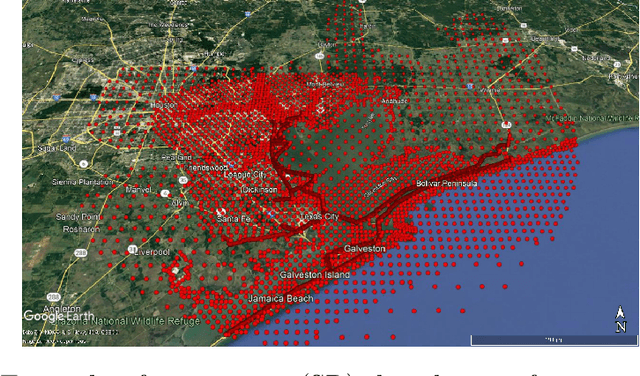
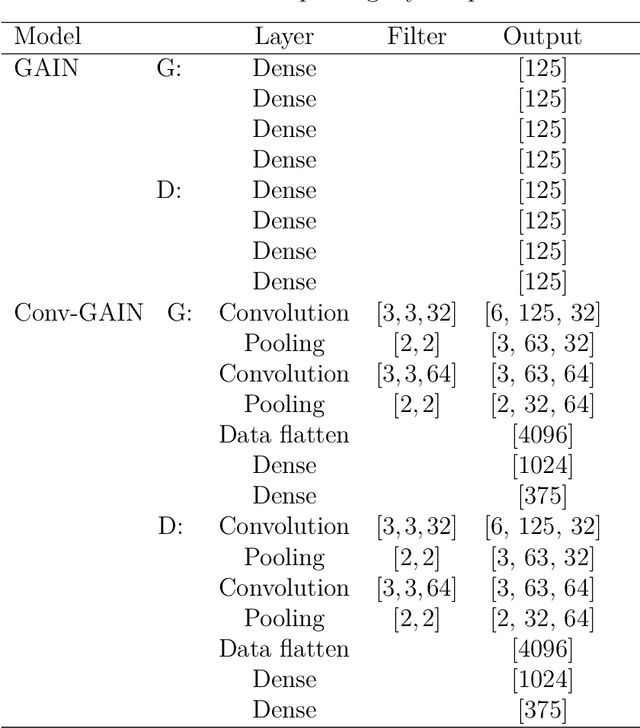
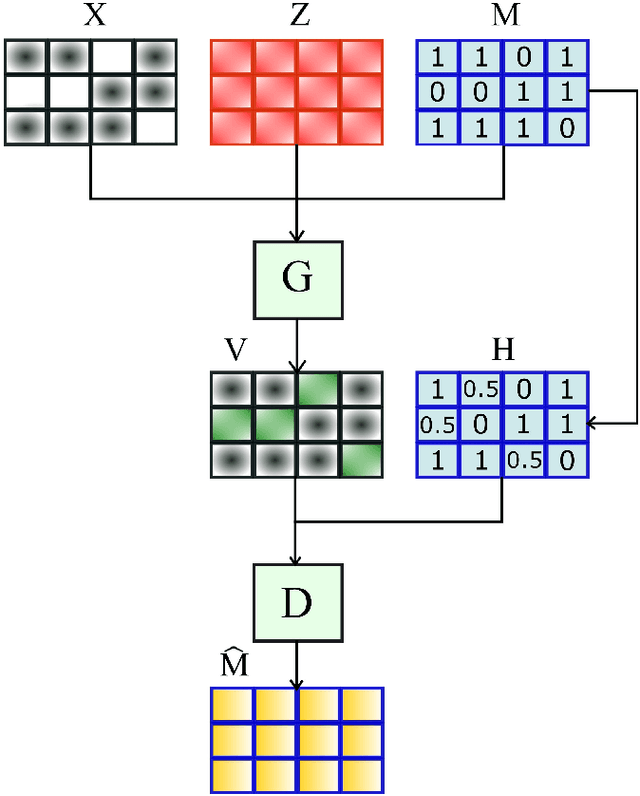

Imputation of missing data is a task that plays a vital role in a number of engineering and science applications. Often such missing data arise in experimental observations from limitations of sensors or post-processing transformation errors. Other times they arise from numerical and algorithmic constraints in computer simulations. One such instance and the application emphasis of this paper are numerical simulations of storm surge. The simulation data corresponds to time-series surge predictions over a number of save points within the geographic domain of interest, creating a spatio-temporal imputation problem where the surge points are heavily correlated spatially and temporally, and the missing values regions are structurally distributed at random. Very recently, machine learning techniques such as neural network methods have been developed and employed for missing data imputation tasks. Generative Adversarial Nets (GANs) and GAN-based techniques have particularly attracted attention as unsupervised machine learning methods. In this study, the Generative Adversarial Imputation Nets (GAIN) performance is improved by applying convolutional neural networks instead of fully connected layers to better capture the correlation of data and promote learning from the adjacent surge points. Another adjustment to the method needed specifically for the studied data is to consider the coordinates of the points as additional features to provide the model more information through the convolutional layers. We name our proposed method as Convolutional Generative Adversarial Imputation Nets (Conv-GAIN). The proposed method's performance by considering the improvements and adaptations required for the storm surge data is assessed and compared to the original GAIN and a few other techniques. The results show that Conv-GAIN has better performance than the alternative methods on the studied data.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Longitudinal Correlation Analysis for Decoding Multi-Modal Brain Development
Jul 10, 2021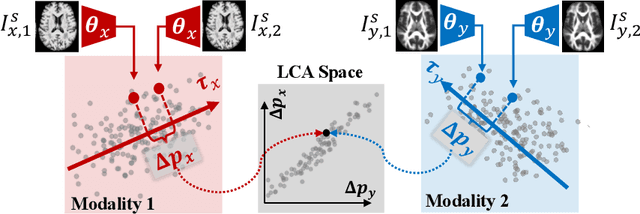
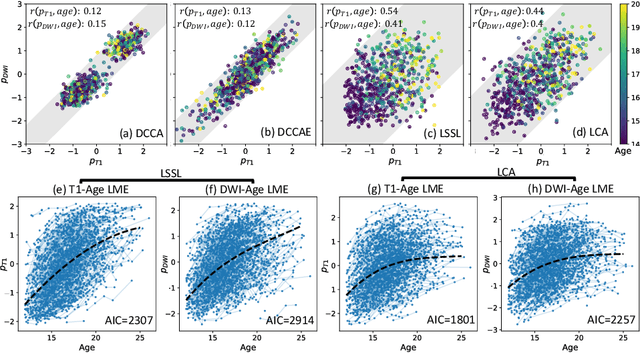
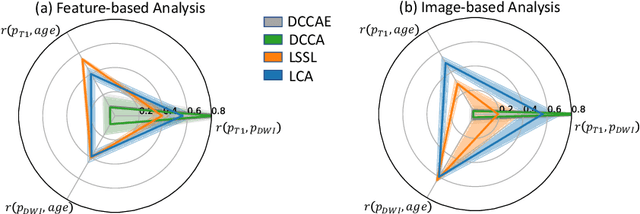
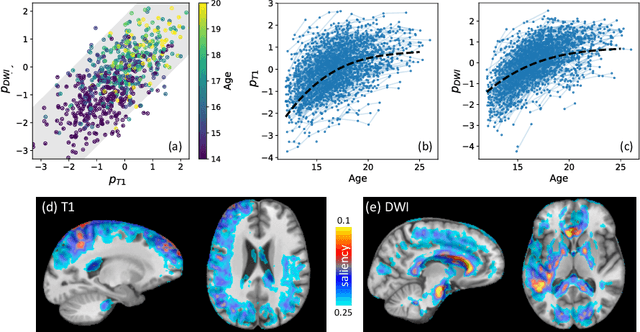
Starting from childhood, the human brain restructures and rewires throughout life. Characterizing such complex brain development requires effective analysis of longitudinal and multi-modal neuroimaging data. Here, we propose such an analysis approach named Longitudinal Correlation Analysis (LCA). LCA couples the data of two modalities by first reducing the input from each modality to a latent representation based on autoencoders. A self-supervised strategy then relates the two latent spaces by jointly disentangling two directions, one in each space, such that the longitudinal changes in latent representations along those directions are maximally correlated between modalities. We applied LCA to analyze the longitudinal T1-weighted and diffusion-weighted MRIs of 679 youths from the National Consortium on Alcohol and Neurodevelopment in Adolescence. Unlike existing approaches that focus on either cross-sectional or single-modal modeling, LCA successfully unraveled coupled macrostructural and microstructural brain development from morphological and diffusivity features extracted from the data. A retesting of LCA on raw 3D image volumes of those subjects successfully replicated the findings from the feature-based analysis. Lastly, the developmental effects revealed by LCA were inline with the current understanding of maturational patterns of the adolescent brain.
Rethinking Architecture Design for Tackling Data Heterogeneity in Federated Learning
Jun 10, 2021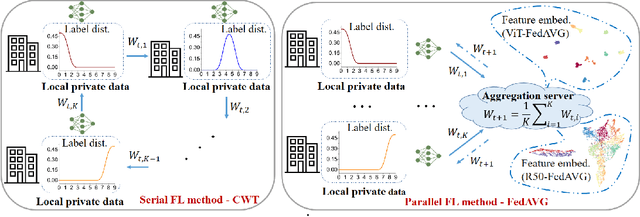
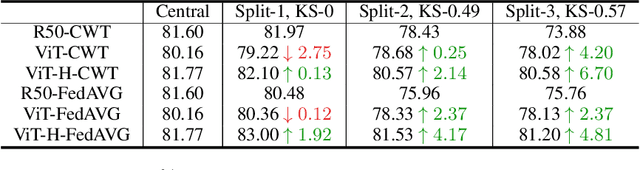
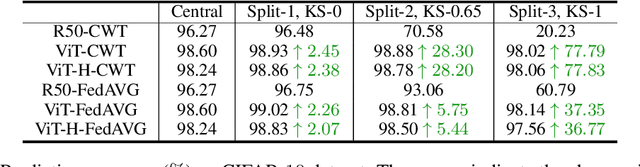

Federated learning is an emerging research paradigm enabling collaborative training of machine learning models among different organizations while keeping data private at each institution. Despite recent progress, there remain fundamental challenges such as lack of convergence and potential for catastrophic forgetting in federated learning across real-world heterogeneous devices. In this paper, we demonstrate that attention-based architectures (e.g., Transformers) are fairly robust to distribution shifts and hence improve federated learning over heterogeneous data. Concretely, we conduct the first rigorous empirical investigation of different neural architectures across a range of federated algorithms, real-world benchmarks, and heterogeneous data splits. Our experiments show that simply replacing convolutional networks with Transformers can greatly reduce catastrophic forgetting of previous devices, accelerate convergence, and reach a better global model, especially when dealing with heterogeneous data. We will release our code and pretrained models at https://github.com/Liangqiong/ViT-FL-main to encourage future exploration in robust architectures as an alternative to current research efforts on the optimization front.
Home Action Genome: Cooperative Compositional Action Understanding
May 11, 2021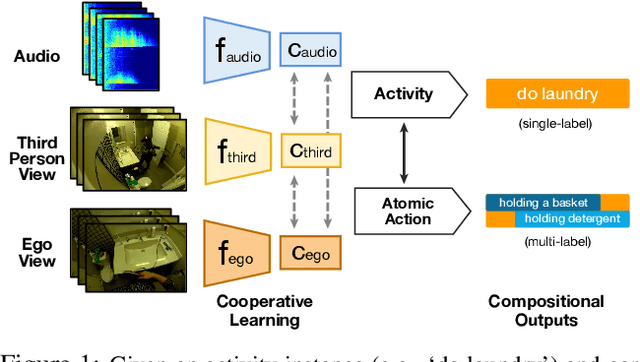
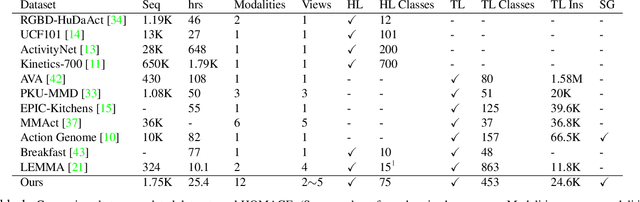

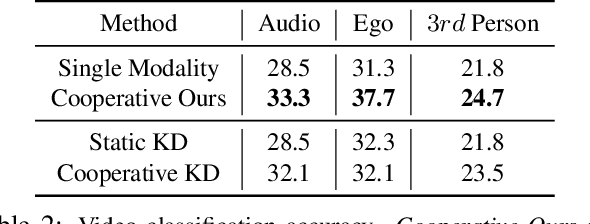
Existing research on action recognition treats activities as monolithic events occurring in videos. Recently, the benefits of formulating actions as a combination of atomic-actions have shown promise in improving action understanding with the emergence of datasets containing such annotations, allowing us to learn representations capturing this information. However, there remains a lack of studies that extend action composition and leverage multiple viewpoints and multiple modalities of data for representation learning. To promote research in this direction, we introduce Home Action Genome (HOMAGE): a multi-view action dataset with multiple modalities and view-points supplemented with hierarchical activity and atomic action labels together with dense scene composition labels. Leveraging rich multi-modal and multi-view settings, we propose Cooperative Compositional Action Understanding (CCAU), a cooperative learning framework for hierarchical action recognition that is aware of compositional action elements. CCAU shows consistent performance improvements across all modalities. Furthermore, we demonstrate the utility of co-learning compositions in few-shot action recognition by achieving 28.6% mAP with just a single sample.
Metadata Normalization
May 05, 2021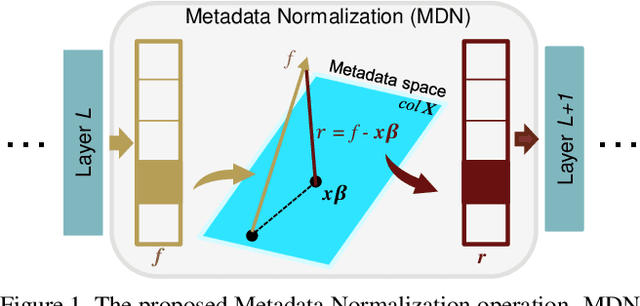
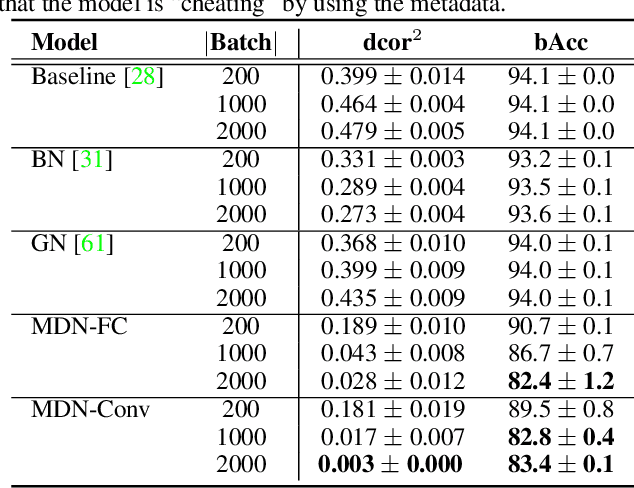

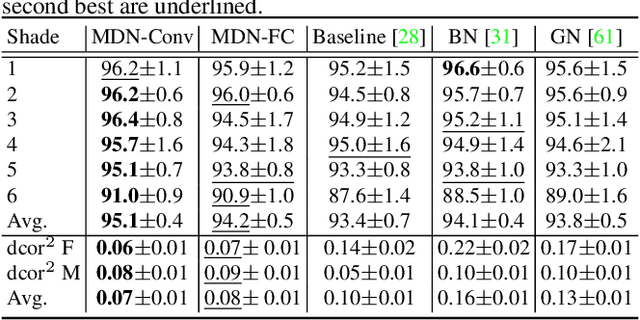
Batch Normalization (BN) and its variants have delivered tremendous success in combating the covariate shift induced by the training step of deep learning methods. While these techniques normalize feature distributions by standardizing with batch statistics, they do not correct the influence on features from extraneous variables or multiple distributions. Such extra variables, referred to as metadata here, may create bias or confounding effects (e.g., race when classifying gender from face images). We introduce the Metadata Normalization (MDN) layer, a new batch-level operation which can be used end-to-end within the training framework, to correct the influence of metadata on feature distributions. MDN adopts a regression analysis technique traditionally used for preprocessing to remove (regress out) the metadata effects on model features during training. We utilize a metric based on distance correlation to quantify the distribution bias from the metadata and demonstrate that our method successfully removes metadata effects on four diverse settings: one synthetic, one 2D image, one video, and one 3D medical image dataset.
CoCon: Cooperative-Contrastive Learning
Apr 30, 2021

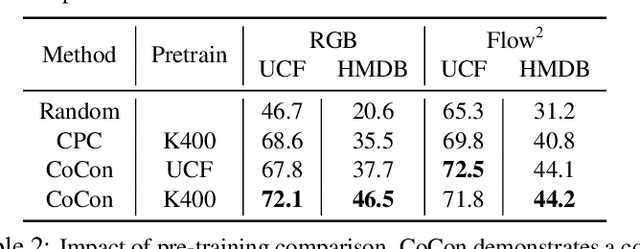
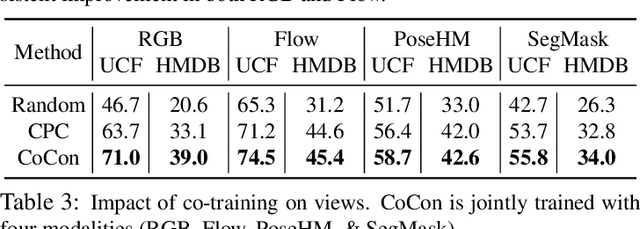
Labeling videos at scale is impractical. Consequently, self-supervised visual representation learning is key for efficient video analysis. Recent success in learning image representations suggests contrastive learning is a promising framework to tackle this challenge. However, when applied to real-world videos, contrastive learning may unknowingly lead to the separation of instances that contain semantically similar events. In our work, we introduce a cooperative variant of contrastive learning to utilize complementary information across views and address this issue. We use data-driven sampling to leverage implicit relationships between multiple input video views, whether observed (e.g. RGB) or inferred (e.g. flow, segmentation masks, poses). We are one of the firsts to explore exploiting inter-instance relationships to drive learning. We experimentally evaluate our representations on the downstream task of action recognition. Our method achieves competitive performance on standard benchmarks (UCF101, HMDB51, Kinetics400). Furthermore, qualitative experiments illustrate that our models can capture higher-order class relationships.
TRiPOD: Human Trajectory and Pose Dynamics Forecasting in the Wild
Apr 08, 2021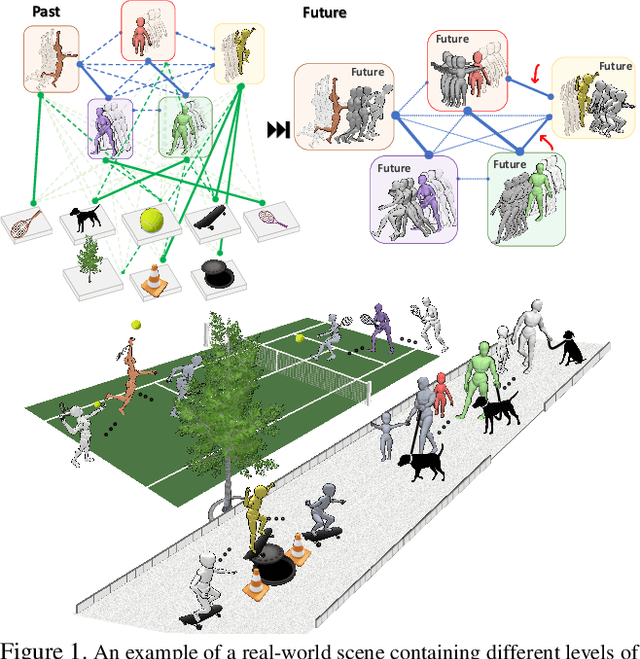
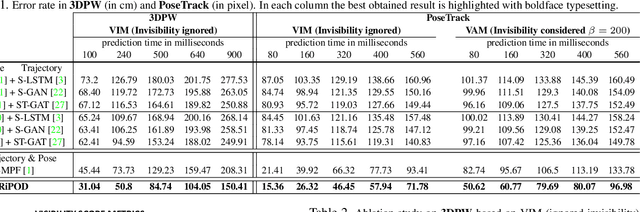
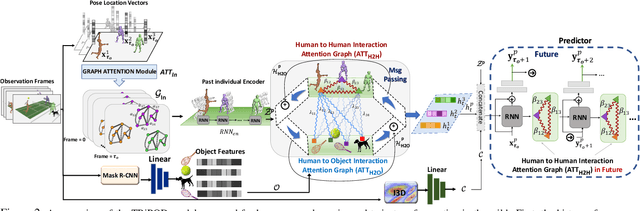
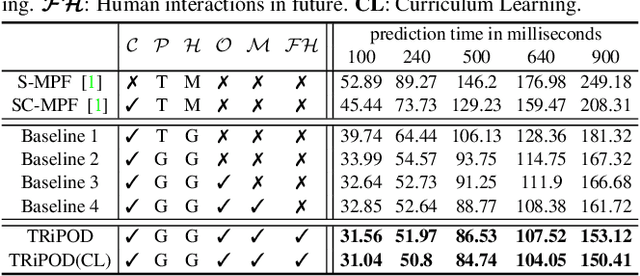
Joint forecasting of human trajectory and pose dynamics is a fundamental building block of various applications ranging from robotics and autonomous driving to surveillance systems. Predicting body dynamics requires capturing subtle information embedded in the humans' interactions with each other and with the objects present in the scene. In this paper, we propose a novel TRajectory and POse Dynamics (nicknamed TRiPOD) method based on graph attentional networks to model the human-human and human-object interactions both in the input space and the output space (decoded future output). The model is supplemented by a message passing interface over the graphs to fuse these different levels of interactions efficiently. Furthermore, to incorporate a real-world challenge, we propound to learn an indicator representing whether an estimated body joint is visible/invisible at each frame, e.g. due to occlusion or being outside the sensor field of view. Finally, we introduce a new benchmark for this joint task based on two challenging datasets (PoseTrack and 3DPW) and propose evaluation metrics to measure the effectiveness of predictions in the global space, even when there are invisible cases of joints. Our evaluation shows that TRiPOD outperforms all prior work and state-of-the-art specifically designed for each of the trajectory and pose forecasting tasks.