 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Transformers: A Survey
Jul 13, 2024



Graph transformers are a recent advancement in machine learning, offering a new class of neural network models for graph-structured data. The synergy between transformers and graph learning demonstrates strong performance and versatility across various graph-related tasks. This survey provides an in-depth review of recent progress and challenges in graph transformer research. We begin with foundational concepts of graphs and transformers. We then explore design perspectives of graph transformers, focusing on how they integrate graph inductive biases and graph attention mechanisms into the transformer architecture. Furthermore, we propose a taxonomy classifying graph transformers based on depth, scalability, and pre-training strategies, summarizing key principles for effective development of graph transformer models. Beyond technical analysis, we discuss the applications of graph transformer models for node-level, edge-level, and graph-level tasks, exploring their potential in other application scenarios as well. Finally, we identify remaining challenges in the field, such as scalability and efficiency, generalization and robustness, interpretability and explainability, dynamic and complex graphs, as well as data quality and diversity, charting future directions for graph transformer research.
Take its Essence, Discard its Dross! Debiasing for Toxic Language Detection via Counterfactual Causal Effect
Jun 03, 2024



Current methods of toxic language detection (TLD) typically rely on specific tokens to conduct decisions, which makes them suffer from lexical bias, leading to inferior performance and generalization. Lexical bias has both "useful" and "misleading" impacts on understanding toxicity. Unfortunately, instead of distinguishing between these impacts, current debiasing methods typically eliminate them indiscriminately, resulting in a degradation in the detection accuracy of the model. To this end, we propose a Counterfactual Causal Debiasing Framework (CCDF) to mitigate lexical bias in TLD. It preserves the "useful impact" of lexical bias and eliminates the "misleading impact". Specifically, we first represent the total effect of the original sentence and biased tokens on decisions from a causal view. We then conduct counterfactual inference to exclude the direct causal effect of lexical bias from the total effect. Empirical evaluations demonstrate that the debiased TLD model incorporating CCDF achieves state-of-the-art performance in both accuracy and fairness compared to competitive baselines applied on several vanilla models. The generalization capability of our model outperforms current debiased models for out-of-distribution data.
Enhancing Textual Personality Detection toward Social Media: Integrating Long-term and Short-term Perspectives
Apr 23, 2024



Textual personality detection aims to identify personality characteristics by analyzing user-generated content toward social media platforms. Numerous psychological literature highlighted that personality encompasses both long-term stable traits and short-term dynamic states. However, existing studies often concentrate only on either long-term or short-term personality representations, without effectively combining both aspects. This limitation hinders a comprehensive understanding of individuals' personalities, as both stable traits and dynamic states are vital. To bridge this gap, we propose a Dual Enhanced Network(DEN) to jointly model users' long-term and short-term personality for textual personality detection. In DEN, a Long-term Personality Encoding is devised to effectively model long-term stable personality traits. Short-term Personality Encoding is presented to capture short-term dynamic personality states. The Bi-directional Interaction component facilitates the integration of both personality aspects, allowing for a comprehensive representation of the user's personality. Experimental results on two personality detection datasets demonstrate the effectiveness of the DEN model and the benefits of considering both the dynamic and stable nature of personality characteristics for textual personality detection.
CoLafier: Collaborative Noisy Label Purifier With Local Intrinsic Dimensionality Guidance
Jan 10, 2024Deep neural networks (DNNs) have advanced many machine learning tasks, but their performance is often harmed by noisy labels in real-world data. Addressing this, we introduce CoLafier, a novel approach that uses Local Intrinsic Dimensionality (LID) for learning with noisy labels. CoLafier consists of two subnets: LID-dis and LID-gen. LID-dis is a specialized classifier. Trained with our uniquely crafted scheme, LID-dis consumes both a sample's features and its label to predict the label - which allows it to produce an enhanced internal representation. We observe that LID scores computed from this representation effectively distinguish between correct and incorrect labels across various noise scenarios. In contrast to LID-dis, LID-gen, functioning as a regular classifier, operates solely on the sample's features. During training, CoLafier utilizes two augmented views per instance to feed both subnets. CoLafier considers the LID scores from the two views as produced by LID-dis to assign weights in an adapted loss function for both subnets. Concurrently, LID-gen, serving as classifier, suggests pseudo-labels. LID-dis then processes these pseudo-labels along with two views to derive LID scores. Finally, these LID scores along with the differences in predictions from the two subnets guide the label update decisions. This dual-view and dual-subnet approach enhances the overall reliability of the framework. Upon completion of the training, we deploy the LID-gen subnet of CoLafier as the final classification model. CoLafier demonstrates improved prediction accuracy, surpassing existing methods, particularly under severe label noise. For more details, see the code at https://github.com/zdy93/CoLafier.
Image Restoration Through Generalized Ornstein-Uhlenbeck Bridge
Dec 16, 2023



Diffusion models possess powerful generative capabilities enabling the mapping of noise to data using reverse stochastic differential equations. However, in image restoration tasks, the focus is on the mapping relationship from low-quality images to high-quality images. To address this, we introduced the Generalized Ornstein-Uhlenbeck Bridge (GOUB) model. By leveraging the natural mean-reverting property of the generalized OU process and further adjusting the variance of its steady-state distribution through the Doob's h-transform, we achieve diffusion mappings from point to point with minimal cost. This allows for end-to-end training, enabling the recovery of high-quality images from low-quality ones. Additionally, we uncovered the mathematical essence of some bridge models, all of which are special cases of the GOUB and empirically demonstrated the optimality of our proposed models. Furthermore, benefiting from our distinctive parameterization mechanism, we proposed the Mean-ODE model that is better at capturing pixel-level information and structural perceptions. Experimental results show that both models achieved state-of-the-art results in various tasks, including inpainting, deraining, and super-resolution. Code is available at https://github.com/Hammour-steak/GOUB.
UCE-FID: Using Large Unlabeled, Medium Crowdsourced-Labeled, and Small Expert-Labeled Tweets for Foodborne Illness Detection
Dec 02, 2023Foodborne illnesses significantly impact public health. Deep learning surveillance applications using social media data aim to detect early warning signals. However, labeling foodborne illness-related tweets for model training requires extensive human resources, making it challenging to collect a sufficient number of high-quality labels for tweets within a limited budget. The severe class imbalance resulting from the scarcity of foodborne illness-related tweets among the vast volume of social media further exacerbates the problem. Classifiers trained on a class-imbalanced dataset are biased towards the majority class, making accurate detection difficult. To overcome these challenges, we propose EGAL, a deep learning framework for foodborne illness detection that uses small expert-labeled tweets augmented by crowdsourced-labeled and massive unlabeled data. Specifically, by leveraging tweets labeled by experts as a reward set, EGAL learns to assign a weight of zero to incorrectly labeled tweets to mitigate their negative influence. Other tweets receive proportionate weights to counter-balance the unbalanced class distribution. Extensive experiments on real-world \textit{TWEET-FID} data show that EGAL outperforms strong baseline models across different settings, including varying expert-labeled set sizes and class imbalance ratios. A case study on a multistate outbreak of Salmonella Typhimurium infection linked to packaged salad greens demonstrates how the trained model captures relevant tweets offering valuable outbreak insights. EGAL, funded by the U.S. Department of Agriculture (USDA), has the potential to be deployed for real-time analysis of tweet streaming, contributing to foodborne illness outbreak surveillance efforts.
FATA-Trans: Field And Time-Aware Transformer for Sequential Tabular Data
Oct 20, 2023



Sequential tabular data is one of the most commonly used data types in real-world applications. Different from conventional tabular data, where rows in a table are independent, sequential tabular data contains rich contextual and sequential information, where some fields are dynamically changing over time and others are static. Existing transformer-based approaches analyzing sequential tabular data overlook the differences between dynamic and static fields by replicating and filling static fields into each transformer, and ignore temporal information between rows, which leads to three major disadvantages: (1) computational overhead, (2) artificially simplified data for masked language modeling pre-training task that may yield less meaningful representations, and (3) disregarding the temporal behavioral patterns implied by time intervals. In this work, we propose FATA-Trans, a model with two field transformers for modeling sequential tabular data, where each processes static and dynamic field information separately. FATA-Trans is field- and time-aware for sequential tabular data. The field-type embedding in the method enables FATA-Trans to capture differences between static and dynamic fields. The time-aware position embedding exploits both order and time interval information between rows, which helps the model detect underlying temporal behavior in a sequence. Our experiments on three benchmark datasets demonstrate that the learned representations from FATA-Trans consistently outperform state-of-the-art solutions in the downstream tasks. We also present visualization studies to highlight the insights captured by the learned representations, enhancing our understanding of the underlying data. Our codes are available at https://github.com/zdy93/FATA-Trans.
EVE: Efficient Vision-Language Pre-training with Masked Prediction and Modality-Aware MoE
Aug 23, 2023



Building scalable vision-language models to learn from diverse, multimodal data remains an open challenge. In this paper, we introduce an Efficient Vision-languagE foundation model, namely EVE, which is one unified multimodal Transformer pre-trained solely by one unified pre-training task. Specifically, EVE encodes both vision and language within a shared Transformer network integrated with modality-aware sparse Mixture-of-Experts (MoE) modules, which capture modality-specific information by selectively switching to different experts. To unify pre-training tasks of vision and language, EVE performs masked signal modeling on image-text pairs to reconstruct masked signals, i.e., image pixels and text tokens, given visible signals. This simple yet effective pre-training objective accelerates training by 3.5x compared to the model pre-trained with Image-Text Contrastive and Image-Text Matching losses. Owing to the combination of the unified architecture and pre-training task, EVE is easy to scale up, enabling better downstream performance with fewer resources and faster training speed. Despite its simplicity, EVE achieves state-of-the-art performance on various vision-language downstream tasks, including visual question answering, visual reasoning, and image-text retrieval.
TWEET-FID: An Annotated Dataset for Multiple Foodborne Illness Detection Tasks
May 22, 2022

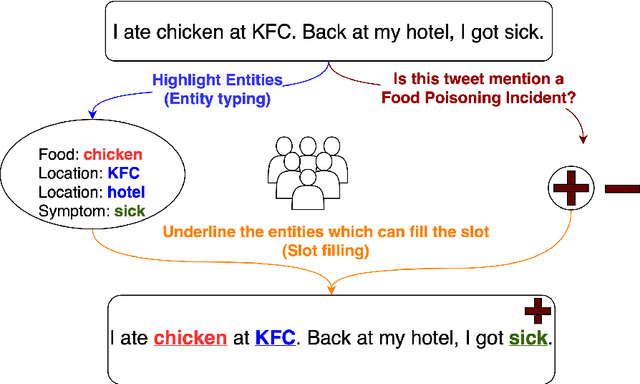
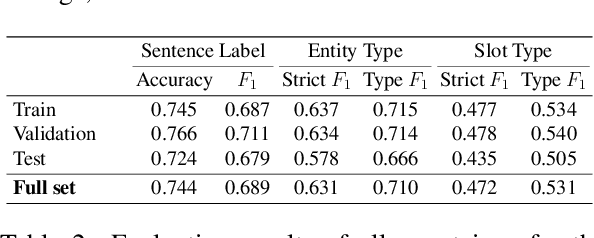
Foodborne illness is a serious but preventable public health problem -- with delays in detecting the associated outbreaks resulting in productivity loss, expensive recalls, public safety hazards, and even loss of life. While social media is a promising source for identifying unreported foodborne illnesses, there is a dearth of labeled datasets for developing effective outbreak detection models. To accelerate the development of machine learning-based models for foodborne outbreak detection, we thus present TWEET-FID (TWEET-Foodborne Illness Detection), the first publicly available annotated dataset for multiple foodborne illness incident detection tasks. TWEET-FID collected from Twitter is annotated with three facets: tweet class, entity type, and slot type, with labels produced by experts as well as by crowdsource workers. We introduce several domain tasks leveraging these three facets: text relevance classification (TRC), entity mention detection (EMD), and slot filling (SF). We describe the end-to-end methodology for dataset design, creation, and labeling for supporting model development for these tasks. A comprehensive set of results for these tasks leveraging state-of-the-art single- and multi-task deep learning methods on the TWEET-FID dataset are provided. This dataset opens opportunities for future research in foodborne outbreak detection.
Surf or sleep? Understanding the influence of bedtime patterns on campus
Feb 18, 2022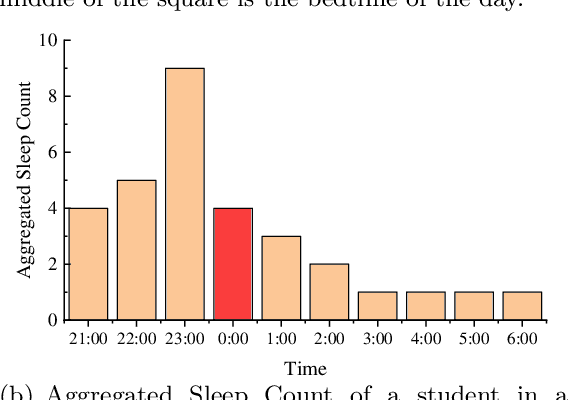

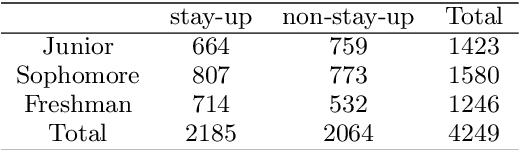
Poor sleep habits may cause serious problems of mind and body, and it is a commonly observed issue for college students due to study workload as well as peer and social influence. Understanding its impact and identifying students with poor sleep habits matters a lot in educational management. Most of the current research is either based on self-reports and questionnaires, suffering from a small sample size and social desirability bias, or the methods used are not suitable for the education system. In this paper, we develop a general data-driven method for identifying students' sleep patterns according to their Internet access pattern stored in the education management system and explore its influence from various aspects. First, we design a Possion-based probabilistic mixture model to cluster students according to the distribution of bedtime and identify students who are used to staying up late. Second, we profile students from five aspects (including eight dimensions) based on campus-behavior data and build Bayesian networks to explore the relationship between behavioral characteristics and sleeping habits. Finally, we test the predictability of sleeping habits. This paper not only contributes to the understanding of student sleep from a cognitive and behavioral perspective but also presents a new approach that provides an effective framework for various educational institutions to detect the sleeping patterns of students.