 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuvion VL: A Multimodal Foundation Model for Adversarial Content and AI Safety
Jun 23, 2026General-purpose models often struggle to reliably identify and understand real-world multimodal risks, largely due to the inherent multimodal adversarial nature of content and AI safety. We present Yuvion VL, a family of multimodal large language models purpose-built for content and AI safety, with both instruction-tuned and reasoning-oriented variants. Yuvion VL addresses this gap by treating safety as an inherently adversarial and multimodal problem and designing the entire pipeline around adversarial robustness. For data construction, we develop an automated pipeline integrating adversarial-aware data synthesis with multi-stage quality control, producing large-scale, high-quality multimodal samples augmented with domain knowledge and reasoning annotations. For training, we adopt a three-stage pipeline that includes continued pretraining for risk-concept cross-modal alignment, instruct post-training for production-grade safety tasks, and reasoning post-training for enhanced interpretability and performance in complex tasks. We further introduce Confuse-then-Contrast Fine-Tuning, a contrastive framework that mines model-specific confusions and constructs multi-image contrastive groups to enforce explicit discrimination of fine-grained visual-semantic elements, enabling the model to distinguish between visually similar cases with different safety implications in adversarial safety tasks. To support rigorous evaluation, we further introduce Yuvion VL RiskEval (YVRE), a collection of benchmarks covering diverse open and internal evaluations, with a focus on content and AI safety, adversarial robustness, and real-world capability requirements. Experiments show that Yuvion VL-32B achieves industry-leading safety performance, surpassing comparably sized open-source models and best closed-source commercial models, while maintaining comparable general capabilities.
Foundation Protocol: A Coordination Layer for Agentic Society
May 22, 2026Autonomous agents are moving from tools into a layer of social infrastructure: they browse, purchase, deploy software, manage systems, and increasingly interact with one another. As these systems scale, the bottleneck shifts away from raw model capability toward coordination. Agents need to form reliable relationships, organize multi-agent work, exchange value, support an AI economy, and stay safe and accountable under real-world oversight. This paper introduces the Foundation Protocol (FP), a graph-first coordination layer for an emerging human-AI society. FP unifies heterogeneous entities, including agents, tools, resources, humans, institutions, and organizations, and supports native multi-party organization and event-based collaboration. It also provides economic primitives for metering, receipts, and settlement, and treats policy, provenance, and audit as first-class concerns. FP is designed to wrap and bridge existing protocols rather than replace them, enabling incremental adoption while reducing integration and governance overhead. The aim is to keep autonomous agency composable while keeping accountability non-negotiable, so that coordination itself can become shared infrastructure for a human-AI society that is open, pluralistic, and governable.
dots.llm1 Technical Report
Jun 06, 2025Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on 11.2T high-quality tokens and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints at every one trillion tokens, providing valuable insights into the learning dynamics of large language models.
LoRA-Null: Low-Rank Adaptation via Null Space for Large Language Models
Mar 04, 2025Low-Rank Adaptation (LoRA) is the leading parameter-efficient fine-tuning method for Large Language Models (LLMs). However, the fine-tuned LLMs encounter the issue of catastrophic forgetting of the pre-trained world knowledge. To address this issue, inspired by theoretical insights of null space, we propose LoRA-Null, i.e., Low-Rank Adaptation via null space, which builds adapters initialized from the null space of the pre-trained knowledge activation. Concretely, we randomly collect a few data samples and capture their activations after passing through the LLM layer. We perform Singular Value Decomposition on the input activations to obtain their null space. We use the projection of the pre-trained weights onto the null space as the initialization for adapters. Experimental results demonstrate that this initialization approach can effectively preserve the original pre-trained world knowledge of the LLMs during fine-tuning. Additionally, if we freeze the values of the down-projection matrices during fine-tuning, it achieves even better preservation of the pre-trained world knowledge. LoRA-Null effectively preserves pre-trained world knowledge while maintaining strong fine-tuning performance, as validated by extensive experiments on LLaMA series (LLaMA2, LLaMA3, LLaMA3.1, and LLaMA3.2) across Code, Math, and Instruction Following tasks. We also provide a theoretical guarantee for the capacity of LoRA-Null to retain pre-trained knowledge. Code is in https://github.com/HungerPWAY/LoRA-Null.
Joint Entity Linking with Deep Reinforcement Learning
Feb 01, 2019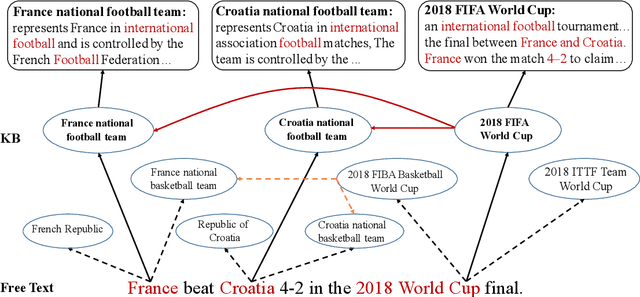
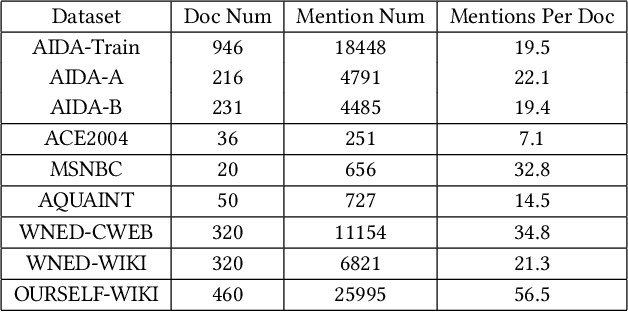
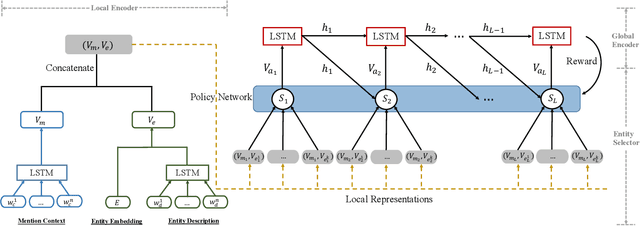
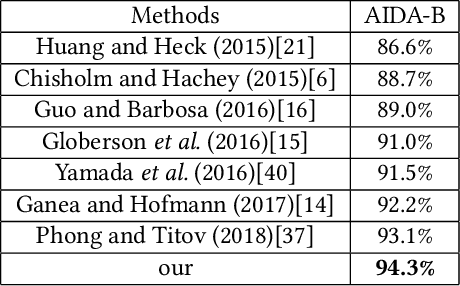
Entity linking is the task of aligning mentions to corresponding entities in a given knowledge base. Previous studies have highlighted the necessity for entity linking systems to capture the global coherence. However, there are two common weaknesses in previous global models. First, most of them calculate the pairwise scores between all candidate entities and select the most relevant group of entities as the final result. In this process, the consistency among wrong entities as well as that among right ones are involved, which may introduce noise data and increase the model complexity. Second, the cues of previously disambiguated entities, which could contribute to the disambiguation of the subsequent mentions, are usually ignored by previous models. To address these problems, we convert the global linking into a sequence decision problem and propose a reinforcement learning model which makes decisions from a global perspective. Our model makes full use of the previous referred entities and explores the long-term influence of current selection on subsequent decisions. We conduct experiments on different types of datasets, the results show that our model outperforms state-of-the-art systems and has better generalization performance.