 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
Nov 23, 2022



Computer vision models suffer from a phenomenon known as catastrophic forgetting when learning novel concepts from continuously shifting training data. Typical solutions for this continual learning problem require extensive rehearsal of previously seen data, which increases memory costs and may violate data privacy. Recently, the emergence of large-scale pre-trained vision transformer models has enabled prompting approaches as an alternative to data-rehearsal. These approaches rely on a key-query mechanism to generate prompts and have been found to be highly resistant to catastrophic forgetting in the well-established rehearsal-free continual learning setting. However, the key mechanism of these methods is not trained end-to-end with the task sequence. Our experiments show that this leads to a reduction in their plasticity, hence sacrificing new task accuracy, and inability to benefit from expanded parameter capacity. We instead propose to learn a set of prompt components which are assembled with input-conditioned weights to produce input-conditioned prompts, resulting in a novel attention-based end-to-end key-query scheme. Our experiments show that we outperform the current SOTA method DualPrompt on established benchmarks by as much as 5.4% in average accuracy. We also outperform the state of art by as much as 6.6% accuracy on a continual learning benchmark which contains both class-incremental and domain-incremental task shifts, corresponding to many practical settings.
Teaching Structured Vision&Language Concepts to Vision&Language Models
Nov 21, 2022Vision and Language (VL) models have demonstrated remarkable zero-shot performance in a variety of tasks. However, some aspects of complex language understanding still remain a challenge. We introduce the collective notion of Structured Vision&Language Concepts (SVLC) which includes object attributes, relations, and states which are present in the text and visible in the image. Recent studies have shown that even the best VL models struggle with SVLC. A possible way of fixing this issue is by collecting dedicated datasets for teaching each SVLC type, yet this might be expensive and time-consuming. Instead, we propose a more elegant data-driven approach for enhancing VL models' understanding of SVLCs that makes more effective use of existing VL pre-training datasets and does not require any additional data. While automatic understanding of image structure still remains largely unsolved, language structure is much better modeled and understood, allowing for its effective utilization in teaching VL models. In this paper, we propose various techniques based on language structure understanding that can be used to manipulate the textual part of off-the-shelf paired VL datasets. VL models trained with the updated data exhibit a significant improvement of up to 15% in their SVLC understanding with only a mild degradation in their zero-shot capabilities both when training from scratch or fine-tuning a pre-trained model.
ConStruct-VL: Data-Free Continual Structured VL Concepts Learning
Nov 17, 2022



Recently, large-scale pre-trained Vision-and-Language (VL) foundation models have demonstrated remarkable capabilities in many zero-shot downstream tasks, achieving competitive results for recognizing objects defined by as little as short text prompts. However, it has also been shown that VL models are still brittle in Structured VL Concept (SVLC) reasoning, such as the ability to recognize object attributes, states, and inter-object relations. This leads to reasoning mistakes, which need to be corrected as they occur by teaching VL models the missing SVLC skills; often this must be done using private data where the issue was found, which naturally leads to a data-free continual (no task-id) VL learning setting. In this work, we introduce the first Continual Data-Free Structured VL Concepts Learning (ConStruct-VL) benchmark and show it is challenging for many existing data-free CL strategies. We, therefore, propose a data-free method comprised of a new approach of Adversarial Pseudo-Replay (APR) which generates adversarial reminders of past tasks from past task models. To use this method efficiently, we also propose a continual parameter-efficient Layered-LoRA (LaLo) neural architecture allowing no-memory-cost access to all past models at train time. We show this approach outperforms all data-free methods by as much as ~7% while even matching some levels of experience-replay (prohibitive for applications where data-privacy must be preserved).
Technical Report on Web-based Visual Corpus Construction for Visual Document Understanding
Nov 07, 2022



We present a dataset generator engine named Web-based Visual Corpus Builder (Webvicob). Webvicob can readily construct a large-scale visual corpus (i.e., images with text annotations) from a raw Wikipedia HTML dump. In this report, we validate that Webvicob-generated data can cover a wide range of context and knowledge and helps practitioners to build a powerful Visual Document Understanding (VDU) backbone. The proposed engine is publicly available at https://github.com/clovaai/webvicob.
Grafting Vision Transformers
Oct 28, 2022



Vision Transformers (ViTs) have recently become the state-of-the-art across many computer vision tasks. In contrast to convolutional networks (CNNs), ViTs enable global information sharing even within shallow layers of a network, i.e., among high-resolution features. However, this perk was later overlooked with the success of pyramid architectures such as Swin Transformer, which show better performance-complexity trade-offs. In this paper, we present a simple and efficient add-on component (termed GrafT) that considers global dependencies and multi-scale information throughout the network, in both high- and low-resolution features alike. GrafT can be easily adopted in both homogeneous and pyramid Transformers while showing consistent gains. It has the flexibility of branching-out at arbitrary depths, widening a network with multiple scales. This grafting operation enables us to share most of the parameters and computations of the backbone, adding only minimal complexity, but with a higher yield. In fact, the process of progressively compounding multi-scale receptive fields in GrafT enables communications between local regions. We show the benefits of the proposed method on multiple benchmarks, including image classification (ImageNet-1K), semantic segmentation (ADE20K), object detection and instance segmentation (COCO2017). Our code and models will be made available.
System Configuration and Navigation of a Guide Dog Robot: Toward Animal Guide Dog-Level Guiding Work
Oct 24, 2022A robot guide dog has compelling advantages over animal guide dogs for its cost-effectiveness, potential for mass production, and low maintenance burden. However, despite the long history of guide dog robot research, previous studies were conducted with little or no consideration of how the guide dog handler and the guide dog work as a team for navigation. To develop a robotic guiding system that is genuinely beneficial to blind or visually impaired individuals, we performed qualitative research, including interviews with guide dog handlers and trainers and first-hand blindfold walking experiences with various guide dogs. Grounded on the facts learned from vivid experience and interviews, we build a collaborative indoor navigation scheme for a guide dog robot that includes preferred features such as speed and directional control. For collaborative navigation, we propose a semantic-aware local path planner that enables safe and efficient guiding work by utilizing semantic information about the environment and considering the handler's position and directional cues to determine the collision-free path. We evaluate our integrated robotic system by testing guide blindfold walking in indoor settings and demonstrate guide dog-like navigation behavior by avoiding obstacles at typical gait speed ($0.7 \mathrm{m/s}$).
Integration of Riemannian Motion Policy and Whole-Body Control for Dynamic Legged Locomotion
Oct 07, 2022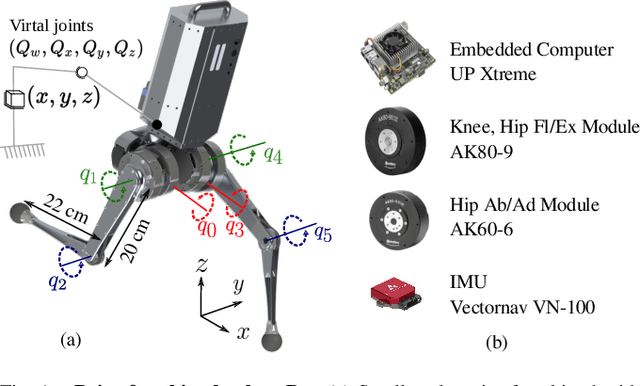
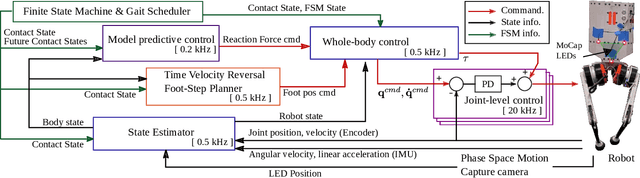
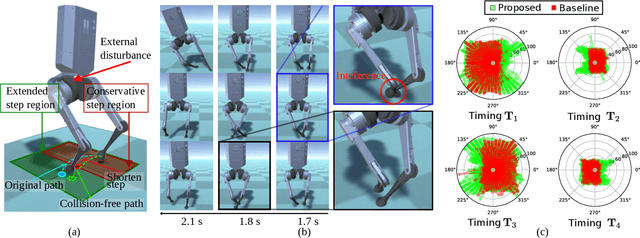
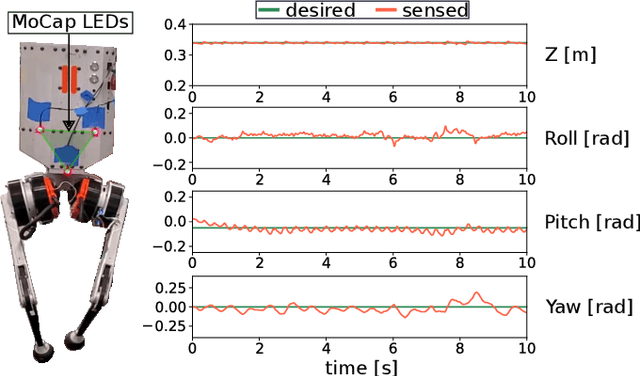
In this paper, we present a novel Riemannian Motion Policy (RMP)flow-based whole-body control framework for improved dynamic legged locomotion. RMPflow is a differential geometry-inspired algorithm for fusing multiple task-space policies (RMPs) into a configuration space policy in a geometrically consistent manner. RMP-based approaches are especially suited for designing simultaneous tracking and collision avoidance behaviors and have been successfully deployed on serial manipulators. However, one caveat of RMPflow is that it is designed with fully actuated systems in mind. In this work, we, for the first time, extend it to the domain of dynamic-legged systems, which have unforgiving under-actuation and limited control input. Thorough push recovery experiments are conducted in simulation to validate the overall framework. We show that expanding the valid stepping region with an RMP-based collision-avoidance swing leg controller improves balance robustness against external disturbances by up to $53\%$ compared to a baseline approach using a restricted stepping region. Furthermore, a point-foot biped robot is purpose-built for experimental studies of dynamic biped locomotion. A preliminary unassisted in-place stepping experiment is conducted to show the viability of the control framework and hardware.
Emp-RFT: Empathetic Response Generation via Recognizing Feature Transitions between Utterances
May 06, 2022
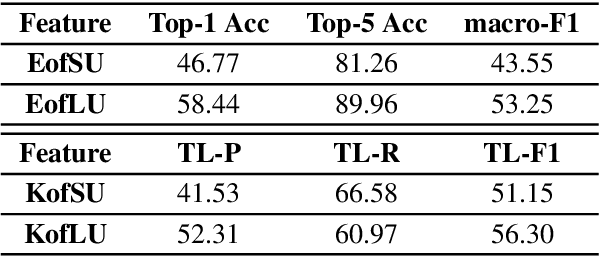
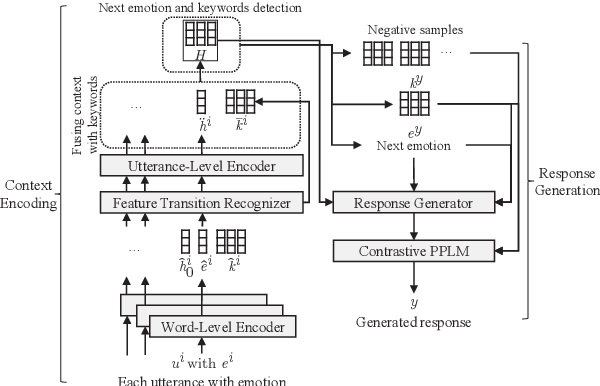
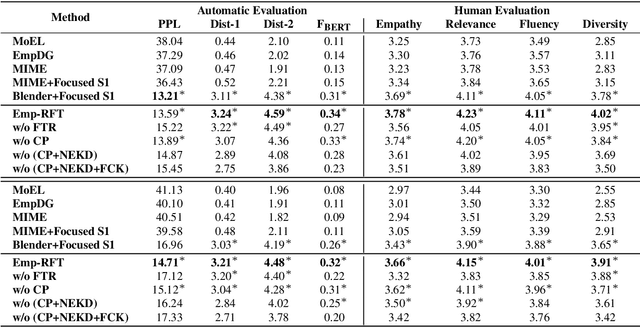
Each utterance in multi-turn empathetic dialogues has features such as emotion, keywords, and utterance-level meaning. Feature transitions between utterances occur naturally. However, existing approaches fail to perceive the transitions because they extract features for the context at the coarse-grained level. To solve the above issue, we propose a novel approach of recognizing feature transitions between utterances, which helps understand the dialogue flow and better grasp the features of utterance that needs attention. Also, we introduce a response generation strategy to help focus on emotion and keywords related to appropriate features when generating responses. Experimental results show that our approach outperforms baselines and especially, achieves significant improvements on multi-turn dialogues.
Temporal Relevance Analysis for Video Action Models
Apr 25, 2022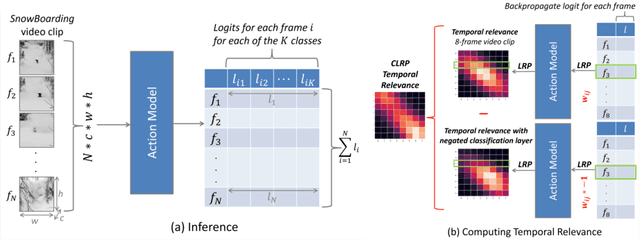
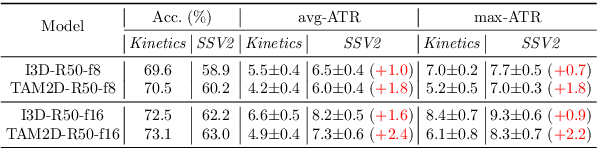
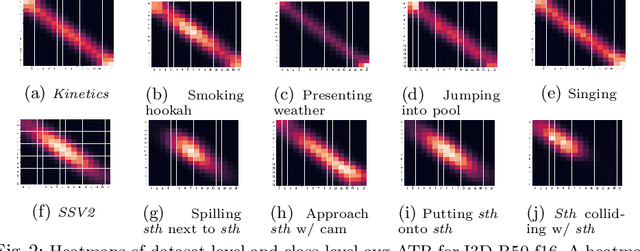
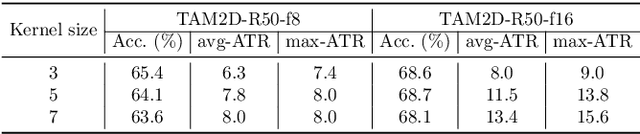
In this paper, we provide a deep analysis of temporal modeling for action recognition, an important but underexplored problem in the literature. We first propose a new approach to quantify the temporal relationships between frames captured by CNN-based action models based on layer-wise relevance propagation. We then conduct comprehensive experiments and in-depth analysis to provide a better understanding of how temporal modeling is affected by various factors such as dataset, network architecture, and input frames. With this, we further study some important questions for action recognition that lead to interesting findings. Our analysis shows that there is no strong correlation between temporal relevance and model performance; and action models tend to capture local temporal information, but less long-range dependencies. Our codes and models will be publicly available.
A Unified Framework for Domain Adaptive Pose Estimation
Apr 06, 2022
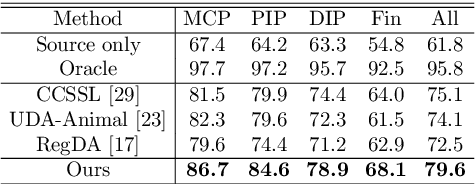
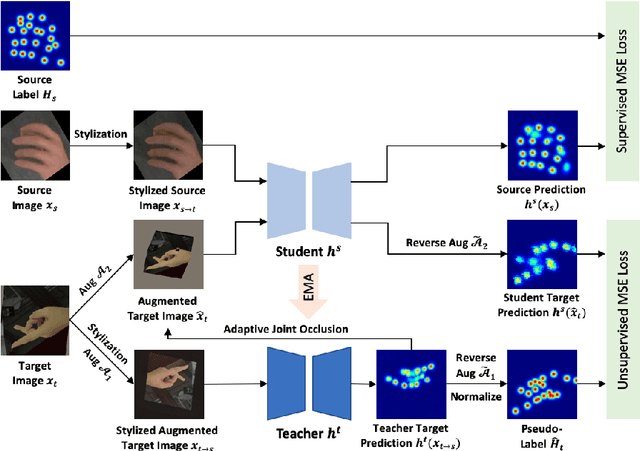
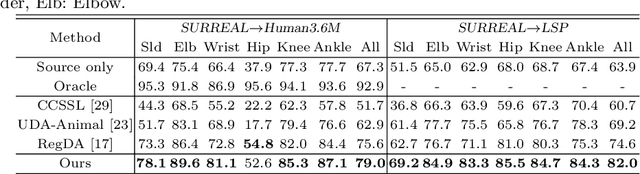
While pose estimation is an important computer vision task, it requires expensive annotation and suffers from domain shift. In this paper, we investigate the problem of domain adaptive 2D pose estimation that transfers knowledge learned on a synthetic source domain to a target domain without supervision. While several domain adaptive pose estimation models have been proposed recently, they are not generic but only focus on either human pose or animal pose estimation, and thus their effectiveness is somewhat limited to specific scenarios. In this work, we propose a unified framework that generalizes well on various domain adaptive pose estimation problems. We propose to align representations using both input-level and output-level cues (pixels and pose labels, respectively), which facilitates the knowledge transfer from the source domain to the unlabeled target domain. Our experiments show that our method achieves state-of-the-art performance under various domain shifts. Our method outperforms existing baselines on human pose estimation by up to 4.5 percent points (pp), hand pose estimation by up to 7.4 pp, and animal pose estimation by up to 4.8 pp for dogs and 3.3 pp for sheep. These results suggest that our method is able to mitigate domain shift on diverse tasks and even unseen domains and objects (e.g., trained on horse and tested on dog).