 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich bird does not have wings: Negative-constrained KGQA with Schema-guided Semantic Matching and Self-directed Refinement
Apr 16, 2026Large language models still struggle with faithfulness and hallucinations despite their remarkable reasoning abilities. In Knowledge Graph Question Answering (KGQA), semantic parsing-based approaches address the limitations by understanding constraints in a user's question and converting them into a logical form to execute on a knowledge graph. However, existing KGQA benchmarks and methods are biased toward positive and calculation constraints. Negative constraints are neglected, although they frequently appear in real-world questions. In this paper, we introduce a new task, NEgative-conSTrained (NEST) KGQA, where each question contains at least one negative constraint, and a corresponding dataset, NestKGQA. We also design PyLF, a Python-formatted logical form, since existing logical forms are hardly suitable to express negation clearly while maintaining readability. Furthermore, NEST questions naturally contain multiple constraints. To mitigate their semantic complexity, we present a novel framework named CUCKOO, specialized to multiple-constrained questions and ensuring semantic executability. CUCKOO first generates a constraint-aware logical form draft and performs schema-guided semantic matching. It then selectively applies self-directed refinement only when executing improper logical forms yields an empty result, reducing cost while improving robustness. Experimental results demonstrate that CUCKOO consistently outperforms baselines on both conventional KGQA and NEST-KGQA benchmarks under few-shot settings.
RPO-RAG: Aligning Small LLMs with Relation-aware Preference Optimization for Knowledge Graph Question Answering
Jan 27, 2026Large Language Models (LLMs) have recently demonstrated remarkable reasoning abilities, yet hallucinate on knowledge-intensive tasks. Retrieval-augmented generation (RAG) mitigates this issue by grounding answers in external sources, e.g., knowledge graphs (KGs). However, existing KG-based RAG approaches rely on semantics-unaware path sampling and are weakly aligned with KG reasoning objectives, which limits further accuracy gains. They also feed retrieved paths directly into the reasoner without organizing them into answer-centered reasoning paths, hindering small LLMs' ability to leverage the retrieved knowledge. Furthermore, prior works predominantly rely on large LLMs (e.g., ChatGPT/GPT-4) or assume backbones above 7B parameters, leaving sub-7B models underexplored. We address this gap with RPO-RAG, the first KG-based RAG framework specifically designed for small LLMs, to the best of our knowledge. RPO-RAG introduces three key innovations: (1) a query-path semantic sampling strategy that provides informative supervisory signals; (2) a relation-aware preference optimization that aligns training with intermediate KG reasoning signals (e.g., relation); and (3) an answer-centered prompt design that organizes entities and reasoning paths in an interpretable format. Extensive experiments on two benchmark Knowledge Graph Question Answering (KGQA) datasets, WebQSP and CWQ, demonstrate that RPO-RAG effectively bridges the performance gap between small and large language models. On WebQSP, it improves F1 by up to 8.8%, reflecting enhanced answer precision, while on CWQ it achieves new state-of-the-art results among models under 8B parameters in both Hit and F1. Overall, RPO-RAG substantially improves the reasoning capability of small LLMs, even under 3B parameters-highlighting their potential for resource-efficient and practical on-device KGQA applications.
VSPO: Validating Semantic Pitfalls in Ontology via LLM-Based CQ Generation
Nov 18, 2025Competency Questions (CQs) play a crucial role in validating ontology design. While manually crafting CQs can be highly time-consuming and costly for ontology engineers, recent studies have explored the use of large language models (LLMs) to automate this process. However, prior approaches have largely evaluated generated CQs based on their similarity to existing datasets, which often fail to verify semantic pitfalls such as "Misusing allValuesFrom". Since such pitfalls cannot be reliably detected through rule-based methods, we propose a novel dataset and model of Validating Semantic Pitfalls in Ontology (VSPO) for CQ generation specifically designed to verify the semantic pitfalls. To simulate missing and misused axioms, we use LLMs to generate natural language definitions of classes and properties and introduce misalignments between the definitions and the ontology by removing axioms or altering logical operators (e.g., substituting union with intersection). We then fine-tune LLaMA-3.1-8B-Instruct to generate CQs that validate these semantic discrepancies between the provided definitions and the corresponding axioms. The resulting CQs can detect a broader range of modeling errors compared to existing public datasets. Our fine-tuned model demonstrates superior performance over baselines, showing 26% higher precision and 28.2% higher recall than GPT-4.1 in generating CQs for pitfall validation. This research enables automatic generation of TBox-validating CQs using LLMs, significantly reducing manual effort while improving semantic alignment between ontologies and expert knowledge. To the best of our knowledge, this is the first study to target semantic pitfall validation in CQ generation using LLMs.
Emp-RFT: Empathetic Response Generation via Recognizing Feature Transitions between Utterances
May 06, 2022
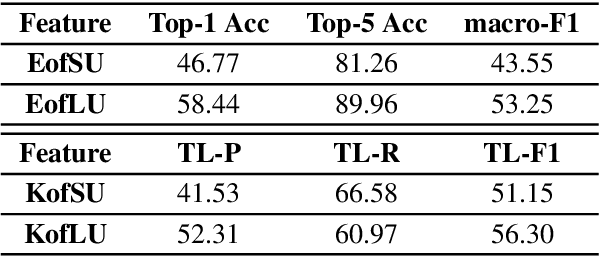
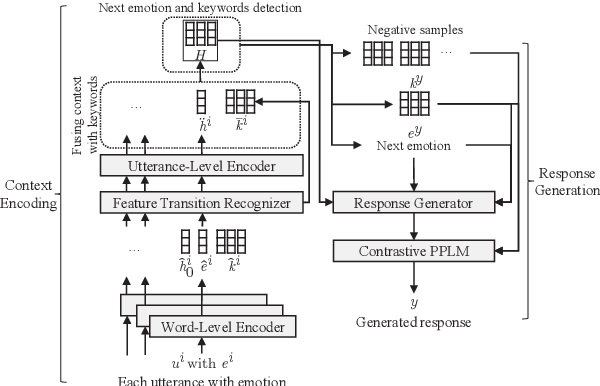
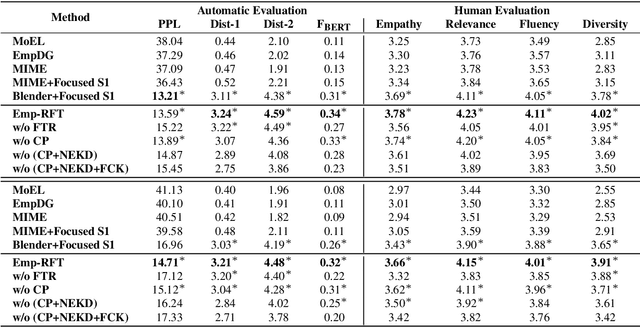
Each utterance in multi-turn empathetic dialogues has features such as emotion, keywords, and utterance-level meaning. Feature transitions between utterances occur naturally. However, existing approaches fail to perceive the transitions because they extract features for the context at the coarse-grained level. To solve the above issue, we propose a novel approach of recognizing feature transitions between utterances, which helps understand the dialogue flow and better grasp the features of utterance that needs attention. Also, we introduce a response generation strategy to help focus on emotion and keywords related to appropriate features when generating responses. Experimental results show that our approach outperforms baselines and especially, achieves significant improvements on multi-turn dialogues.