 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGanLM: Encoder-Decoder Pre-training with an Auxiliary Discriminator
Dec 20, 2022



Pre-trained models have achieved remarkable success in natural language processing (NLP). However, existing pre-training methods underutilize the benefits of language understanding for generation. Inspired by the idea of Generative Adversarial Networks (GANs), we propose a GAN-style model for encoder-decoder pre-training by introducing an auxiliary discriminator, unifying the ability of language understanding and generation in a single model. Our model, named as GanLM, is trained with two pre-training objectives: replaced token detection and replaced token denoising. Specifically, given masked source sentences, the generator outputs the target distribution and the discriminator predicts whether the target sampled tokens from distribution are incorrect. The target sentence is replaced with misclassified tokens to construct noisy previous context, which is used to generate the gold sentence. In general, both tasks improve the ability of language understanding and generation by selectively using the denoising data. Extensive experiments in language generation benchmarks show that GanLM with the powerful language understanding capability outperforms various strong pre-trained language models (PLMs) and achieves state-of-the-art performance.
TRIP: Triangular Document-level Pre-training for Multilingual Language Models
Dec 15, 2022



Despite the current success of multilingual pre-training, most prior works focus on leveraging monolingual data or bilingual parallel data and overlooked the value of trilingual parallel data. This paper presents \textbf{Tri}angular Document-level \textbf{P}re-training (\textbf{TRIP}), which is the first in the field to extend the conventional monolingual and bilingual pre-training to a trilingual setting by (i) \textbf{Grafting} the same documents in two languages into one mixed document, and (ii) predicting the remaining one language as the reference translation. Our experiments on document-level MT and cross-lingual abstractive summarization show that TRIP brings by up to 3.65 d-BLEU points and 6.2 ROUGE-L points on three multilingual document-level machine translation benchmarks and one cross-lingual abstractive summarization benchmark, including multiple strong state-of-the-art (SOTA) scores. In-depth analysis indicates that TRIP improves document-level machine translation and captures better document contexts in at least three characteristics: (i) tense consistency, (ii) noun consistency and (iii) conjunction presence.
A Bilingual Parallel Corpus with Discourse Annotations
Oct 26, 2022



Machine translation (MT) has almost achieved human parity at sentence-level translation. In response, the MT community has, in part, shifted its focus to document-level translation. However, the development of document-level MT systems is hampered by the lack of parallel document corpora. This paper describes BWB, a large parallel corpus first introduced in Jiang et al. (2022), along with an annotated test set. The BWB corpus consists of Chinese novels translated by experts into English, and the annotated test set is designed to probe the ability of machine translation systems to model various discourse phenomena. Our resource is freely available, and we hope it will serve as a guide and inspiration for more work in document-level machine translation.
CROP: Zero-shot Cross-lingual Named Entity Recognition with Multilingual Labeled Sequence Translation
Oct 13, 2022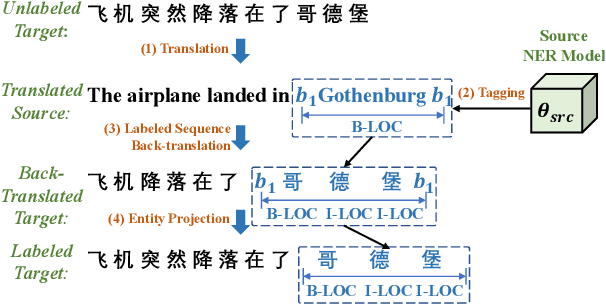
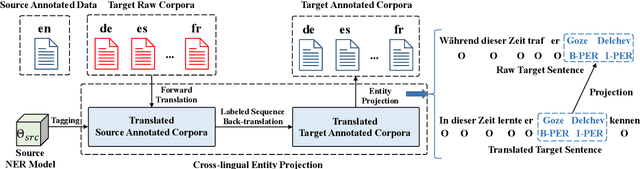
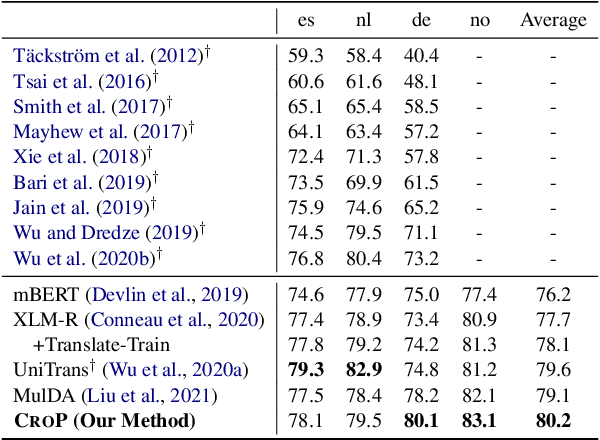
Named entity recognition (NER) suffers from the scarcity of annotated training data, especially for low-resource languages without labeled data. Cross-lingual NER has been proposed to alleviate this issue by transferring knowledge from high-resource languages to low-resource languages via aligned cross-lingual representations or machine translation results. However, the performance of cross-lingual NER methods is severely affected by the unsatisfactory quality of translation or label projection. To address these problems, we propose a Cross-lingual Entity Projection framework (CROP) to enable zero-shot cross-lingual NER with the help of a multilingual labeled sequence translation model. Specifically, the target sequence is first translated into the source language and then tagged by a source NER model. We further adopt a labeled sequence translation model to project the tagged sequence back to the target language and label the target raw sentence. Ultimately, the whole pipeline is integrated into an end-to-end model by the way of self-training. Experimental results on two benchmarks demonstrate that our method substantially outperforms the previous strong baseline by a large margin of +3~7 F1 scores and achieves state-of-the-art performance.
Multilingual Transitivity and Bidirectional Multilingual Agreement for Multilingual Document-level Machine Translation
Oct 05, 2022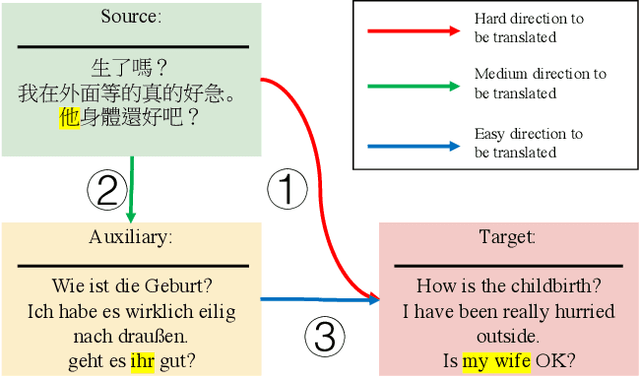
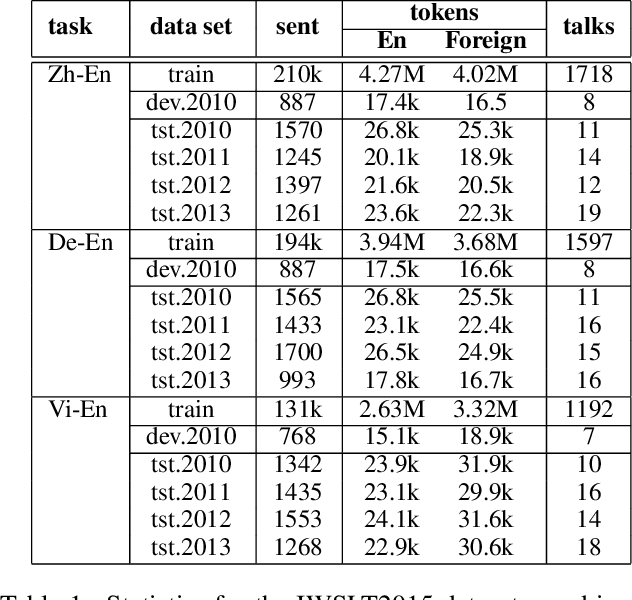
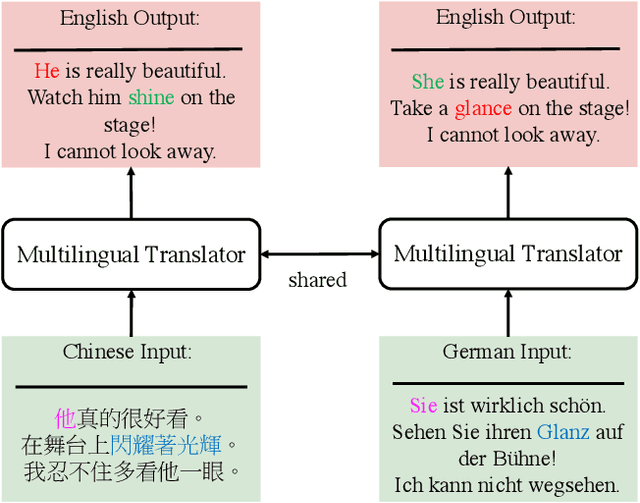

Multilingual machine translation has been proven an effective strategy to support translation between multiple languages with a single model. However, most studies focus on multilingual sentence translation without considering generating long documents across different languages, which requires an understanding of multilingual context dependency and is typically harder. In this paper, we first spot that naively incorporating auxiliary multilingual data either auxiliary-target or source-auxiliary brings no improvement to the source-target language pair in our interest. Motivated by this observation, we propose a novel framework called Multilingual Transitivity (MTrans) to find an implicit optimal route via source-auxiliary-target within the multilingual model. To encourage MTrans, we propose a novel method called Triplet Parallel Data (TPD), which uses parallel triplets that contain (source-auxiliary, auxiliary-target, and source-target) for training. The auxiliary language then serves as a pivot and automatically facilitates the implicit information transition flow which is easier to translate. We further propose a novel framework called Bidirectional Multilingual Agreement (Bi-MAgree) that encourages the bidirectional agreement between different languages. To encourage Bi-MAgree, we propose a novel method called Multilingual Kullback-Leibler Divergence (MKL) that forces the output distribution of the inputs with the same meaning but in different languages to be consistent with each other. The experimental results indicate that our methods bring consistent improvements over strong baselines on three document translation tasks: IWSLT2015 Zh-En, De-En, and Vi-En. Our analysis validates the usefulness and existence of MTrans and Bi-MAgree, and our frameworks and methods are effective on synthetic auxiliary data.
GTrans: Grouping and Fusing Transformer Layers for Neural Machine Translation
Jul 29, 2022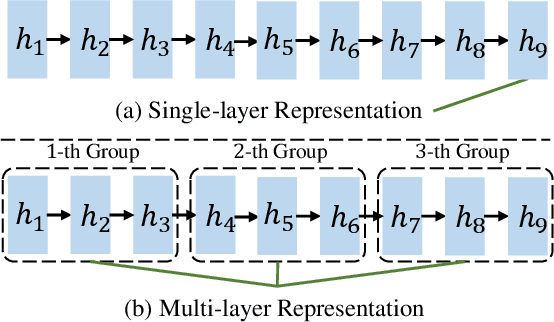
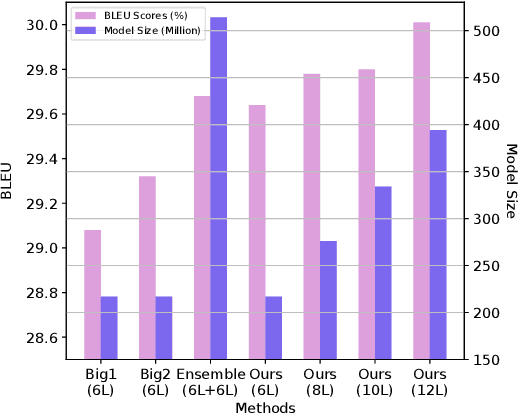
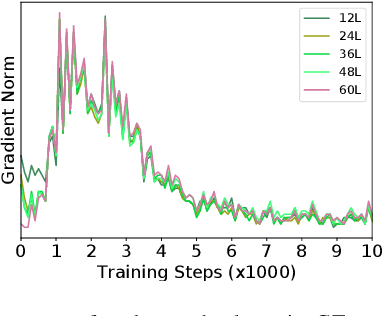
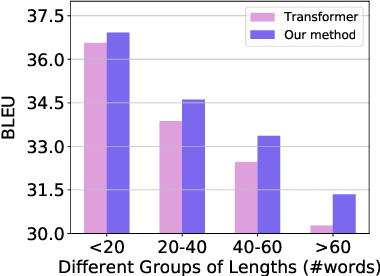
Transformer structure, stacked by a sequence of encoder and decoder network layers, achieves significant development in neural machine translation. However, vanilla Transformer mainly exploits the top-layer representation, assuming the lower layers provide trivial or redundant information and thus ignoring the bottom-layer feature that is potentially valuable. In this work, we propose the Group-Transformer model (GTrans) that flexibly divides multi-layer representations of both encoder and decoder into different groups and then fuses these group features to generate target words. To corroborate the effectiveness of the proposed method, extensive experiments and analytic experiments are conducted on three bilingual translation benchmarks and two multilingual translation tasks, including the IWLST-14, IWLST-17, LDC, WMT-14 and OPUS-100 benchmark. Experimental and analytical results demonstrate that our model outperforms its Transformer counterparts by a consistent gain. Furthermore, it can be successfully scaled up to 60 encoder layers and 36 decoder layers.
HLT-MT: High-resource Language-specific Training for Multilingual Neural Machine Translation
Jul 15, 2022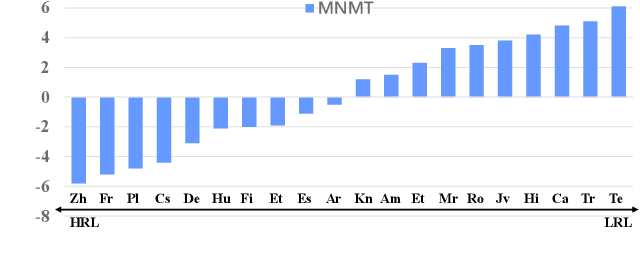
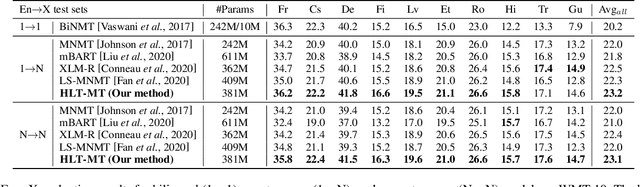
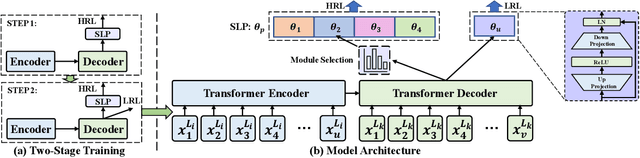

Multilingual neural machine translation (MNMT) trained in multiple language pairs has attracted considerable attention due to fewer model parameters and lower training costs by sharing knowledge among multiple languages. Nonetheless, multilingual training is plagued by language interference degeneration in shared parameters because of the negative interference among different translation directions, especially on high-resource languages. In this paper, we propose the multilingual translation model with the high-resource language-specific training (HLT-MT) to alleviate the negative interference, which adopts the two-stage training with the language-specific selection mechanism. Specifically, we first train the multilingual model only with the high-resource pairs and select the language-specific modules at the top of the decoder to enhance the translation quality of high-resource directions. Next, the model is further trained on all available corpora to transfer knowledge from high-resource languages (HRLs) to low-resource languages (LRLs). Experimental results show that HLT-MT outperforms various strong baselines on WMT-10 and OPUS-100 benchmarks. Furthermore, the analytic experiments validate the effectiveness of our method in mitigating the negative interference in multilingual training.
UM4: Unified Multilingual Multiple Teacher-Student Model for Zero-Resource Neural Machine Translation
Jul 11, 2022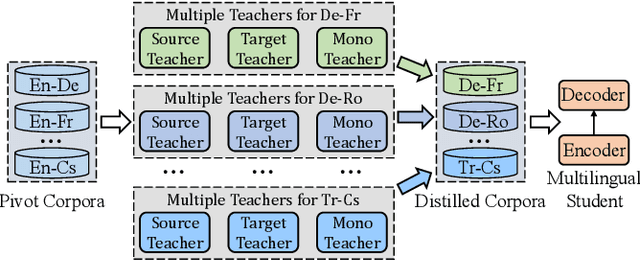
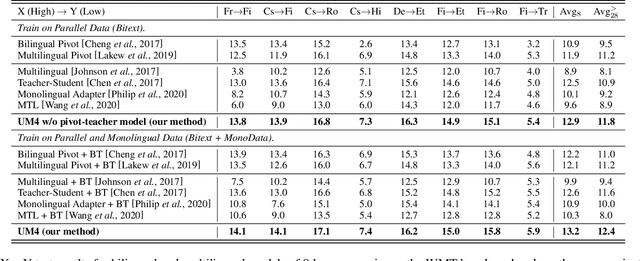
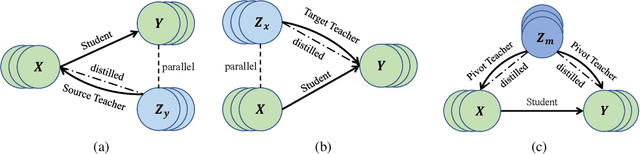
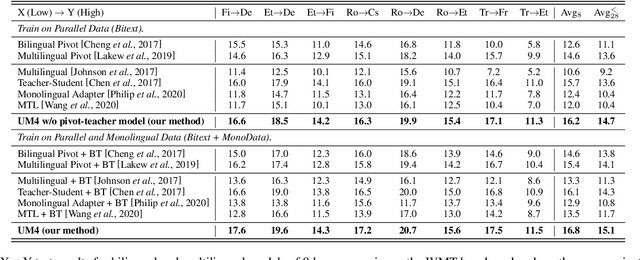
Most translation tasks among languages belong to the zero-resource translation problem where parallel corpora are unavailable. Multilingual neural machine translation (MNMT) enables one-pass translation using shared semantic space for all languages compared to the two-pass pivot translation but often underperforms the pivot-based method. In this paper, we propose a novel method, named as Unified Multilingual Multiple teacher-student Model for NMT (UM4). Our method unifies source-teacher, target-teacher, and pivot-teacher models to guide the student model for the zero-resource translation. The source teacher and target teacher force the student to learn the direct source to target translation by the distilled knowledge on both source and target sides. The monolingual corpus is further leveraged by the pivot-teacher model to enhance the student model. Experimental results demonstrate that our model of 72 directions significantly outperforms previous methods on the WMT benchmark.
DeepNet: Scaling Transformers to 1,000 Layers
Mar 01, 2022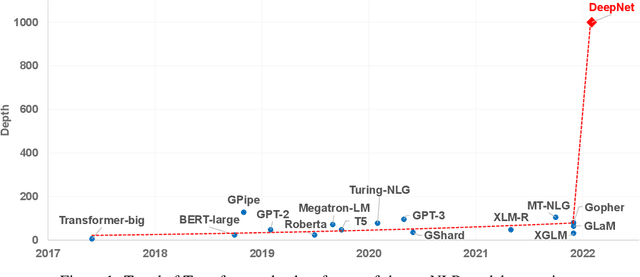
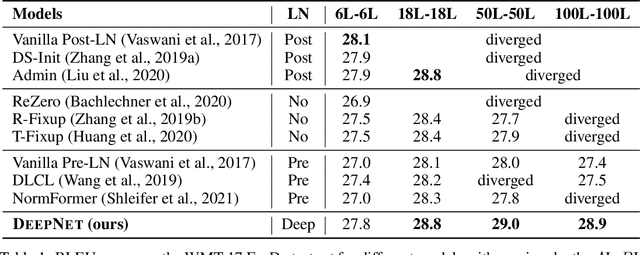

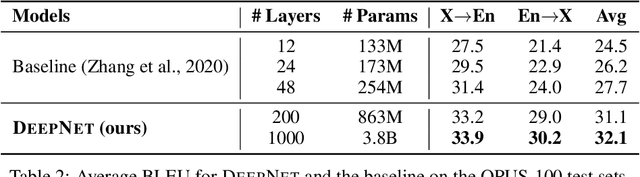
In this paper, we propose a simple yet effective method to stabilize extremely deep Transformers. Specifically, we introduce a new normalization function (DeepNorm) to modify the residual connection in Transformer, accompanying with theoretically derived initialization. In-depth theoretical analysis shows that model updates can be bounded in a stable way. The proposed method combines the best of two worlds, i.e., good performance of Post-LN and stable training of Pre-LN, making DeepNorm a preferred alternative. We successfully scale Transformers up to 1,000 layers (i.e., 2,500 attention and feed-forward network sublayers) without difficulty, which is one order of magnitude deeper than previous deep Transformers. Remarkably, on a multilingual benchmark with 7,482 translation directions, our 200-layer model with 3.2B parameters significantly outperforms the 48-layer state-of-the-art model with 12B parameters by 5 BLEU points, which indicates a promising scaling direction.
Zero-shot Cross-lingual Transfer of Prompt-based Tuning with a Unified Multilingual Prompt
Feb 23, 2022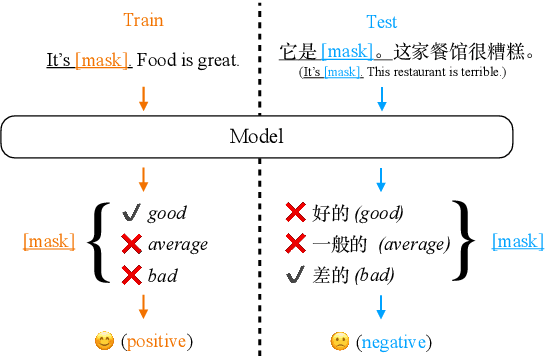

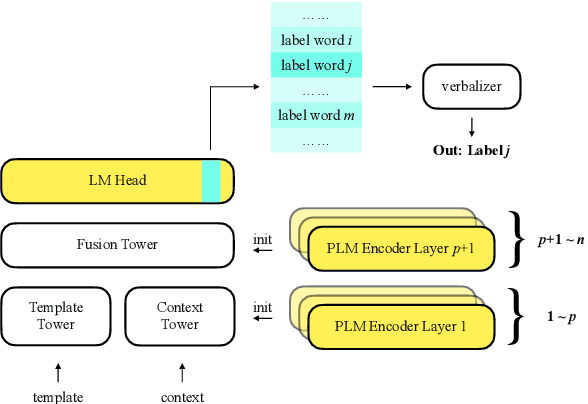
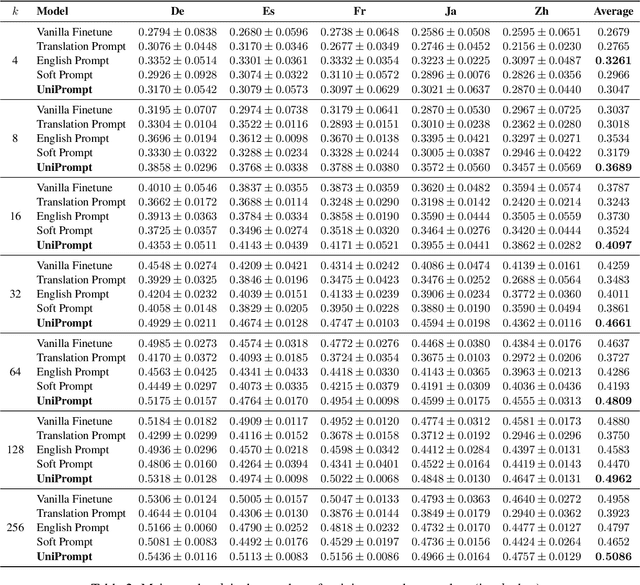
Prompt-based tuning has been proven effective for pretrained language models (PLMs). While most of the existing work focuses on the monolingual prompts, we study the multilingual prompts for multilingual PLMs, especially in the zero-shot cross-lingual setting. To alleviate the effort of designing different prompts for multiple languages, we propose a novel model that uses a unified prompt for all languages, called UniPrompt. Different from the discrete prompts and soft prompts, the unified prompt is model-based and language-agnostic. Specifically, the unified prompt is initialized by a multilingual PLM to produce language-independent representation, after which is fused with the text input. During inference, the prompts can be pre-computed so that no extra computation cost is needed. To collocate with the unified prompt, we propose a new initialization method for the target label word to further improve the model's transferability across languages. Extensive experiments show that our proposed methods can significantly outperform the strong baselines across different languages. We will release data and code to facilitate future research.