 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHMS: Multimodal Hierarchical Multimedia Summarization
Apr 07, 2022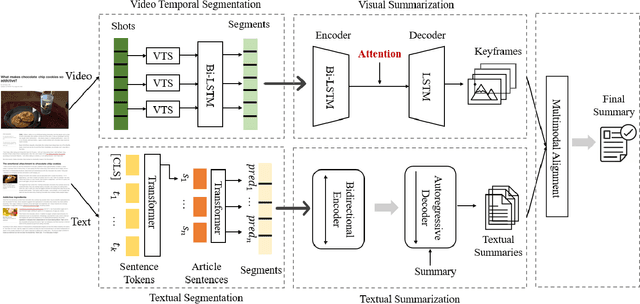
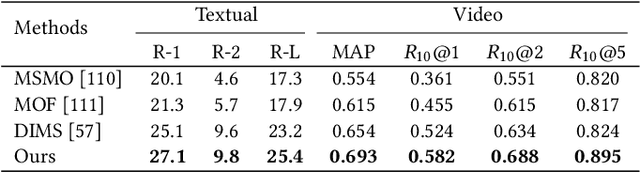
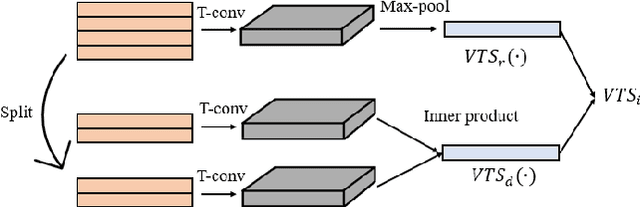

Multimedia summarization with multimodal output can play an essential role in real-world applications, i.e., automatically generating cover images and titles for news articles or providing introductions to online videos. In this work, we propose a multimodal hierarchical multimedia summarization (MHMS) framework by interacting visual and language domains to generate both video and textual summaries. Our MHMS method contains video and textual segmentation and summarization module, respectively. It formulates a cross-domain alignment objective with optimal transport distance which leverages cross-domain interaction to generate the representative keyframe and textual summary. We evaluated MHMS on three recent multimodal datasets and demonstrated the effectiveness of our method in producing high-quality multimodal summaries.
Test Against High-Dimensional Uncertainties: Accelerated Evaluation of Autonomous Vehicles with Deep Importance Sampling
Apr 06, 2022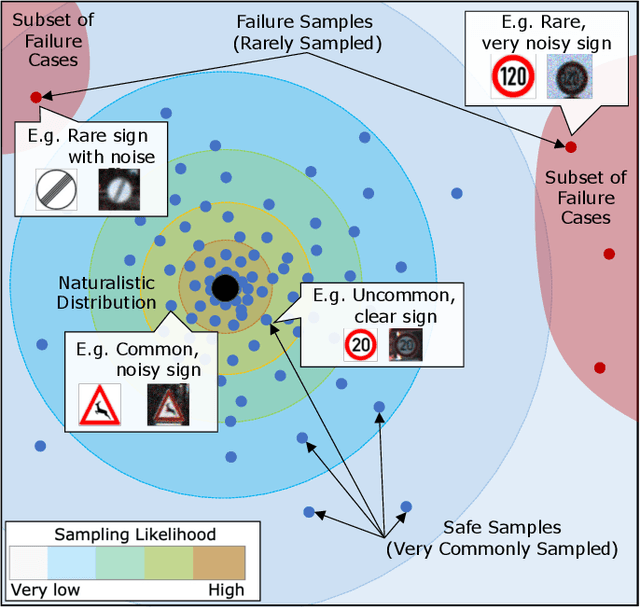


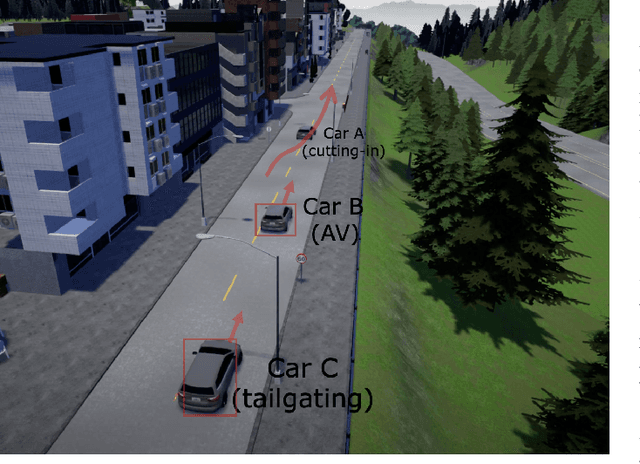
Evaluating the performance of autonomous vehicles (AV) and their complex subsystems to high precision under naturalistic circumstances remains a challenge, especially when failure or dangerous cases are rare. Rarity does not only require an enormous sample size for a naive method to achieve high confidence estimation, but it also causes dangerous underestimation of the true failure rate and it is extremely hard to detect. Meanwhile, the state-of-the-art approach that comes with a correctness guarantee can only compute an upper bound for the failure rate under certain conditions, which could limit its practical uses. In this work, we present Deep Importance Sampling (Deep IS) framework that utilizes a deep neural network to obtain an efficient IS that is on par with the state-of-the-art, capable of reducing the required sample size 43 times smaller than the naive sampling method to achieve 10% relative error and while producing an estimate that is much less conservative. Our high-dimensional experiment estimating the misclassification rate of one of the state-of-the-art traffic sign classifiers further reveals that this efficiency still holds true even when the target is very small, achieving over 600 times efficiency boost. This highlights the potential of Deep IS in providing a precise estimate even against high-dimensional uncertainties.
PhysioMTL: Personalizing Physiological Patterns using Optimal Transport Multi-Task Regression
Mar 19, 2022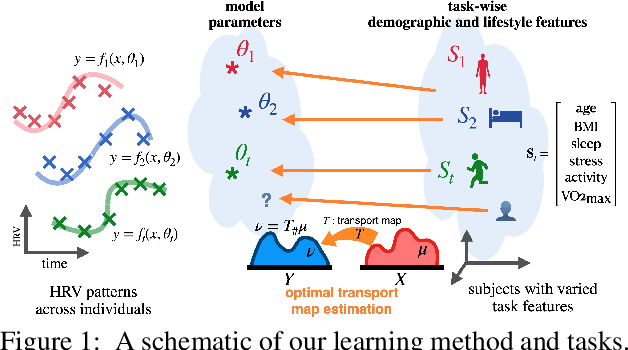
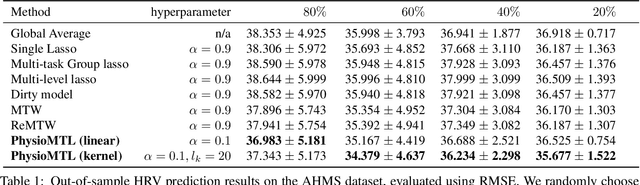
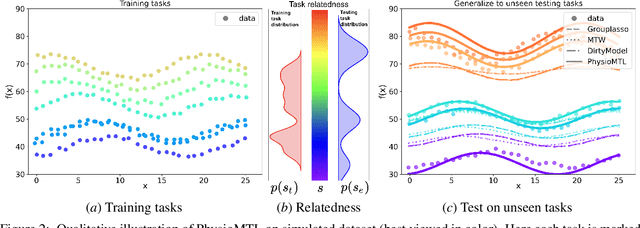
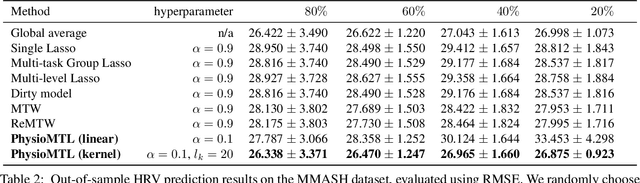
Heart rate variability (HRV) is a practical and noninvasive measure of autonomic nervous system activity, which plays an essential role in cardiovascular health. However, using HRV to assess physiology status is challenging. Even in clinical settings, HRV is sensitive to acute stressors such as physical activity, mental stress, hydration, alcohol, and sleep. Wearable devices provide convenient HRV measurements, but the irregularity of measurements and uncaptured stressors can bias conventional analytical methods. To better interpret HRV measurements for downstream healthcare applications, we learn a personalized diurnal rhythm as an accurate physiological indicator for each individual. We develop Physiological Multitask-Learning (PhysioMTL) by harnessing Optimal Transport theory within a Multitask-learning (MTL) framework. The proposed method learns an individual-specific predictive model from heterogeneous observations, and enables estimation of an optimal transport map that yields a push forward operation onto the demographic features for each task. Our model outperforms competing MTL methodologies on unobserved predictive tasks for synthetic and two real-world datasets. Specifically, our method provides remarkable prediction results on unseen held-out subjects given only $20\%$ of the subjects in real-world observational studies. Furthermore, our model enables a counterfactual engine that generates the effect of acute stressors and chronic conditions on HRV rhythms.
COPA: Certifying Robust Policies for Offline Reinforcement Learning against Poisoning Attacks
Mar 16, 2022
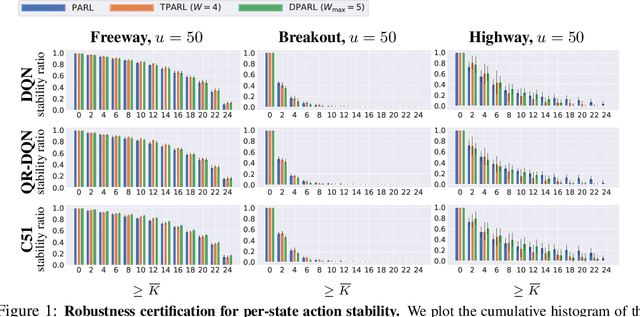
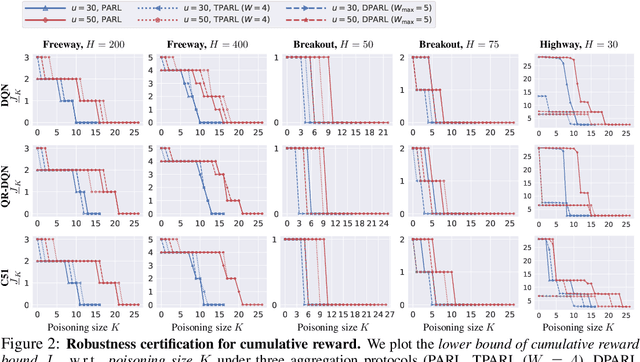
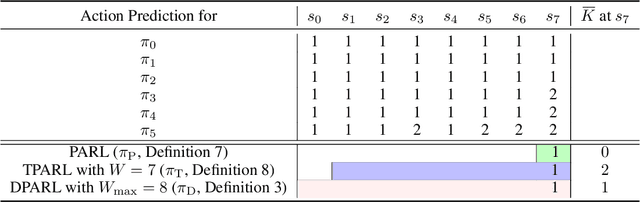
As reinforcement learning (RL) has achieved near human-level performance in a variety of tasks, its robustness has raised great attention. While a vast body of research has explored test-time (evasion) attacks in RL and corresponding defenses, its robustness against training-time (poisoning) attacks remains largely unanswered. In this work, we focus on certifying the robustness of offline RL in the presence of poisoning attacks, where a subset of training trajectories could be arbitrarily manipulated. We propose the first certification framework, COPA, to certify the number of poisoning trajectories that can be tolerated regarding different certification criteria. Given the complex structure of RL, we propose two certification criteria: per-state action stability and cumulative reward bound. To further improve the certification, we propose new partition and aggregation protocols to train robust policies. We further prove that some of the proposed certification methods are theoretically tight and some are NP-Complete problems. We leverage COPA to certify three RL environments trained with different algorithms and conclude: (1) The proposed robust aggregation protocols such as temporal aggregation can significantly improve the certifications; (2) Our certification for both per-state action stability and cumulative reward bound are efficient and tight; (3) The certification for different training algorithms and environments are different, implying their intrinsic robustness properties. All experimental results are available at https://copa-leaderboard.github.io.
Robust Reinforcement Learning as a Stackelberg Game via Adaptively-Regularized Adversarial Training
Feb 19, 2022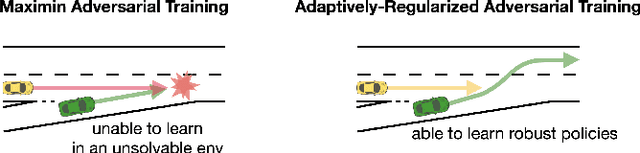
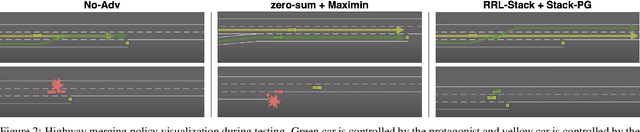
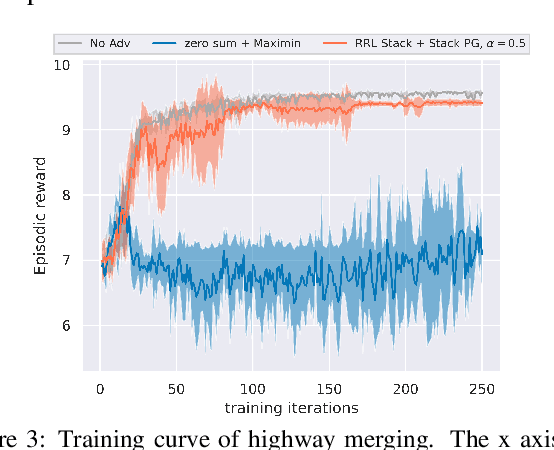
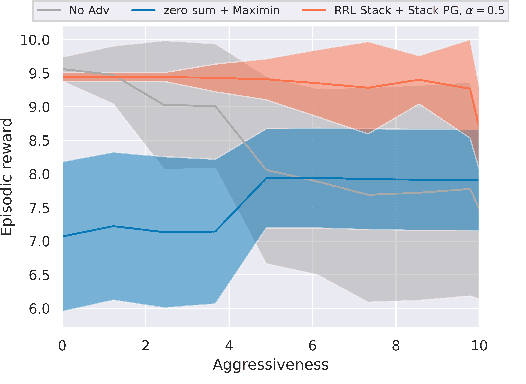
Robust Reinforcement Learning (RL) focuses on improving performances under model errors or adversarial attacks, which facilitates the real-life deployment of RL agents. Robust Adversarial Reinforcement Learning (RARL) is one of the most popular frameworks for robust RL. However, most of the existing literature models RARL as a zero-sum simultaneous game with Nash equilibrium as the solution concept, which could overlook the sequential nature of RL deployments, produce overly conservative agents, and induce training instability. In this paper, we introduce a novel hierarchical formulation of robust RL - a general-sum Stackelberg game model called RRL-Stack - to formalize the sequential nature and provide extra flexibility for robust training. We develop the Stackelberg Policy Gradient algorithm to solve RRL-Stack, leveraging the Stackelberg learning dynamics by considering the adversary's response. Our method generates challenging yet solvable adversarial environments which benefit RL agents' robust learning. Our algorithm demonstrates better training stability and robustness against different testing conditions in the single-agent robotics control and multi-agent highway merging tasks.
A Survey on Safety-Critical Scenario Generation for Autonomous Driving -- A Methodological Perspective
Feb 07, 2022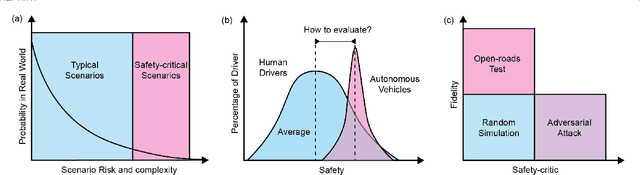
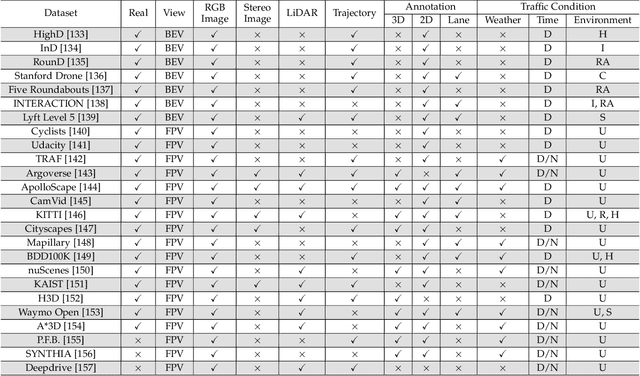
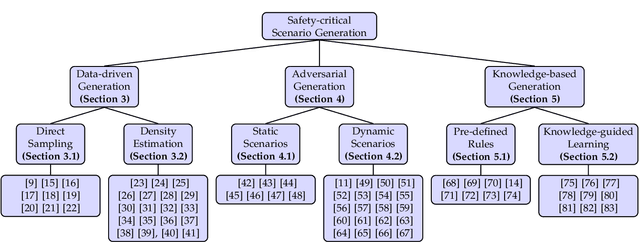
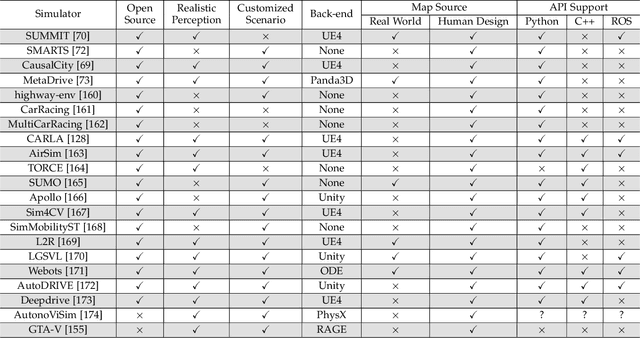
Autonomous driving systems have witnessed a great development during the past years thanks to the advance in sensing and decision-making. One critical obstacle for their massive deployment in the real world is the evaluation of safety. Most existing driving systems are still trained and evaluated on naturalistic scenarios that account for the vast majority of daily life or heuristically-generated adversarial ones. However, the large population of cars requires an extremely low collision rate, indicating safety-critical scenarios collected in the real world would be rare. Thus, methods to artificially generate artificial scenarios becomes critical to manage the risk and reduce the cost. In this survey, we focus on the algorithms of safety-critical scenario generation. We firstly provide a comprehensive taxonomy of existing algorithms by dividing them into three categories: data-driven generation, adversarial generation, and knowledge-based generation. Then, we discuss useful tools for scenario generation, including simulation platforms and packages. Finally, we extend our discussion to five main challenges of current works -- fidelity, efficiency, diversity, transferability, controllability -- and the research opportunities lighted up by these challenges.
A Hybrid Physics Machine Learning Approach for Macroscopic Traffic State Estimation
Feb 01, 2022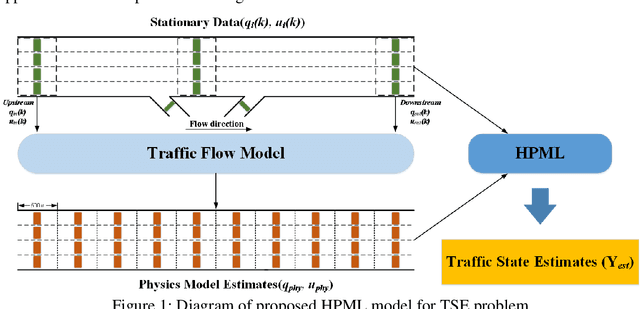
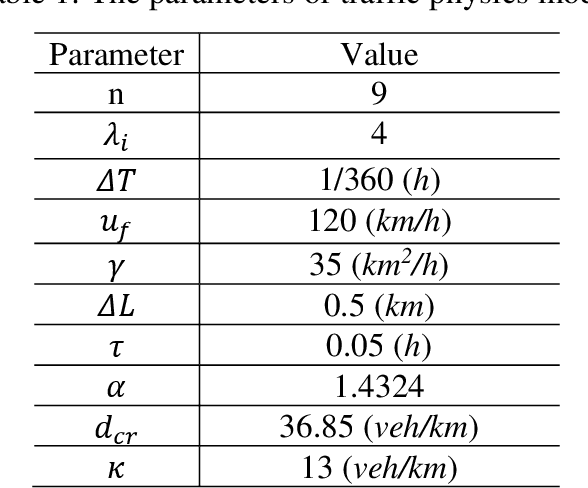
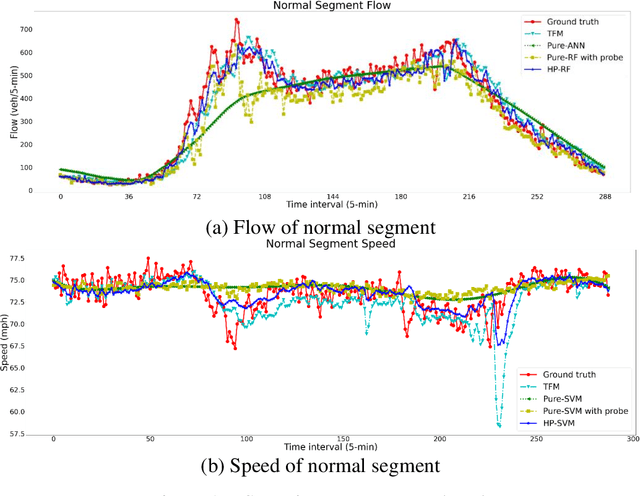
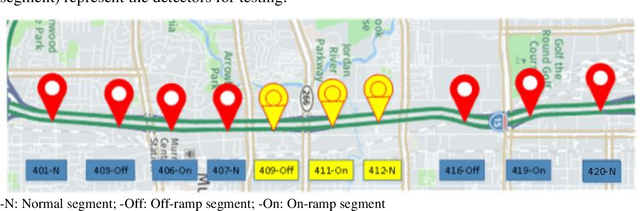
Full-field traffic state information (i.e., flow, speed, and density) is critical for the successful operation of Intelligent Transportation Systems (ITS) on freeways. However, incomplete traffic information tends to be directly collected from traffic detectors that are insufficiently installed in most areas, which is a major obstacle to the popularization of ITS. To tackle this issue, this paper introduces an innovative traffic state estimation (TSE) framework that hybrid regression machine learning techniques (e.g., artificial neural network (ANN), random forest (RF), and support vector machine (SVM)) with a traffic physics model (e.g., second-order macroscopic traffic flow model) using limited information from traffic sensors as inputs to construct accurate and full-field estimated traffic state for freeway systems. To examine the effectiveness of the proposed TSE framework, this paper conducted empirical studies on a real-world data set collected from a stretch of I-15 freeway in Salt Lake City, Utah. Experimental results show that the proposed method has been proved to estimate full-field traffic information accurately. Hence, the proposed method could provide accurate and full-field traffic information, thus providing the basis for the popularization of ITS.
Constrained Variational Policy Optimization for Safe Reinforcement Learning
Jan 28, 2022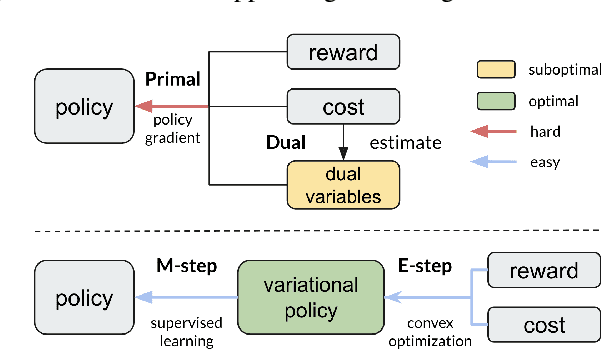
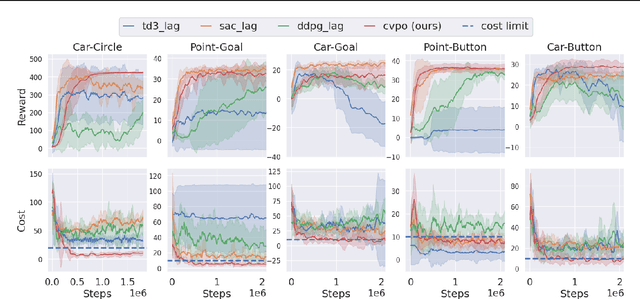
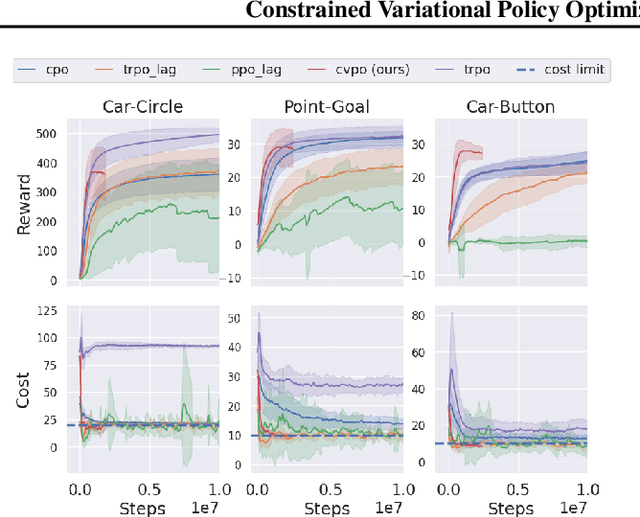
Safe reinforcement learning (RL) aims to learn policies that satisfy certain constraints before deploying to safety-critical applications. Primal-dual as a prevalent constrained optimization framework suffers from instability issues and lacks optimality guarantees. This paper overcomes the issues from a novel probabilistic inference perspective and proposes an Expectation-Maximization style approach to learn safe policy. We show that the safe RL problem can be decomposed to 1) a convex optimization phase with a non-parametric variational distribution and 2) a supervised learning phase. We show the unique advantages of constrained variational policy optimization by proving its optimality and policy improvement stability. A wide range of experiments on continuous robotic tasks show that the proposed method achieves significantly better performance in terms of constraint satisfaction and sample efficiency than primal-dual baselines.
Optimal Transport based Data Augmentation for Heart Disease Diagnosis and Prediction
Jan 25, 2022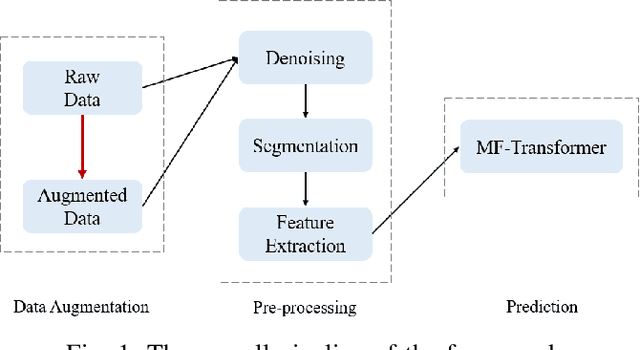
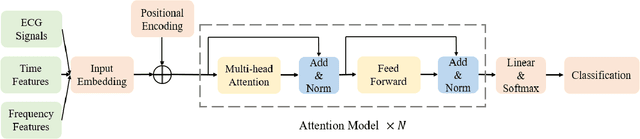
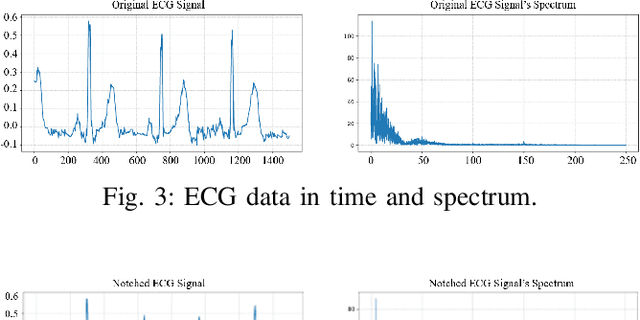
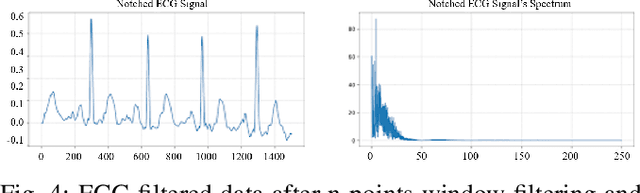
In this paper, we focus on a new method of data augmentation to solve the data imbalance problem within imbalanced ECG datasets to improve the robustness and accuracy of heart disease detection. By using Optimal Transport, we augment the ECG disease data from normal ECG beats to balance the data among different categories. We build a Multi-Feature Transformer (MF-Transformer) as our classification model, where different features are extracted from both time and frequency domains to diagnose various heart conditions. Learning from 12-lead ECG signals, our model is able to distinguish five categories of cardiac conditions. Our results demonstrate 1) the classification models' ability to make competitive predictions on five ECG categories; 2) improvements in accuracy and robustness reflecting the effectiveness of our data augmentation method.
Joint transmit and reflective beamforming for IRS-assisted integrated sensing and communication
Nov 26, 2021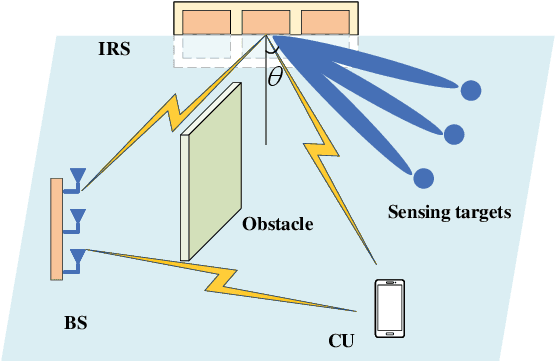
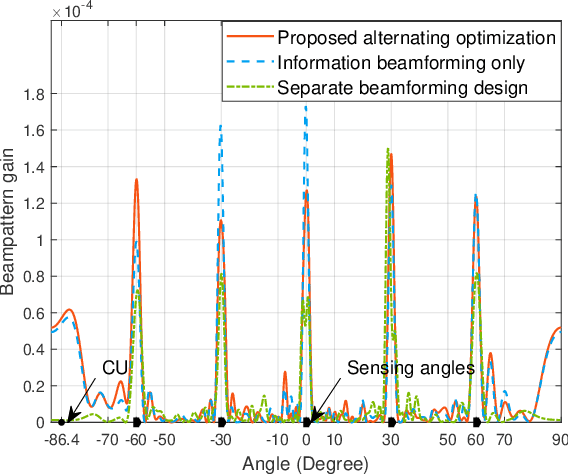
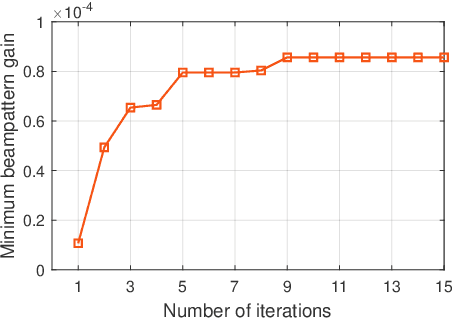
This letter studies an intelligent reflecting surface (IRS)-assisted integrated sensing and communication (ISAC) system, in which one IRS is deployed to not only assist the wireless communication from a multi-antenna base station (BS) to a single-antenna communication user (CU), but also create virtual line-of-sight (LoS) links for sensing targets at areas with LoS links blocked. We consider that the BS transmits combined information and sensing signals for ISAC. Under this setup, we jointly optimize the transmit information and sensing beamforming at the BS and the reflective beamforming at the IRS, to maximize the IRS's minimum beampattern gain towards the desired sensing angles, subject to the minimum signal-to-noise ratio (SNR) requirement at the CU and the maximum transmit power constraint at the BS. Although the formulated SNR-constrained beampattern gain maximization problem is non-convex and difficult to solve, we present an efficient algorithm to obtain a high-quality solution using alternating optimization and semi-definite relaxation (SDR). Numerical results show that the proposed algorithm achieves improved sensing performance while ensuring the communication requirement.