 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Real-world Low-light Image Enhancement with Decoupled Networks
May 06, 2020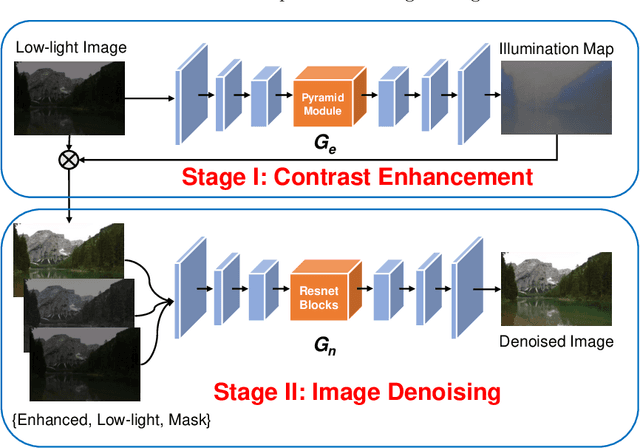



Conventional learning-based approaches to low-light image enhancement typically require a large amount of paired training data, which are difficult to acquire in real-world scenarios. Recently, unsupervised models for this task have been explored to eliminate the use of paired data. However, these methods primarily tackle the problem of illumination enhancement, and usually fail to suppress the noises that ubiquitously exist in images taken under real-world low-light conditions. In this paper, we address the real-world low-light image enhancement problem by decoupling this task into two sub-tasks: illumination enhancement and noise suppression. We propose to learn a two-stage GAN-based framework to enhance the real-world low-light images in a fully unsupervised fashion. In addition to conventional benchmark datasets, a new unpaired low-light image enhancement dataset is built and used to thoroughly evaluate the performance of our model. Extensive experiments show that our method outperforms the state-of-the-art unsupervised image enhancement methods in terms of both illumination enhancement and noise reduction.
Scale-wise Convolution for Image Restoration
Dec 19, 2019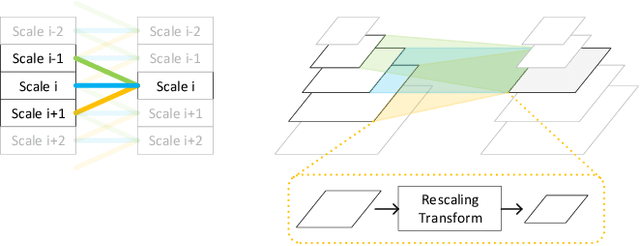
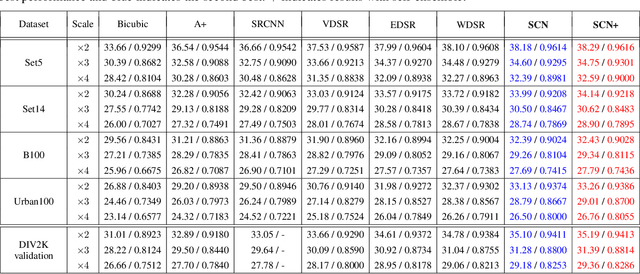
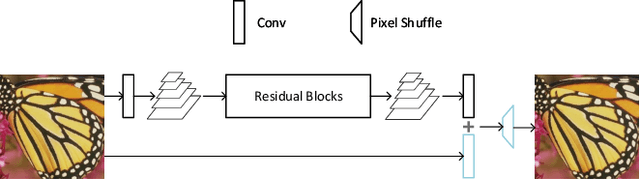
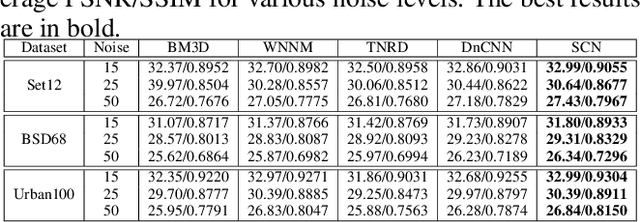
While scale-invariant modeling has substantially boosted the performance of visual recognition tasks, it remains largely under-explored in deep networks based image restoration. Naively applying those scale-invariant techniques (e.g. multi-scale testing, random-scale data augmentation) to image restoration tasks usually leads to inferior performance. In this paper, we show that properly modeling scale-invariance into neural networks can bring significant benefits to image restoration performance. Inspired from spatial-wise convolution for shift-invariance, "scale-wise convolution" is proposed to convolve across multiple scales for scale-invariance. In our scale-wise convolutional network (SCN), we first map the input image to the feature space and then build a feature pyramid representation via bi-linear down-scaling progressively. The feature pyramid is then passed to a residual network with scale-wise convolutions. The proposed scale-wise convolution learns to dynamically activate and aggregate features from different input scales in each residual building block, in order to exploit contextual information on multiple scales. In experiments, we compare the restoration accuracy and parameter efficiency among our model and many different variants of multi-scale neural networks. The proposed network with scale-wise convolution achieves superior performance in multiple image restoration tasks including image super-resolution, image denoising and image compression artifacts removal. Code and models are available at: https://github.com/ychfan/scn_sr
DAVID: Dual-Attentional Video Deblurring
Dec 07, 2019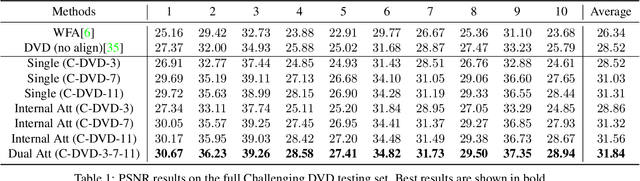
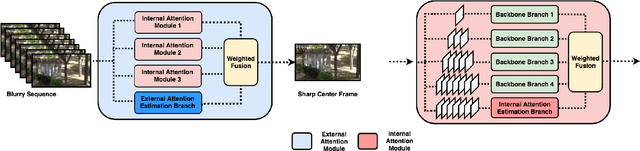

Blind video deblurring restores sharp frames from a blurry sequence without any prior. It is a challenging task because the blur due to camera shake, object movement and defocusing is heterogeneous in both temporal and spatial dimensions. Traditional methods train on datasets synthesized with a single level of blur, and thus do not generalize well across levels of blurriness. To address this challenge, we propose a dual attention mechanism to dynamically aggregate temporal cues for deblurring with an end-to-end trainable network structure. Specifically, an internal attention module adaptively selects the optimal temporal scales for restoring the sharp center frame. An external attention module adaptively aggregates and refines multiple sharp frame estimates, from several internal attention modules designed for different blur levels. To train and evaluate on more diverse blur severity levels, we propose a Challenging DVD dataset generated from the raw DVD video set by pooling frames with different temporal windows. Our framework achieves consistently better performance on this more challenging dataset while obtaining strongly competitive results on the original DVD benchmark. Extensive ablative studies and qualitative visualizations further demonstrate the advantage of our method in handling real video blur.
Information Bottleneck Methods on Convolutional Neural Networks
Nov 09, 2019
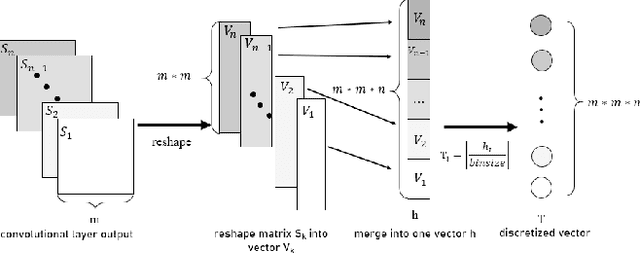
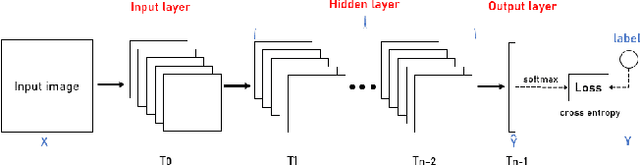
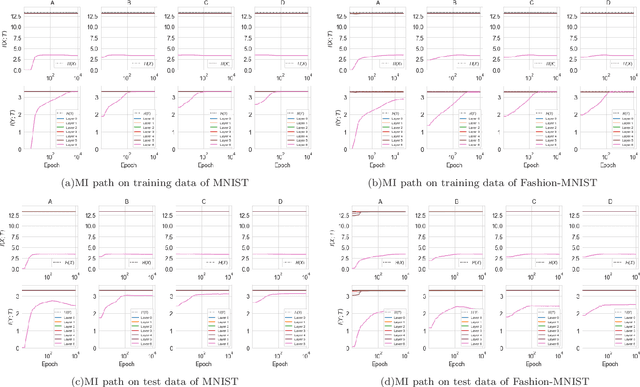
Recent year, many researches attempt to open the black box of deep neural networks and propose a various of theories to understand it. Among them, information bottleneck theory (IB) claims that there are two distinct phases consisting of fitting phase and compression phase in the course of training. This statement attracts many attentions since its success in explaining the inner behavior of feedforward neural networks. In this paper, we employ IB theory to understand the dynamic behavior of convolutional neural networks (CNNs) and investigate how the fundamental features have impact on the performance of CNNs. In particular, through a series of experimental analysis on benchmark of MNIST and Fashion-MNIST, we demonstrate that the compression phase is not observed in all these cases. This show us the CNNs have a rather complicated behavior than feedforward neural networks.
EnlightenGAN: Deep Light Enhancement without Paired Supervision
Jun 17, 2019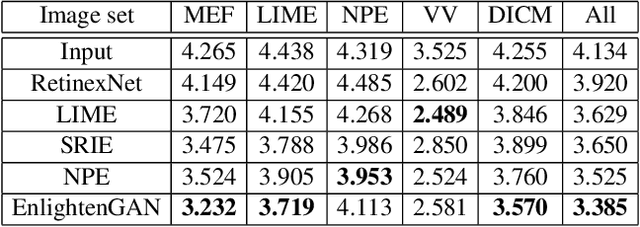
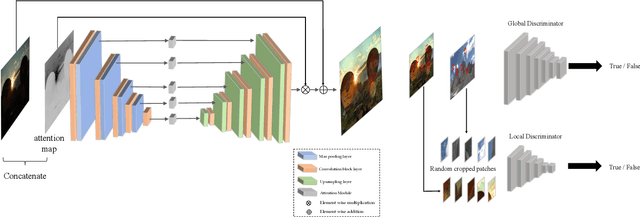


Deep learning-based methods have achieved remarkable success in image restoration and enhancement, but are they still competitive when there is a lack of paired training data? As one such example, this paper explores the low-light image enhancement problem, where in practice it is extremely challenging to simultaneously take a low-light and a normal-light photo of the same visual scene. We propose a highly effective unsupervised generative adversarial network, dubbed EnlightenGAN, that can be trained without low/normal-light image pairs, yet proves to generalize very well on various real-world test images. Instead of supervising the learning using ground truth data, we propose to regularize the unpaired training using the information extracted from the input itself, and benchmark a series of innovations for the low-light image enhancement problem, including a global-local discriminator structure, a self-regularized perceptual loss fusion, and attention mechanism. Through extensive experiments, our proposed approach outperforms recent methods under a variety of metrics in terms of visual quality and subjective user study. Thanks to the great flexibility brought by unpaired training, EnlightenGAN is demonstrated to be easily adaptable to enhancing real-world images from various domains. The code is available at \url{https://github.com/yueruchen/EnlightenGAN}
Generative Tensor Network Classification Model for Supervised Machine Learning
Mar 26, 2019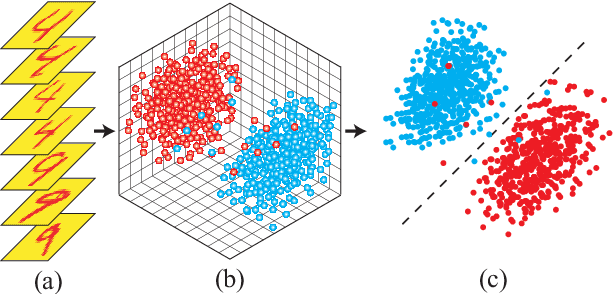
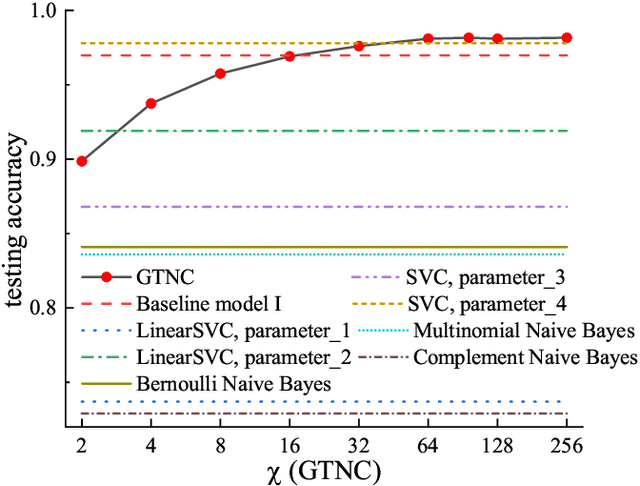
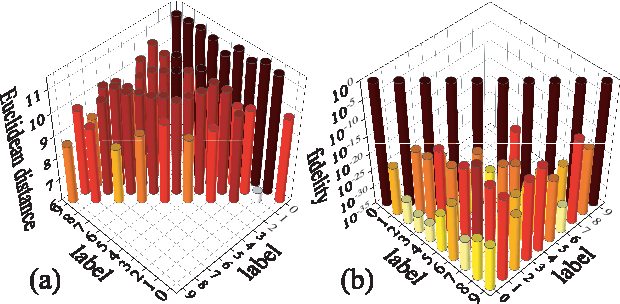
Tensor network (TN) has recently triggered extensive interests in developing machine-learning models in quantum many-body Hilbert space. Here we purpose a generative TN classification (GTNC) approach for supervised learning. The strategy is to train the generative TN for each class of the samples to construct the classifiers. The classification is implemented by comparing the distance in the many-body Hilbert space. The numerical experiments by GTNC show impressive performance on the MNIST and Fashion-MNIST dataset. The testing accuracy is competitive to the state-of-the-art convolutional neural network while higher than the naive Bayes classifier (a generative classifier) and support vector machine. Moreover, GTNC is more efficient than the existing TN models that are in general discriminative. By investigating the distances in the many-body Hilbert space, we find that (a) the samples are naturally clustering in such a space; and (b) bounding the bond dimensions of the TN's to finite values corresponds to removing redundant information in the image recognition. These two characters make GTNC an adaptive and universal model of excellent performance.
Machine Learning by Two-Dimensional Hierarchical Tensor Networks: A Quantum Information Theoretic Perspective on Deep Architectures
Oct 23, 2018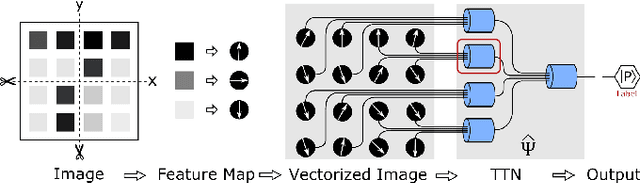
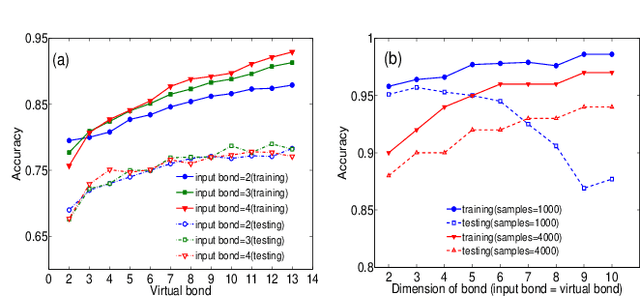

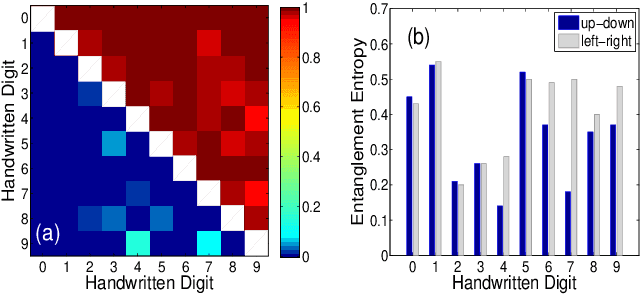
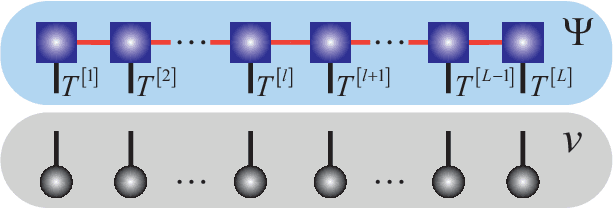
The resemblance between the methods used in quantum-many body physics and in machine learning has drawn considerable attention. In particular, tensor networks (TNs) and deep learning architectures bear striking similarities to the extent that TNs can be used for machine learning. Previous results used one-dimensional TNs in image recognition, showing limited scalability and flexibilities. In this work, we train two-dimensional hierarchical TNs to solve image recognition problems, using a training algorithm derived from the multipartite entanglement renormalization ansatz. This approach introduces novel mathematical connections among quantum many-body physics, quantum information theory, and machine learning. While keeping the TN unitary in the training phase, TN states are defined, which optimally encode classes of images into quantum many-body states. We study the quantum features of the TN states, including quantum entanglement and fidelity. We find these quantities could be novel properties that characterize the image classes, as well as the machine learning tasks. Our work could contribute to the research on identifying/modeling quantum artificial intelligences.
Connecting Image Denoising and High-Level Vision Tasks via Deep Learning
Sep 06, 2018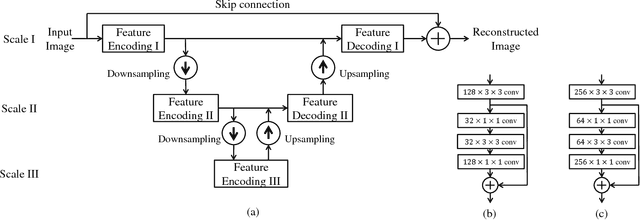
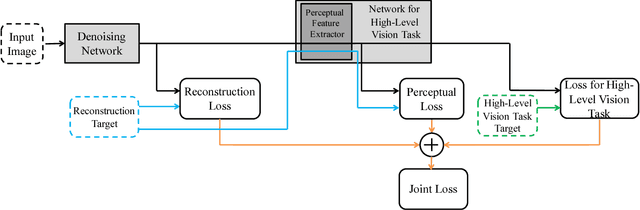

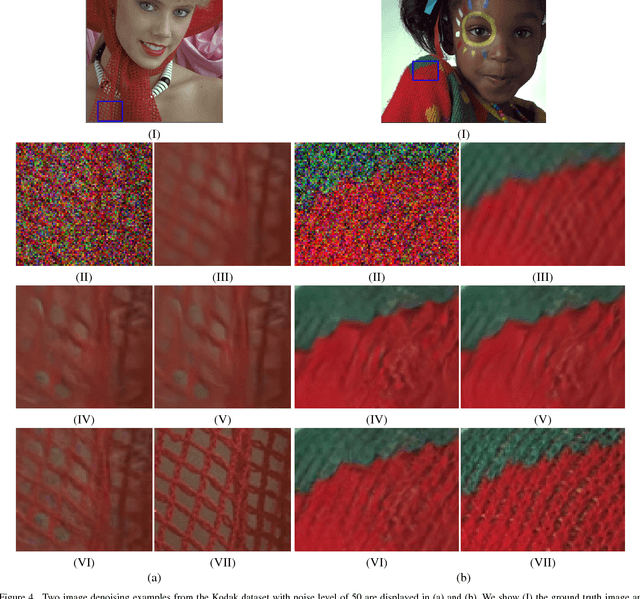
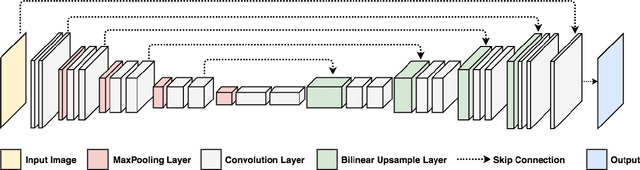
Image denoising and high-level vision tasks are usually handled independently in the conventional practice of computer vision, and their connection is fragile. In this paper, we cope with the two jointly and explore the mutual influence between them with the focus on two questions, namely (1) how image denoising can help improving high-level vision tasks, and (2) how the semantic information from high-level vision tasks can be used to guide image denoising. First for image denoising we propose a convolutional neural network in which convolutions are conducted in various spatial resolutions via downsampling and upsampling operations in order to fuse and exploit contextual information on different scales. Second we propose a deep neural network solution that cascades two modules for image denoising and various high-level tasks, respectively, and use the joint loss for updating only the denoising network via back-propagation. We experimentally show that on one hand, the proposed denoiser has the generality to overcome the performance degradation of different high-level vision tasks. On the other hand, with the guidance of high-level vision information, the denoising network produces more visually appealing results. Extensive experiments demonstrate the benefit of exploiting image semantics simultaneously for image denoising and high-level vision tasks via deep learning. The code is available online: https://github.com/Ding-Liu/DeepDenoising
U-Finger: Multi-Scale Dilated Convolutional Network for Fingerprint Image Denoising and Inpainting
Aug 05, 2018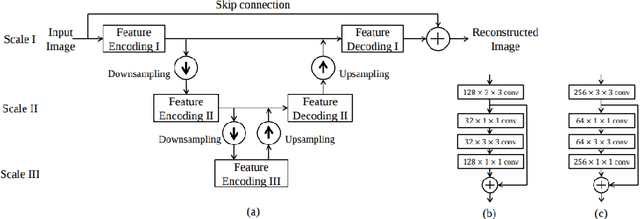



This paper studies the challenging problem of fingerprint image denoising and inpainting. To tackle the challenge of suppressing complicated artifacts (blur, brightness, contrast, elastic transformation, occlusion, scratch, resolution, rotation, and so on) while preserving fine textures, we develop a multi-scale convolutional network, termed U- Finger. Based on the domain expertise, we show that the usage of dilated convolutions as well as the removal of padding have important positive impacts on the final restoration performance, in addition to multi-scale cascaded feature modules. Our model achieves the overall ranking of No.2 in the ECCV 2018 Chalearn LAP Inpainting Competition Track 3 (Fingerprint Denoising and Inpainting). Among all participating teams, we obtain the MSE of 0.0231 (rank 2), PSNR 16.9688 dB (rank 2), and SSIM 0.8093 (rank 3) on the hold-out testing set.
Non-Local Recurrent Network for Image Restoration
Jun 07, 2018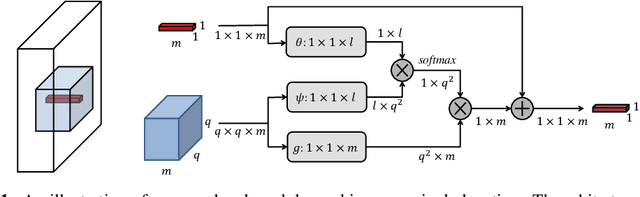
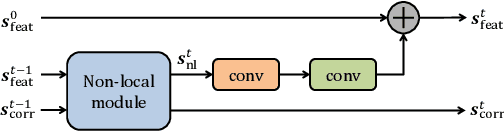
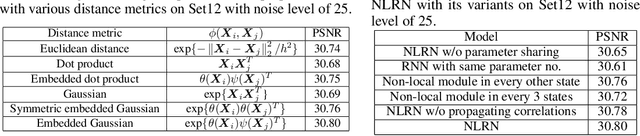
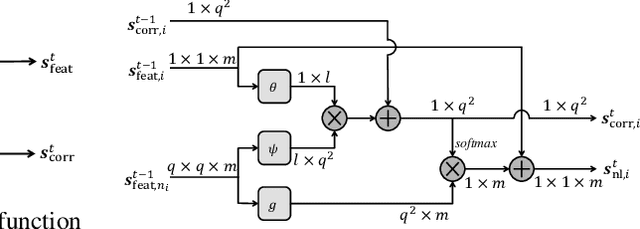
Many classic methods have shown non-local self-similarity in natural images to be an effective prior for image restoration. However, it remains unclear and challenging to make use of this intrinsic property via deep networks. In this paper, we propose a non-local recurrent network (NLRN) as the first attempt to incorporate non-local operations into a recurrent neural network (RNN) for image restoration. The main contributions of this work are: (1) Unlike existing methods that measure self-similarity in an isolated manner, the proposed non-local module can be flexibly integrated into existing deep networks for end-to-end training to capture deep feature correlation between each location and its neighborhood. (2) We fully employ the RNN structure for its parameter efficiency and allow deep feature correlation to be propagated along adjacent recurrent states. This new design boosts robustness against inaccurate correlation estimation due to severely degraded images. (3) We show that it is essential to maintain a confined neighborhood for computing deep feature correlation given degraded images. This is in contrast to existing practice that deploys the whole image. Extensive experiments on both image denoising and super-resolution tasks are conducted. Thanks to the recurrent non-local operations and correlation propagation, the proposed NLRN achieves superior results to state-of-the-art methods with much fewer parameters.