 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Orchestration of Multi-Agent Systems: Architectures, Protocols, and Enterprise Adoption
Jan 20, 2026Orchestrated multi-agent systems represent the next stage in the evolution of artificial intelligence, where autonomous agents collaborate through structured coordination and communication to achieve complex, shared objectives. This paper consolidates and formalizes the technical composition of such systems, presenting a unified architectural framework that integrates planning, policy enforcement, state management, and quality operations into a coherent orchestration layer. Another primary contribution of this work is the in-depth technical delineation of two complementary communication protocols - the Model Context Protocol, which standardizes how agents access external tools and contextual data, and the Agent2Agent protocol, which governs peer coordination, negotiation, and delegation. Together, these protocols establish an interoperable communication substrate that enables scalable, auditable, and policy-compliant reasoning across distributed agent collectives. Beyond protocol design, the paper details how orchestration logic, governance frameworks, and observability mechanisms collectively sustain system coherence, transparency, and accountability. By synthesizing these elements into a cohesive technical blueprint, this paper provides comprehensive treatments of orchestrated multi-agent systems - bridging conceptual architectures with implementation-ready design principles for enterprise-scale AI ecosystems.
Physics-Informed Data Denoising for Real-Life Sensing Systems
Nov 12, 2023
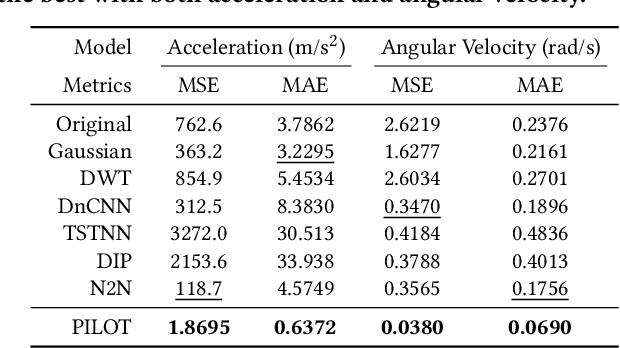


Sensors measuring real-life physical processes are ubiquitous in today's interconnected world. These sensors inherently bear noise that often adversely affects performance and reliability of the systems they support. Classic filtering-based approaches introduce strong assumptions on the time or frequency characteristics of sensory measurements, while learning-based denoising approaches typically rely on using ground truth clean data to train a denoising model, which is often challenging or prohibitive to obtain for many real-world applications. We observe that in many scenarios, the relationships between different sensor measurements (e.g., location and acceleration) are analytically described by laws of physics (e.g., second-order differential equation). By incorporating such physics constraints, we can guide the denoising process to improve even in the absence of ground truth data. In light of this, we design a physics-informed denoising model that leverages the inherent algebraic relationships between different measurements governed by the underlying physics. By obviating the need for ground truth clean data, our method offers a practical denoising solution for real-world applications. We conducted experiments in various domains, including inertial navigation, CO2 monitoring, and HVAC control, and achieved state-of-the-art performance compared with existing denoising methods. Our method can denoise data in real time (4ms for a sequence of 1s) for low-cost noisy sensors and produces results that closely align with those from high-precision, high-cost alternatives, leading to an efficient, cost-effective approach for more accurate sensor-based systems.
Targeted collapse regularized autoencoder for anomaly detection: black hole at the center
Jun 22, 2023



Autoencoders have been extensively used in the development of recent anomaly detection techniques. The premise of their application is based on the notion that after training the autoencoder on normal training data, anomalous inputs will exhibit a significant reconstruction error. Consequently, this enables a clear differentiation between normal and anomalous samples. In practice, however, it is observed that autoencoders can generalize beyond the normal class and achieve a small reconstruction error on some of the anomalous samples. To improve the performance, various techniques propose additional components and more sophisticated training procedures. In this work, we propose a remarkably straightforward alternative: instead of adding neural network components, involved computations, and cumbersome training, we complement the reconstruction loss with a computationally light term that regulates the norm of representations in the latent space. The simplicity of our approach minimizes the requirement for hyperparameter tuning and customization for new applications which, paired with its permissive data modality constraint, enhances the potential for successful adoption across a broad range of applications. We test the method on various visual and tabular benchmarks and demonstrate that the technique matches and frequently outperforms alternatives. We also provide a theoretical analysis and numerical simulations that help demonstrate the underlying process that unfolds during training and how it can help with anomaly detection. This mitigates the black-box nature of autoencoder-based anomaly detection algorithms and offers an avenue for further investigation of advantages, fail cases, and potential new directions.
Towards Diverse and Coherent Augmentation for Time-Series Forecasting
Mar 24, 2023



Time-series data augmentation mitigates the issue of insufficient training data for deep learning models. Yet, existing augmentation methods are mainly designed for classification, where class labels can be preserved even if augmentation alters the temporal dynamics. We note that augmentation designed for forecasting requires diversity as well as coherence with the original temporal dynamics. As time-series data generated by real-life physical processes exhibit characteristics in both the time and frequency domains, we propose to combine Spectral and Time Augmentation (STAug) for generating more diverse and coherent samples. Specifically, in the frequency domain, we use the Empirical Mode Decomposition to decompose a time series and reassemble the subcomponents with random weights. This way, we generate diverse samples while being coherent with the original temporal relationships as they contain the same set of base components. In the time domain, we adapt a mix-up strategy that generates diverse as well as linearly in-between coherent samples. Experiments on five real-world time-series datasets demonstrate that STAug outperforms the base models without data augmentation as well as state-of-the-art augmentation methods.
B2RL: An open-source Dataset for Building Batch Reinforcement Learning
Sep 30, 2022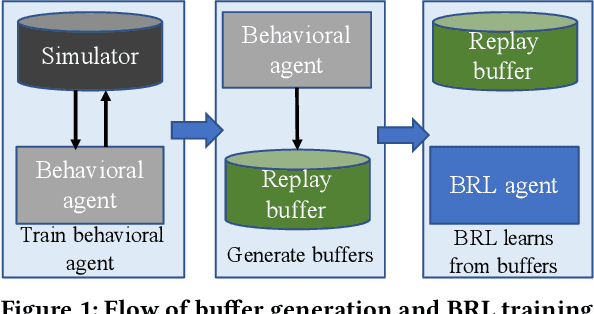
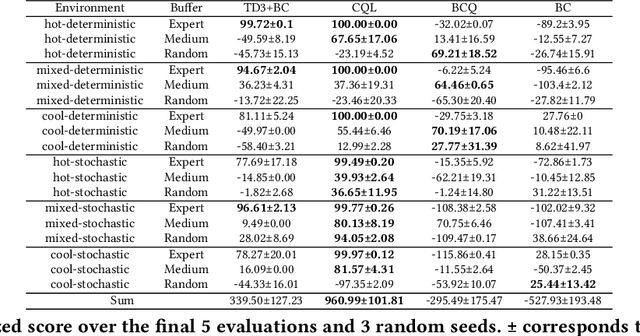
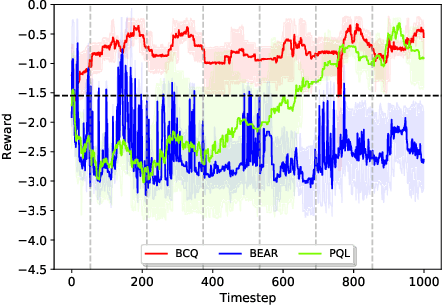
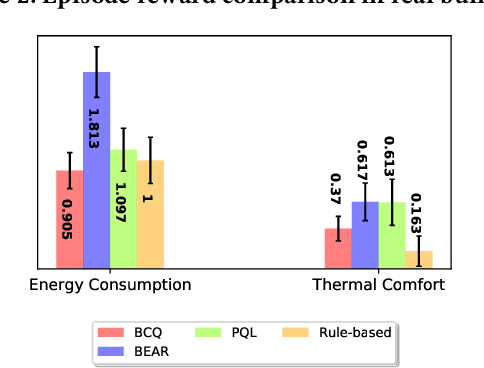
Batch reinforcement learning (BRL) is an emerging research area in the RL community. It learns exclusively from static datasets (i.e. replay buffers) without interaction with the environment. In the offline settings, existing replay experiences are used as prior knowledge for BRL models to find the optimal policy. Thus, generating replay buffers is crucial for BRL model benchmark. In our B2RL (Building Batch RL) dataset, we collected real-world data from our building management systems, as well as buffers generated by several behavioral policies in simulation environments. We believe it could help building experts on BRL research. To the best of our knowledge, we are the first to open-source building datasets for the purpose of BRL learning.
Sensei: Self-Supervised Sensor Name Segmentation
Jan 01, 2021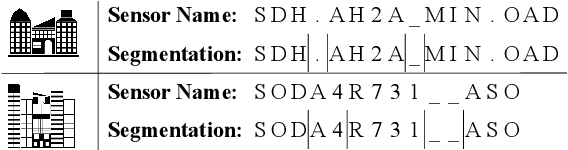

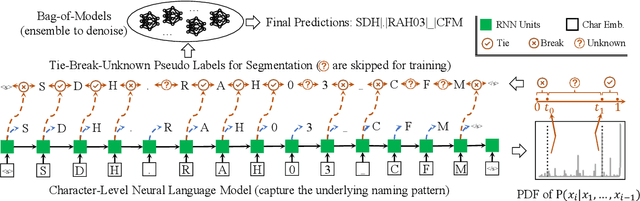
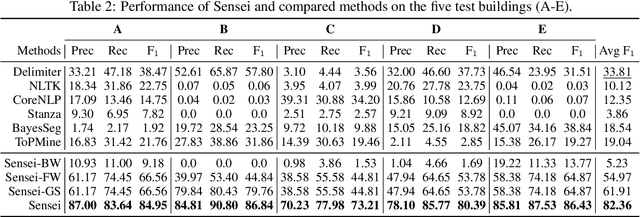
A sensor name, typically an alphanumeric string, encodes the key context (e.g., function and location) of a sensor needed for deploying smart building applications. Sensor names, however, are curated in a building vendor-specific manner using different structures and vocabularies that are often esoteric. They thus require tremendous manual effort to annotate on a per-building basis; even to just segment these sensor names into meaningful chunks. In this paper, we propose a fully automated self-supervised framework, Sensei, which can learn to segment sensor names without any human annotation. Specifically, we employ a neural language model to capture the underlying sensor naming structure and then induce self-supervision based on information from the language model to build the segmentation model. Extensive experiments on five real-world buildings comprising thousands of sensors demonstrate the superiority of Sensei over baseline methods.
Scaling Configuration of Energy Harvesting Sensors with Reinforcement Learning
Nov 27, 2018
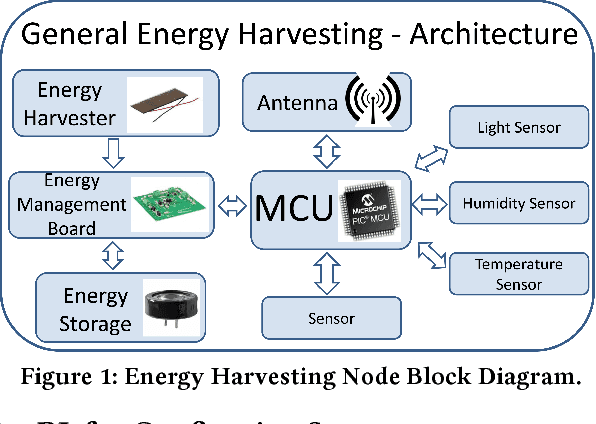
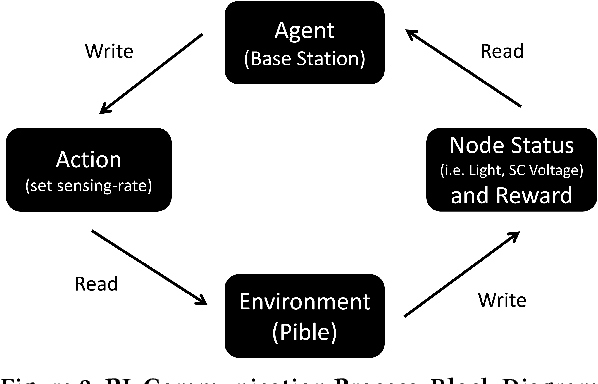
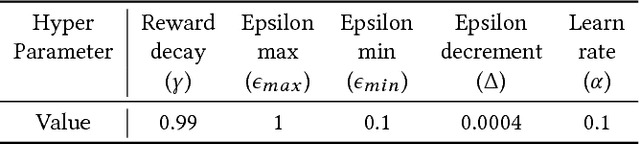
With the advent of the Internet of Things (IoT), an increasing number of energy harvesting methods are being used to supplement or supplant battery based sensors. Energy harvesting sensors need to be configured according to the application, hardware, and environmental conditions to maximize their usefulness. As of today, the configuration of sensors is either manual or heuristics based, requiring valuable domain expertise. Reinforcement learning (RL) is a promising approach to automate configuration and efficiently scale IoT deployments, but it is not yet adopted in practice. We propose solutions to bridge this gap: reduce the training phase of RL so that nodes are operational within a short time after deployment and reduce the computational requirements to scale to large deployments. We focus on configuration of the sampling rate of indoor solar panel based energy harvesting sensors. We created a simulator based on 3 months of data collected from 5 sensor nodes subject to different lighting conditions. Our simulation results show that RL can effectively learn energy availability patterns and configure the sampling rate of the sensor nodes to maximize the sensing data while ensuring that energy storage is not depleted. The nodes can be operational within the first day by using our methods. We show that it is possible to reduce the number of RL policies by using a single policy for nodes that share similar lighting conditions.
* 7 pages, 5 figures
Local Binary Pattern Networks
Mar 22, 2018
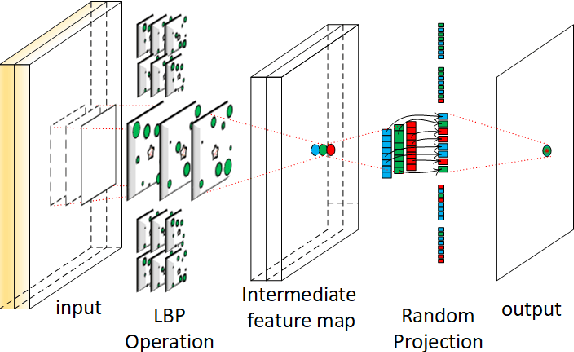
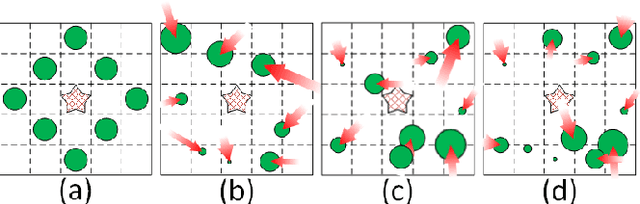
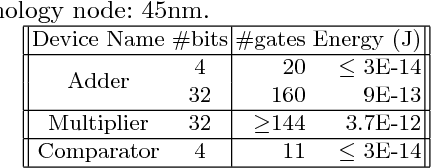
Memory and computation efficient deep learning architec- tures are crucial to continued proliferation of machine learning capabili- ties to new platforms and systems. Binarization of operations in convo- lutional neural networks has shown promising results in reducing model size and computing efficiency. In this paper, we tackle the problem us- ing a strategy different from the existing literature by proposing local binary pattern networks or LBPNet, that is able to learn and perform binary operations in an end-to-end fashion. LBPNet1 uses local binary comparisons and random projection in place of conventional convolu- tion (or approximation of convolution) operations. These operations can be implemented efficiently on different platforms including direct hard- ware implementation. We applied LBPNet and its variants on standard benchmarks. The results are promising across benchmarks while provid- ing an important means to improve memory and speed efficiency that is particularly suited for small footprint devices and hardware accelerators.