 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalance of Number of Embedding and their Dimensions in Vector Quantization
Jul 06, 2024



The dimensionality of the embedding and the number of available embeddings ( also called codebook size) are critical factors influencing the performance of Vector Quantization(VQ), a discretization process used in many models such as the Vector Quantized Variational Autoencoder (VQ-VAE) architecture. This study examines the balance between the codebook sizes and dimensions of embeddings in VQ, while maintaining their product constant. Traditionally, these hyper parameters are static during training; however, our findings indicate that augmenting the codebook size while simultaneously reducing the embedding dimension can significantly boost the effectiveness of the VQ-VAE. As a result, the strategic selection of codebook size and embedding dimensions, while preserving the capacity of the discrete codebook space, is critically important. To address this, we propose a novel adaptive dynamic quantization approach, underpinned by the Gumbel-Softmax mechanism, which allows the model to autonomously determine the optimal codebook configuration for each data instance. This dynamic discretizer gives the VQ-VAE remarkable flexibility. Thorough empirical evaluations across multiple benchmark datasets validate the notable performance enhancements achieved by our approach, highlighting the significant potential of adaptive dynamic quantization to improve model performance.
Common and Rare Fundus Diseases Identification Using Vision-Language Foundation Model with Knowledge of Over 400 Diseases
Jun 13, 2024



The current retinal artificial intelligence models were trained using data with a limited category of diseases and limited knowledge. In this paper, we present a retinal vision-language foundation model (RetiZero) with knowledge of over 400 fundus diseases. Specifically, we collected 341,896 fundus images paired with text descriptions from 29 publicly available datasets, 180 ophthalmic books, and online resources, encompassing over 400 fundus diseases across multiple countries and ethnicities. RetiZero achieved outstanding performance across various downstream tasks, including zero-shot retinal disease recognition, image-to-image retrieval, internal domain and cross-domain retinal disease classification, and few-shot fine-tuning. Specially, in the zero-shot scenario, RetiZero achieved a Top5 score of 0.8430 and 0.7561 on 15 and 52 fundus diseases respectively. In the image-retrieval task, RetiZero achieved a Top5 score of 0.9500 and 0.8860 on 15 and 52 retinal diseases respectively. Furthermore, clinical evaluations by ophthalmology experts from different countries demonstrate that RetiZero can achieve performance comparable to experienced ophthalmologists using zero-shot and image retrieval methods without requiring model retraining. These capabilities of retinal disease identification strengthen our RetiZero foundation model in clinical implementation.
Verbalized Probabilistic Graphical Modeling with Large Language Models
Jun 08, 2024Faced with complex problems, the human brain demonstrates a remarkable capacity to transcend sensory input and form latent understandings of perceived world patterns. However, this cognitive capacity is not explicitly considered or encoded in current large language models (LLMs). As a result, LLMs often struggle to capture latent structures and model uncertainty in complex compositional reasoning tasks. This work introduces a novel Bayesian prompting approach that facilitates training-free Bayesian inference with LLMs by using a verbalized Probabilistic Graphical Model (PGM). While traditional Bayesian approaches typically depend on extensive data and predetermined mathematical structures for learning latent factors and dependencies, our approach efficiently reasons latent variables and their probabilistic dependencies by prompting LLMs to adhere to Bayesian principles. We evaluated our model on several compositional reasoning tasks, both close-ended and open-ended. Our results indicate that the model effectively enhances confidence elicitation and text generation quality, demonstrating its potential to improve AI language understanding systems, especially in modeling uncertainty.
Bifurcated Generative Flow Networks
Jun 04, 2024

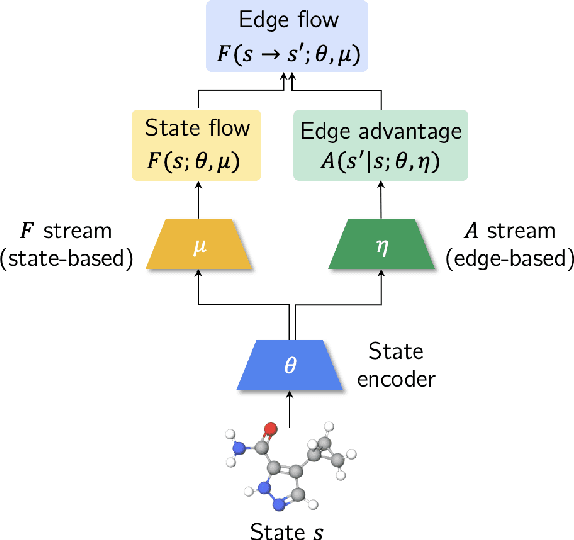
Generative Flow Networks (GFlowNets), a new family of probabilistic samplers, have recently emerged as a promising framework for learning stochastic policies that generate high-quality and diverse objects proportionally to their rewards. However, existing GFlowNets often suffer from low data efficiency due to the direct parameterization of edge flows or reliance on backward policies that may struggle to scale up to large action spaces. In this paper, we introduce Bifurcated GFlowNets (BN), a novel approach that employs a bifurcated architecture to factorize the flows into separate representations for state flows and edge-based flow allocation. This factorization enables BN to learn more efficiently from data and better handle large-scale problems while maintaining the convergence guarantee. Through extensive experiments on standard evaluation benchmarks, we demonstrate that BN significantly improves learning efficiency and effectiveness compared to strong baselines.
VQSynery: Robust Drug Synergy Prediction With Vector Quantization Mechanism
Mar 05, 2024The pursuit of optimizing cancer therapies is significantly advanced by the accurate prediction of drug synergy. Traditional methods, such as clinical trials, are reliable yet encumbered by extensive time and financial demands. The emergence of high-throughput screening and computational innovations has heralded a shift towards more efficient methodologies for exploring drug interactions. In this study, we present VQSynergy, a novel framework that employs the Vector Quantization (VQ) mechanism, integrated with gated residuals and a tailored attention mechanism, to enhance the precision and generalizability of drug synergy predictions. Our findings demonstrate that VQSynergy surpasses existing models in terms of robustness, particularly under Gaussian noise conditions, highlighting its superior performance and utility in the complex and often noisy domain of drug synergy research. This study underscores the potential of VQSynergy in revolutionizing the field through its advanced predictive capabilities, thereby contributing to the optimization of cancer treatment strategies.
Uncertainty-Based Extensible Codebook for Discrete Federated Learning in Heterogeneous Data Silos
Mar 01, 2024



Federated learning (FL), aimed at leveraging vast distributed datasets, confronts a crucial challenge: the heterogeneity of data across different silos. While previous studies have explored discrete representations to enhance model generalization across minor distributional shifts, these approaches often struggle to adapt to new data silos with significantly divergent distributions. In response, we have identified that models derived from FL exhibit markedly increased uncertainty when applied to data silos with unfamiliar distributions. Consequently, we propose an innovative yet straightforward iterative framework, termed Uncertainty-Based Extensible-Codebook Federated Learning (UEFL). This framework dynamically maps latent features to trainable discrete vectors, assesses the uncertainty, and specifically extends the discretization dictionary or codebook for silos exhibiting high uncertainty. Our approach aims to simultaneously enhance accuracy and reduce uncertainty by explicitly addressing the diversity of data distributions, all while maintaining minimal computational overhead in environments characterized by heterogeneous data silos. Through experiments conducted on five datasets, our method has demonstrated its superiority, achieving significant improvements in accuracy (by 3%--22.1%) and uncertainty reduction (by 38.83%--96.24%), thereby outperforming contemporary state-of-the-art methods. The source code is available at https://github.com/destiny301/uefl.
Unsupervised Concept Discovery Mitigates Spurious Correlations
Feb 20, 2024



Models prone to spurious correlations in training data often produce brittle predictions and introduce unintended biases. Addressing this challenge typically involves methods relying on prior knowledge and group annotation to remove spurious correlations, which may not be readily available in many applications. In this paper, we establish a novel connection between unsupervised object-centric learning and mitigation of spurious correlations. Instead of directly inferring sub-groups with varying correlations with labels, our approach focuses on discovering concepts: discrete ideas that are shared across input samples. Leveraging existing object-centric representation learning, we introduce CoBalT: a concept balancing technique that effectively mitigates spurious correlations without requiring human labeling of subgroups. Evaluation across the Waterbirds, CelebA and ImageNet-9 benchmark datasets for subpopulation shifts demonstrate superior or competitive performance compared state-of-the-art baselines, without the need for group annotation.
BarlowTwins-CXR : Enhancing Chest X-Ray abnormality localization in heterogeneous data with cross-domain self-supervised learning
Feb 09, 2024Background: Chest X-ray imaging-based abnormality localization, essential in diagnosing various diseases, faces significant clinical challenges due to complex interpretations and the growing workload of radiologists. While recent advances in deep learning offer promising solutions, there is still a critical issue of domain inconsistency in cross-domain transfer learning, which hampers the efficiency and accuracy of diagnostic processes. This study aims to address the domain inconsistency problem and improve autonomic abnormality localization performance of heterogeneous chest X-ray image analysis, by developing a self-supervised learning strategy called "BarlwoTwins-CXR". Methods: We utilized two publicly available datasets: the NIH Chest X-ray Dataset and the VinDr-CXR. The BarlowTwins-CXR approach was conducted in a two-stage training process. Initially, self-supervised pre-training was performed using an adjusted Barlow Twins algorithm on the NIH dataset with a Resnet50 backbone pre-trained on ImageNet. This was followed by supervised fine-tuning on the VinDr-CXR dataset using Faster R-CNN with Feature Pyramid Network (FPN). Results: Our experiments showed a significant improvement in model performance with BarlowTwins-CXR. The approach achieved a 3% increase in mAP50 accuracy compared to traditional ImageNet pre-trained models. In addition, the Ablation CAM method revealed enhanced precision in localizing chest abnormalities. Conclusion: BarlowTwins-CXR significantly enhances the efficiency and accuracy of chest X-ray image-based abnormality localization, outperforming traditional transfer learning methods and effectively overcoming domain inconsistency in cross-domain scenarios. Our experiment results demonstrate the potential of using self-supervised learning to improve the generalizability of models in medical settings with limited amounts of heterogeneous data.
Evolution Guided Generative Flow Networks
Feb 03, 2024



Generative Flow Networks (GFlowNets) are a family of probabilistic generative models that learn to sample compositional objects proportional to their rewards. One big challenge of GFlowNets is training them effectively when dealing with long time horizons and sparse rewards. To address this, we propose Evolution guided generative flow networks (EGFN), a simple but powerful augmentation to the GFlowNets training using Evolutionary algorithms (EA). Our method can work on top of any GFlowNets training objective, by training a set of agent parameters using EA, storing the resulting trajectories in the prioritized replay buffer, and training the GFlowNets agent using the stored trajectories. We present a thorough investigation over a wide range of toy and real-world benchmark tasks showing the effectiveness of our method in handling long trajectories and sparse rewards.
Discrete Messages Improve Communication Efficiency among Isolated Intelligent Agents
Dec 28, 2023



Individuals, despite having varied life experiences and learning processes, can communicate effectively through languages. This study aims to explore the efficiency of language as a communication medium. We put forth two specific hypotheses: First, discrete messages are more effective than continuous ones when agents have diverse personal experiences. Second, communications using multiple discrete tokens are more advantageous than those using a single token. To valdate these hypotheses, we designed multi-agent machine learning experiments to assess communication efficiency using various information transmission methods between speakers and listeners. Our empirical findings indicate that, in scenarios where agents are exposed to different data, communicating through sentences composed of discrete tokens offers the best inter-agent communication efficiency. The limitations of our finding include lack of systematic advantages over other more sophisticated encoder-decoder model such as variational autoencoder and lack of evluation on non-image dataset, which we will leave for future studies.