 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort Data, Long Context: Distilling Positional Knowledge in Transformers
Apr 07, 2026Extending the context window of language models typically requires expensive long-context pre-training, posing significant challenges for both training efficiency and data collection. In this paper, we present evidence that long-context retrieval capabilities can be transferred to student models through logit-based knowledge distillation, even when training exclusively on packed short-context samples within a long-context window. We provide comprehensive insights through the lens of Rotary Position Embedding (RoPE) and establish three key findings. First, consistent with prior work, we show that phase-wise RoPE scaling, which maximizes rotational spectrum utilization at each training stage, also achieves the best long-context performance in knowledge distillation setups. Second, we demonstrate that logit-based knowledge distillation can directly enable positional information transfer. Using an experimental setup with packed repeated token sequences, we trace the propagation of positional perturbations from query and key vectors through successive transformer layers to output logits, revealing that positional information systematically influences the teacher's output distribution and, in turn, the distillation signal received by the student model. Third, our analysis uncovers structured update patterns in the query state during long-context extension, with distinct parameter spans exhibiting strong sensitivity to long-context training.
Layer by Layer: Uncovering Hidden Representations in Language Models
Feb 04, 2025



From extracting features to generating text, the outputs of large language models (LLMs) typically rely on their final layers, following the conventional wisdom that earlier layers capture only low-level cues. However, our analysis shows that intermediate layers can encode even richer representations, often improving performance on a wide range of downstream tasks. To explain and quantify these hidden-layer properties, we propose a unified framework of representation quality metrics based on information theory, geometry, and invariance to input perturbations. Our framework highlights how each model layer balances information compression and signal preservation, revealing why mid-depth embeddings can exceed the last layer's performance. Through extensive experiments on 32 text-embedding tasks and comparisons across model architectures (transformers, state-space models) and domains (language, vision), we demonstrate that intermediate layers consistently provide stronger features. These findings challenge the standard focus on final-layer embeddings and open new directions for model analysis and optimization, including strategic use of mid-layer representations for more robust and accurate AI systems.
Does Representation Matter? Exploring Intermediate Layers in Large Language Models
Dec 12, 2024Understanding what defines a good representation in large language models (LLMs) is fundamental to both theoretical understanding and practical applications. In this paper, we investigate the quality of intermediate representations in various LLM architectures, including Transformers and State Space Models (SSMs). We find that intermediate layers often yield more informative representations for downstream tasks than the final layers. To measure the representation quality, we adapt and apply a suite of metrics - such as prompt entropy, curvature, and augmentation-invariance - originally proposed in other contexts. Our empirical study reveals significant architectural differences, how representations evolve throughout training, and how factors like input randomness and prompt length affect each layer. Notably, we observe a bimodal pattern in the entropy of some intermediate layers and consider potential explanations tied to training data. Overall, our results illuminate the internal mechanics of LLMs and guide strategies for architectural optimization and training.
Seq-VCR: Preventing Collapse in Intermediate Transformer Representations for Enhanced Reasoning
Nov 04, 2024



Decoder-only Transformers often struggle with complex reasoning tasks, particularly arithmetic reasoning requiring multiple sequential operations. In this work, we identify representation collapse in the model's intermediate layers as a key factor limiting their reasoning capabilities. To address this, we propose Sequential Variance-Covariance Regularization (Seq-VCR), which enhances the entropy of intermediate representations and prevents collapse. Combined with dummy pause tokens as substitutes for chain-of-thought (CoT) tokens, our method significantly improves performance in arithmetic reasoning problems. In the challenging $5 \times 5$ integer multiplication task, our approach achieves $99.5\%$ exact match accuracy, outperforming models of the same size (which yield $0\%$ accuracy) and GPT-4 with five-shot CoT prompting ($44\%$). We also demonstrate superior results on arithmetic expression and longest increasing subsequence (LIS) datasets. Our findings highlight the importance of preventing intermediate layer representation collapse to enhance the reasoning capabilities of Transformers and show that Seq-VCR offers an effective solution without requiring explicit CoT supervision.
VFA: Vision Frequency Analysis of Foundation Models and Human
Sep 09, 2024



Machine learning models often struggle with distribution shifts in real-world scenarios, whereas humans exhibit robust adaptation. Models that better align with human perception may achieve higher out-of-distribution generalization. In this study, we investigate how various characteristics of large-scale computer vision models influence their alignment with human capabilities and robustness. Our findings indicate that increasing model and data size and incorporating rich semantic information and multiple modalities enhance models' alignment with human perception and their overall robustness. Our empirical analysis demonstrates a strong correlation between out-of-distribution accuracy and human alignment.
Unsupervised Concept Discovery Mitigates Spurious Correlations
Feb 20, 2024



Models prone to spurious correlations in training data often produce brittle predictions and introduce unintended biases. Addressing this challenge typically involves methods relying on prior knowledge and group annotation to remove spurious correlations, which may not be readily available in many applications. In this paper, we establish a novel connection between unsupervised object-centric learning and mitigation of spurious correlations. Instead of directly inferring sub-groups with varying correlations with labels, our approach focuses on discovering concepts: discrete ideas that are shared across input samples. Leveraging existing object-centric representation learning, we introduce CoBalT: a concept balancing technique that effectively mitigates spurious correlations without requiring human labeling of subgroups. Evaluation across the Waterbirds, CelebA and ImageNet-9 benchmark datasets for subpopulation shifts demonstrate superior or competitive performance compared state-of-the-art baselines, without the need for group annotation.
Amplifying Pathological Detection in EEG Signaling Pathways through Cross-Dataset Transfer Learning
Sep 19, 2023



Pathology diagnosis based on EEG signals and decoding brain activity holds immense importance in understanding neurological disorders. With the advancement of artificial intelligence methods and machine learning techniques, the potential for accurate data-driven diagnoses and effective treatments has grown significantly. However, applying machine learning algorithms to real-world datasets presents diverse challenges at multiple levels. The scarcity of labelled data, especially in low regime scenarios with limited availability of real patient cohorts due to high costs of recruitment, underscores the vital deployment of scaling and transfer learning techniques. In this study, we explore a real-world pathology classification task to highlight the effectiveness of data and model scaling and cross-dataset knowledge transfer. As such, we observe varying performance improvements through data scaling, indicating the need for careful evaluation and labelling. Additionally, we identify the challenges of possible negative transfer and emphasize the significance of some key components to overcome distribution shifts and potential spurious correlations and achieve positive transfer. We see improvement in the performance of the target model on the target (NMT) datasets by using the knowledge from the source dataset (TUAB) when a low amount of labelled data was available. Our findings indicate a small and generic model (e.g. ShallowNet) performs well on a single dataset, however, a larger model (e.g. TCN) performs better on transfer and learning from a larger and diverse dataset.
Scaling the Number of Tasks in Continual Learning
Jul 10, 2022
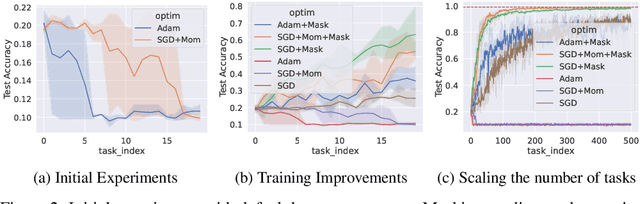

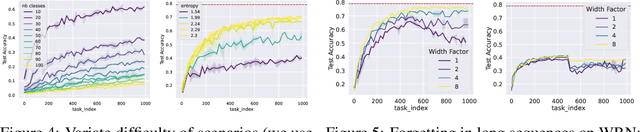
Standard gradient descent algorithms applied to sequences of tasks are known to produce catastrophic forgetting in deep neural networks. When trained on a new task in a sequence, the model updates its parameters on the current task, forgetting past knowledge. This article explores scenarios where we scale the number of tasks in a finite environment. Those scenarios are composed of a long sequence of tasks with reoccurring data. We show that in such setting, stochastic gradient descent can learn, progress, and converge to a solution that according to existing literature needs a continual learning algorithm. In other words, we show that the model performs knowledge retention and accumulation without specific memorization mechanisms. We propose a new experimentation framework, SCoLe (Scaling Continual Learning), to study the knowledge retention and accumulation of algorithms in potentially infinite sequences of tasks. To explore this setting, we performed a large number of experiments on sequences of 1,000 tasks to better understand this new family of settings. We also propose a slight modifications to the vanilla stochastic gradient descent to facilitate continual learning in this setting. The SCoLe framework represents a good simulation of practical training environments with reoccurring situations and allows the study of convergence behavior in long sequences. Our experiments show that previous results on short scenarios cannot always be extrapolated to longer scenarios.
Foundational Models for Continual Learning: An Empirical Study of Latent Replay
Apr 30, 2022
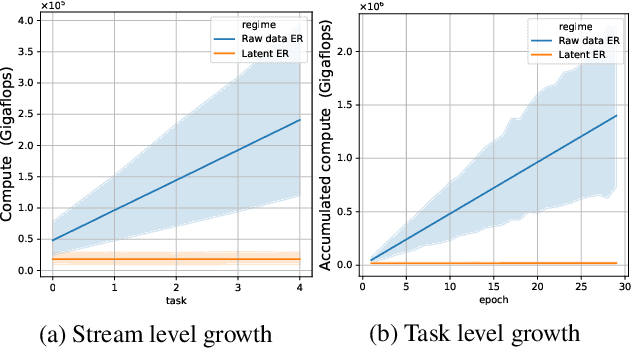
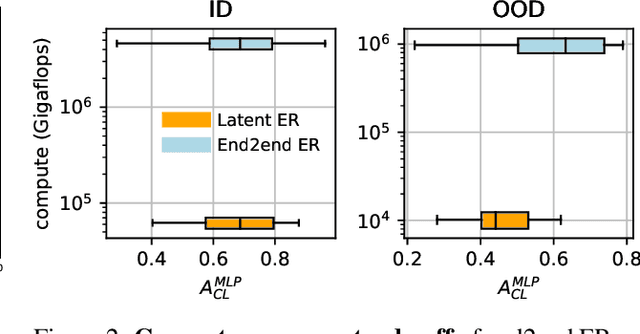
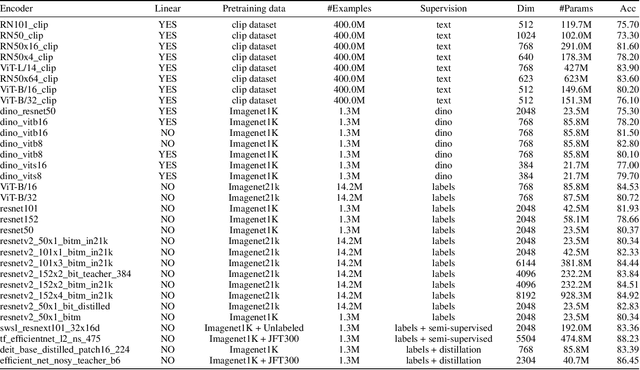
Rapid development of large-scale pre-training has resulted in foundation models that can act as effective feature extractors on a variety of downstream tasks and domains. Motivated by this, we study the efficacy of pre-trained vision models as a foundation for downstream continual learning (CL) scenarios. Our goal is twofold. First, we want to understand the compute-accuracy trade-off between CL in the raw-data space and in the latent space of pre-trained encoders. Second, we investigate how the characteristics of the encoder, the pre-training algorithm and data, as well as of the resulting latent space affect CL performance. For this, we compare the efficacy of various pre-trained models in large-scale benchmarking scenarios with a vanilla replay setting applied in the latent and in the raw-data space. Notably, this study shows how transfer, forgetting, task similarity and learning are dependent on the input data characteristics and not necessarily on the CL algorithms. First, we show that under some circumstances reasonable CL performance can readily be achieved with a non-parametric classifier at negligible compute. We then show how models pre-trained on broader data result in better performance for various replay sizes. We explain this with representational similarity and transfer properties of these representations. Finally, we show the effectiveness of self-supervised pre-training for downstream domains that are out-of-distribution as compared to the pre-training domain. We point out and validate several research directions that can further increase the efficacy of latent CL including representation ensembling. The diverse set of datasets used in this study can serve as a compute-efficient playground for further CL research. The codebase is available under https://github.com/oleksost/latent_CL.
AvaTr: One-Shot Speaker Extraction with Transformers
May 03, 2021

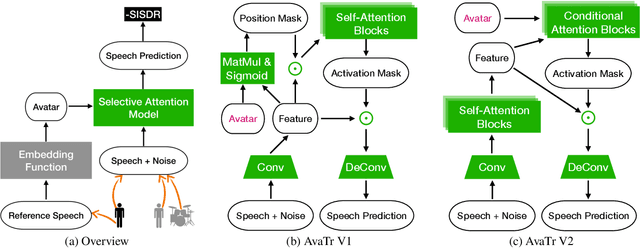
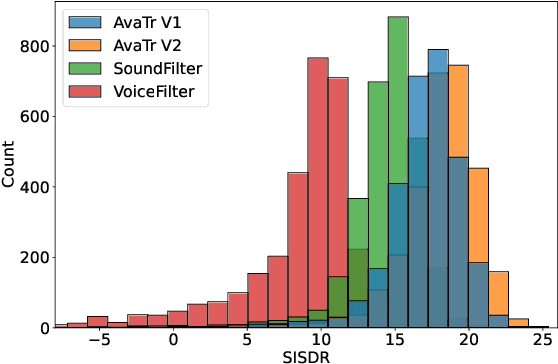
To extract the voice of a target speaker when mixed with a variety of other sounds, such as white and ambient noises or the voices of interfering speakers, we extend the Transformer network to attend the most relevant information with respect to the target speaker given the characteristics of his or her voices as a form of contextual information. The idea has a natural interpretation in terms of the selective attention theory. Specifically, we propose two models to incorporate the voice characteristics in Transformer based on different insights of where the feature selection should take place. Both models yield excellent performance, on par or better than published state-of-the-art models on the speaker extraction task, including separating speech of novel speakers not seen during training.