 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering parameter-efficient transfer learning by recognizing the kernel structure in self-attention
May 07, 2022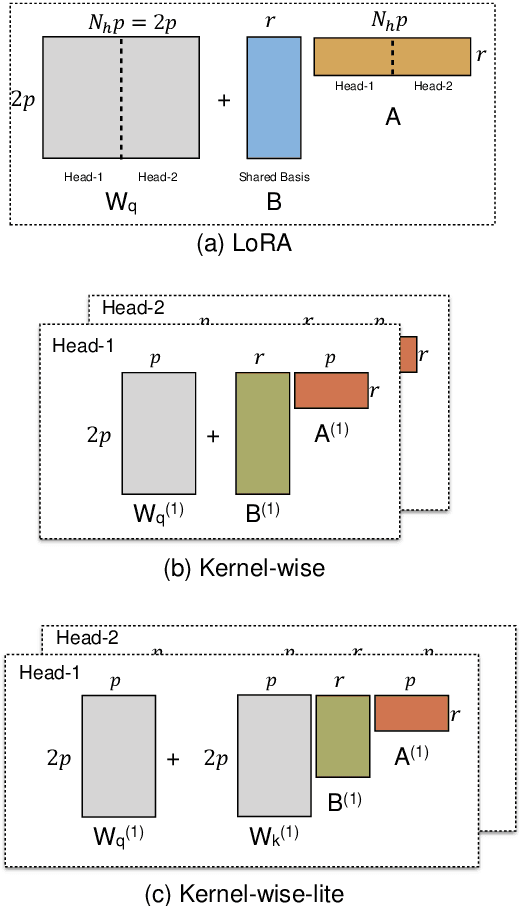
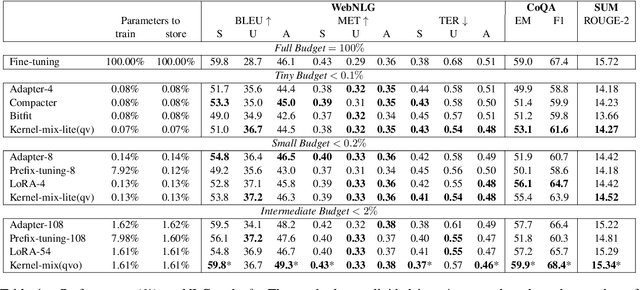
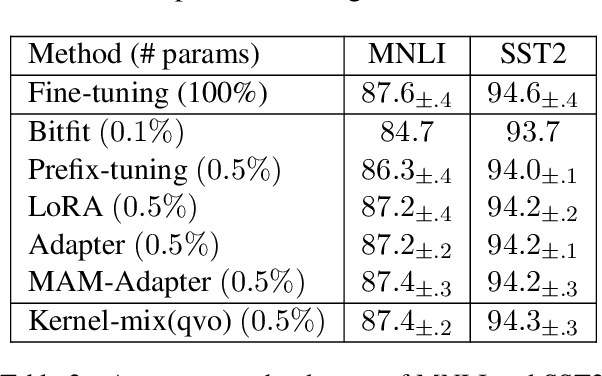
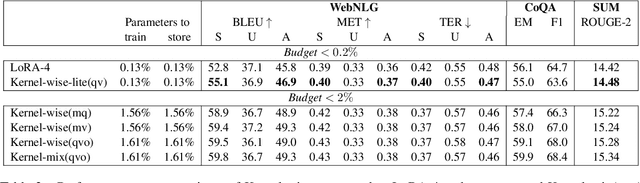
The massive amount of trainable parameters in the pre-trained language models (PLMs) makes them hard to be deployed to multiple downstream tasks. To address this issue, parameter-efficient transfer learning methods have been proposed to tune only a few parameters during fine-tuning while freezing the rest. This paper looks at existing methods along this line through the \textit{kernel lens}. Motivated by the connection between self-attention in transformer-based PLMs and kernel learning, we propose \textit{kernel-wise adapters}, namely \textit{Kernel-mix}, that utilize the kernel structure in self-attention to guide the assignment of the tunable parameters. These adapters use guidelines found in classical kernel learning and enable separate parameter tuning for each attention head. Our empirical results, over a diverse set of natural language generation and understanding tasks, show that our proposed adapters can attain or improve the strong performance of existing baselines.
Heterogeneous Graph Neural Networks using Self-supervised Reciprocally Contrastive Learning
Apr 30, 2022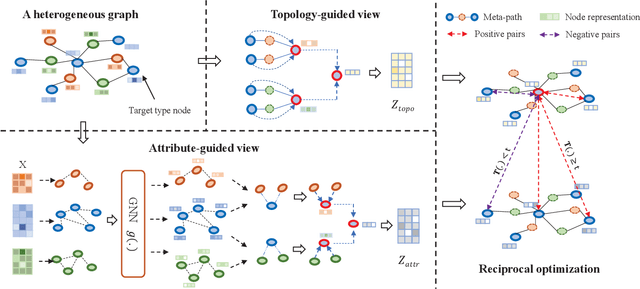
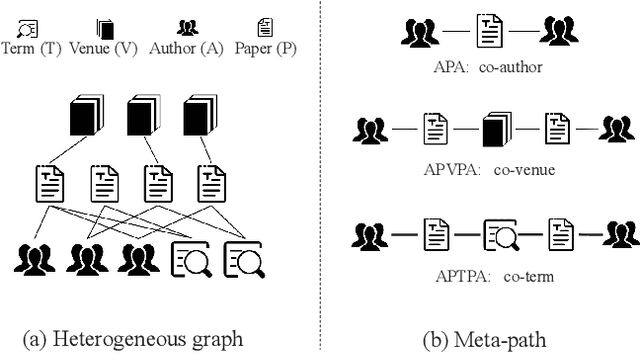
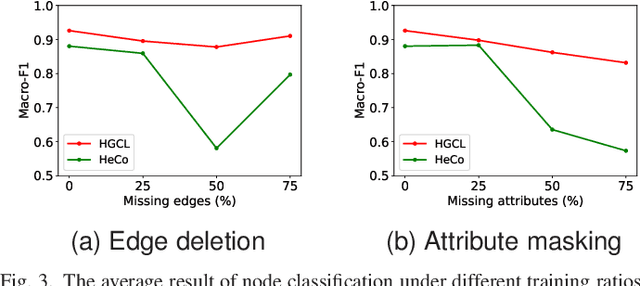
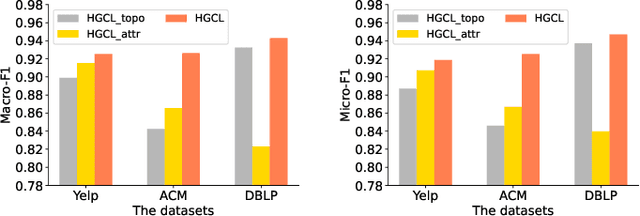
Heterogeneous graph neural network (HGNN) is a very popular technique for the modeling and analysis of heterogeneous graphs. Most existing HGNN-based approaches are supervised or semi-supervised learning methods requiring graphs to be annotated, which is costly and time-consuming. Self-supervised contrastive learning has been proposed to address the problem of requiring annotated data by mining intrinsic information hidden within the given data. However, the existing contrastive learning methods are inadequate for heterogeneous graphs because they construct contrastive views only based on data perturbation or pre-defined structural properties (e.g., meta-path) in graph data while ignore the noises that may exist in both node attributes and graph topologies. We develop for the first time a novel and robust heterogeneous graph contrastive learning approach, namely HGCL, which introduces two views on respective guidance of node attributes and graph topologies and integrates and enhances them by reciprocally contrastive mechanism to better model heterogeneous graphs. In this new approach, we adopt distinct but most suitable attribute and topology fusion mechanisms in the two views, which are conducive to mining relevant information in attributes and topologies separately. We further use both attribute similarity and topological correlation to construct high-quality contrastive samples. Extensive experiments on three large real-world heterogeneous graphs demonstrate the superiority and robustness of HGCL over state-of-the-art methods.
Towards Textual Out-of-Domain Detection without In-Domain Labels
Mar 22, 2022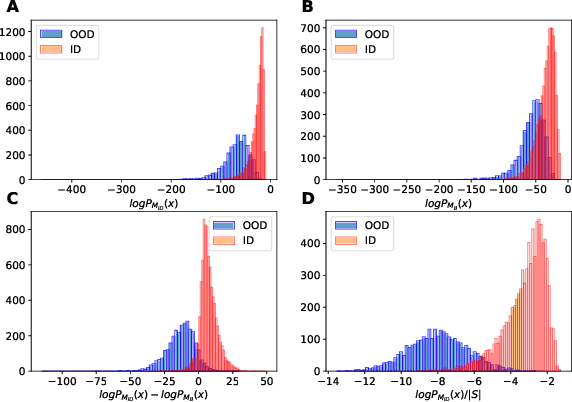
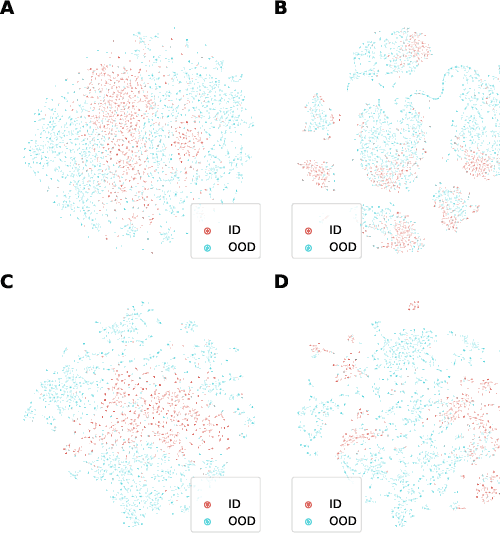
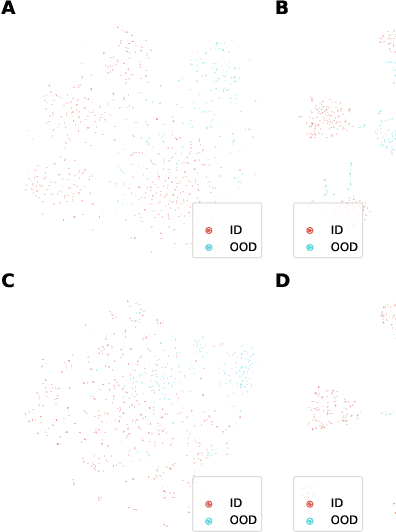
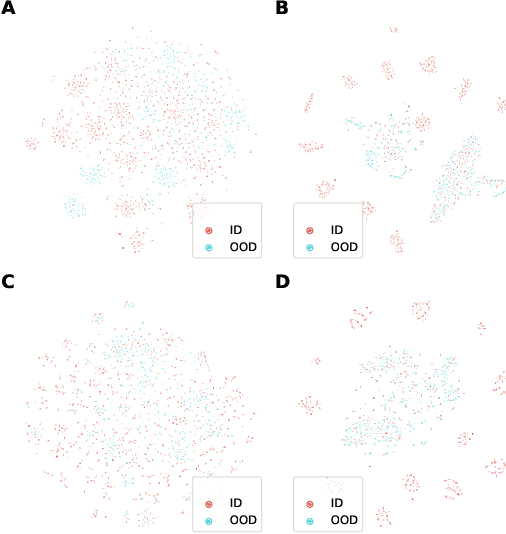
In many real-world settings, machine learning models need to identify user inputs that are out-of-domain (OOD) so as to avoid performing wrong actions. This work focuses on a challenging case of OOD detection, where no labels for in-domain data are accessible (e.g., no intent labels for the intent classification task). To this end, we first evaluate different language model based approaches that predict likelihood for a sequence of tokens. Furthermore, we propose a novel representation learning based method by combining unsupervised clustering and contrastive learning so that better data representations for OOD detection can be learned. Through extensive experiments, we demonstrate that this method can significantly outperform likelihood-based methods and can be even competitive to the state-of-the-art supervised approaches with label information.
TMS: A Temporal Multi-scale Backbone Design for Speaker Embedding
Mar 17, 2022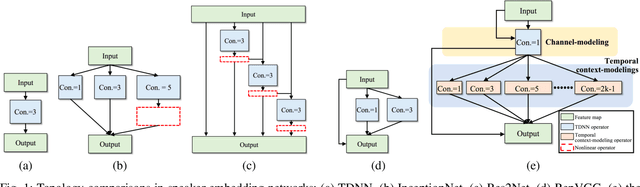
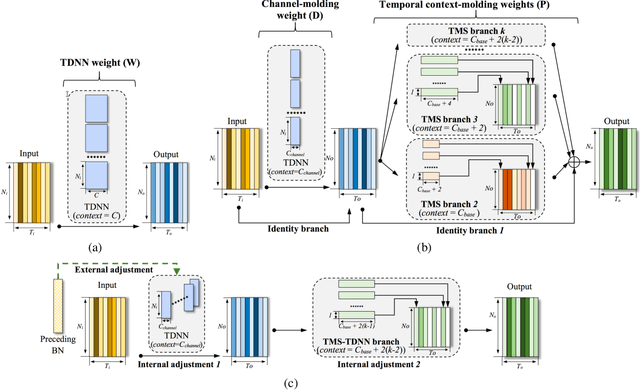
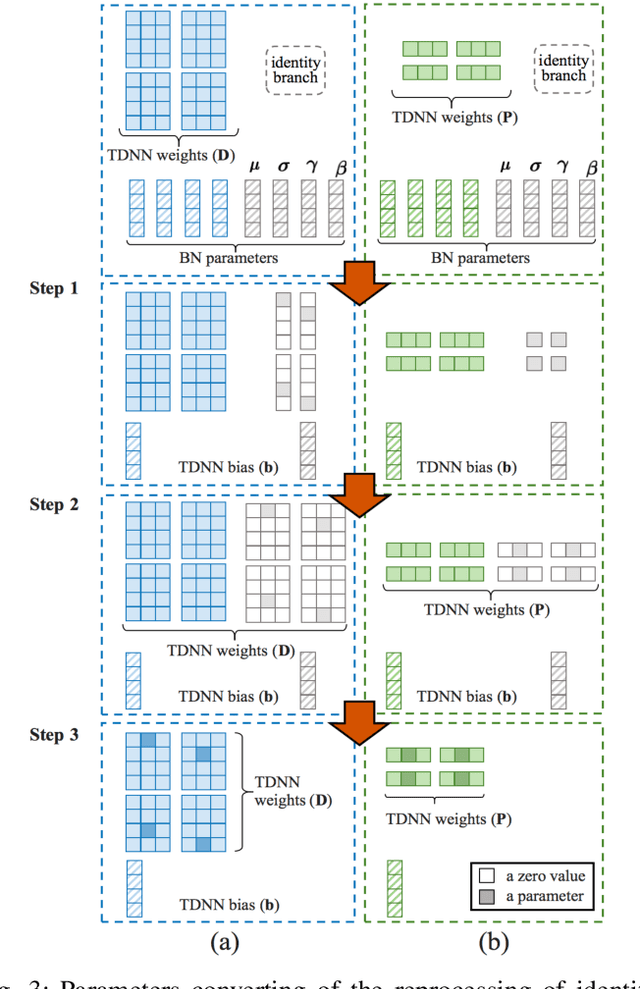
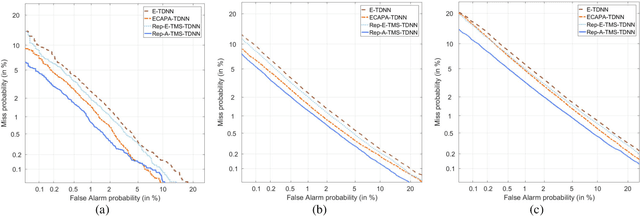
Speaker embedding is an important front-end module to explore discriminative speaker features for many speech applications where speaker information is needed. Current SOTA backbone networks for speaker embedding are designed to aggregate multi-scale features from an utterance with multi-branch network architectures for speaker representation. However, naively adding many branches of multi-scale features with the simple fully convolutional operation could not efficiently improve the performance due to the rapid increase of model parameters and computational complexity. Therefore, in the most current state-of-the-art network architectures, only a few branches corresponding to a limited number of temporal scales could be designed for speaker embeddings. To address this problem, in this paper, we propose an effective temporal multi-scale (TMS) model where multi-scale branches could be efficiently designed in a speaker embedding network almost without increasing computational costs. The new model is based on the conventional TDNN, where the network architecture is smartly separated into two modeling operators: a channel-modeling operator and a temporal multi-branch modeling operator. Adding temporal multi-scale in the temporal multi-branch operator needs only a little bit increase of the number of parameters, and thus save more computational budget for adding more branches with large temporal scales. Moreover, in the inference stage, we further developed a systemic re-parameterization method to convert the TMS-based model into a single-path-based topology in order to increase inference speed. We investigated the performance of the new TMS method for automatic speaker verification (ASV) on in-domain and out-of-domain conditions. Results show that the TMS-based model obtained a significant increase in the performance over the SOTA ASV models, meanwhile, had a faster inference speed.
Graph Neural Networks for Graphs with Heterophily: A Survey
Feb 14, 2022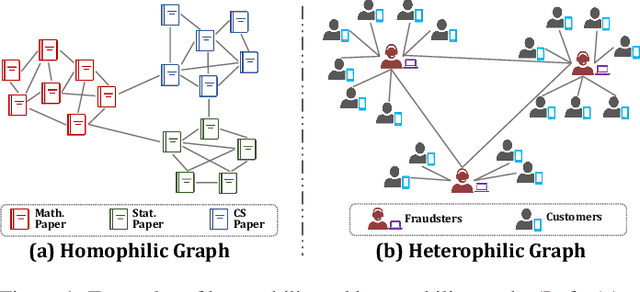
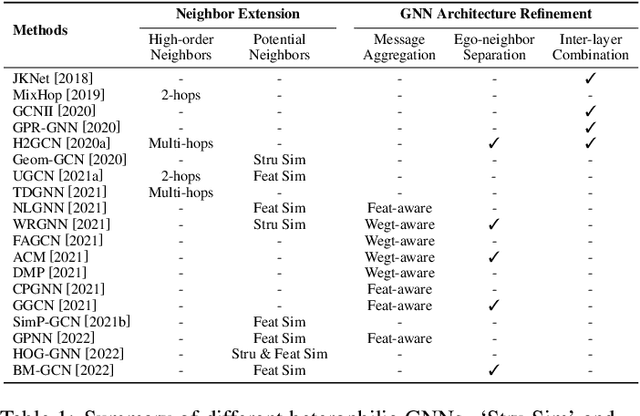
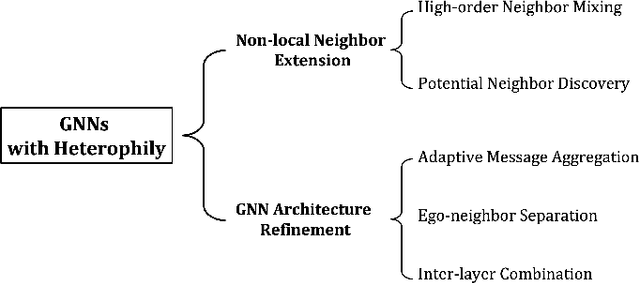
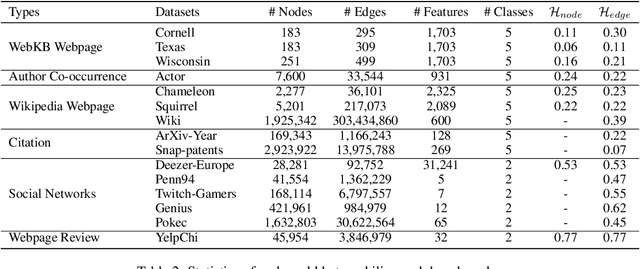
Recent years have witnessed fast developments of graph neural networks (GNNs) that have benefited myriads of graph analytic tasks and applications. In general, most GNNs depend on the homophily assumption that nodes belonging to the same class are more likely to be connected. However, as a ubiquitous graph property in numerous real-world scenarios, heterophily, i.e., nodes with different labels tend to be linked, significantly limits the performance of tailor-made homophilic GNNs. Hence, \textit{GNNs for heterophilic graphs} are gaining increasing attention in this community. To the best of our knowledge, in this paper, we provide a comprehensive review of GNNs for heterophilic graphs for the first time. Specifically, we propose a systematic taxonomy that essentially governs existing heterophilic GNN models, along with a general summary and detailed analysis. Furthermore, we summarize the mainstream heterophilic graph benchmarks to facilitate robust and fair evaluations. In the end, we point out the potential directions to advance and stimulate future research and applications on heterophilic graphs.
Powerful Graph Convolutioal Networks with Adaptive Propagation Mechanism for Homophily and Heterophily
Dec 27, 2021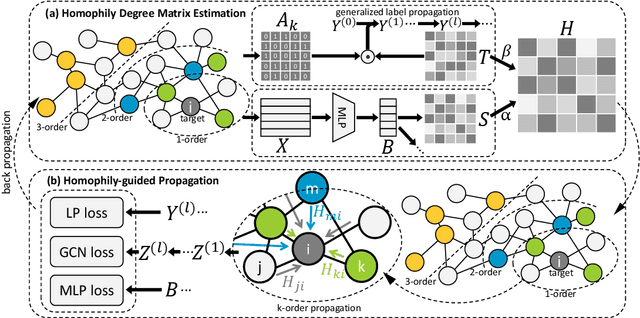
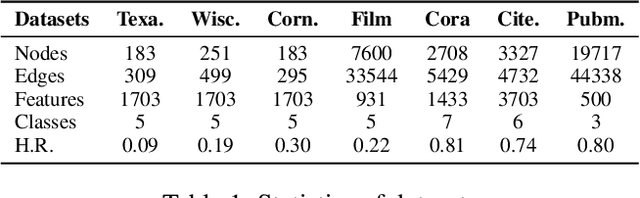
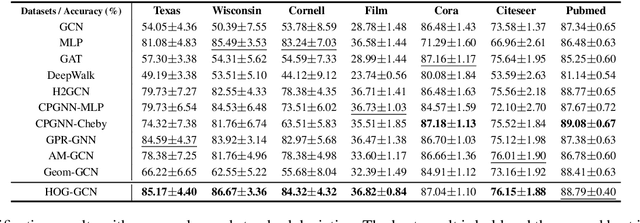

Graph Convolutional Networks (GCNs) have been widely applied in various fields due to their significant power on processing graph-structured data. Typical GCN and its variants work under a homophily assumption (i.e., nodes with same class are prone to connect to each other), while ignoring the heterophily which exists in many real-world networks (i.e., nodes with different classes tend to form edges). Existing methods deal with heterophily by mainly aggregating higher-order neighborhoods or combing the immediate representations, which leads to noise and irrelevant information in the result. But these methods did not change the propagation mechanism which works under homophily assumption (that is a fundamental part of GCNs). This makes it difficult to distinguish the representation of nodes from different classes. To address this problem, in this paper we design a novel propagation mechanism, which can automatically change the propagation and aggregation process according to homophily or heterophily between node pairs. To adaptively learn the propagation process, we introduce two measurements of homophily degree between node pairs, which is learned based on topological and attribute information, respectively. Then we incorporate the learnable homophily degree into the graph convolution framework, which is trained in an end-to-end schema, enabling it to go beyond the assumption of homophily. More importantly, we theoretically prove that our model can constrain the similarity of representations between nodes according to their homophily degree. Experiments on seven real-world datasets demonstrate that this new approach outperforms the state-of-the-art methods under heterophily or low homophily, and gains competitive performance under homophily.
Sketching as a Tool for Understanding and Accelerating Self-attention for Long Sequences
Dec 10, 2021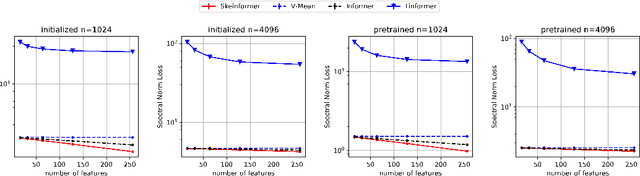
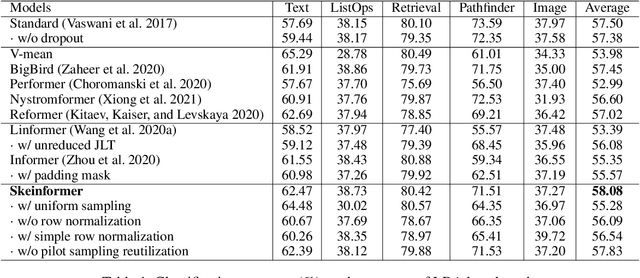
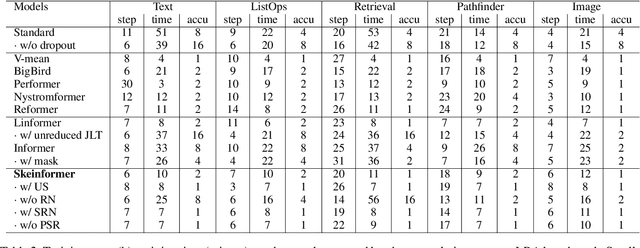

Transformer-based models are not efficient in processing long sequences due to the quadratic space and time complexity of the self-attention modules. To address this limitation, Linformer and Informer are proposed to reduce the quadratic complexity to linear (modulo logarithmic factors) via low-dimensional projection and row selection respectively. These two models are intrinsically connected, and to understand their connection, we introduce a theoretical framework of matrix sketching. Based on the theoretical analysis, we propose Skeinformer to accelerate self-attention and further improve the accuracy of matrix approximation to self-attention with three carefully designed components: column sampling, adaptive row normalization and pilot sampling reutilization. Experiments on the Long Range Arena (LRA) benchmark demonstrate that our methods outperform alternatives with a consistently smaller time/space footprint.
Explainable Deep Learning in Healthcare: A Methodological Survey from an Attribution View
Dec 05, 2021

The increasing availability of large collections of electronic health record (EHR) data and unprecedented technical advances in deep learning (DL) have sparked a surge of research interest in developing DL based clinical decision support systems for diagnosis, prognosis, and treatment. Despite the recognition of the value of deep learning in healthcare, impediments to further adoption in real healthcare settings remain due to the black-box nature of DL. Therefore, there is an emerging need for interpretable DL, which allows end users to evaluate the model decision making to know whether to accept or reject predictions and recommendations before an action is taken. In this review, we focus on the interpretability of the DL models in healthcare. We start by introducing the methods for interpretability in depth and comprehensively as a methodological reference for future researchers or clinical practitioners in this field. Besides the methods' details, we also include a discussion of advantages and disadvantages of these methods and which scenarios each of them is suitable for, so that interested readers can know how to compare and choose among them for use. Moreover, we discuss how these methods, originally developed for solving general-domain problems, have been adapted and applied to healthcare problems and how they can help physicians better understand these data-driven technologies. Overall, we hope this survey can help researchers and practitioners in both artificial intelligence (AI) and clinical fields understand what methods we have for enhancing the interpretability of their DL models and choose the optimal one accordingly.
Convolutional Neural Network Dynamics: A Graph Perspective
Nov 09, 2021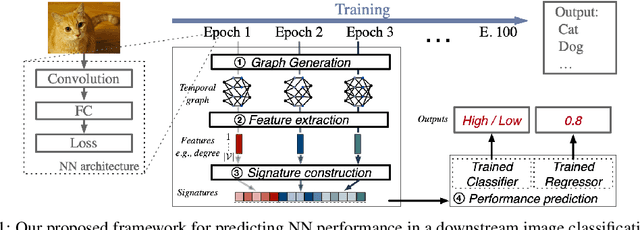

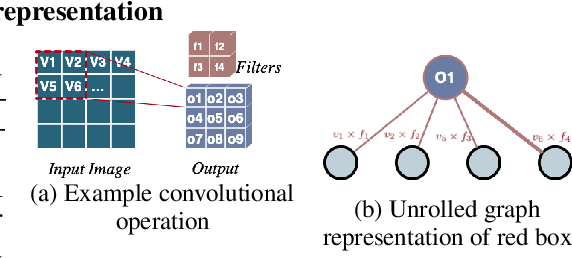
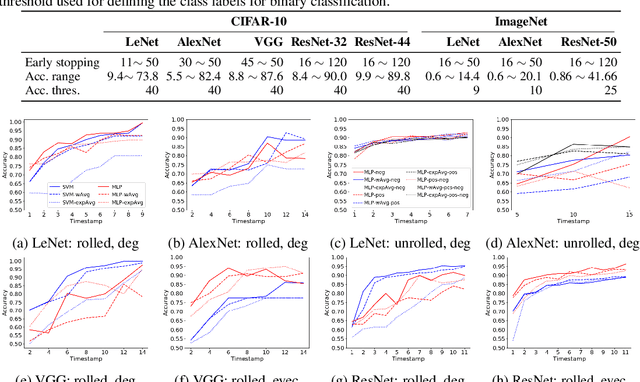
The success of neural networks (NNs) in a wide range of applications has led to increased interest in understanding the underlying learning dynamics of these models. In this paper, we go beyond mere descriptions of the learning dynamics by taking a graph perspective and investigating the relationship between the graph structure of NNs and their performance. Specifically, we propose (1) representing the neural network learning process as a time-evolving graph (i.e., a series of static graph snapshots over epochs), (2) capturing the structural changes of the NN during the training phase in a simple temporal summary, and (3) leveraging the structural summary to predict the accuracy of the underlying NN in a classification or regression task. For the dynamic graph representation of NNs, we explore structural representations for fully-connected and convolutional layers, which are key components of powerful NN models. Our analysis shows that a simple summary of graph statistics, such as weighted degree and eigenvector centrality, over just a few epochs can be used to accurately predict the performance of NNs. For example, a weighted degree-based summary of the time-evolving graph that is constructed based on 5 training epochs of the LeNet architecture achieves classification accuracy of over 93%. Our findings are consistent for different NN architectures, including LeNet, VGG, AlexNet and ResNet.
Deep Transfer Learning for Multi-source Entity Linkage via Domain Adaptation
Oct 27, 2021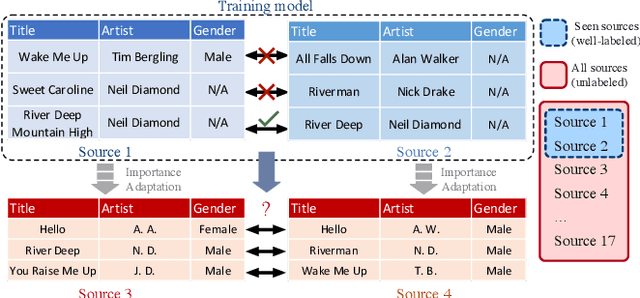

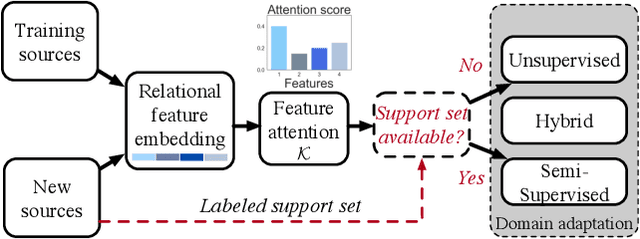
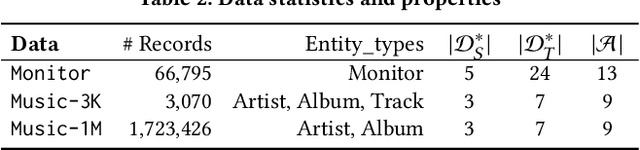
Multi-source entity linkage focuses on integrating knowledge from multiple sources by linking the records that represent the same real world entity. This is critical in high-impact applications such as data cleaning and user stitching. The state-of-the-art entity linkage pipelines mainly depend on supervised learning that requires abundant amounts of training data. However, collecting well-labeled training data becomes expensive when the data from many sources arrives incrementally over time. Moreover, the trained models can easily overfit to specific data sources, and thus fail to generalize to new sources due to significant differences in data and label distributions. To address these challenges, we present AdaMEL, a deep transfer learning framework that learns generic high-level knowledge to perform multi-source entity linkage. AdaMEL models the attribute importance that is used to match entities through an attribute-level self-attention mechanism, and leverages the massive unlabeled data from new data sources through domain adaptation to make it generic and data-source agnostic. In addition, AdaMEL is capable of incorporating an additional set of labeled data to more accurately integrate data sources with different attribute importance. Extensive experiments show that our framework achieves state-of-the-art results with 8.21% improvement on average over methods based on supervised learning. Besides, it is more stable in handling different sets of data sources in less runtime.