 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniCellTOSG: The First Cell Text-Omic Signaling Graphs Dataset for Joint LLM and GNN Modeling
Apr 02, 2025Complex cell signaling systems -- governed by varying protein abundances and interactions -- generate diverse cell types across organs. These systems evolve under influences such as age, sex, diet, environmental exposures, and diseases, making them challenging to decode given the involvement of tens of thousands of genes and proteins. Recently, hundreds of millions of single-cell omics data have provided a robust foundation for understanding these signaling networks within various cell subpopulations and conditions. Inspired by the success of large foundation models (for example, large language models and large vision models) pre-trained on massive datasets, we introduce OmniCellTOSG, the first dataset of cell text-omic signaling graphs (TOSGs). Each TOSG represents the signaling network of an individual or meta-cell and is labeled with information such as organ, disease, sex, age, and cell subtype. OmniCellTOSG offers two key contributions. First, it introduces a novel graph model that integrates human-readable annotations -- such as biological functions, cellular locations, signaling pathways, related diseases, and drugs -- with quantitative gene and protein abundance data, enabling graph reasoning to decode cell signaling. This approach calls for new joint models combining large language models and graph neural networks. Second, the dataset is built from single-cell RNA sequencing data of approximately 120 million cells from diverse tissues and conditions (healthy and diseased) and is fully compatible with PyTorch. This facilitates the development of innovative cell signaling models that could transform research in life sciences, healthcare, and precision medicine. The OmniCellTOSG dataset is continuously expanding and will be updated regularly. The dataset and code are available at https://github.com/FuhaiLiAiLab/OmniCellTOSG.
KoGNER: A Novel Framework for Knowledge Graph Distillation on Biomedical Named Entity Recognition
Mar 19, 2025Named Entity Recognition (NER) is a fundamental task in Natural Language Processing (NLP) that plays a crucial role in information extraction, question answering, and knowledge-based systems. Traditional deep learning-based NER models often struggle with domain-specific generalization and suffer from data sparsity issues. In this work, we introduce Knowledge Graph distilled for Named Entity Recognition (KoGNER), a novel approach that integrates Knowledge Graph (KG) distillation into NER models to enhance entity recognition performance. Our framework leverages structured knowledge representations from KGs to enrich contextual embeddings, thereby improving entity classification and reducing ambiguity in entity detection. KoGNER employs a two-step process: (1) Knowledge Distillation, where external knowledge sources are distilled into a lightweight representation for seamless integration with NER models, and (2) Entity-Aware Augmentation, which integrates contextual embeddings that have been enriched with knowledge graph information directly into GNN, thereby improving the model's ability to understand and represent entity relationships. Experimental results on benchmark datasets demonstrate that KoGNER achieves state-of-the-art performance, outperforming finetuned NER models and LLMs by a significant margin. These findings suggest that leveraging knowledge graphs as auxiliary information can significantly improve NER accuracy, making KoGNER a promising direction for future research in knowledge-aware NLP.
GraphSeqLM: A Unified Graph Language Framework for Omic Graph Learning
Dec 20, 2024

The integration of multi-omic data is pivotal for understanding complex diseases, but its high dimensionality and noise present significant challenges. Graph Neural Networks (GNNs) offer a robust framework for analyzing large-scale signaling pathways and protein-protein interaction networks, yet they face limitations in expressivity when capturing intricate biological relationships. To address this, we propose Graph Sequence Language Model (GraphSeqLM), a framework that enhances GNNs with biological sequence embeddings generated by Large Language Models (LLMs). These embeddings encode structural and biological properties of DNA, RNA, and proteins, augmenting GNNs with enriched features for analyzing sample-specific multi-omic data. By integrating topological, sequence-derived, and biological information, GraphSeqLM demonstrates superior predictive accuracy and outperforms existing methods, paving the way for more effective multi-omic data integration in precision medicine.
Discriminator-Guided Model-Based Offline Imitation Learning
Jul 05, 2022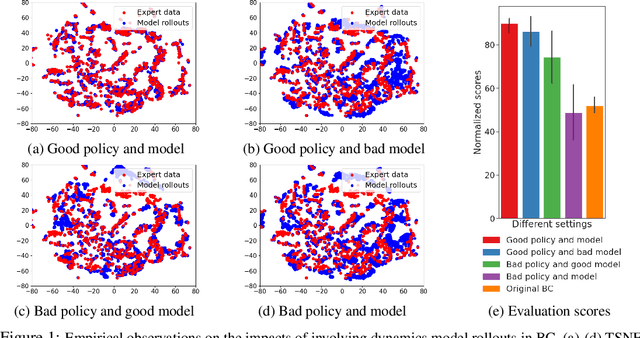
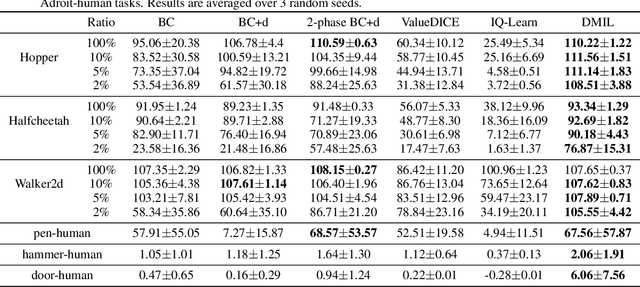
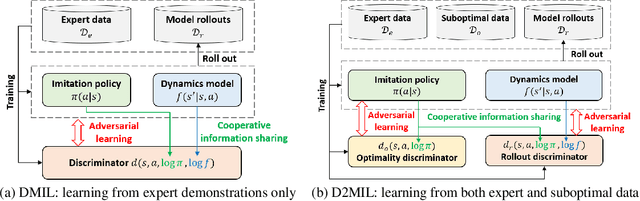
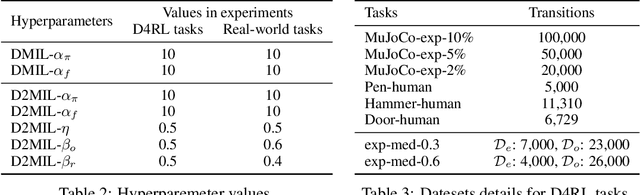
Offline imitation learning (IL) is a powerful method to solve decision-making problems from expert demonstrations without reward labels. Existing offline IL methods suffer from severe performance degeneration under limited expert data due to covariate shift. Including a learned dynamics model can potentially improve the state-action space coverage of expert data, however, it also faces challenging issues like model approximation/generalization errors and suboptimality of rollout data. In this paper, we propose the Discriminator-guided Model-based offline Imitation Learning (DMIL) framework, which introduces a discriminator to simultaneously distinguish the dynamics correctness and suboptimality of model rollout data against real expert demonstrations. DMIL adopts a novel cooperative-yet-adversarial learning strategy, which uses the discriminator to guide and couple the learning process of the policy and dynamics model, resulting in improved model performance and robustness. Our framework can also be extended to the case when demonstrations contain a large proportion of suboptimal data. Experimental results show that DMIL and its extension achieve superior performance and robustness compared to state-of-the-art offline IL methods under small datasets.
Interpretable Drug Synergy Prediction with Graph Neural Networks for Human-AI Collaboration in Healthcare
May 14, 2021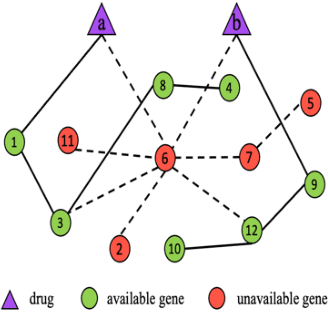
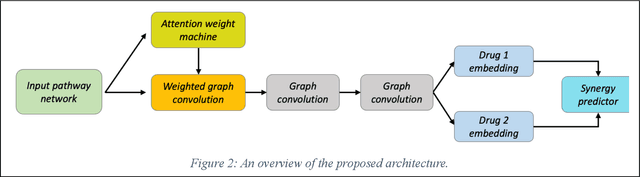
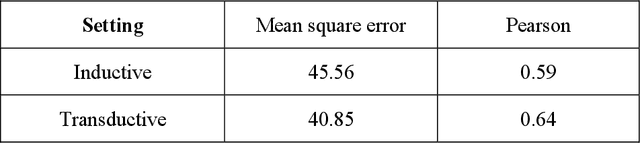
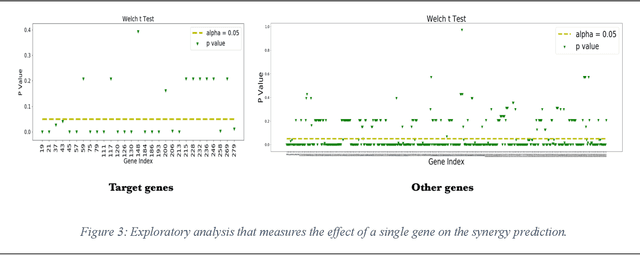
We investigate molecular mechanisms of resistant or sensitive response of cancer drug combination therapies in an inductive and interpretable manner. Though deep learning algorithms are widely used in the drug synergy prediction problem, it is still an open problem to formulate the prediction model with biological meaning to investigate the mysterious mechanisms of synergy (MoS) for the human-AI collaboration in healthcare systems. To address the challenges, we propose a deep graph neural network, IDSP (Interpretable Deep Signaling Pathways), to incorporate the gene-gene as well as gene-drug regulatory relationships in synergic drug combination predictions. IDSP automatically learns weights of edges based on the gene and drug node relations, i.e., signaling interactions, by a multi-layer perceptron (MLP) and aggregates information in an inductive manner. The proposed architecture generates interpretable drug synergy prediction by detecting important signaling interactions, and can be implemented when the underlying molecular mechanism encounters unseen genes or signaling pathways. We test IDWSP on signaling networks formulated by genes from 46 core cancer signaling pathways and drug combinations from NCI ALMANAC drug combination screening data. The experimental results demonstrated that 1) IDSP can learn from the underlying molecular mechanism to make prediction without additional drug chemical information while achieving highly comparable performance with current state-of-art methods; 2) IDSP show superior generality and flexibility to implement the synergy prediction task on both transductive tasks and inductive tasks. 3) IDSP can generate interpretable results by detecting different salient signaling patterns (i.e. MoS) for different cell lines.
Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards
Aug 06, 2020
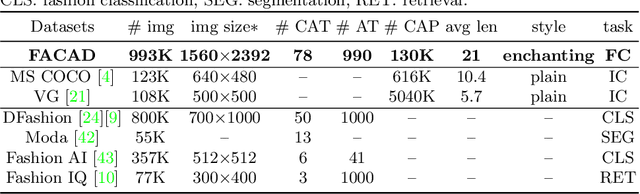
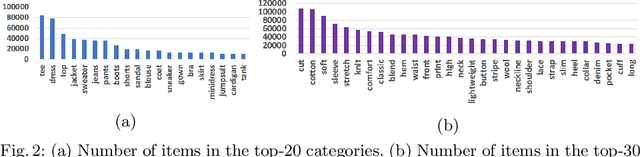
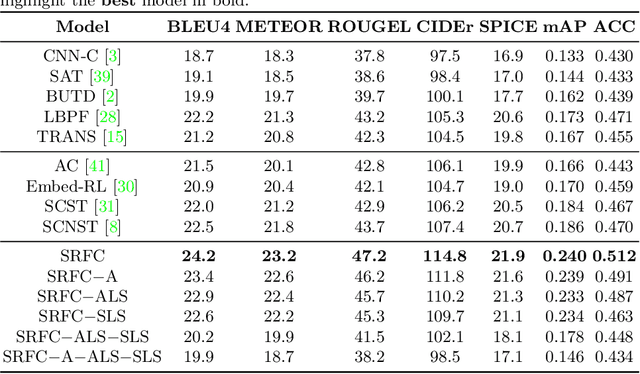
Generating accurate descriptions for online fashion items is important not only for enhancing customers' shopping experiences, but also for the increase of online sales. Besides the need of correctly presenting the attributes of items, the expressions in an enchanting style could better attract customer interests. The goal of this work is to develop a novel learning framework for accurate and expressive fashion captioning. Different from popular work on image captioning, it is hard to identify and describe the rich attributes of fashion items. We seed the description of an item by first identifying its attributes, and introduce attribute-level semantic (ALS) reward and sentence-level semantic (SLS) reward as metrics to improve the quality of text descriptions. We further integrate the training of our model with maximum likelihood estimation (MLE), attribute embedding, and Reinforcement Learning (RL). To facilitate the learning, we build a new FAshion CAptioning Dataset (FACAD), which contains 993K images and 130K corresponding enchanting and diverse descriptions. Experiments on FACAD demonstrate the effectiveness of our model.
Learning Color Compatibility in Fashion Outfits
Jul 05, 2020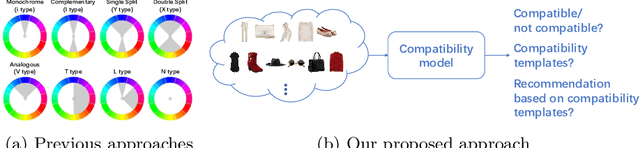
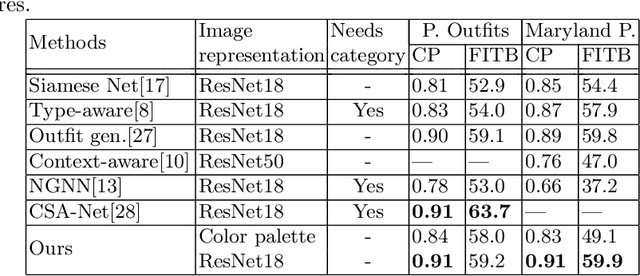
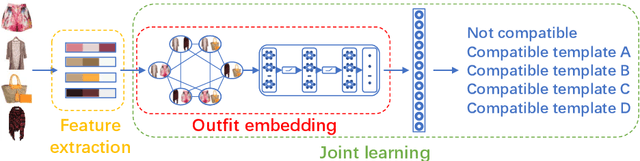
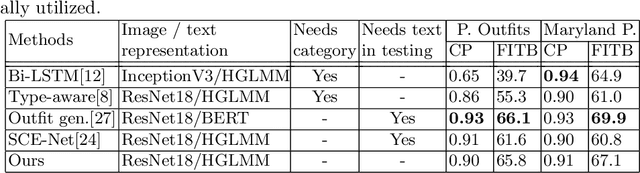
Color compatibility is important for evaluating the compatibility of a fashion outfit, yet it was neglected in previous studies. We bring this important problem to researchers' attention and present a compatibility learning framework as solution to various fashion tasks. The framework consists of a novel way to model outfit compatibility and an innovative learning scheme. Specifically, we model the outfits as graphs and propose a novel graph construction to better utilize the power of graph neural networks. Then we utilize both ground-truth labels and pseudo labels to train the compatibility model in a weakly-supervised manner.Extensive experimental results verify the importance of color compatibility alone with the effectiveness of our framework. With color information alone, our model's performance is already comparable to previous methods that use deep image features. Our full model combining the aforementioned contributions set the new state-of-the-art in fashion compatibility prediction.
Deep Kinship Verification via Appearance-shape Joint Prediction and Adaptation-based Approach
May 15, 2019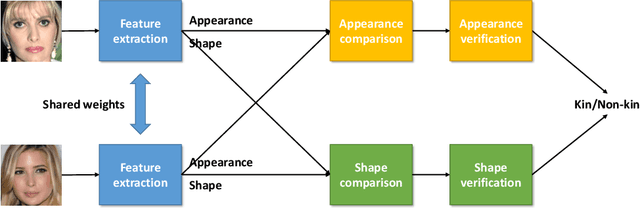
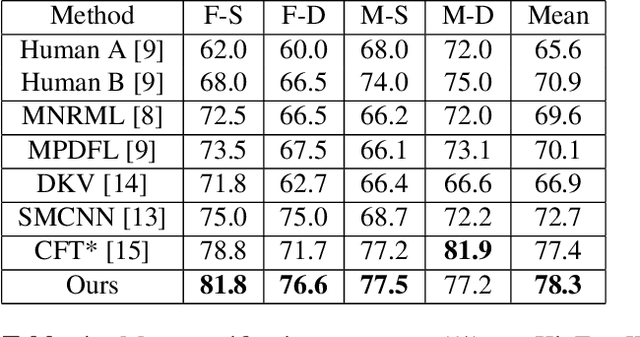
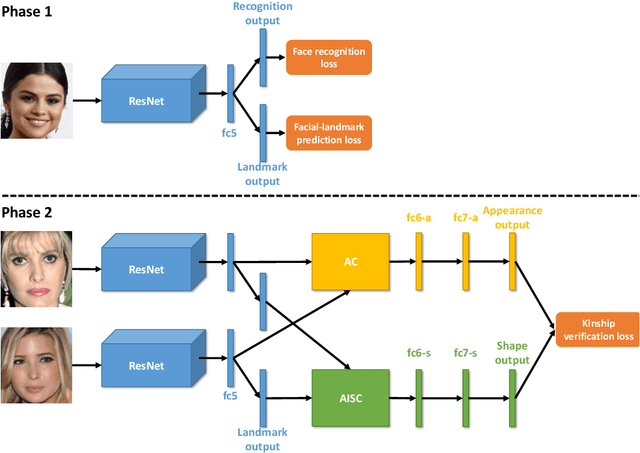
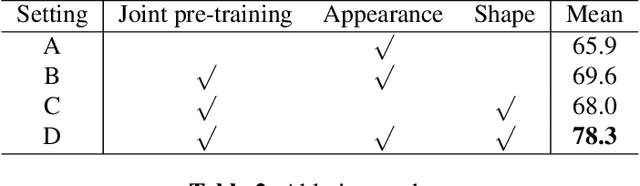
Kinship verification aims to identify the kin relation between two given face images. It is a very challenging problem due to the lack of training data and facial similarity variations between kinship pairs. In this work, we build a novel appearance and shape based deep learning pipeline. First we adopt the knowledge learned from general face recognition network to learn general facial features. Afterwards, we learn kinship oriented appearance and shape features from kinship pairs and combine them for the final prediction. We have evaluated the model performance on a widely used popular benchmark and demonstrated the superiority over the state-of-the-art.
Accelerating Proposal Generation Network for \\Fast Face Detection on Mobile Devices
Apr 27, 2019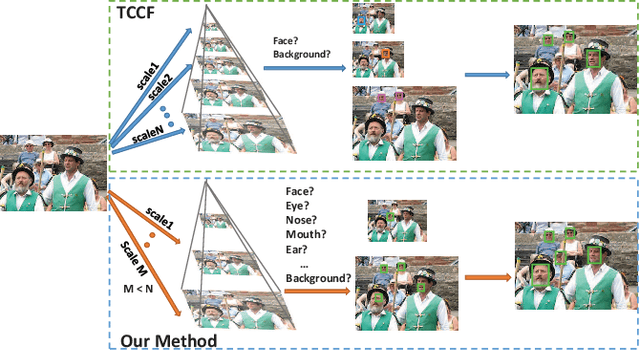

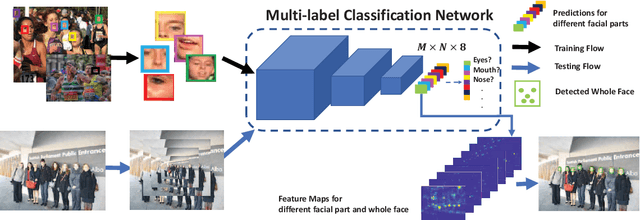
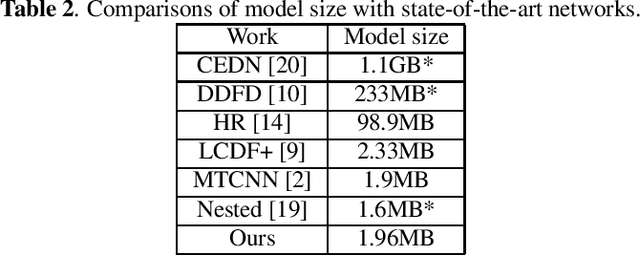
Face detection is a widely studied problem over the past few decades. Recently, significant improvements have been achieved via the deep neural network, however, it is still challenging to directly apply these techniques to mobile devices for its limited computational power and memory. In this work, we present a proposal generation acceleration framework for real-time face detection. More specifically, we adopt a popular cascaded convolutional neural network (CNN) as the basis, then apply our acceleration approach on the basic framework to speed up the model inference time. We are motivated by the observation that the computation bottleneck of this framework arises from the proposal generation stage, where each level of the dense image pyramid has to go through the network. In this work, we reduce the number of image pyramid levels by utilizing both global and local facial characteristics (i.e., global face and facial parts). Experimental results on public benchmarks WIDER-face and FDDB demonstrate the satisfactory performance and faster speed compared to the state-of-the-arts. %the comparable accuracy to state-of-the-arts with faster speed.
Class-incremental Learning via Deep Model Consolidation
Mar 28, 2019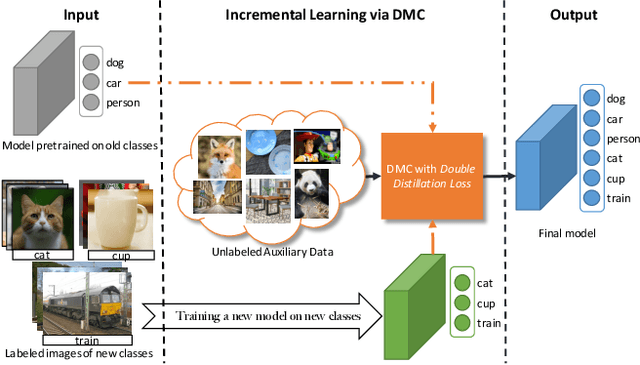
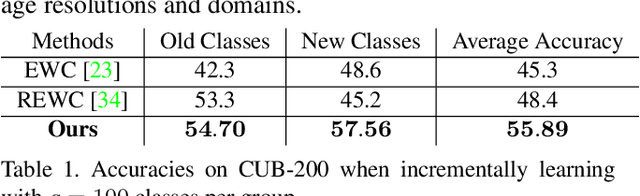
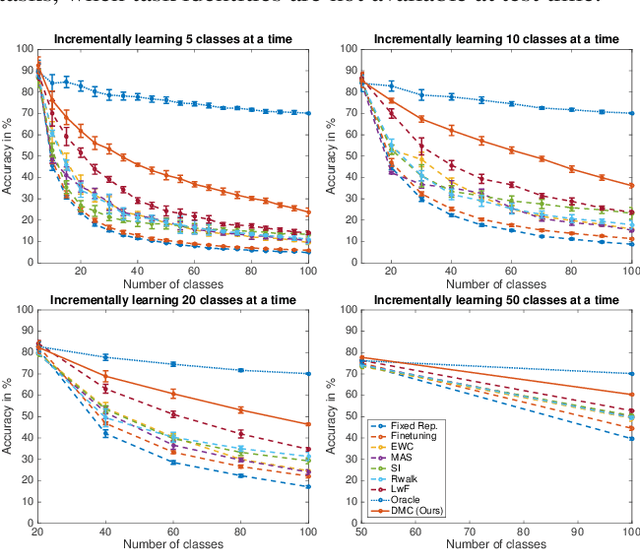
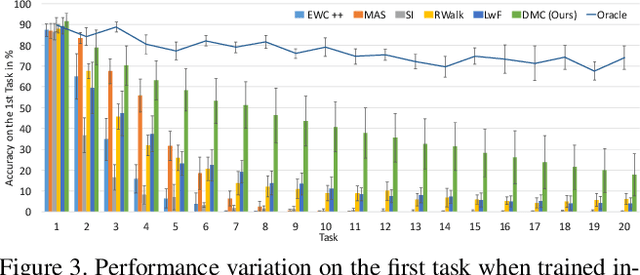
Deep neural networks (DNNs) often suffer from "catastrophic forgetting" during incremental learning (IL) --- an abrupt degradation of performance on the original set of classes when the training objective is adapted to a newly added set of classes. Existing IL approaches tend to produce a model that is biased towards either the old classes or new classes, unless with the help of exemplars of the old data. To address this issue, we propose a class-incremental learning paradigm called Deep Model Consolidation (DMC), which works well even when the original training data is not available. The idea is to first train a separate model only for the new classes, and then combine the two individual models trained on data of two distinct set of classes (old classes and new classes) via a novel dual distillation training objective. The two existing models are consolidated by exploiting publicly available unlabeled auxiliary data. This overcomes the potential difficulties due to unavailability of original training data. Compared to the state-of-the-art techniques, DMC demonstrates significantly better performance in CIFAR-100 image classification and PASCAL VOC 2007 object detection benchmarks in the single-headed IL setting.