 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Vocoder is All You Need for Speech Super-resolution
Mar 28, 2022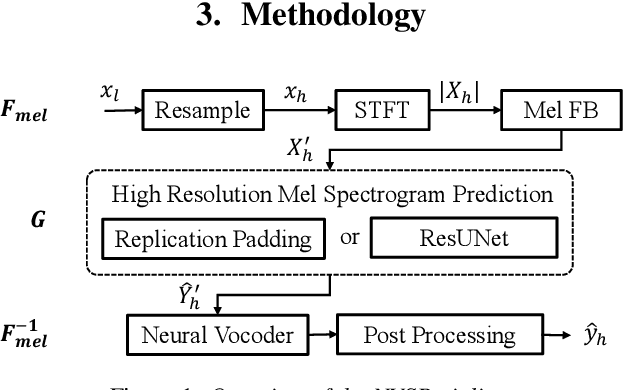

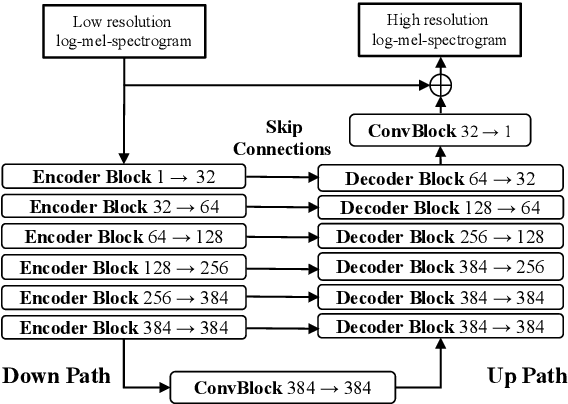

Speech super-resolution (SR) is a task to increase speech sampling rate by generating high-frequency components. Existing speech SR methods are trained in constrained experimental settings, such as a fixed upsampling ratio. These strong constraints can potentially lead to poor generalization ability in mismatched real-world cases. In this paper, we propose a neural vocoder based speech super-resolution method (NVSR) that can handle a variety of input resolution and upsampling ratios. NVSR consists of a mel-bandwidth extension module, a neural vocoder module, and a post-processing module. Our proposed system achieves state-of-the-art results on the VCTK multi-speaker benchmark. On 44.1 kHz target resolution, NVSR outperforms WSRGlow and Nu-wave by 8% and 37% respectively on log spectral distance and achieves a significantly better perceptual quality. We also demonstrate that prior knowledge in the pre-trained vocoder is crucial for speech SR by performing mel-bandwidth extension with a simple replication-padding method. Samples can be found in https://haoheliu.github.io/nvsr.
A Conformer Based Acoustic Model for Robust Automatic Speech Recognition
Mar 20, 2022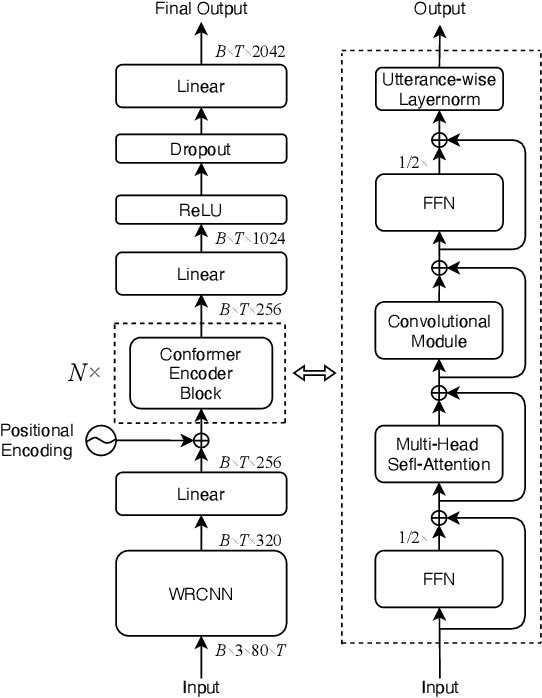
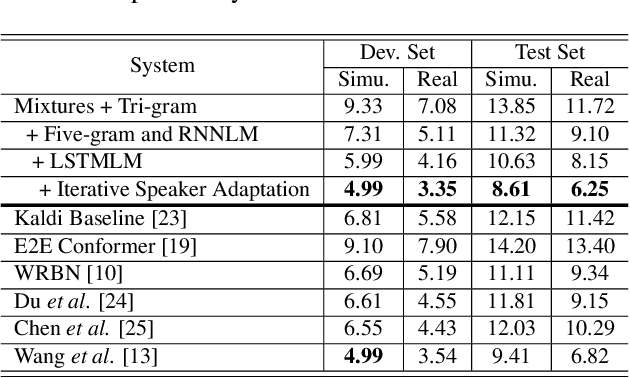
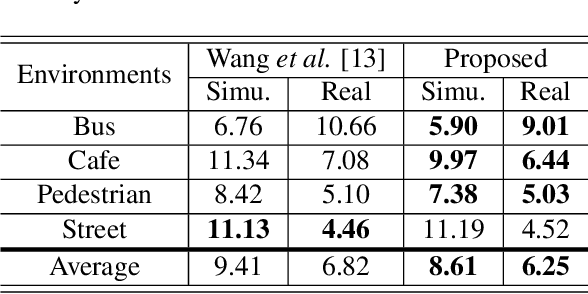
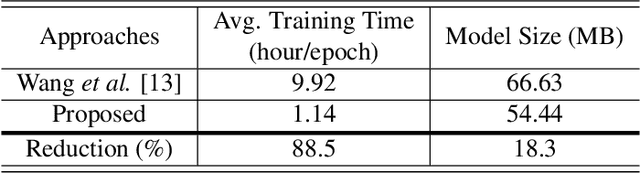
This study addresses robust automatic speech recognition (ASR) by introducing a Conformer-based acoustic model. The proposed model builds on a state-of-the-art recognition system using a bi-directional long short-term memory (BLSTM) model with utterance-wise dropout and iterative speaker adaptation, but employs a Conformer encoder instead of the BLSTM network. The Conformer encoder uses a convolution-augmented attention mechanism for acoustic modeling. The proposed system is evaluated on the monaural ASR task of the CHiME-4 corpus. Coupled with utterance-wise normalization and speaker adaptation, our model achieves $6.25\%$ word error rate, which outperforms the previous best system by $8.4\%$ relatively. In addition, the proposed Conformer-based model is $18.3\%$ smaller in model size and reduces total training time by $79.6\%$.
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022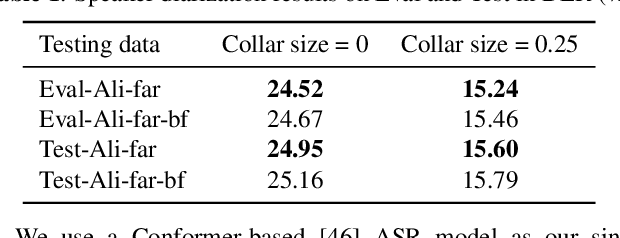
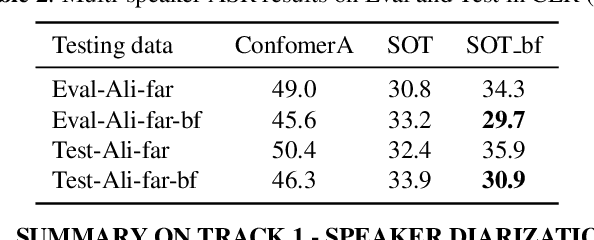
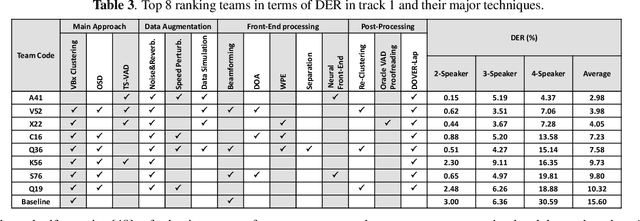
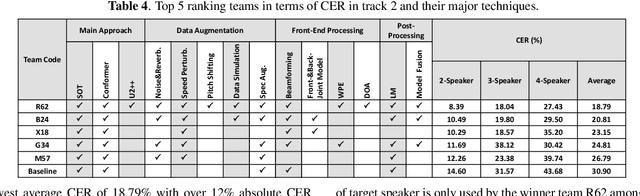
The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
Improving Noise Robustness of Contrastive Speech Representation Learning with Speech Reconstruction
Oct 28, 2021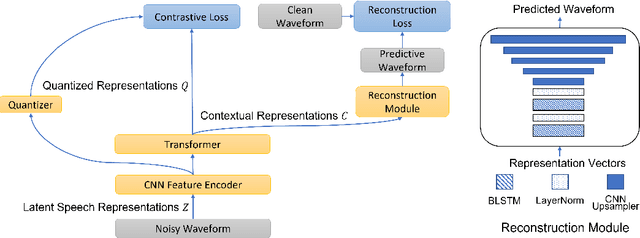
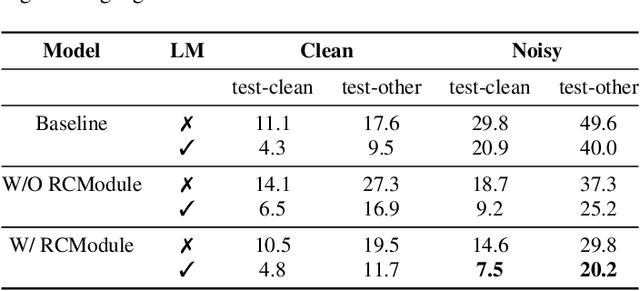
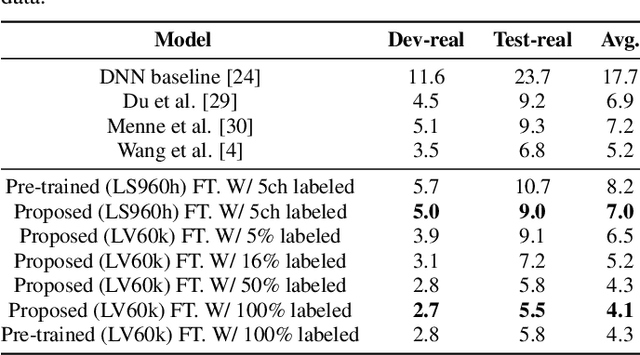
Noise robustness is essential for deploying automatic speech recognition (ASR) systems in real-world environments. One way to reduce the effect of noise interference is to employ a preprocessing module that conducts speech enhancement, and then feed the enhanced speech to an ASR backend. In this work, instead of suppressing background noise with a conventional cascaded pipeline, we employ a noise-robust representation learned by a refined self-supervised framework for noisy speech recognition. We propose to combine a reconstruction module with contrastive learning and perform multi-task continual pre-training on noisy data. The reconstruction module is used for auxiliary learning to improve the noise robustness of the learned representation and thus is not required during inference. Experiments demonstrate the effectiveness of our proposed method. Our model substantially reduces the word error rate (WER) for the synthesized noisy LibriSpeech test sets, and yields around 4.1/7.5% WER reduction on noisy clean/other test sets compared to data augmentation. For the real-world noisy speech from the CHiME-4 challenge (1-channel track), we have obtained the state of the art ASR performance without any denoising front-end. Moreover, we achieve comparable performance to the best supervised approach reported with only 16% of labeled data.
Multichannel Speech Enhancement without Beamforming
Oct 25, 2021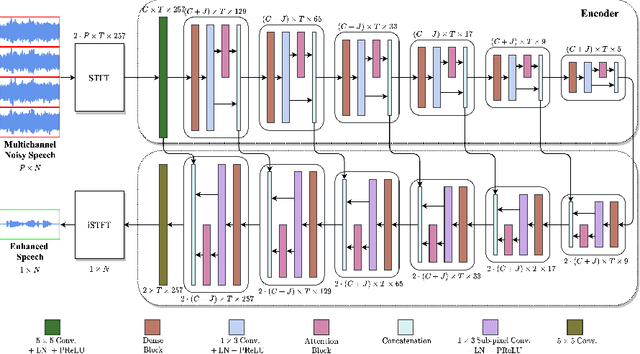
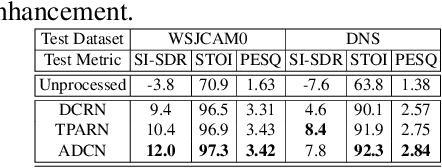
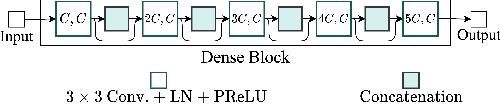
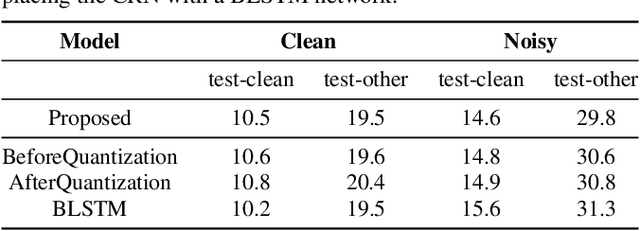
Deep neural networks are often coupled with traditional spatial filters, such as MVDR beamformers for effectively exploiting spatial information. Even though single-stage end-to-end supervised models can obtain impressive enhancement, combining them with a beamformer and a DNN-based post-filter in a multistage processing provides additional improvements. In this work, we propose a two-stage strategy for multi-channel speech enhancement that does not need a beamformer for additional performance. First, we propose a novel attentive dense convolutional network (ADCN) for predicting real and imaginary parts of complex spectrogram. ADCN obtains state-of-the-art results among single-stage models. Next, we use ADCN in the proposed strategy with a recently proposed triple-path attentive recurrent network (TPARN) for predicting waveform samples. The proposed strategy uses two insights; first, using different approaches in two stages; and second, using a stronger model in the first stage. We illustrate the efficacy of our strategy by evaluating multiple models in a two-stage approach with and without beamformer.
TADRN: Triple-Attentive Dual-Recurrent Network for Ad-hoc Array Multichannel Speech Enhancement
Oct 22, 2021


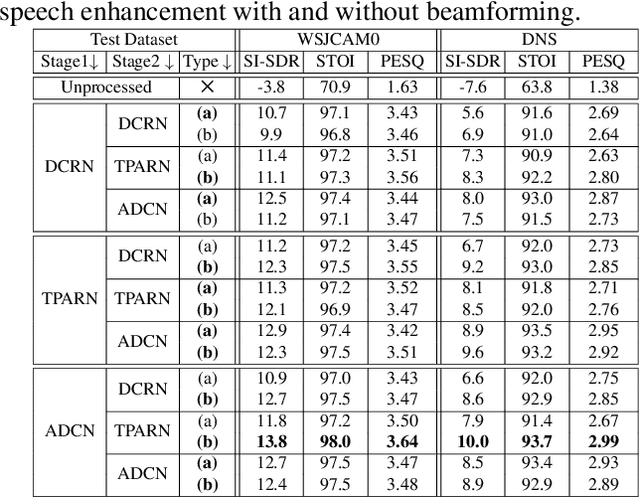
Deep neural networks (DNNs) have been successfully used for multichannel speech enhancement in fixed array geometries. However, challenges remain for ad-hoc arrays with unknown microphone placements. We propose a deep neural network based approach for ad-hoc array processing: Triple-Attentive Dual-Recurrent Network (TADRN). TADRN uses self-attention across channels for learning spatial information and a dual-path attentive recurrent network (ARN) for temporal modeling. Temporal modeling is done independently for all channels by dividing a signal into smaller chunks and using an intra-chunk ARN for local modeling and an inter-chunk ARN for global modeling. Consequently, TADRN uses triple-path attention: inter-channel, intra-chunk, and inter-chunk, and dual-path recurrence: intra-chunk and inter-chunk. Experimental results show excellent performance of TADRN. We demonstrate that TADRN improves speech enhancement by leveraging additional randomly placed microphones, even at locations far from the target source. Additionally, large improvements in objective scores are observed when poorly placed microphones in the scene are complemented with more effective microphone positions, such as those closer to a target source.
TPARN: Triple-path Attentive Recurrent Network for Time-domain Multichannel Speech Enhancement
Oct 20, 2021
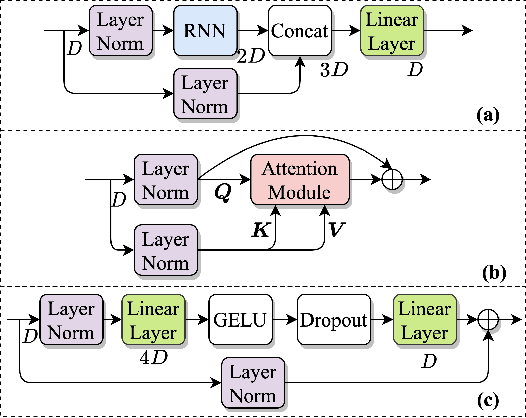
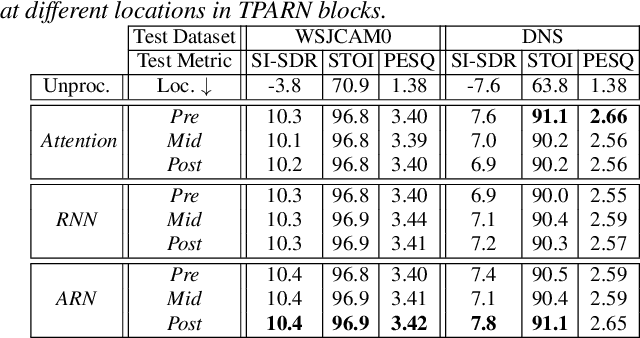
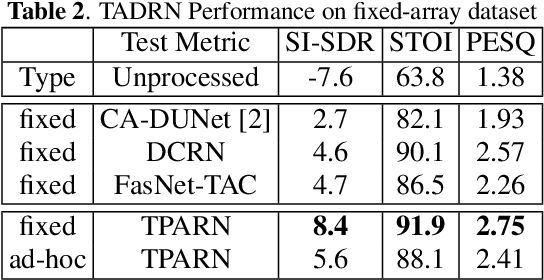
In this work, we propose a new model called triple-path attentive recurrent network (TPARN) for multichannel speech enhancement in the time domain. TPARN extends a single-channel dual-path network to a multichannel network by adding a third path along the spatial dimension. First, TPARN processes speech signals from all channels independently using a dual-path attentive recurrent network (ARN), which is a recurrent neural network (RNN) augmented with self-attention. Next, an ARN is introduced along the spatial dimension for spatial context aggregation. TPARN is designed as a multiple-input and multiple-output architecture to enhance all input channels simultaneously. Experimental results demonstrate the superiority of TPARN over existing state-of-the-art approaches.
Location-based training for multi-channel talker-independent speaker separation
Oct 08, 2021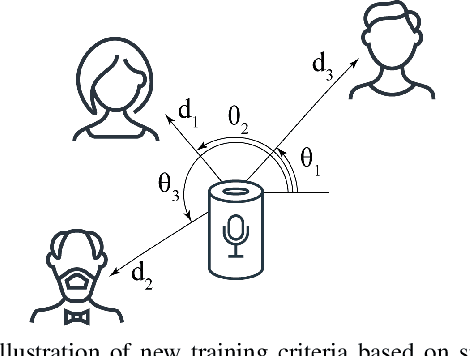
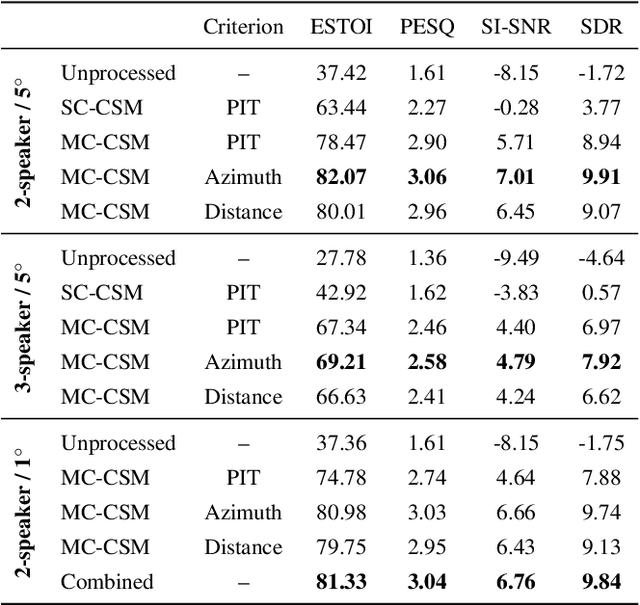
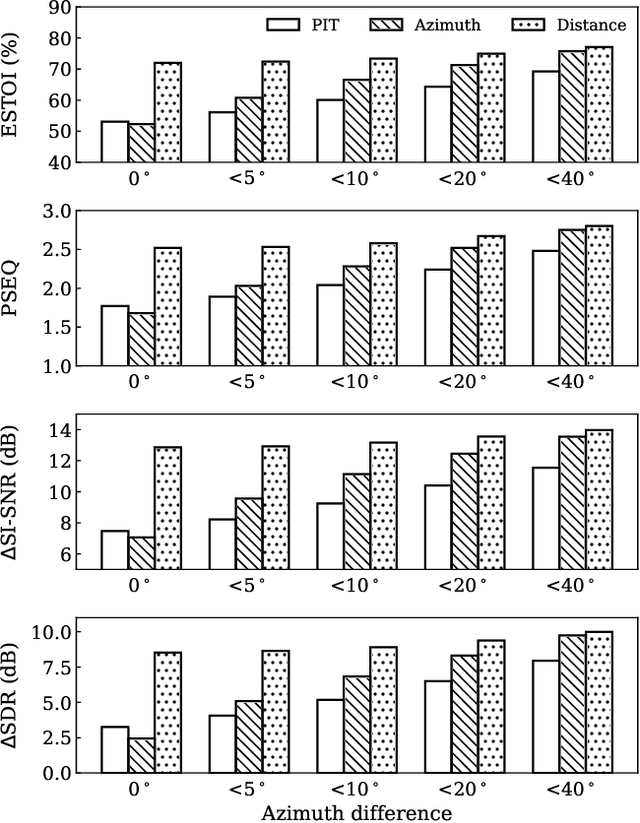
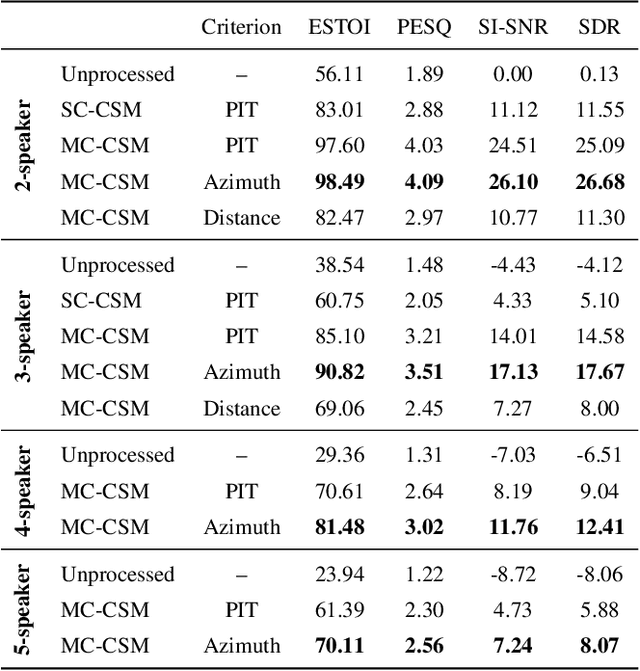
Permutation-invariant training (PIT) is a dominant approach for addressing the permutation ambiguity problem in talker-independent speaker separation. Leveraging spatial information afforded by microphone arrays, we propose a new training approach to resolving permutation ambiguities for multi-channel speaker separation. The proposed approach, named location-based training (LBT), assigns speakers on the basis of their spatial locations. This training strategy is easy to apply, and organizes speakers according to their positions in physical space. Specifically, this study investigates azimuth angles and source distances for location-based training. Evaluation results on separating two- and three-speaker mixtures show that azimuth-based training consistently outperforms PIT, and distance-based training further improves the separation performance when speaker azimuths are close. Furthermore, we dynamically select azimuth-based or distance-based training by estimating the azimuths of separated speakers, which further improves separation performance. LBT has a linear training complexity with respect to the number of speakers, as opposed to the factorial complexity of PIT. We further demonstrate the effectiveness of LBT for the separation of four and five concurrent speakers.
VoiceFixer: Toward General Speech Restoration with Neural Vocoder
Oct 05, 2021
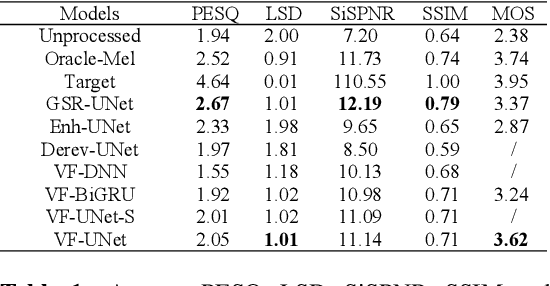
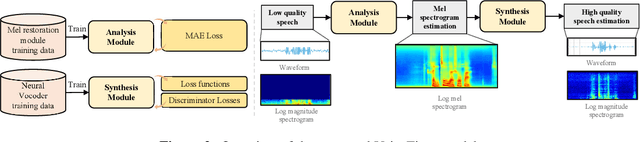
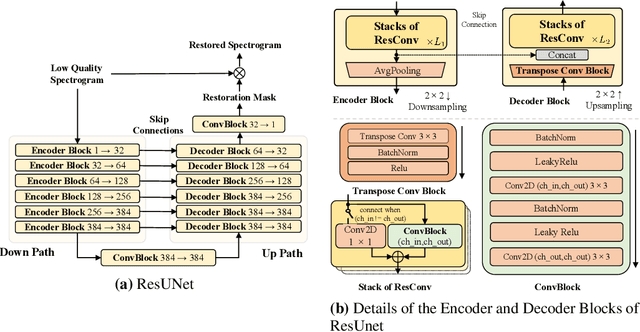
Speech restoration aims to remove distortions in speech signals. Prior methods mainly focus on single-task speech restoration (SSR), such as speech denoising or speech declipping. However, SSR systems only focus on one task and do not address the general speech restoration problem. In addition, previous SSR systems show limited performance in some speech restoration tasks such as speech super-resolution. To overcome those limitations, we propose a general speech restoration (GSR) task that attempts to remove multiple distortions simultaneously. Furthermore, we propose VoiceFixer, a generative framework to address the GSR task. VoiceFixer consists of an analysis stage and a synthesis stage to mimic the speech analysis and comprehension of the human auditory system. We employ a ResUNet to model the analysis stage and a neural vocoder to model the synthesis stage. We evaluate VoiceFixer with additive noise, room reverberation, low-resolution, and clipping distortions. Our baseline GSR model achieves a 0.499 higher mean opinion score (MOS) than the speech enhancement SSR model. VoiceFixer further surpasses the GSR baseline model on the MOS score by 0.256. Moreover, we observe that VoiceFixer generalizes well to severely degraded real speech recordings, indicating its potential in restoring old movies and historical speeches. The source code is available at https://github.com/haoheliu/voicefixer_main.
Localization Based Sequential Grouping for Continuous Speech Separation
Jul 14, 2021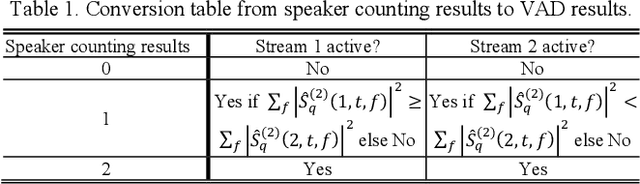
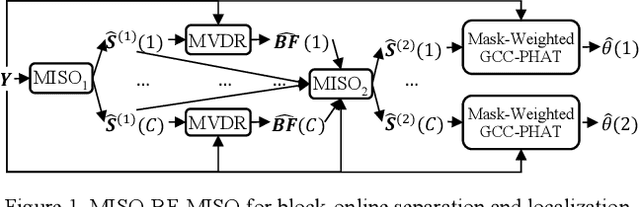
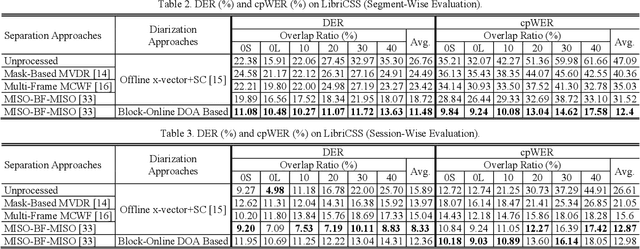
This study investigates robust speaker localization for con-tinuous speech separation and speaker diarization, where we use speaker directions to group non-contiguous segments of the same speaker. Assuming that speakers do not move and are located in different directions, the direction of arrival (DOA) information provides an informative cue for accurate sequential grouping and speaker diarization. Our system is block-online in the following sense. Given a block of frames with at most two speakers, we apply a two-speaker separa-tion model to separate (and enhance) the speakers, estimate the DOA of each separated speaker, and group the separation results across blocks based on the DOA estimates. Speaker diarization and speaker-attributed speech recognition results on the LibriCSS corpus demonstrate the effectiveness of the proposed algorithm.