 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Jan 05, 2024



The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scaling laws and present our distinctive findings that facilitate scaling of large scale models in two commonly used open-source configurations, 7B and 67B. Guided by the scaling laws, we introduce DeepSeek LLM, a project dedicated to advancing open-source language models with a long-term perspective. To support the pre-training phase, we have developed a dataset that currently consists of 2 trillion tokens and is continuously expanding. We further conduct supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) on DeepSeek LLM Base models, resulting in the creation of DeepSeek Chat models. Our evaluation results demonstrate that DeepSeek LLM 67B surpasses LLaMA-2 70B on various benchmarks, particularly in the domains of code, mathematics, and reasoning. Furthermore, open-ended evaluations reveal that DeepSeek LLM 67B Chat exhibits superior performance compared to GPT-3.5.
Noisy Pair Corrector for Dense Retrieval
Nov 07, 2023



Most dense retrieval models contain an implicit assumption: the training query-document pairs are exactly matched. Since it is expensive to annotate the corpus manually, training pairs in real-world applications are usually collected automatically, which inevitably introduces mismatched-pair noise. In this paper, we explore an interesting and challenging problem in dense retrieval, how to train an effective model with mismatched-pair noise. To solve this problem, we propose a novel approach called Noisy Pair Corrector (NPC), which consists of a detection module and a correction module. The detection module estimates noise pairs by calculating the perplexity between annotated positive and easy negative documents. The correction module utilizes an exponential moving average (EMA) model to provide a soft supervised signal, aiding in mitigating the effects of noise. We conduct experiments on text-retrieval benchmarks Natural Question and TriviaQA, code-search benchmarks StaQC and SO-DS. Experimental results show that NPC achieves excellent performance in handling both synthetic and realistic noise.
LongCoder: A Long-Range Pre-trained Language Model for Code Completion
Jun 26, 2023



In this paper, we introduce a new task for code completion that focuses on handling long code input and propose a sparse Transformer model, called LongCoder, to address this task. LongCoder employs a sliding window mechanism for self-attention and introduces two types of globally accessible tokens - bridge tokens and memory tokens - to improve performance and efficiency. Bridge tokens are inserted throughout the input sequence to aggregate local information and facilitate global interaction, while memory tokens are included to highlight important statements that may be invoked later and need to be memorized, such as package imports and definitions of classes, functions, or structures. We conduct experiments on a newly constructed dataset that contains longer code context and the publicly available CodeXGLUE benchmark. Experimental results demonstrate that LongCoder achieves superior performance on code completion tasks compared to previous models while maintaining comparable efficiency in terms of computational resources during inference. All the codes and data are available at https://github.com/microsoft/CodeBERT.
Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data
Apr 04, 2023Chat models, such as ChatGPT, have shown impressive capabilities and have been rapidly adopted across numerous domains. However, these models are only accessible through a restricted API, creating barriers for new research and progress in the field. We propose a pipeline that can automatically generate a high-quality multi-turn chat corpus by leveraging ChatGPT to engage in a conversation with itself. Subsequently, we employ parameter-efficient tuning to enhance LLaMA, an open-source large language model. The resulting model, named Baize, demonstrates good performance in multi-turn dialogues with guardrails that minimize potential risks. The Baize models and data are released for research purposes only at https://github.com/project-baize/baize. An online demo is also available at https://huggingface.co/spaces/project-baize/baize-lora-7B.
Soft-Labeled Contrastive Pre-training for Function-level Code Representation
Oct 18, 2022
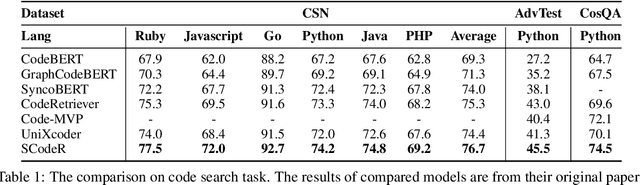
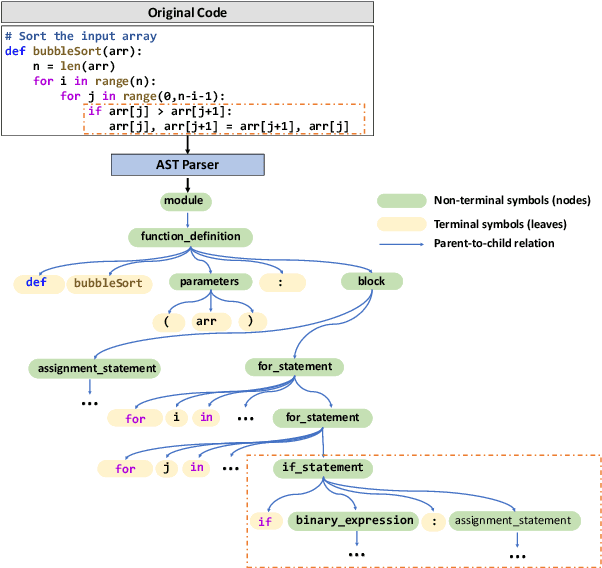
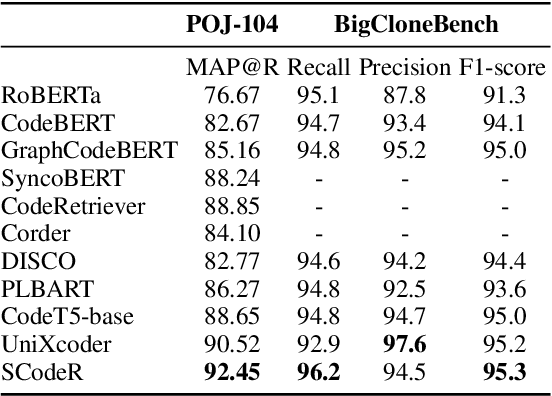
Code contrastive pre-training has recently achieved significant progress on code-related tasks. In this paper, we present \textbf{SCodeR}, a \textbf{S}oft-labeled contrastive pre-training framework with two positive sample construction methods to learn functional-level \textbf{Code} \textbf{R}epresentation. Considering the relevance between codes in a large-scale code corpus, the soft-labeled contrastive pre-training can obtain fine-grained soft-labels through an iterative adversarial manner and use them to learn better code representation. The positive sample construction is another key for contrastive pre-training. Previous works use transformation-based methods like variable renaming to generate semantically equal positive codes. However, they usually result in the generated code with a highly similar surface form, and thus mislead the model to focus on superficial code structure instead of code semantics. To encourage SCodeR to capture semantic information from the code, we utilize code comments and abstract syntax sub-trees of the code to build positive samples. We conduct experiments on four code-related tasks over seven datasets. Extensive experimental results show that SCodeR achieves new state-of-the-art performance on all of them, which illustrates the effectiveness of the proposed pre-training method.
CodeReviewer: Pre-Training for Automating Code Review Activities
Mar 17, 2022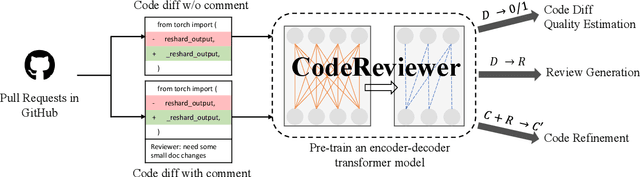

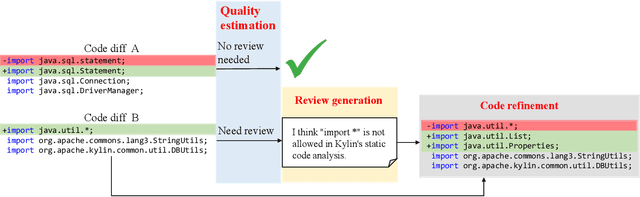
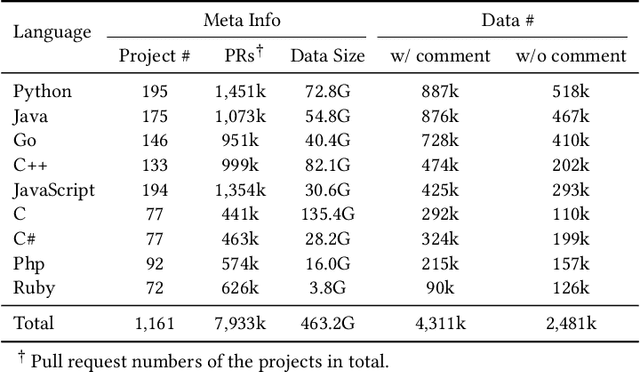
Code review is an essential part to software development lifecycle since it aims at guaranteeing the quality of codes. Modern code review activities necessitate developers viewing, understanding and even running the programs to assess logic, functionality, latency, style and other factors. It turns out that developers have to spend far too much time reviewing the code of their peers. Accordingly, it is in significant demand to automate the code review process. In this research, we focus on utilizing pre-training techniques for the tasks in the code review scenario. We collect a large-scale dataset of real world code changes and code reviews from open-source projects in nine of the most popular programming languages. To better understand code diffs and reviews, we propose CodeReviewer, a pre-trained model that utilizes four pre-training tasks tailored specifically for the code review senario. To evaluate our model, we focus on three key tasks related to code review activities, including code change quality estimation, review comment generation and code refinement. Furthermore, we establish a high-quality benchmark dataset based on our collected data for these three tasks and conduct comprehensive experiments on it. The experimental results demonstrate that our model outperforms the previous state-of-the-art pre-training approaches in all tasks. Further analysis show that our proposed pre-training tasks and the multilingual pre-training dataset benefit the model on the understanding of code changes and reviews.
ReACC: A Retrieval-Augmented Code Completion Framework
Mar 15, 2022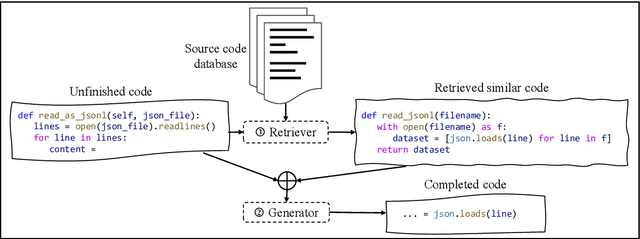


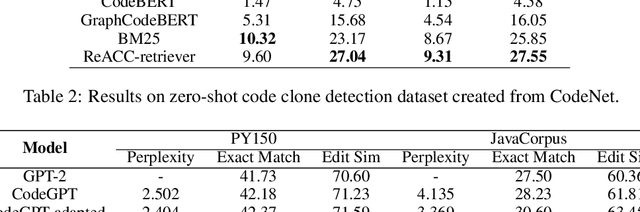
Code completion, which aims to predict the following code token(s) according to the code context, can improve the productivity of software development. Recent work has proved that statistical language modeling with transformers can greatly improve the performance in the code completion task via learning from large-scale source code datasets. However, current approaches focus only on code context within the file or project, i.e. internal context. Our distinction is utilizing "external" context, inspired by human behaviors of copying from the related code snippets when writing code. Specifically, we propose a retrieval-augmented code completion framework, leveraging both lexical copying and referring to code with similar semantics by retrieval. We adopt a stage-wise training approach that combines a source code retriever and an auto-regressive language model for programming language. We evaluate our approach in the code completion task in Python and Java programming languages, achieving a state-of-the-art performance on CodeXGLUE benchmark.
LaPraDoR: Unsupervised Pretrained Dense Retriever for Zero-Shot Text Retrieval
Mar 11, 2022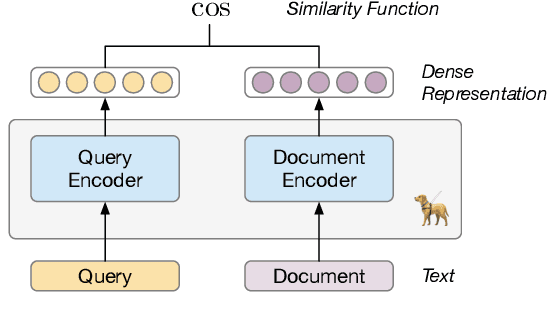
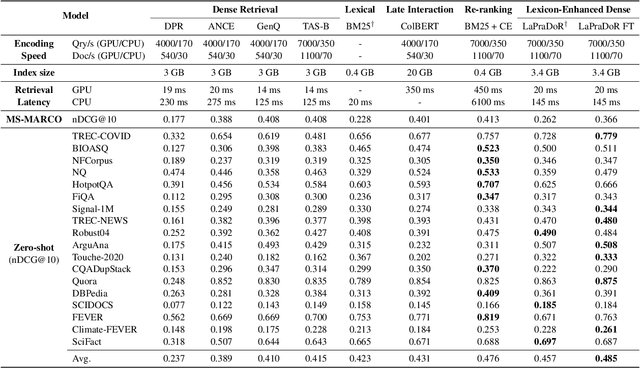
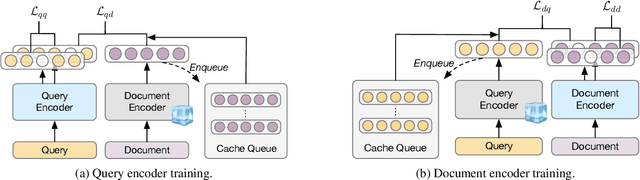
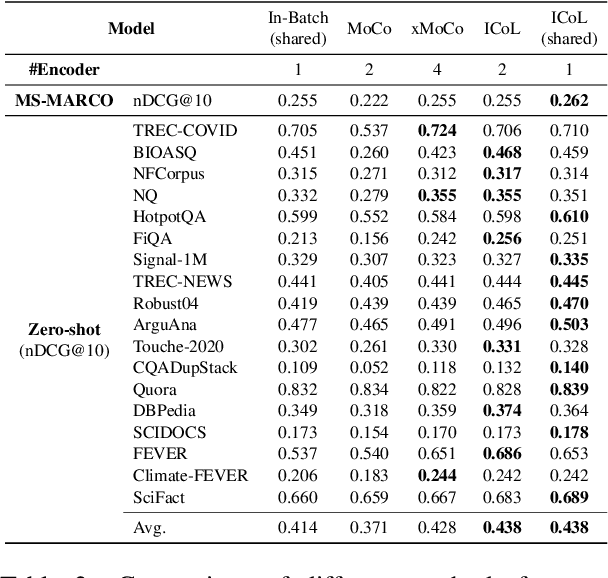
In this paper, we propose LaPraDoR, a pretrained dual-tower dense retriever that does not require any supervised data for training. Specifically, we first present Iterative Contrastive Learning (ICoL) that iteratively trains the query and document encoders with a cache mechanism. ICoL not only enlarges the number of negative instances but also keeps representations of cached examples in the same hidden space. We then propose Lexicon-Enhanced Dense Retrieval (LEDR) as a simple yet effective way to enhance dense retrieval with lexical matching. We evaluate LaPraDoR on the recently proposed BEIR benchmark, including 18 datasets of 9 zero-shot text retrieval tasks. Experimental results show that LaPraDoR achieves state-of-the-art performance compared with supervised dense retrieval models, and further analysis reveals the effectiveness of our training strategy and objectives. Compared to re-ranking, our lexicon-enhanced approach can be run in milliseconds (22.5x faster) while achieving superior performance.
UniXcoder: Unified Cross-Modal Pre-training for Code Representation
Mar 08, 2022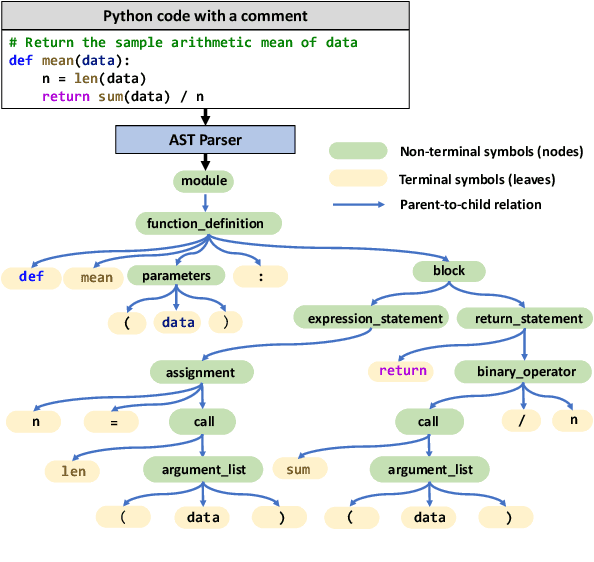
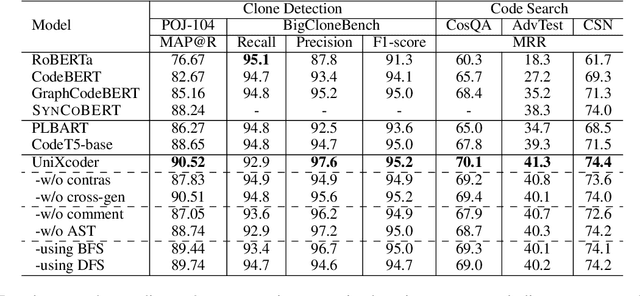
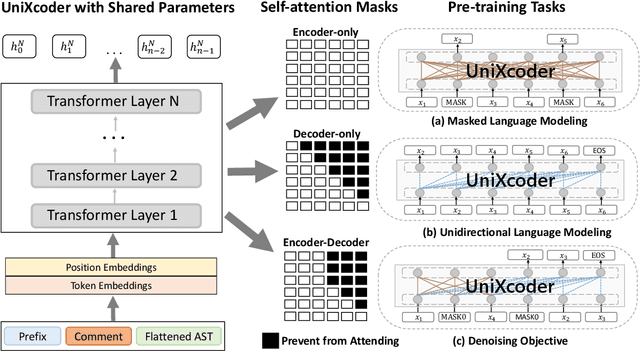
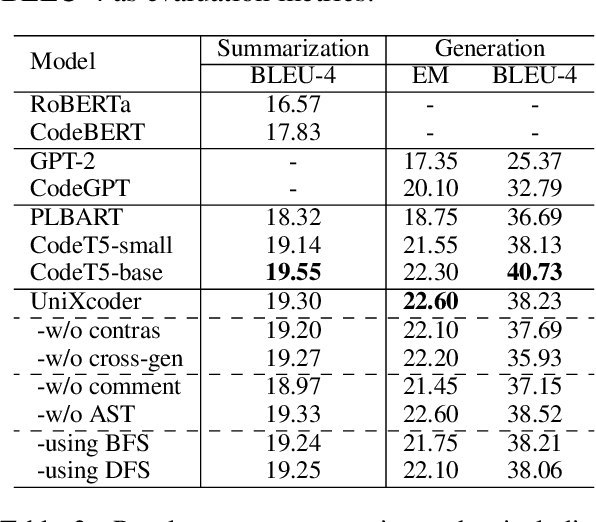
Pre-trained models for programming languages have recently demonstrated great success on code intelligence. To support both code-related understanding and generation tasks, recent works attempt to pre-train unified encoder-decoder models. However, such encoder-decoder framework is sub-optimal for auto-regressive tasks, especially code completion that requires a decoder-only manner for efficient inference. In this paper, we present UniXcoder, a unified cross-modal pre-trained model for programming language. The model utilizes mask attention matrices with prefix adapters to control the behavior of the model and leverages cross-modal contents like AST and code comment to enhance code representation. To encode AST that is represented as a tree in parallel, we propose a one-to-one mapping method to transform AST in a sequence structure that retains all structural information from the tree. Furthermore, we propose to utilize multi-modal contents to learn representation of code fragment with contrastive learning, and then align representations among programming languages using a cross-modal generation task. We evaluate UniXcoder on five code-related tasks over nine datasets. To further evaluate the performance of code fragment representation, we also construct a dataset for a new task, called zero-shot code-to-code search. Results show that our model achieves state-of-the-art performance on most tasks and analysis reveals that comment and AST can both enhance UniXcoder.
Multi-modal Representation Learning for Video Advertisement Content Structuring
Sep 04, 2021
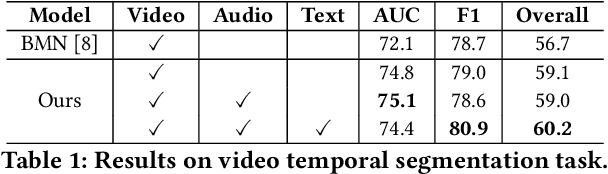

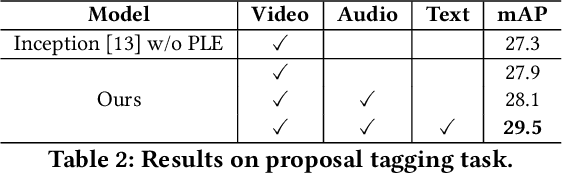
Video advertisement content structuring aims to segment a given video advertisement and label each segment on various dimensions, such as presentation form, scene, and style. Different from real-life videos, video advertisements contain sufficient and useful multi-modal content like caption and speech, which provides crucial video semantics and would enhance the structuring process. In this paper, we propose a multi-modal encoder to learn multi-modal representation from video advertisements by interacting between video-audio and text. Based on multi-modal representation, we then apply Boundary-Matching Network to generate temporal proposals. To make the proposals more accurate, we refine generated proposals by scene-guided alignment and re-ranking. Finally, we incorporate proposal located embeddings into the introduced multi-modal encoder to capture temporal relationships between local features of each proposal and global features of the whole video for classification. Experimental results show that our method achieves significantly improvement compared with several baselines and Rank 1 on the task of Multi-modal Ads Video Understanding in ACM Multimedia 2021 Grand Challenge. Ablation study further shows that leveraging multi-modal content like caption and speech in video advertisements significantly improve the performance.