 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeOCR: On the Effectiveness of Vision Language Models in Code Understanding
Feb 02, 2026Large Language Models (LLMs) have achieved remarkable success in source code understanding, yet as software systems grow in scale, computational efficiency has become a critical bottleneck. Currently, these models rely on a text-based paradigm that treats source code as a linear sequence of tokens, which leads to a linear increase in context length and associated computational costs. The rapid advancement of Multimodal LLMs (MLLMs) introduces an opportunity to optimize efficiency by representing source code as rendered images. Unlike text, which is difficult to compress without losing semantic meaning, the image modality is inherently suitable for compression. By adjusting resolution, images can be scaled to a fraction of their original token cost while remaining recognizable to vision-capable models. To explore the feasibility of this approach, we conduct the first systematic study on the effectiveness of MLLMs for code understanding. Our experiments reveal that: (1) MLLMs can effectively understand code with substantial token reduction, achieving up to 8x compression; (2) MLLMs can effectively leverage visual cues such as syntax highlighting, improving code completion performance under 4x compression; and (3) Code-understanding tasks like clone detection exhibit exceptional resilience to visual compression, with some compression ratios even slightly outperforming raw text inputs. Our findings highlight both the potential and current limitations of MLLMs in code understanding, which points out a shift toward image-modality code representation as a pathway to more efficient inference.
Autoregressive, Yet Revisable: In Decoding Revision for Secure Code Generation
Feb 01, 2026Large Language Model (LLM) based code generation is predominantly formulated as a strictly monotonic process, appending tokens linearly to an immutable prefix. This formulation contrasts to the cognitive process of programming, which is inherently interleaved with forward generation and on-the-fly revision. While prior works attempt to introduce revision via post-hoc agents or external static tools, they either suffer from high latency or fail to leverage the model's intrinsic semantic reasoning. In this paper, we propose Stream of Revision, a paradigm shift that elevates code generation from a monotonic stream to a dynamic, self-correcting trajectory by leveraging model's intrinsic capabilities. We introduce specific action tokens that enable the model to seamlessly backtrack and edit its own history within a single forward pass. By internalizing the revision loop, our framework Stream of Revision allows the model to activate its latent capabilities just-in-time without external dependencies. Empirical results on secure code generation show that Stream of Revision significantly reduces vulnerabilities with minimal inference overhead.
Identifying Good and Bad Neurons for Task-Level Controllable LLMs
Jan 08, 2026Large Language Models have demonstrated remarkable capabilities on multiple-choice question answering benchmarks, but the complex mechanisms underlying their large-scale neurons remain opaque, posing significant challenges for understanding and steering LLMs. While recent studies made progress on identifying responsible neurons for certain abilities, these ability-specific methods are infeasible for task-focused scenarios requiring coordinated use of multiple abilities. Moreover, these approaches focus only on supportive neurons that correlate positively with task completion, while neglecting neurons with other roles-such as inhibitive roles-and misled neuron attribution due to fortuitous behaviors in LLMs (i.e., correctly answer the questions by chance rather than genuine understanding). To address these challenges, we propose NeuronLLM, a novel task-level LLM understanding framework that adopts the biological principle of functional antagonism for LLM neuron identification. The key insight is that task performance is jointly determined by neurons with two opposing roles: good neurons that facilitate task completion and bad neurons that inhibit it. NeuronLLM achieves a holistic modeling of neurons via contrastive learning of good and bad neurons, while leveraging augmented question sets to mitigate the fortuitous behaviors in LLMs. Comprehensive experiments on LLMs of different sizes and families show the superiority of NeuronLLM over existing methods in four NLP tasks, providing new insights into LLM functional organization.
Agentic Software Issue Resolution with Large Language Models: A Survey
Dec 24, 2025Software issue resolution aims to address real-world issues in software repositories (e.g., bug fixing and efficiency optimization) based on natural language descriptions provided by users, representing a key aspect of software maintenance. With the rapid development of large language models (LLMs) in reasoning and generative capabilities, LLM-based approaches have made significant progress in automated software issue resolution. However, real-world software issue resolution is inherently complex and requires long-horizon reasoning, iterative exploration, and feedback-driven decision making, which demand agentic capabilities beyond conventional single-step approaches. Recently, LLM-based agentic systems have become mainstream for software issue resolution. Advancements in agentic software issue resolution not only greatly enhance software maintenance efficiency and quality but also provide a realistic environment for validating agentic systems' reasoning, planning, and execution capabilities, bridging artificial intelligence and software engineering. This work presents a systematic survey of 126 recent studies at the forefront of LLM-based agentic software issue resolution research. It outlines the general workflow of the task and establishes a taxonomy across three dimensions: benchmarks, techniques, and empirical studies. Furthermore, it highlights how the emergence of agentic reinforcement learning has brought a paradigm shift in the design and training of agentic systems for software engineering. Finally, it summarizes key challenges and outlines promising directions for future research.
SecureAgentBench: Benchmarking Secure Code Generation under Realistic Vulnerability Scenarios
Sep 26, 2025Large language model (LLM) powered code agents are rapidly transforming software engineering by automating tasks such as testing, debugging, and repairing, yet the security risks of their generated code have become a critical concern. Existing benchmarks have offered valuable insights but remain insufficient: they often overlook the genuine context in which vulnerabilities were introduced or adopt narrow evaluation protocols that fail to capture either functional correctness or newly introduced vulnerabilities. We therefore introduce SecureAgentBench, a benchmark of 105 coding tasks designed to rigorously evaluate code agents' capabilities in secure code generation. Each task includes (i) realistic task settings that require multi-file edits in large repositories, (ii) aligned contexts based on real-world open-source vulnerabilities with precisely identified introduction points, and (iii) comprehensive evaluation that combines functionality testing, vulnerability checking through proof-of-concept exploits, and detection of newly introduced vulnerabilities using static analysis. We evaluate three representative agents (SWE-agent, OpenHands, and Aider) with three state-of-the-art LLMs (Claude 3.7 Sonnet, GPT-4.1, and DeepSeek-V3.1). Results show that (i) current agents struggle to produce secure code, as even the best-performing one, SWE-agent supported by DeepSeek-V3.1, achieves merely 15.2% correct-and-secure solutions, (ii) some agents produce functionally correct code but still introduce vulnerabilities, including new ones not previously recorded, and (iii) adding explicit security instructions for agents does not significantly improve secure coding, underscoring the need for further research. These findings establish SecureAgentBench as a rigorous benchmark for secure code generation and a step toward more reliable software development with LLMs.
"My productivity is boosted, but ..." Demystifying Users' Perception on AI Coding Assistants
Aug 17, 2025This paper aims to explore fundamental questions in the era when AI coding assistants like GitHub Copilot are widely adopted: what do developers truly value and criticize in AI coding assistants, and what does this reveal about their needs and expectations in real-world software development? Unlike previous studies that conduct observational research in controlled and simulated environments, we analyze extensive, first-hand user reviews of AI coding assistants, which capture developers' authentic perspectives and experiences drawn directly from their actual day-to-day work contexts. We identify 1,085 AI coding assistants from the Visual Studio Code Marketplace. Although they only account for 1.64% of all extensions, we observe a surge in these assistants: over 90% of them are released within the past two years. We then manually analyze the user reviews sampled from 32 AI coding assistants that have sufficient installations and reviews to construct a comprehensive taxonomy of user concerns and feedback about these assistants. We manually annotate each review's attitude when mentioning certain aspects of coding assistants, yielding nuanced insights into user satisfaction and dissatisfaction regarding specific features, concerns, and overall tool performance. Built on top of the findings-including how users demand not just intelligent suggestions but also context-aware, customizable, and resource-efficient interactions-we propose five practical implications and suggestions to guide the enhancement of AI coding assistants that satisfy user needs.
Enhancing Project-Specific Code Completion by Inferring Internal API Information
Jul 28, 2025Project-specific code completion is a critical task that leverages context from a project to generate accurate code. State-of-the-art methods use retrieval-augmented generation (RAG) with large language models (LLMs) and project information for code completion. However, they often struggle to incorporate internal API information, which is crucial for accuracy, especially when APIs are not explicitly imported in the file. To address this, we propose a method to infer internal API information without relying on imports. Our method extends the representation of APIs by constructing usage examples and semantic descriptions, building a knowledge base for LLMs to generate relevant completions. We also introduce ProjBench, a benchmark that avoids leaked imports and consists of large-scale real-world projects. Experiments on ProjBench and CrossCodeEval show that our approach significantly outperforms existing methods, improving code exact match by 22.72% and identifier exact match by 18.31%. Additionally, integrating our method with existing baselines boosts code match by 47.80% and identifier match by 35.55%.
An LLM-as-Judge Metric for Bridging the Gap with Human Evaluation in SE Tasks
May 27, 2025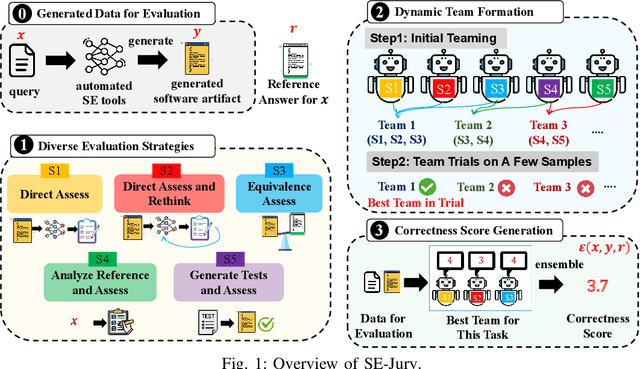
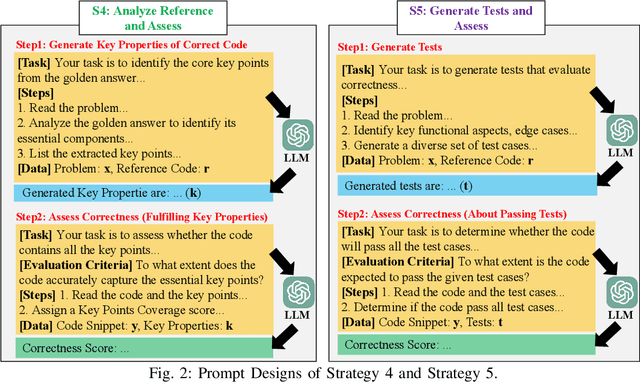
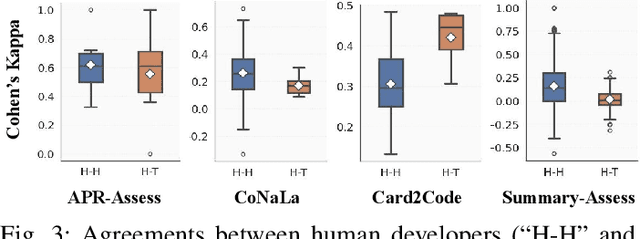
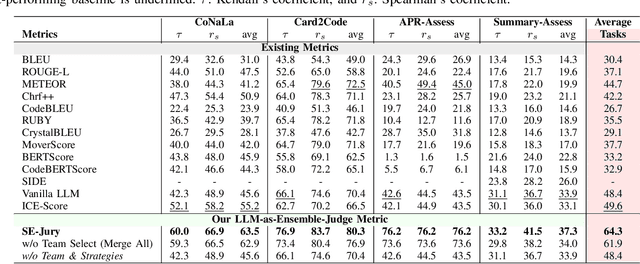
Large Language Models (LLMs) and other automated techniques have been increasingly used to support software developers by generating software artifacts such as code snippets, patches, and comments. However, accurately assessing the correctness of these generated artifacts remains a significant challenge. On one hand, human evaluation provides high accuracy but is labor-intensive and lacks scalability. On the other hand, other existing automatic evaluation metrics are scalable and require minimal human effort, but they often fail to accurately reflect the actual correctness of generated software artifacts. In this paper, we present SWE-Judge, the first evaluation metric for LLM-as-Ensemble-Judge specifically designed to accurately assess the correctness of generated software artifacts. SWE-Judge first defines five distinct evaluation strategies, each implemented as an independent judge. A dynamic team selection mechanism then identifies the most appropriate subset of judges to produce a final correctness score through ensembling. We evaluate SWE-Judge across a diverse set of software engineering (SE) benchmarks, including CoNaLa, Card2Code, HumanEval-X, APPS, APR-Assess, and Summary-Assess. These benchmarks span three SE tasks: code generation, automated program repair, and code summarization. Experimental results demonstrate that SWE-Judge consistently achieves a higher correlation with human judgments, with improvements ranging from 5.9% to 183.8% over existing automatic metrics. Furthermore, SWE-Judge reaches agreement levels with human annotators that are comparable to inter-annotator agreement in code generation and program repair tasks. These findings underscore SWE-Judge's potential as a scalable and reliable alternative to human evaluation.
CODE-DITING: A Reasoning-Based Metric for Functional Alignment in Code Evaluation
May 26, 2025Trustworthy evaluation methods for code snippets play a crucial role in neural code generation. Traditional methods, which either rely on reference solutions or require executable test cases, have inherent limitation in flexibility and scalability. The recent LLM-as-Judge methodology offers a promising alternative by directly evaluating functional consistency between the problem description and the generated code. To systematically understand the landscape of these LLM-as-Judge methods, we conduct a comprehensive empirical study across three diverse datasets. Our investigation reveals the pros and cons of two categories of LLM-as-Judge methods: the methods based on general foundation models can achieve good performance but require complex prompts and lack explainability, while the methods based on reasoning foundation models provide better explainability with simpler prompts but demand substantial computational resources due to their large parameter sizes. To address these limitations, we propose CODE-DITING, a novel code evaluation method that balances accuracy, efficiency and explainability. We develop a data distillation framework that effectively transfers reasoning capabilities from DeepSeek-R1671B to our CODE-DITING 1.5B and 7B models, significantly enhancing evaluation explainability and reducing the computational cost. With the majority vote strategy in the inference process, CODE-DITING 1.5B outperforms all models with the same magnitude of parameters and achieves performance which would normally exhibit in a model with 5 times of parameter scale. CODE-DITING 7B surpasses GPT-4o and DeepSeek-V3 671B, even though it only uses 1% of the parameter volume of these large models. Further experiments show that CODEDITING is robust to preference leakage and can serve as a promising alternative for code evaluation.
Let the Trial Begin: A Mock-Court Approach to Vulnerability Detection using LLM-Based Agents
May 16, 2025Detecting vulnerabilities in source code remains a critical yet challenging task, especially when benign and vulnerable functions share significant similarities. In this work, we introduce VulTrial, a courtroom-inspired multi-agent framework designed to enhance automated vulnerability detection. It employs four role-specific agents, which are security researcher, code author, moderator, and review board. Through extensive experiments using GPT-3.5 and GPT-4o we demonstrate that Vultrial outperforms single-agent and multi-agent baselines. Using GPT-4o, VulTrial improves the performance by 102.39% and 84.17% over its respective baseline. Additionally, we show that role-specific instruction tuning in multi-agent with small data (50 pair samples) improves the performance of VulTrial further by 139.89% and 118.30%. Furthermore, we analyze the impact of increasing the number of agent interactions on VulTrial's overall performance. While multi-agent setups inherently incur higher costs due to increased token usage, our findings reveal that applying VulTrial to a cost-effective model like GPT-3.5 can improve its performance by 69.89% compared to GPT-4o in a single-agent setting, at a lower overall cost.