 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA heterogeneous group CNN for image super-resolution
Sep 26, 2022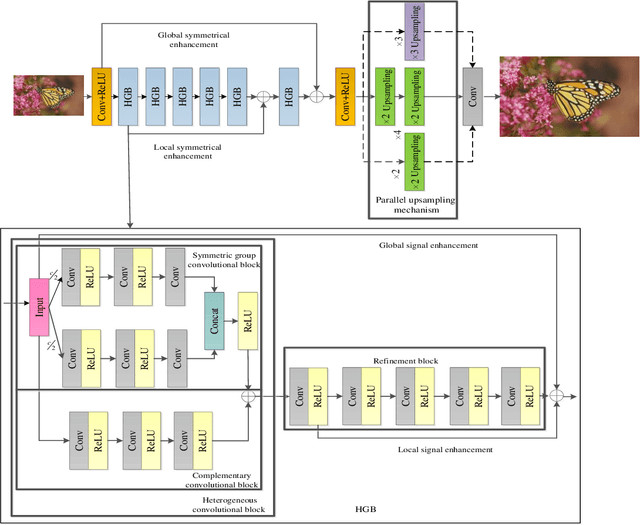


Convolutional neural networks (CNNs) have obtained remarkable performance via deep architectures. However, these CNNs often achieve poor robustness for image super-resolution (SR) under complex scenes. In this paper, we present a heterogeneous group SR CNN (HGSRCNN) via leveraging structure information of different types to obtain a high-quality image. Specifically, each heterogeneous group block (HGB) of HGSRCNN uses a heterogeneous architecture containing a symmetric group convolutional block and a complementary convolutional block in a parallel way to enhance internal and external relations of different channels for facilitating richer low-frequency structure information of different types. To prevent appearance of obtained redundant features, a refinement block with signal enhancements in a serial way is designed to filter useless information. To prevent loss of original information, a multi-level enhancement mechanism guides a CNN to achieve a symmetric architecture for promoting expressive ability of HGSRCNN. Besides, a parallel up-sampling mechanism is developed to train a blind SR model. Extensive experiments illustrate that the proposed HGSRCNN has obtained excellent SR performance in terms of both quantitative and qualitative analysis. Codes can be accessed at https://github.com/hellloxiaotian/HGSRCNN.
Learning ASR pathways: A sparse multilingual ASR model
Sep 13, 2022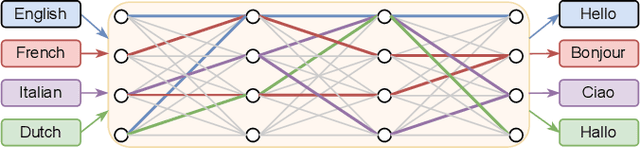
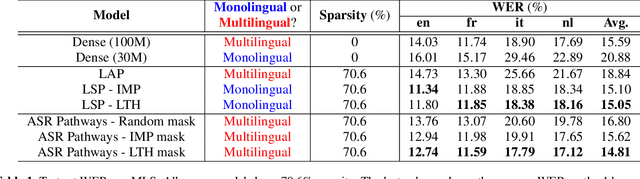
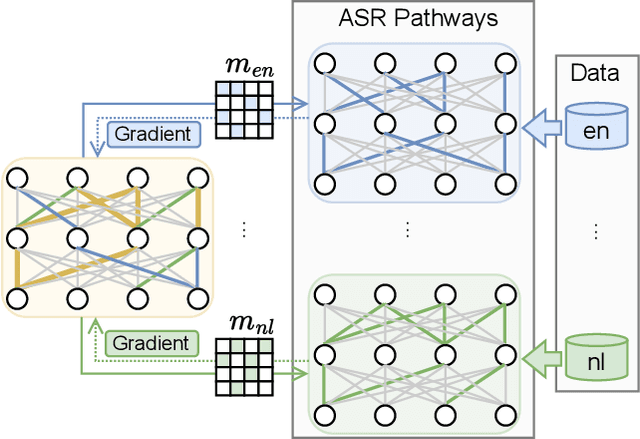
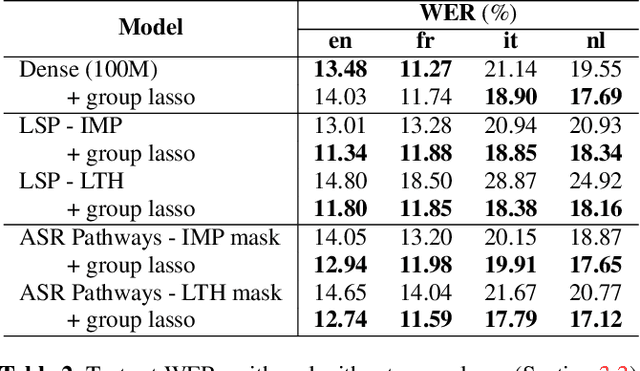
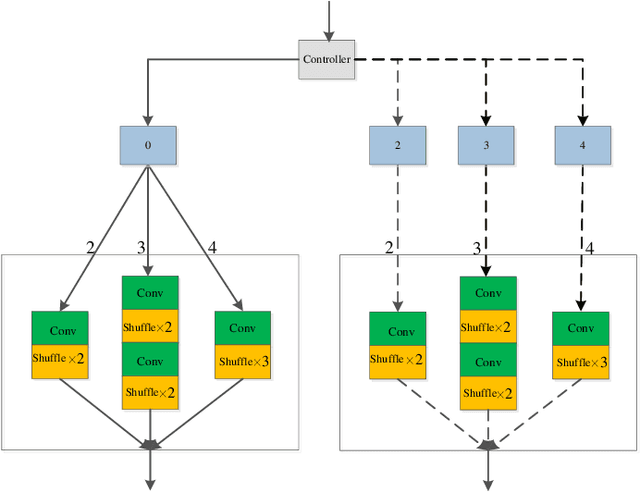
Neural network pruning can be effectively applied to compress automatic speech recognition (ASR) models. However, in multilingual ASR, performing language-agnostic pruning may lead to severe performance degradation on some languages because language-agnostic pruning masks may not fit all languages and discard important language-specific parameters. In this work, we present ASR pathways, a sparse multilingual ASR model that activates language-specific sub-networks ("pathways"), such that the parameters for each language are learned explicitly. With the overlapping sub-networks, the shared parameters can also enable knowledge transfer for lower resource languages via joint multilingual training. We propose a novel algorithm to learn ASR pathways, and evaluate the proposed method on 4 languages with a streaming RNN-T model. Our proposed ASR pathways outperform both dense models (-5.0% average WER) and a language-agnostically pruned model (-21.4% average WER), and provide better performance on low-resource languages compared to the monolingual sparse models.
Learning with Local Gradients at the Edge
Aug 17, 2022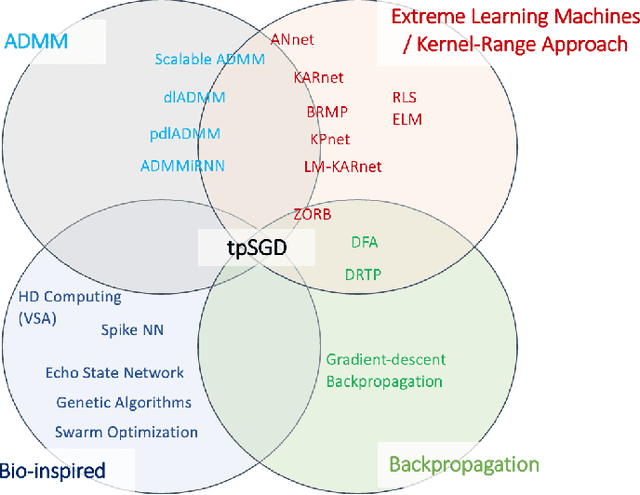
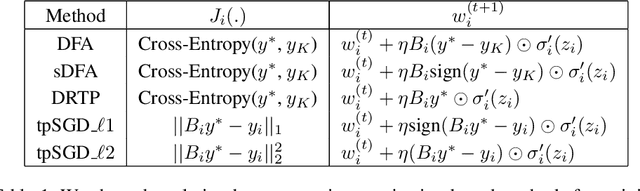
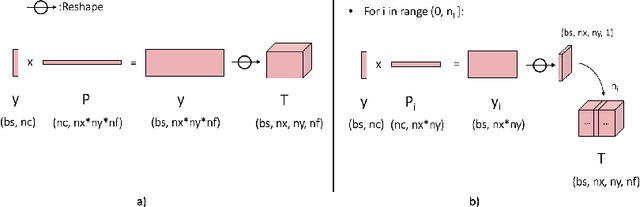
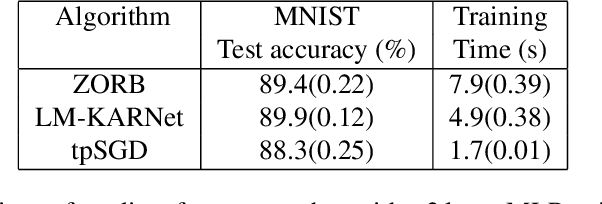
To enable learning on edge devices with fast convergence and low memory, we present a novel backpropagation-free optimization algorithm dubbed Target Projection Stochastic Gradient Descent (tpSGD). tpSGD generalizes direct random target projection to work with arbitrary loss functions and extends target projection for training recurrent neural networks (RNNs) in addition to feedforward networks. tpSGD uses layer-wise stochastic gradient descent (SGD) and local targets generated via random projections of the labels to train the network layer-by-layer with only forward passes. tpSGD doesn't require retaining gradients during optimization, greatly reducing memory allocation compared to SGD backpropagation (BP) methods that require multiple instances of the entire neural network weights, input/output, and intermediate results. Our method performs comparably to BP gradient-descent within 5% accuracy on relatively shallow networks of fully connected layers, convolutional layers, and recurrent layers. tpSGD also outperforms other state-of-the-art gradient-free algorithms in shallow models consisting of multi-layer perceptrons, convolutional neural networks (CNNs), and RNNs with competitive accuracy and less memory and time. We evaluate the performance of tpSGD in training deep neural networks (e.g. VGG) and extend the approach to multi-layer RNNs. These experiments highlight new research directions related to optimized layer-based adaptor training for domain-shift using tpSGD at the edge.
Learning Modal-Invariant and Temporal-Memory for Video-based Visible-Infrared Person Re-Identification
Aug 04, 2022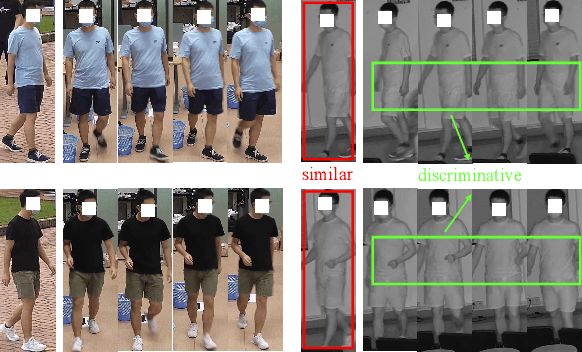


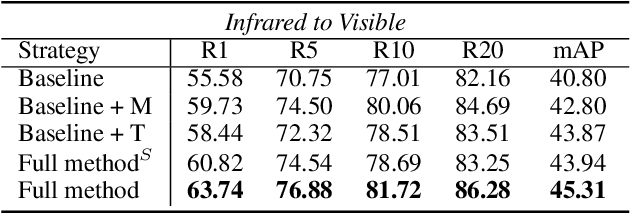
Thanks for the cross-modal retrieval techniques, visible-infrared (RGB-IR) person re-identification (Re-ID) is achieved by projecting them into a common space, allowing person Re-ID in 24-hour surveillance systems. However, with respect to the probe-to-gallery, almost all existing RGB-IR based cross-modal person Re-ID methods focus on image-to-image matching, while the video-to-video matching which contains much richer spatial- and temporal-information remains under-explored. In this paper, we primarily study the video-based cross-modal person Re-ID method. To achieve this task, a video-based RGB-IR dataset is constructed, in which 927 valid identities with 463,259 frames and 21,863 tracklets captured by 12 RGB/IR cameras are collected. Based on our constructed dataset, we prove that with the increase of frames in a tracklet, the performance does meet more enhancement, demonstrating the significance of video-to-video matching in RGB-IR person Re-ID. Additionally, a novel method is further proposed, which not only projects two modalities to a modal-invariant subspace, but also extracts the temporal-memory for motion-invariant. Thanks to these two strategies, much better results are achieved on our video-based cross-modal person Re-ID. The code and dataset are released at: https://github.com/VCMproject233/MITML.
Global-Local Stepwise Generative Network for Ultra High-Resolution Image Restoration
Jul 16, 2022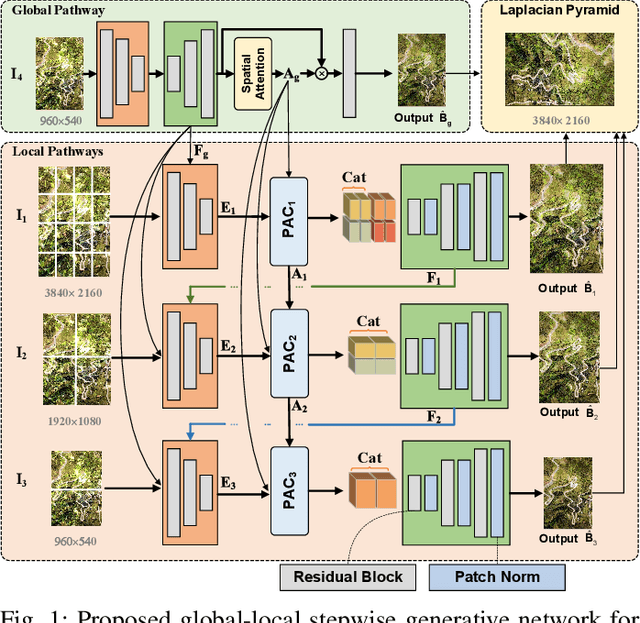



While the research on image background restoration from regular size of degraded images has achieved remarkable progress, restoring ultra high-resolution (e.g., 4K) images remains an extremely challenging task due to the explosion of computational complexity and memory usage, as well as the deficiency of annotated data. In this paper we present a novel model for ultra high-resolution image restoration, referred to as the Global-Local Stepwise Generative Network (GLSGN), which employs a stepwise restoring strategy involving four restoring pathways: three local pathways and one global pathway. The local pathways focus on conducting image restoration in a fine-grained manner over local but high-resolution image patches, while the global pathway performs image restoration coarsely on the scale-down but intact image to provide cues for the local pathways in a global view including semantics and noise patterns. To smooth the mutual collaboration between these four pathways, our GLSGN is designed to ensure the inter-pathway consistency in four aspects in terms of low-level content, perceptual attention, restoring intensity and high-level semantics, respectively. As another major contribution of this work, we also introduce the first ultra high-resolution dataset to date for both reflection removal and rain streak removal, comprising 4,670 real-world and synthetic images. Extensive experiments across three typical tasks for image background restoration, including image reflection removal, image rain streak removal and image dehazing, show that our GLSGN consistently outperforms state-of-the-art methods.
Real-time Hyper-Dimensional Reconfiguration at the Edge using Hardware Accelerators
Jun 10, 2022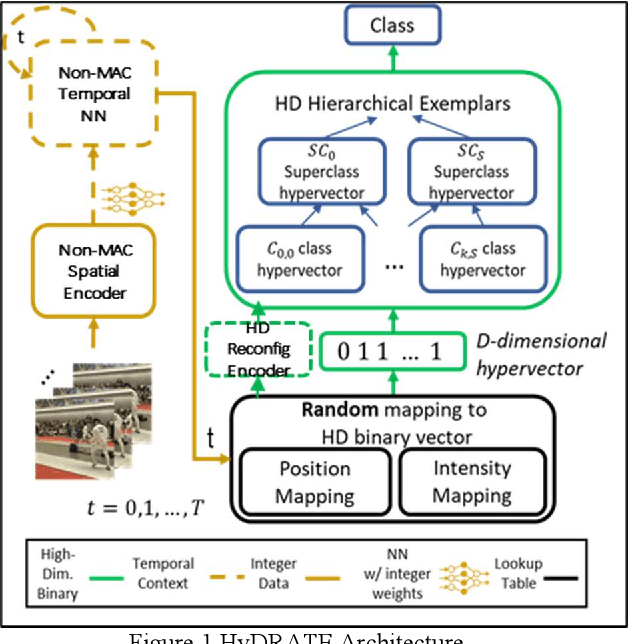
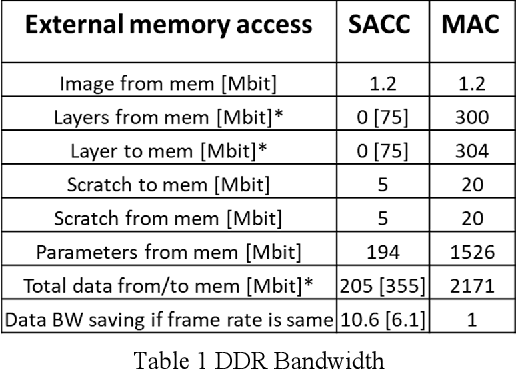
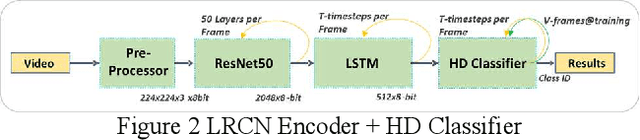
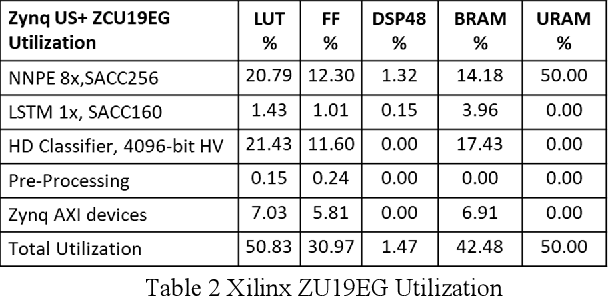
In this paper we present Hyper-Dimensional Reconfigurable Analytics at the Tactical Edge (HyDRATE) using low-SWaP embedded hardware that can perform real-time reconfiguration at the edge leveraging non-MAC (free of floating-point MultiplyACcumulate operations) deep neural nets (DNN) combined with hyperdimensional (HD) computing accelerators. We describe the algorithm, trained quantized model generation, and simulated performance of a feature extractor free of multiply-accumulates feeding a hyperdimensional logic-based classifier. Then we show how performance increases with the number of hyperdimensions. We describe the realized low-SWaP FPGA hardware and embedded software system compared to traditional DNNs and detail the implemented hardware accelerators. We discuss the measured system latency and power, noise robustness due to use of learnable quantization and HD computing, actual versus simulated system performance for a video activity classification task and demonstration of reconfiguration on this same dataset. We show that reconfigurability in the field is achieved by retraining only the feed-forward HD classifier without gradient descent backpropagation (gradient-free), using few-shot learning of new classes at the edge. Initial work performed used LRCN DNN and is currently extended to use Two-stream DNN with improved performance.
Saccade Mechanisms for Image Classification, Object Detection and Tracking
Jun 10, 2022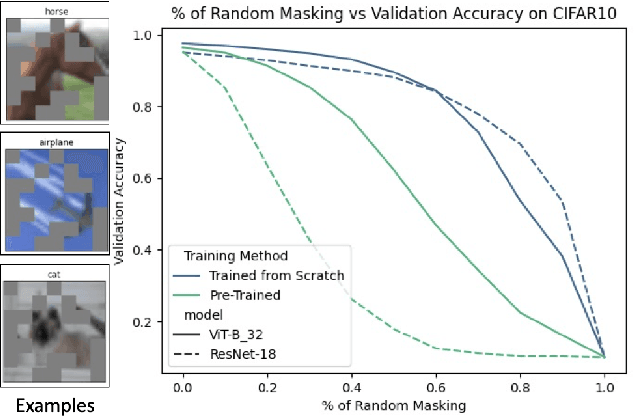
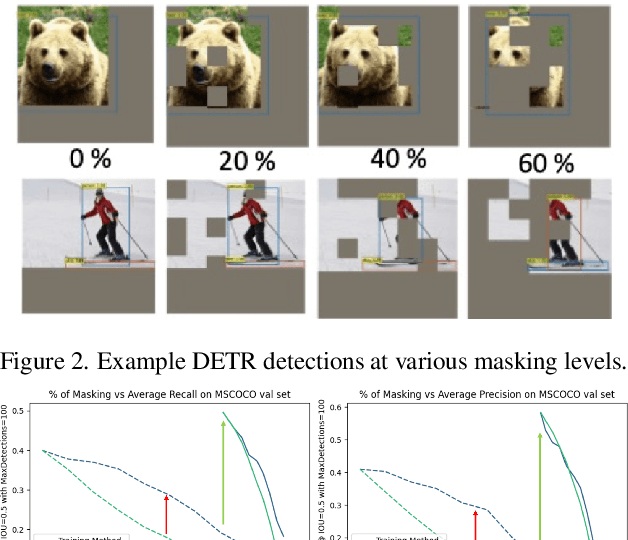

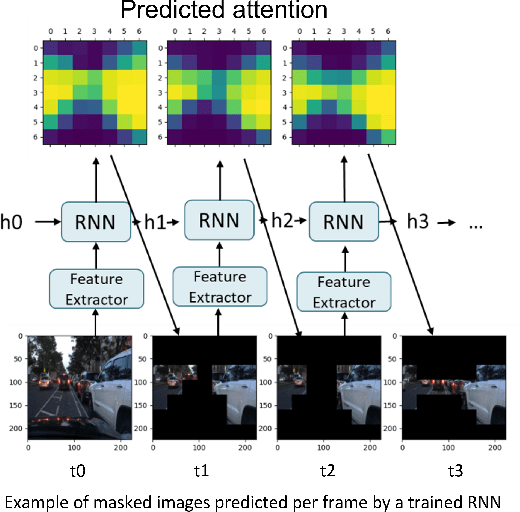
We examine how the saccade mechanism from biological vision can be used to make deep neural networks more efficient for classification and object detection problems. Our proposed approach is based on the ideas of attention-driven visual processing and saccades, miniature eye movements influenced by attention. We conduct experiments by analyzing: i) the robustness of different deep neural network (DNN) feature extractors to partially-sensed images for image classification and object detection, and ii) the utility of saccades in masking image patches for image classification and object tracking. Experiments with convolutional nets (ResNet-18) and transformer-based models (ViT, DETR, TransTrack) are conducted on several datasets (CIFAR-10, DAVSOD, MSCOCO, and MOT17). Our experiments show intelligent data reduction via learning to mimic human saccades when used in conjunction with state-of-the-art DNNs for classification, detection, and tracking tasks. We observed minimal drop in performance for the classification and detection tasks while only using about 30\% of the original sensor data. We discuss how the saccade mechanism can inform hardware design via ``in-pixel'' processing.
Image Super-resolution with An Enhanced Group Convolutional Neural Network
May 29, 2022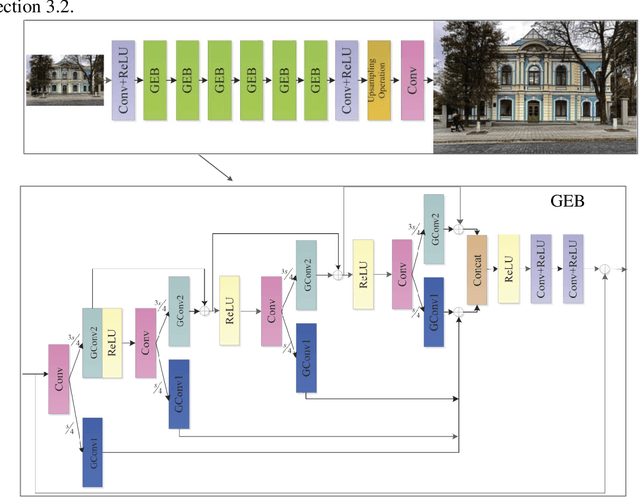

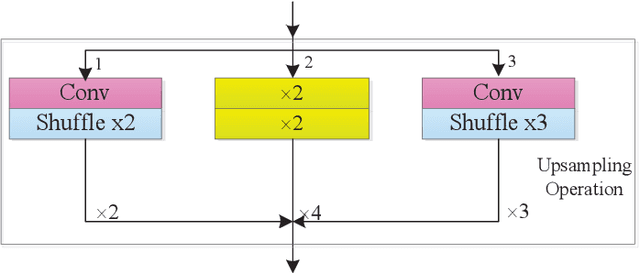
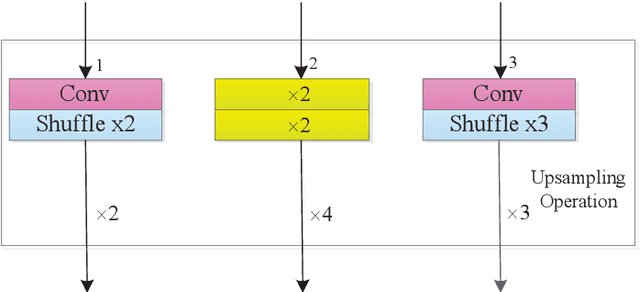
CNNs with strong learning abilities are widely chosen to resolve super-resolution problem. However, CNNs depend on deeper network architectures to improve performance of image super-resolution, which may increase computational cost in general. In this paper, we present an enhanced super-resolution group CNN (ESRGCNN) with a shallow architecture by fully fusing deep and wide channel features to extract more accurate low-frequency information in terms of correlations of different channels in single image super-resolution (SISR). Also, a signal enhancement operation in the ESRGCNN is useful to inherit more long-distance contextual information for resolving long-term dependency. An adaptive up-sampling operation is gathered into a CNN to obtain an image super-resolution model with low-resolution images of different sizes. Extensive experiments report that our ESRGCNN surpasses the state-of-the-arts in terms of SISR performance, complexity, execution speed, image quality evaluation and visual effect in SISR. Code is found at https://github.com/hellloxiaotian/ESRGCNN.
HIPA: Hierarchical Patch Transformer for Single Image Super Resolution
Mar 19, 2022
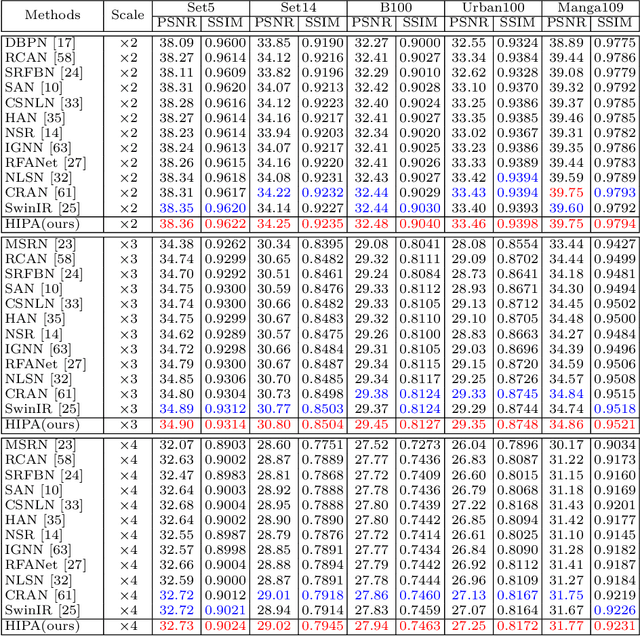
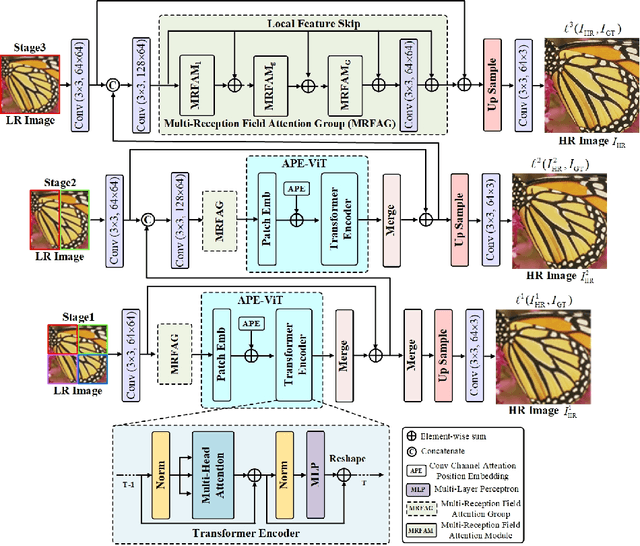

Transformer-based architectures start to emerge in single image super resolution (SISR) and have achieved promising performance. Most existing Vision Transformers divide images into the same number of patches with a fixed size, which may not be optimal for restoring patches with different levels of texture richness. This paper presents HIPA, a novel Transformer architecture that progressively recovers the high resolution image using a hierarchical patch partition. Specifically, we build a cascaded model that processes an input image in multiple stages, where we start with tokens with small patch sizes and gradually merge to the full resolution. Such a hierarchical patch mechanism not only explicitly enables feature aggregation at multiple resolutions but also adaptively learns patch-aware features for different image regions, e.g., using a smaller patch for areas with fine details and a larger patch for textureless regions. Meanwhile, a new attention-based position encoding scheme for Transformer is proposed to let the network focus on which tokens should be paid more attention by assigning different weights to different tokens, which is the first time to our best knowledge. Furthermore, we also propose a new multi-reception field attention module to enlarge the convolution reception field from different branches. The experimental results on several public datasets demonstrate the superior performance of the proposed HIPA over previous methods quantitatively and qualitatively.
Pseudocylindrical Convolutions for Learned Omnidirectional Image Compression
Dec 25, 2021
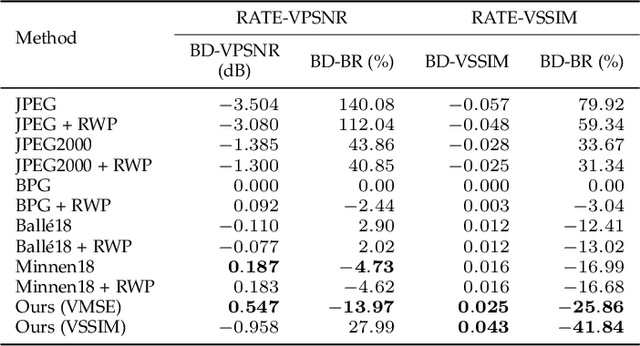
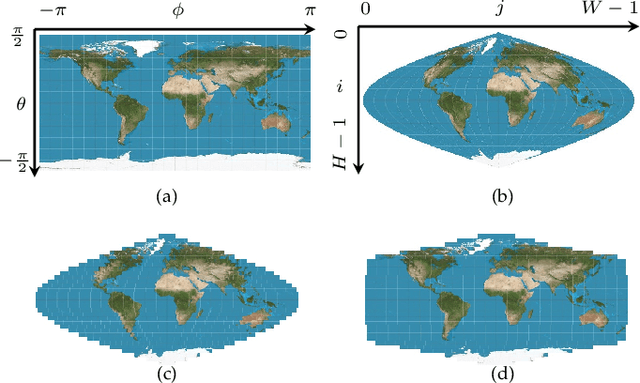

Although equirectangular projection (ERP) is a convenient form to store omnidirectional images (also known as 360-degree images), it is neither equal-area nor conformal, thus not friendly to subsequent visual communication. In the context of image compression, ERP will over-sample and deform things and stuff near the poles, making it difficult for perceptually optimal bit allocation. In conventional 360-degree image compression, techniques such as region-wise packing and tiled representation are introduced to alleviate the over-sampling problem, achieving limited success. In this paper, we make one of the first attempts to learn deep neural networks for omnidirectional image compression. We first describe parametric pseudocylindrical representation as a generalization of common pseudocylindrical map projections. A computationally tractable greedy method is presented to determine the (sub)-optimal configuration of the pseudocylindrical representation in terms of a novel proxy objective for rate-distortion performance. We then propose pseudocylindrical convolutions for 360-degree image compression. Under reasonable constraints on the parametric representation, the pseudocylindrical convolution can be efficiently implemented by standard convolution with the so-called pseudocylindrical padding. To demonstrate the feasibility of our idea, we implement an end-to-end 360-degree image compression system, consisting of the learned pseudocylindrical representation, an analysis transform, a non-uniform quantizer, a synthesis transform, and an entropy model. Experimental results on $19,790$ omnidirectional images show that our method achieves consistently better rate-distortion performance than the competing methods. Moreover, the visual quality by our method is significantly improved for all images at all bitrates.