 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-OmniClaw Technical Report: A Unified Mobile Agent for Multimodal Understanding and Interaction
May 07, 2026Inspired by the development of OpenClaw, there is a growing demand for mobile-based personal agents capable of handling complex and intuitive interactions. In this technical report, we introduce X-OmniClaw, a unified mobile agent designed for multimodal understanding and interaction in the Android ecosystem. This unified architecture of perception, memory, and action enables the agent to handle complex mobile tasks with high contextual awareness. Specifically, Omni Perception provides a unified multimodal ingress pipeline that integrates UI states, real-world visual contexts, and speech inputs, leveraging a temporal alignment module to decompose raw data into structured multimodal intent representations. Omni Memory leverages multimodal memory optimization to enhance personalized intelligence by integrating runtime working memory for task continuity with long-term personal memory distilled from local data, enabling highly context-aware and personalized interactions. Finally, Omni Action employs a hybrid grounding strategy that combines structural XML metadata with visual perception for robust interaction. Through Behavior Cloning and Trajectory Replay, the system captures user navigation as reusable skills, enabling precise direct-access execution. Demonstrations across diverse scenarios show that X-OmniClaw effectively enhances interaction efficiency and task reliability, providing a practical architectural blueprint for the next generation of mobile-native personal assistants.
Global-Local Stepwise Generative Network for Ultra High-Resolution Image Restoration
Jul 16, 2022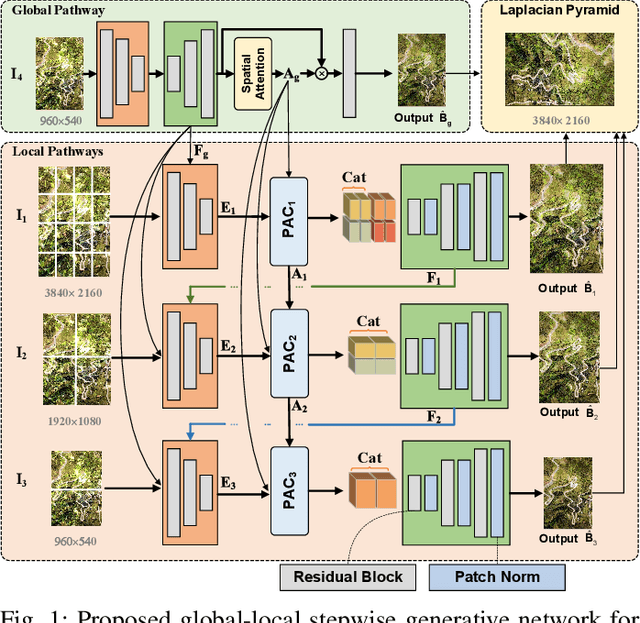



While the research on image background restoration from regular size of degraded images has achieved remarkable progress, restoring ultra high-resolution (e.g., 4K) images remains an extremely challenging task due to the explosion of computational complexity and memory usage, as well as the deficiency of annotated data. In this paper we present a novel model for ultra high-resolution image restoration, referred to as the Global-Local Stepwise Generative Network (GLSGN), which employs a stepwise restoring strategy involving four restoring pathways: three local pathways and one global pathway. The local pathways focus on conducting image restoration in a fine-grained manner over local but high-resolution image patches, while the global pathway performs image restoration coarsely on the scale-down but intact image to provide cues for the local pathways in a global view including semantics and noise patterns. To smooth the mutual collaboration between these four pathways, our GLSGN is designed to ensure the inter-pathway consistency in four aspects in terms of low-level content, perceptual attention, restoring intensity and high-level semantics, respectively. As another major contribution of this work, we also introduce the first ultra high-resolution dataset to date for both reflection removal and rain streak removal, comprising 4,670 real-world and synthetic images. Extensive experiments across three typical tasks for image background restoration, including image reflection removal, image rain streak removal and image dehazing, show that our GLSGN consistently outperforms state-of-the-art methods.
U2-Former: A Nested U-shaped Transformer for Image Restoration
Dec 08, 2021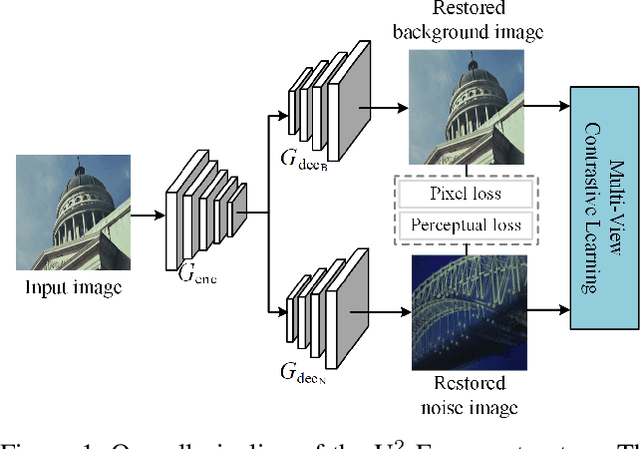
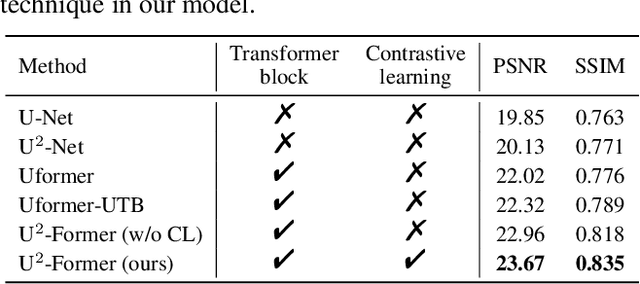
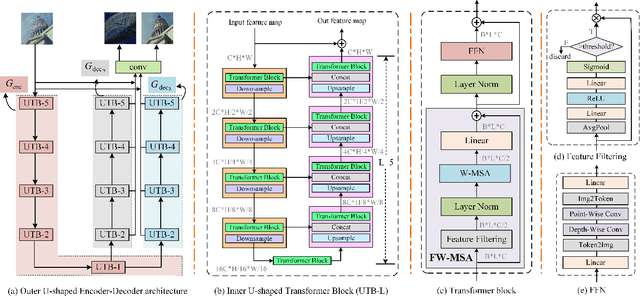
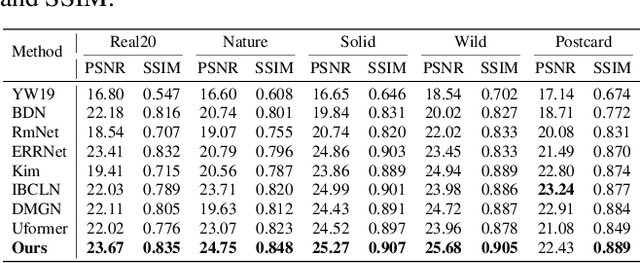
While Transformer has achieved remarkable performance in various high-level vision tasks, it is still challenging to exploit the full potential of Transformer in image restoration. The crux lies in the limited depth of applying Transformer in the typical encoder-decoder framework for image restoration, resulting from heavy self-attention computation load and inefficient communications across different depth (scales) of layers. In this paper, we present a deep and effective Transformer-based network for image restoration, termed as U2-Former, which is able to employ Transformer as the core operation to perform image restoration in a deep encoding and decoding space. Specifically, it leverages the nested U-shaped structure to facilitate the interactions across different layers with different scales of feature maps. Furthermore, we optimize the computational efficiency for the basic Transformer block by introducing a feature-filtering mechanism to compress the token representation. Apart from the typical supervision ways for image restoration, our U2-Former also performs contrastive learning in multiple aspects to further decouple the noise component from the background image. Extensive experiments on various image restoration tasks, including reflection removal, rain streak removal and dehazing respectively, demonstrate the effectiveness of the proposed U2-Former.