 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit vs Unfolded Graph Neural Networks
Nov 12, 2021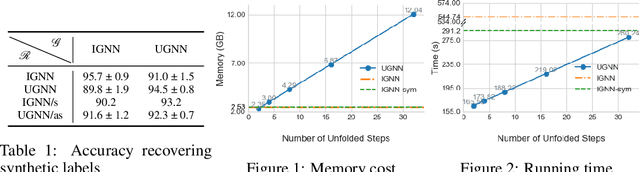

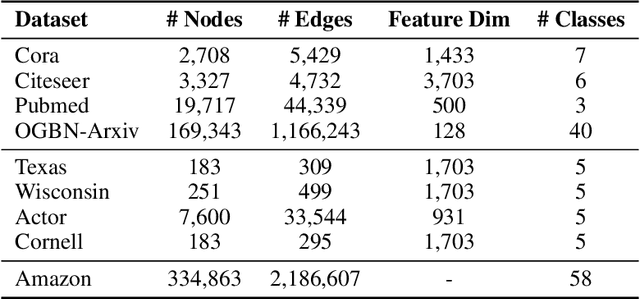
It has been observed that graph neural networks (GNN) sometimes struggle to maintain a healthy balance between modeling long-range dependencies across nodes while avoiding unintended consequences such as oversmoothed node representations. To address this issue (among other things), two separate strategies have recently been proposed, namely implicit and unfolded GNNs. The former treats node representations as the fixed points of a deep equilibrium model that can efficiently facilitate arbitrary implicit propagation across the graph with a fixed memory footprint. In contrast, the latter involves treating graph propagation as the unfolded descent iterations as applied to some graph-regularized energy function. While motivated differently, in this paper we carefully elucidate the similarity and differences of these methods, quantifying explicit situations where the solutions they produced may actually be equivalent and others where behavior diverges. This includes the analysis of convergence, representational capacity, and interpretability. We also provide empirical head-to-head comparisons across a variety of synthetic and public real-world benchmarks.
Convergent Boosted Smoothing for Modeling Graph Data with Tabular Node Features
Oct 26, 2021
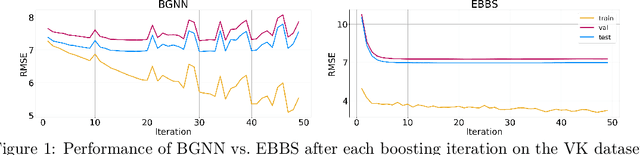

For supervised learning with tabular data, decision tree ensembles produced via boosting techniques generally dominate real-world applications involving iid training/test sets. However for graph data where the iid assumption is violated due to structured relations between samples, it remains unclear how to best incorporate this structure within existing boosting pipelines. To this end, we propose a generalized framework for iterating boosting with graph propagation steps that share node/sample information across edges connecting related samples. Unlike previous efforts to integrate graph-based models with boosting, our approach is anchored in a principled meta loss function such that provable convergence can be guaranteed under relatively mild assumptions. Across a variety of non-iid graph datasets with tabular node features, our method achieves comparable or superior performance than both tabular and graph neural network models, as well as existing hybrid strategies that combine the two. Beyond producing better predictive performance than recently proposed graph models, our proposed techniques are easy to implement, computationally more efficient, and enjoy stronger theoretical guarantees (which make our results more reproducible).
Why Propagate Alone? Parallel Use of Labels and Features on Graphs
Oct 14, 2021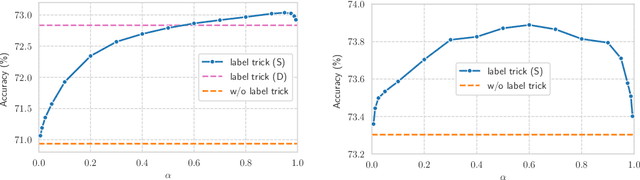



Graph neural networks (GNNs) and label propagation represent two interrelated modeling strategies designed to exploit graph structure in tasks such as node property prediction. The former is typically based on stacked message-passing layers that share neighborhood information to transform node features into predictive embeddings. In contrast, the latter involves spreading label information to unlabeled nodes via a parameter-free diffusion process, but operates independently of the node features. Given then that the material difference is merely whether features or labels are smoothed across the graph, it is natural to consider combinations of the two for improving performance. In this regard, it has recently been proposed to use a randomly-selected portion of the training labels as GNN inputs, concatenated with the original node features for making predictions on the remaining labels. This so-called label trick accommodates the parallel use of features and labels, and is foundational to many of the top-ranking submissions on the Open Graph Benchmark (OGB) leaderboard. And yet despite its wide-spread adoption, thus far there has been little attempt to carefully unpack exactly what statistical properties the label trick introduces into the training pipeline, intended or otherwise. To this end, we prove that under certain simplifying assumptions, the stochastic label trick can be reduced to an interpretable, deterministic training objective composed of two factors. The first is a data-fitting term that naturally resolves potential label leakage issues, while the second serves as a regularization factor conditioned on graph structure that adapts to graph size and connectivity. Later, we leverage this perspective to motivate a broader range of label trick use cases, and provide experiments to verify the efficacy of these extensions.
Learning Hierarchical Graph Neural Networks for Image Clustering
Jul 17, 2021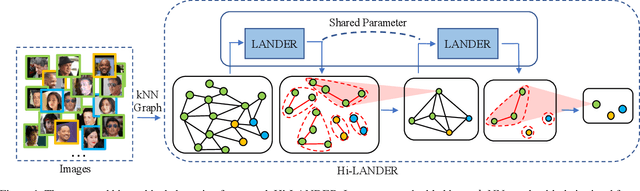
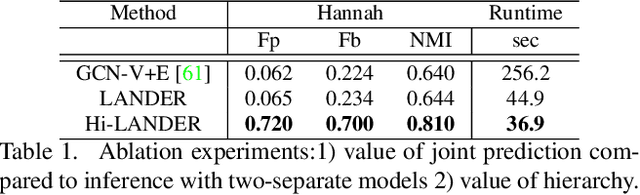
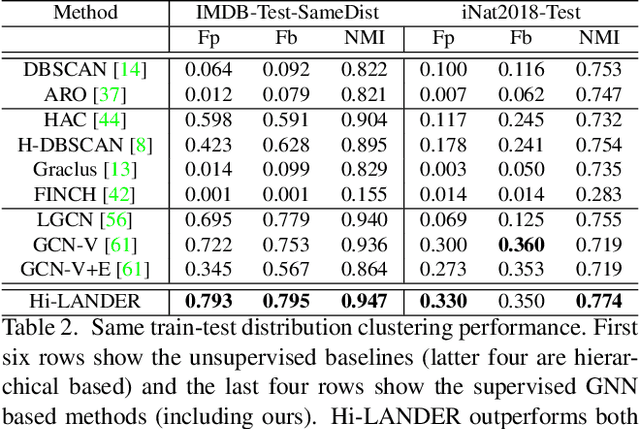
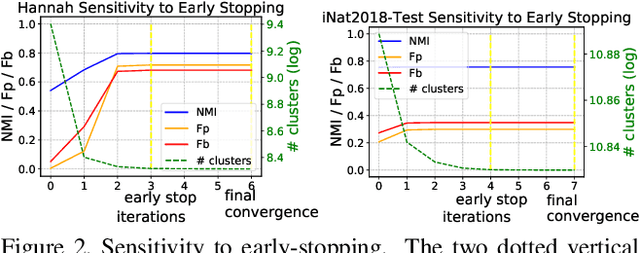
We propose a hierarchical graph neural network (GNN) model that learns how to cluster a set of images into an unknown number of identities using a training set of images annotated with labels belonging to a disjoint set of identities. Our hierarchical GNN uses a novel approach to merge connected components predicted at each level of the hierarchy to form a new graph at the next level. Unlike fully unsupervised hierarchical clustering, the choice of grouping and complexity criteria stems naturally from supervision in the training set. The resulting method, Hi-LANDER, achieves an average of 54% improvement in F-score and 8% increase in Normalized Mutual Information (NMI) relative to current GNN-based clustering algorithms. Additionally, state-of-the-art GNN-based methods rely on separate models to predict linkage probabilities and node densities as intermediate steps of the clustering process. In contrast, our unified framework achieves a seven-fold decrease in computational cost. We release our training and inference code at https://github.com/dmlc/dgl/tree/master/examples/pytorch/hilander.
From Canonical Correlation Analysis to Self-supervised Graph Neural Networks
Jun 23, 2021
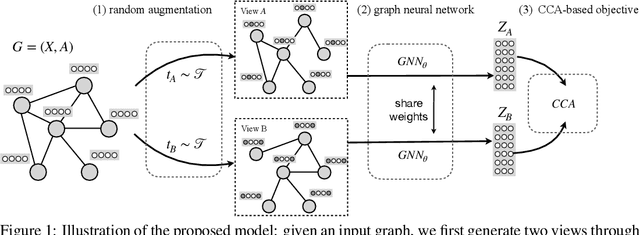
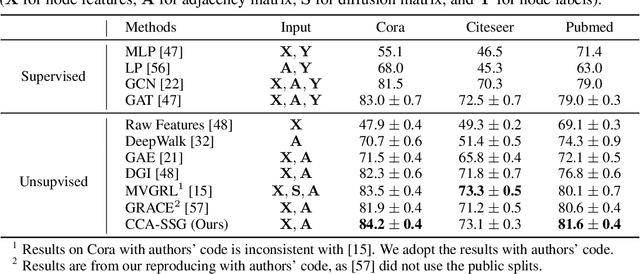
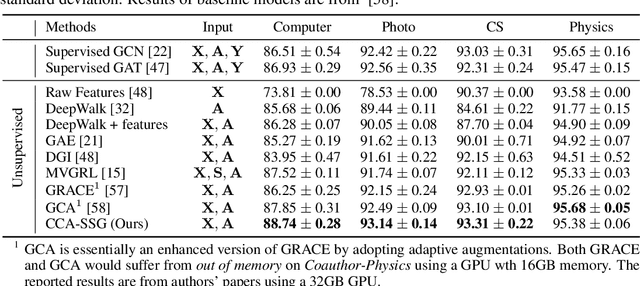
We introduce a conceptually simple yet effective model for self-supervised representation learning with graph data. It follows the previous methods that generate two views of an input graph through data augmentation. However, unlike contrastive methods that focus on instance-level discrimination, we optimize an innovative feature-level objective inspired by classical Canonical Correlation Analysis. Compared with other works, our approach requires none of the parameterized mutual information estimator, additional projector, asymmetric structures, and most importantly, negative samples which can be costly. We show that the new objective essentially 1) aims at discarding augmentation-variant information by learning invariant representations, and 2) can prevent degenerated solutions by decorrelating features in different dimensions. Our theoretical analysis further provides an understanding for the new objective which can be equivalently seen as an instantiation of the Information Bottleneck Principle under the self-supervised setting. Despite its simplicity, our method performs competitively on seven public graph datasets.
Graph Neural Networks Inspired by Classical Iterative Algorithms
Mar 10, 2021
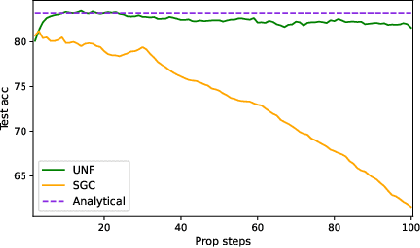
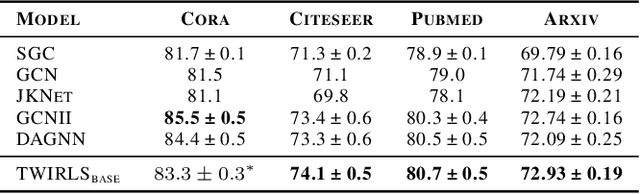
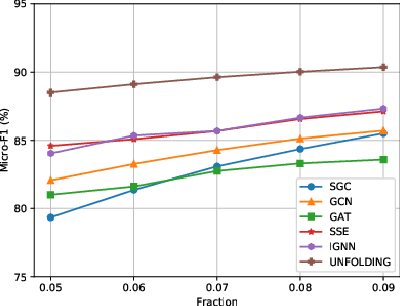
Despite the recent success of graph neural networks (GNN), common architectures often exhibit significant limitations, including sensitivity to oversmoothing, long-range dependencies, and spurious edges, e.g., as can occur as a result of graph heterophily or adversarial attacks. To at least partially address these issues within a simple transparent framework, we consider a new family of GNN layers designed to mimic and integrate the update rules of two classical iterative algorithms, namely, proximal gradient descent and iterative reweighted least squares (IRLS). The former defines an extensible base GNN architecture that is immune to oversmoothing while nonetheless capturing long-range dependencies by allowing arbitrary propagation steps. In contrast, the latter produces a novel attention mechanism that is explicitly anchored to an underlying end-toend energy function, contributing stability with respect to edge uncertainty. When combined we obtain an extremely simple yet robust model that we evaluate across disparate scenarios including standardized benchmarks, adversarially-perturbated graphs, graphs with heterophily, and graphs involving long-range dependencies. In doing so, we compare against SOTA GNN approaches that have been explicitly designed for the respective task, achieving competitive or superior node classification accuracy.
A Biased Graph Neural Network Sampler with Near-Optimal Regret
Mar 01, 2021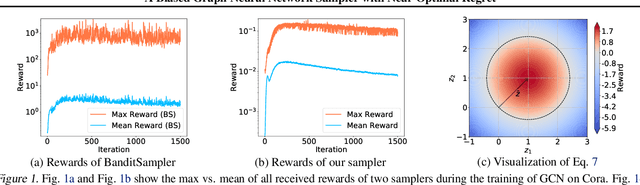

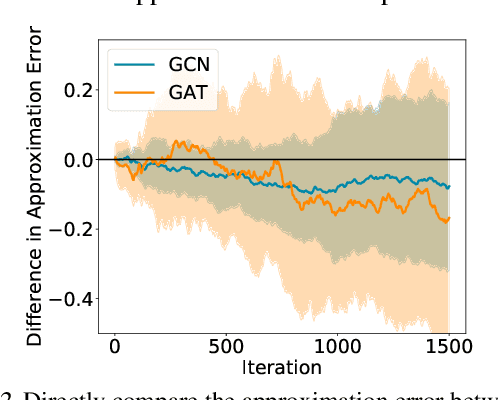

Graph neural networks (GNN) have recently emerged as a vehicle for applying deep network architectures to graph and relational data. However, given the increasing size of industrial datasets, in many practical situations, the message passing computations required for sharing information across GNN layers are no longer scalable. Although various sampling methods have been introduced to approximate full-graph training within a tractable budget, there remain unresolved complications such as high variances and limited theoretical guarantees. To address these issues, we build upon existing work and treat GNN neighbor sampling as a multi-armed bandit problem but with a newly-designed reward function that introduces some degree of bias designed to reduce variance and avoid unstable, possibly-unbounded payouts. And unlike prior bandit-GNN use cases, the resulting policy leads to near-optimal regret while accounting for the GNN training dynamics introduced by SGD. From a practical standpoint, this translates into lower variance estimates and competitive or superior test accuracy across several benchmarks.
Fork or Fail: Cycle-Consistent Training with Many-to-One Mappings
Jan 25, 2021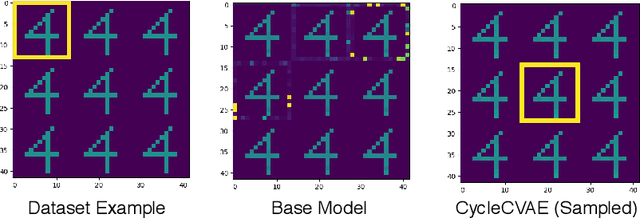
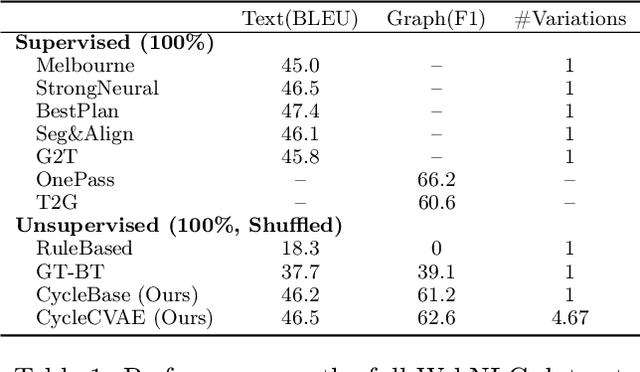
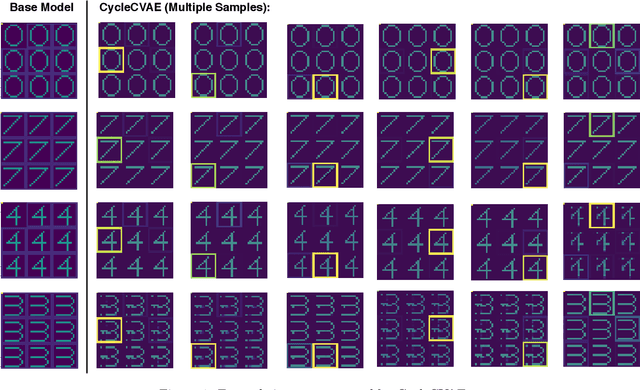
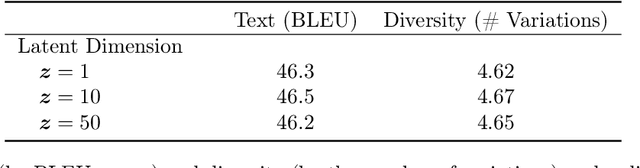
Cycle-consistent training is widely used for jointly learning a forward and inverse mapping between two domains of interest without the cumbersome requirement of collecting matched pairs within each domain. In this regard, the implicit assumption is that there exists (at least approximately) a ground-truth bijection such that a given input from either domain can be accurately reconstructed from successive application of the respective mappings. But in many applications no such bijection can be expected to exist and large reconstruction errors can compromise the success of cycle-consistent training. As one important instance of this limitation, we consider practically-relevant situations where there exists a many-to-one or surjective mapping between domains. To address this regime, we develop a conditional variational autoencoder (CVAE) approach that can be viewed as converting surjective mappings to implicit bijections whereby reconstruction errors in both directions can be minimized, and as a natural byproduct, realistic output diversity can be obtained in the one-to-many direction. As theoretical motivation, we analyze a simplified scenario whereby minima of the proposed CVAE-based energy function align with the recovery of ground-truth surjective mappings. On the empirical side, we consider a synthetic image dataset with known ground-truth, as well as a real-world application involving natural language generation from knowledge graphs and vice versa, a prototypical surjective case. For the latter, our CVAE pipeline can capture such many-to-one mappings during cycle training while promoting textural diversity for graph-to-text tasks. Our code is available at github.com/QipengGuo/CycleGT *A condensed version of this paper has been accepted to AISTATS 2021. This version contains additional content and updates.
Further Analysis of Outlier Detection with Deep Generative Models
Oct 25, 2020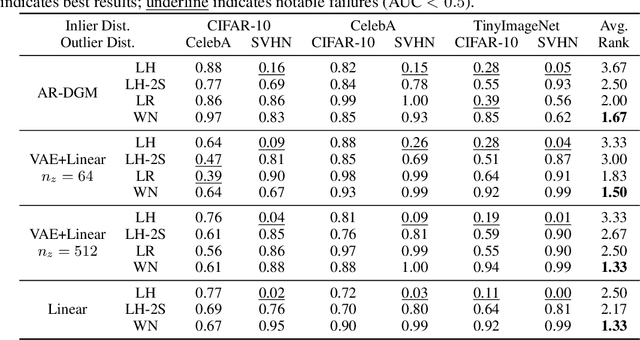

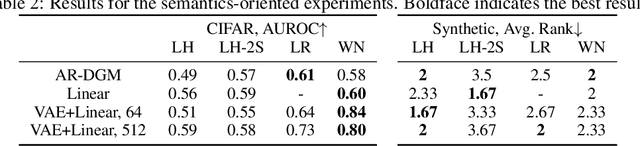
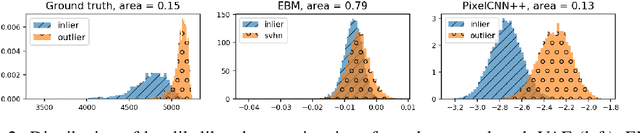
The recent, counter-intuitive discovery that deep generative models (DGMs) can frequently assign a higher likelihood to outliers has implications for both outlier detection applications as well as our overall understanding of generative modeling. In this work, we present a possible explanation for this phenomenon, starting from the observation that a model's typical set and high-density region may not conincide. From this vantage point we propose a novel outlier test, the empirical success of which suggests that the failure of existing likelihood-based outlier tests does not necessarily imply that the corresponding generative model is uncalibrated. We also conduct additional experiments to help disentangle the impact of low-level texture versus high-level semantics in differentiating outliers. In aggregate, these results suggest that modifications to the standard evaluation practices and benchmarks commonly applied in the literature are needed.
CycleGT: Unsupervised Graph-to-Text and Text-to-Graph Generation via Cycle Training
Jun 11, 2020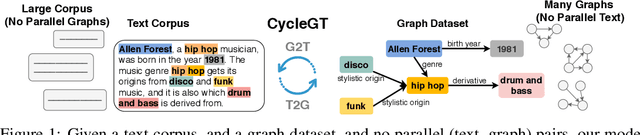

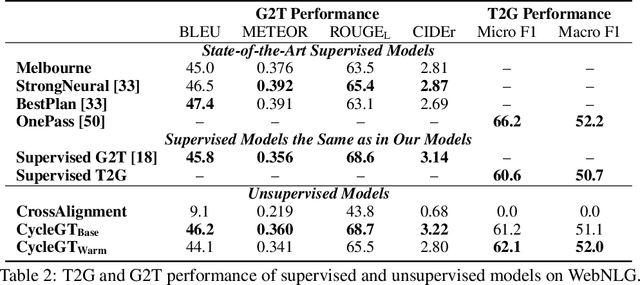
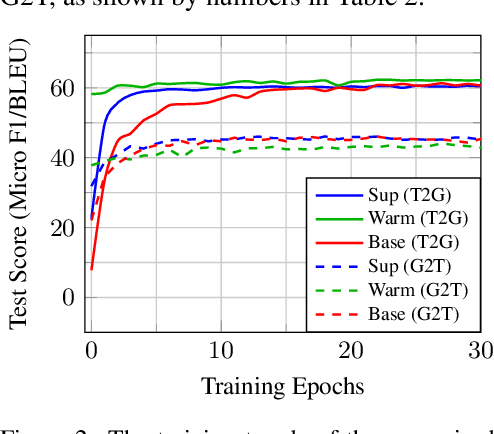
Two important tasks at the intersection of knowledge graphs and natural language processing are graph-to-text (G2T) and text-to-graph (T2G) conversion. Due to the difficulty and high cost of data collection, the supervised data available in the two fields are usually on the magnitude of tens of thousands, for example, 18K in the WebNLG dataset, which is far fewer than the millions of data for other tasks such as machine translation. Consequently, deep learning models in these two fields suffer largely from scarce training data. This work presents the first attempt to unsupervised learning of T2G and G2T via cycle training. We present CycleGT, an unsupervised training framework that can bootstrap from fully non-parallel graph and text datasets, iteratively back translate between the two forms, and use a novel pretraining strategy. Experiments on the benchmark WebNLG dataset show that, impressively, our unsupervised model trained on the same amount of data can achieve performance on par with the supervised models. This validates our framework as an effective approach to overcome the data scarcity problem in the fields of G2T and T2G.