 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayerwise Optimization by Gradient Decomposition for Continual Learning
May 17, 2021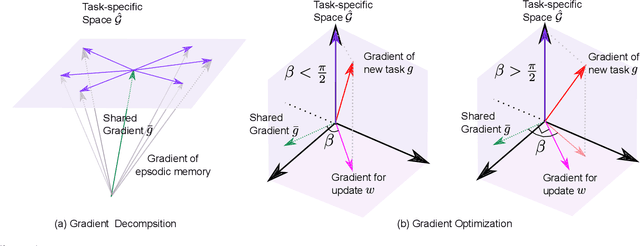
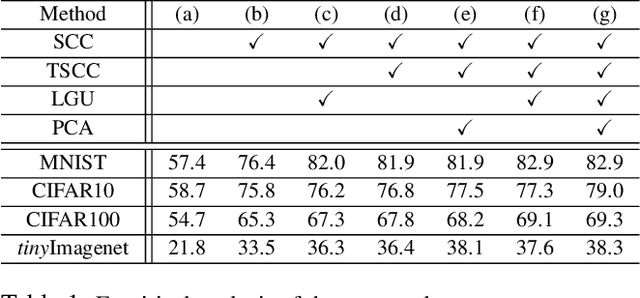
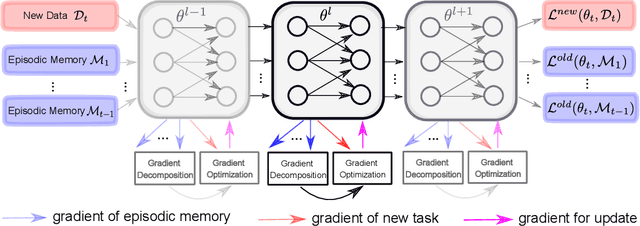
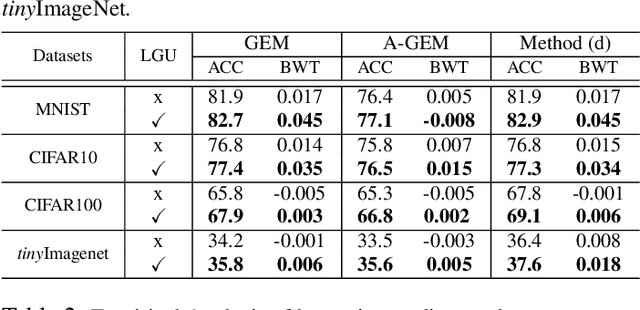
Deep neural networks achieve state-of-the-art and sometimes super-human performance across various domains. However, when learning tasks sequentially, the networks easily forget the knowledge of previous tasks, known as "catastrophic forgetting". To achieve the consistencies between the old tasks and the new task, one effective solution is to modify the gradient for update. Previous methods enforce independent gradient constraints for different tasks, while we consider these gradients contain complex information, and propose to leverage inter-task information by gradient decomposition. In particular, the gradient of an old task is decomposed into a part shared by all old tasks and a part specific to that task. The gradient for update should be close to the gradient of the new task, consistent with the gradients shared by all old tasks, and orthogonal to the space spanned by the gradients specific to the old tasks. In this way, our approach encourages common knowledge consolidation without impairing the task-specific knowledge. Furthermore, the optimization is performed for the gradients of each layer separately rather than the concatenation of all gradients as in previous works. This effectively avoids the influence of the magnitude variation of the gradients in different layers. Extensive experiments validate the effectiveness of both gradient-decomposed optimization and layer-wise updates. Our proposed method achieves state-of-the-art results on various benchmarks of continual learning.
Neighbourhood-guided Feature Reconstruction for Occluded Person Re-Identification
May 16, 2021
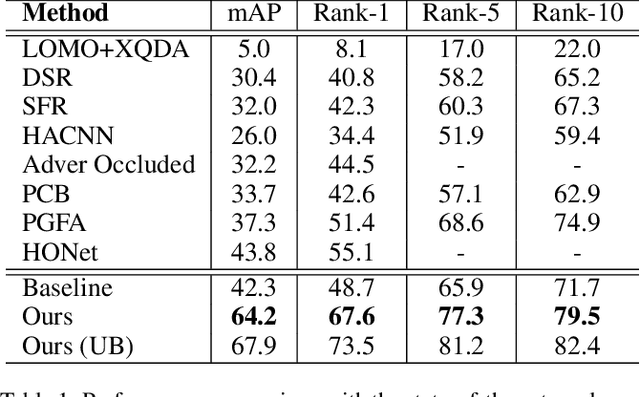
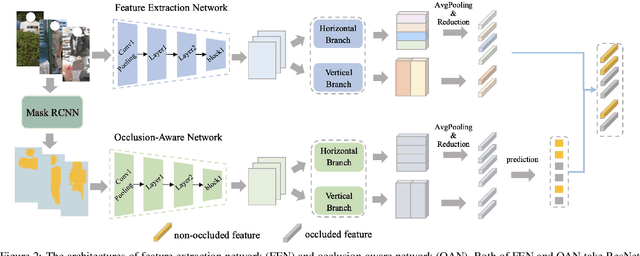
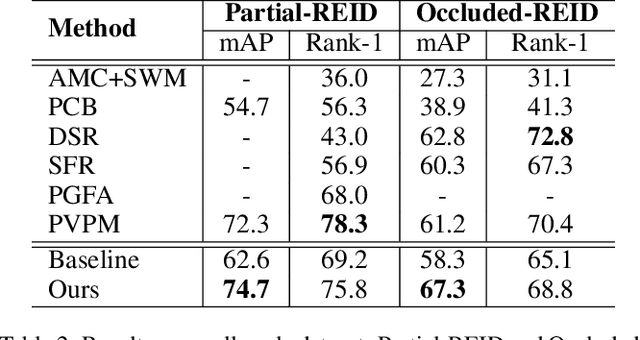
Person images captured by surveillance cameras are often occluded by various obstacles, which lead to defective feature representation and harm person re-identification (Re-ID) performance. To tackle this challenge, we propose to reconstruct the feature representation of occluded parts by fully exploiting the information of its neighborhood in a gallery image set. Specifically, we first introduce a visible part-based feature by body mask for each person image. Then we identify its neighboring samples using the visible features and reconstruct the representation of the full body by an outlier-removable graph neural network with all the neighboring samples as input. Extensive experiments show that the proposed approach obtains significant improvements. In the large-scale Occluded-DukeMTMC benchmark, our approach achieves 64.2% mAP and 67.6% rank-1 accuracy which outperforms the state-of-the-art approaches by large margins, i.e.,20.4% and 12.5%, respectively, indicating the effectiveness of our method on occluded Re-ID problem.
Complementary Relation Contrastive Distillation
Mar 29, 2021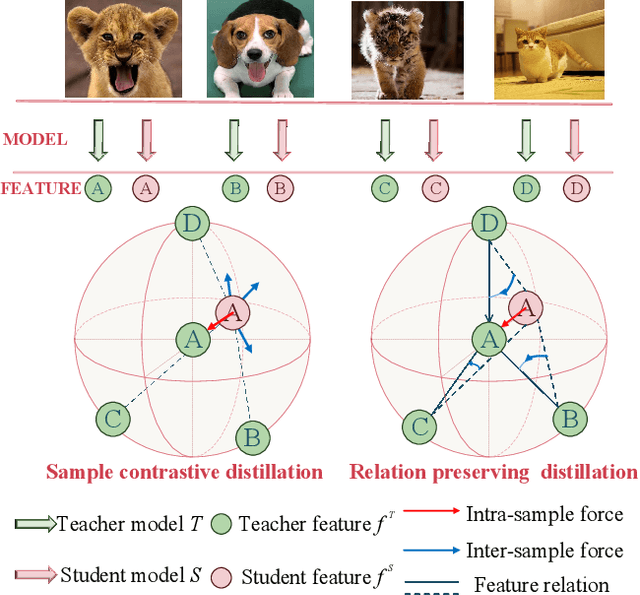
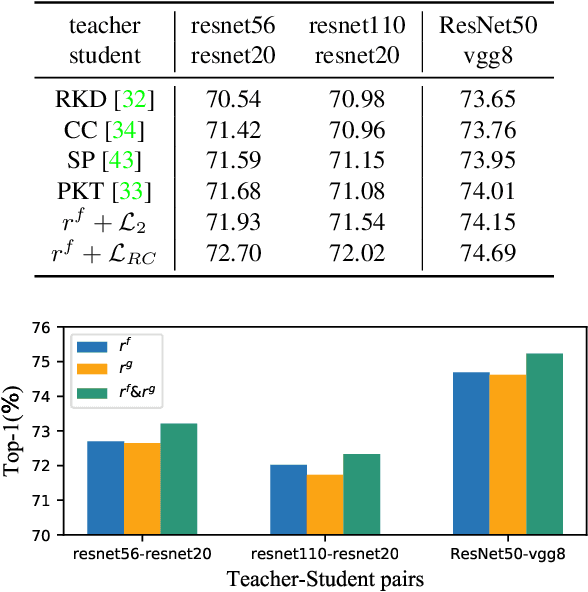
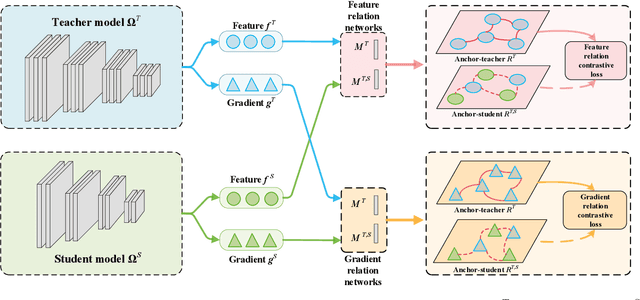

Knowledge distillation aims to transfer representation ability from a teacher model to a student model. Previous approaches focus on either individual representation distillation or inter-sample similarity preservation. While we argue that the inter-sample relation conveys abundant information and needs to be distilled in a more effective way. In this paper, we propose a novel knowledge distillation method, namely Complementary Relation Contrastive Distillation (CRCD), to transfer the structural knowledge from the teacher to the student. Specifically, we estimate the mutual relation in an anchor-based way and distill the anchor-student relation under the supervision of its corresponding anchor-teacher relation. To make it more robust, mutual relations are modeled by two complementary elements: the feature and its gradient. Furthermore, the low bound of mutual information between the anchor-teacher relation distribution and the anchor-student relation distribution is maximized via relation contrastive loss, which can distill both the sample representation and the inter-sample relations. Experiments on different benchmarks demonstrate the effectiveness of our proposed CRCD.
Gradient Regularized Contrastive Learning for Continual Domain Adaptation
Mar 23, 2021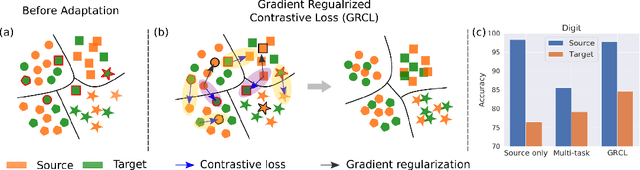
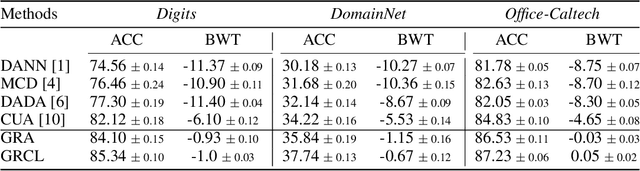
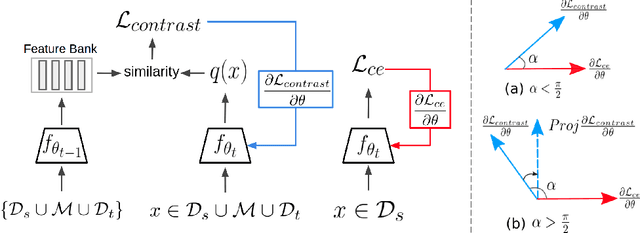

Human beings can quickly adapt to environmental changes by leveraging learning experience. However, adapting deep neural networks to dynamic environments by machine learning algorithms remains a challenge. To better understand this issue, we study the problem of continual domain adaptation, where the model is presented with a labelled source domain and a sequence of unlabelled target domains. The obstacles in this problem are both domain shift and catastrophic forgetting. We propose Gradient Regularized Contrastive Learning (GRCL) to solve the obstacles. At the core of our method, gradient regularization plays two key roles: (1) enforcing the gradient not to harm the discriminative ability of source features which can, in turn, benefit the adaptation ability of the model to target domains; (2) constraining the gradient not to increase the classification loss on old target domains, which enables the model to preserve the performance on old target domains when adapting to an in-coming target domain. Experiments on Digits, DomainNet and Office-Caltech benchmarks demonstrate the strong performance of our approach when compared to the other state-of-the-art methods.
Dynamic Graph: Learning Instance-aware Connectivity for Neural Networks
Oct 02, 2020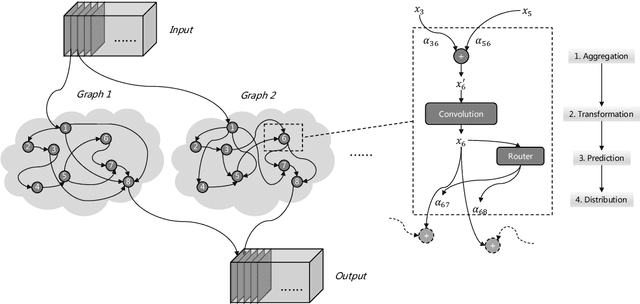
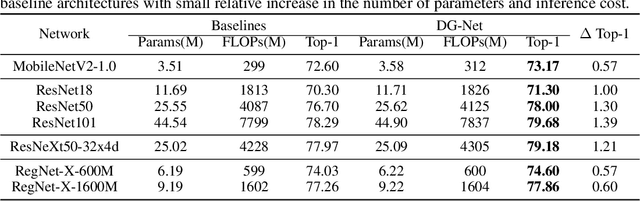
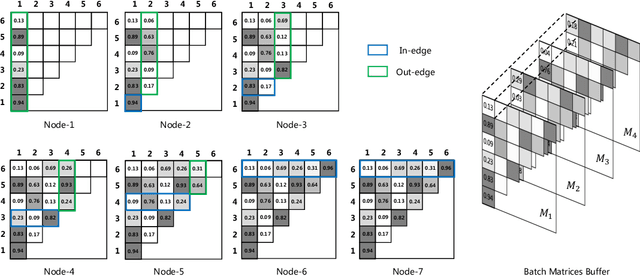
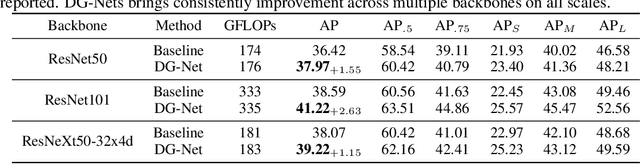
One practice of employing deep neural networks is to apply the same architecture to all the input instances. However, a fixed architecture may not be representative enough for data with high diversity. To promote the model capacity, existing approaches usually employ larger convolutional kernels or deeper network structure, which may increase the computational cost. In this paper, we address this issue by raising the Dynamic Graph Network (DG-Net). The network learns the instance-aware connectivity, which creates different forward paths for different instances. Specifically, the network is initialized as a complete directed acyclic graph, where the nodes represent convolutional blocks and the edges represent the connection paths. We generate edge weights by a learnable module \textit{router} and select the edges whose weights are larger than a threshold, to adjust the connectivity of the neural network structure. Instead of using the same path of the network, DG-Net aggregates features dynamically in each node, which allows the network to have more representation ability. To facilitate the training, we represent the network connectivity of each sample in an adjacency matrix. The matrix is updated to aggregate features in the forward pass, cached in the memory, and used for gradient computing in the backward pass. We verify the effectiveness of our method with several static architectures, including MobileNetV2, ResNet, ResNeXt, and RegNet. Extensive experiments are performed on ImageNet classification and COCO object detection, which shows the effectiveness and generalization ability of our approach.
Improved Mutual Mean-Teaching for Unsupervised Domain Adaptive Re-ID
Aug 24, 2020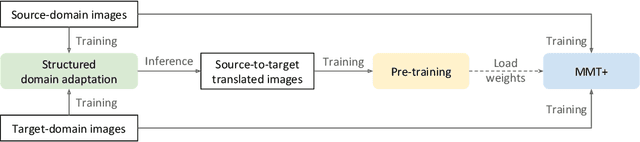



In this technical report, we present our submission to the VisDA Challenge in ECCV 2020 and we achieved one of the top-performing results on the leaderboard. Our solution is based on Structured Domain Adaptation (SDA) and Mutual Mean-Teaching (MMT) frameworks. SDA, a domain-translation-based framework, focuses on carefully translating the source-domain images to the target domain. MMT, a pseudo-label-based framework, focuses on conducting pseudo label refinery with robust soft labels. Specifically, there are three main steps in our training pipeline. (i) We adopt SDA to generate source-to-target translated images, and (ii) such images serve as informative training samples to pre-train the network. (iii) The pre-trained network is further fine-tuned by MMT on the target domain. Note that we design an improved MMT (dubbed MMT+) to further mitigate the label noise by modeling inter-sample relations across two domains and maintaining the instance discrimination. Our proposed method achieved 74.78% accuracies in terms of mAP, ranked the 2nd place out of 153 teams.
Continual Representation Learning for Biometric Identification
Jun 28, 2020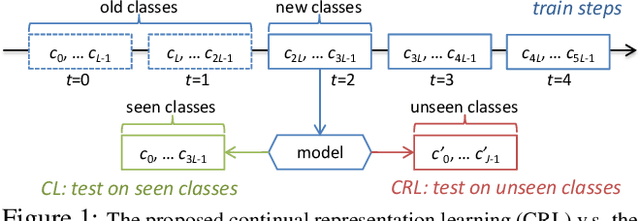
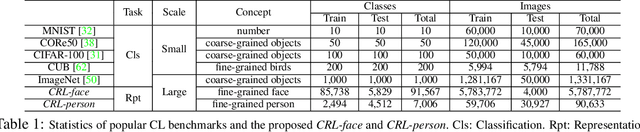
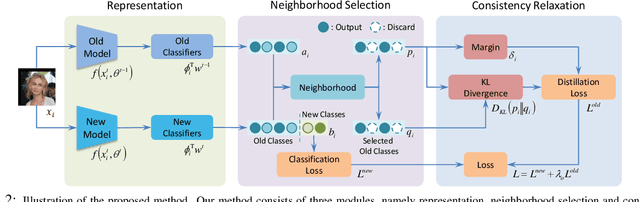

With the explosion of digital data in recent years, continuously learning new tasks from a stream of data without forgetting previously acquired knowledge has become increasingly important. In this paper, we propose a new continual learning (CL) setting, namely ``continual representation learning'', which focuses on learning better representation in a continuous way. We also provide two large-scale multi-step benchmarks for biometric identification, where the visual appearance of different classes are highly relevant. In contrast to requiring the model to recognize more learned classes, we aim to learn feature representation that can be better generalized to not only previously unseen images but also unseen classes/identities. For the new setting, we propose a novel approach that performs the knowledge distillation over a large number of identities by applying the neighbourhood selection and consistency relaxation strategies to improve scalability and flexibility of the continual learning model. We demonstrate that existing CL methods can improve the representation in the new setting, and our method achieves better results than the competitors.
Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID
Jun 04, 2020

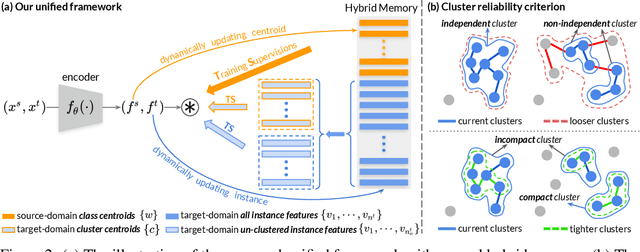
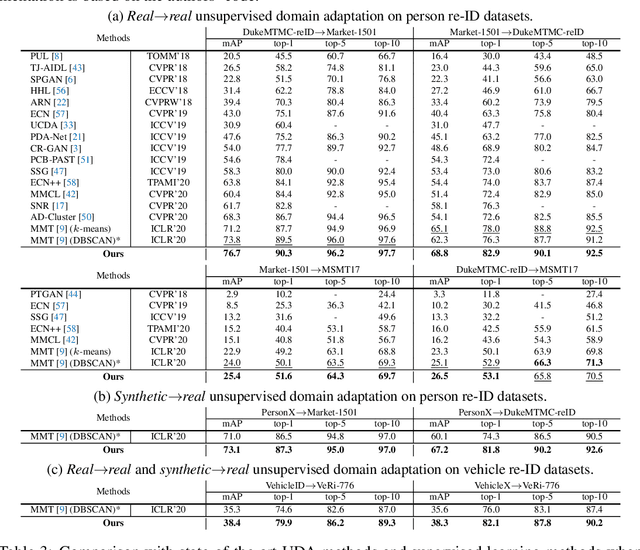
Domain adaptive object re-ID aims to transfer the learned knowledge from the labeled source domain to the unlabeled target domain to tackle the open-class re-identification problems. Although state-of-the-art pseudo-label-based methods have achieved great success, they did not make full use of all valuable information because of the domain gap and unsatisfying clustering performance. To solve these problems, we propose a novel self-paced contrastive learning framework with hybrid memory. The hybrid memory dynamically generates source-domain class-level, target-domain cluster-level and un-clustered instance-level supervisory signals for learning feature representations. Different from the conventional contrastive learning strategy, the proposed framework jointly distinguishes source-domain classes, and target-domain clusters and un-clustered instances. Most importantly, the proposed self-paced method gradually creates more reliable clusters to refine the hybrid memory and learning targets, and is shown to be the key to our outstanding performance. Our method outperforms state-of-the-arts on multiple domain adaptation tasks of object re-ID and even boosts the performance on the source domain without any extra annotations. Our generalized version on unsupervised person re-ID surpasses state-of-the-art algorithms by considerable 16.2% and 14.6% on Market-1501 and DukeMTMC-reID benchmarks. Code is available at https://github.com/yxgeee/SpCL.
COCAS: A Large-Scale Clothes Changing Person Dataset for Re-identification
May 16, 2020

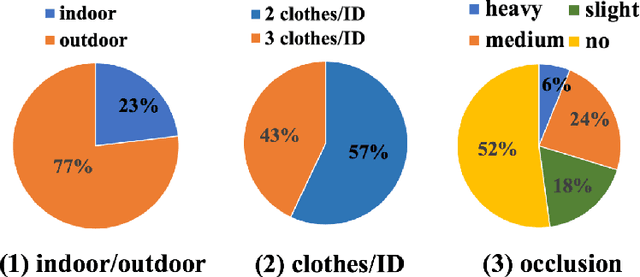
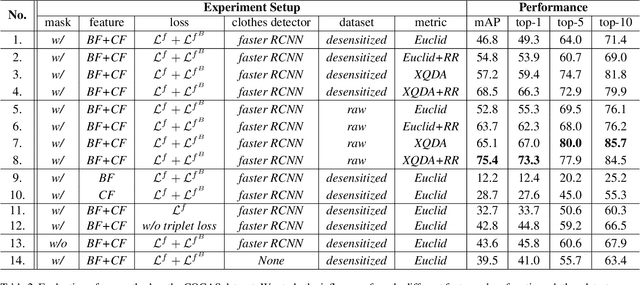
Recent years have witnessed great progress in person re-identification (re-id). Several academic benchmarks such as Market1501, CUHK03 and DukeMTMC play important roles to promote the re-id research. To our best knowledge, all the existing benchmarks assume the same person will have the same clothes. While in real-world scenarios, it is very often for a person to change clothes. To address the clothes changing person re-id problem, we construct a novel large-scale re-id benchmark named ClOthes ChAnging Person Set (COCAS), which provides multiple images of the same identity with different clothes. COCAS totally contains 62,382 body images from 5,266 persons. Based on COCAS, we introduce a new person re-id setting for clothes changing problem, where the query includes both a clothes template and a person image taking another clothes. Moreover, we propose a two-branch network named Biometric-Clothes Network (BC-Net) which can effectively integrate biometric and clothes feature for re-id under our setting. Experiments show that it is feasible for clothes changing re-id with clothes templates.
Learning to Cluster Faces via Confidence and Connectivity Estimation
Apr 03, 2020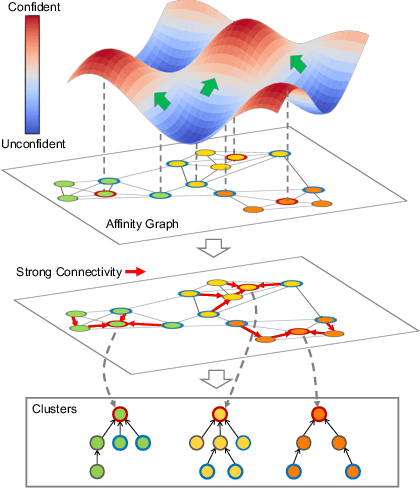
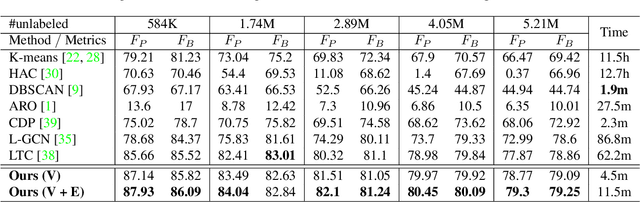
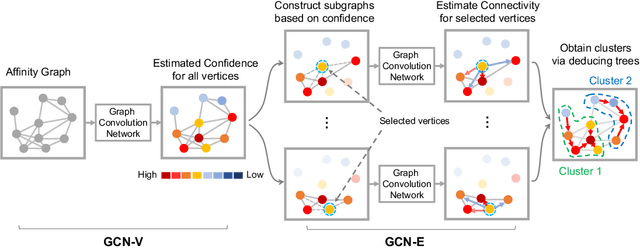
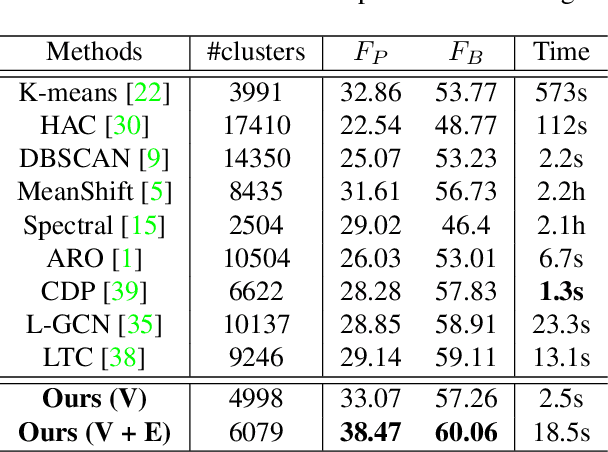
Face clustering is an essential tool for exploiting the unlabeled face data, and has a wide range of applications including face annotation and retrieval. Recent works show that supervised clustering can result in noticeable performance gain. However, they usually involve heuristic steps and require numerous overlapped subgraphs, severely restricting their accuracy and efficiency. In this paper, we propose a fully learnable clustering framework without requiring a large number of overlapped subgraphs. Instead, we transform the clustering problem into two sub-problems. Specifically, two graph convolutional networks, named GCN-V and GCN-E, are designed to estimate the confidence of vertices and the connectivity of edges, respectively. With the vertex confidence and edge connectivity, we can naturally organize more relevant vertices on the affinity graph and group them into clusters. Experiments on two large-scale benchmarks show that our method significantly improves clustering accuracy and thus performance of the recognition models trained on top, yet it is an order of magnitude more efficient than existing supervised methods.