 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-Based Policy Search Using Monte Carlo Gradient Estimation with Real Systems Application
Jan 28, 2021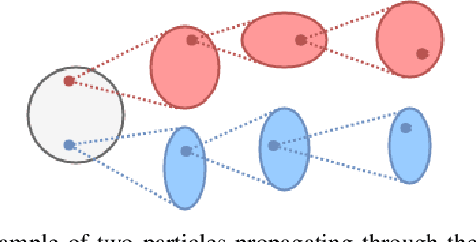
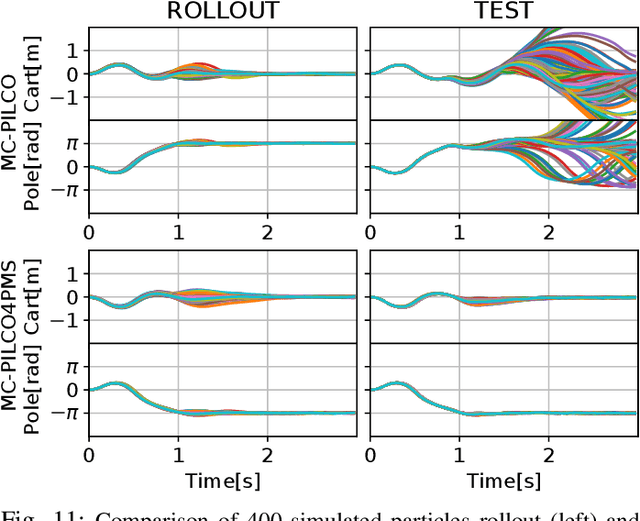

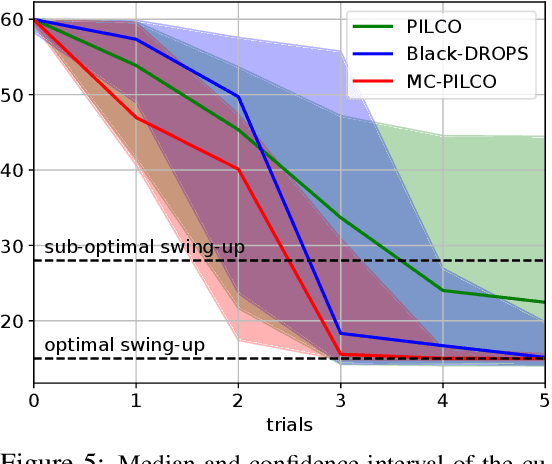
In this paper, we present a Model-Based Reinforcement Learning algorithm named Monte Carlo Probabilistic Inference for Learning COntrol (MC-PILCO). The algorithm relies on Gaussian Processes (GPs) to model the system dynamics and on a Monte Carlo approach to estimate the policy gradient. This defines a framework in which we ablate the choice of the following components: (i) the selection of the cost function, (ii) the optimization of policies using dropout, (iii) an improved data efficiency through the use of structured kernels in the GP models. The combination of the aforementioned aspects affects dramatically the performance of MC-PILCO. Numerical comparisons in a simulated cart-pole environment show that MC-PILCO exhibits better data-efficiency and control performance w.r.t. state-of-the-art GP-based MBRL algorithms. Finally, we apply MC-PILCO to real systems, considering in particular systems with partially measurable states. We discuss the importance of modeling both the measurement system and the state estimators during policy optimization. The effectiveness of the proposed solutions has been tested in simulation and in two real systems, a Furuta pendulum and a ball-and-plate.
Model-based Policy Search for Partially Measurable Systems
Jan 21, 2021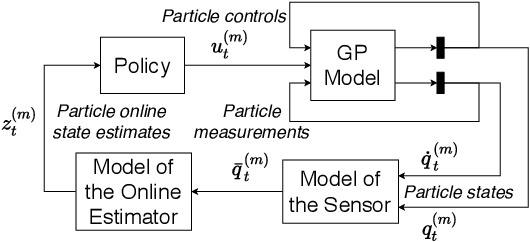

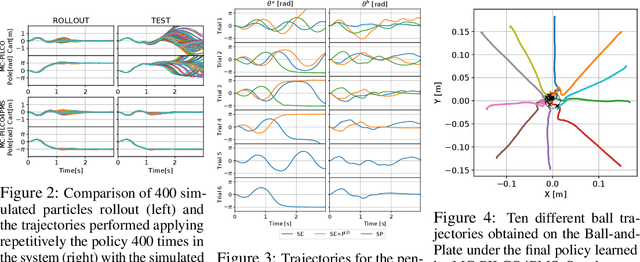
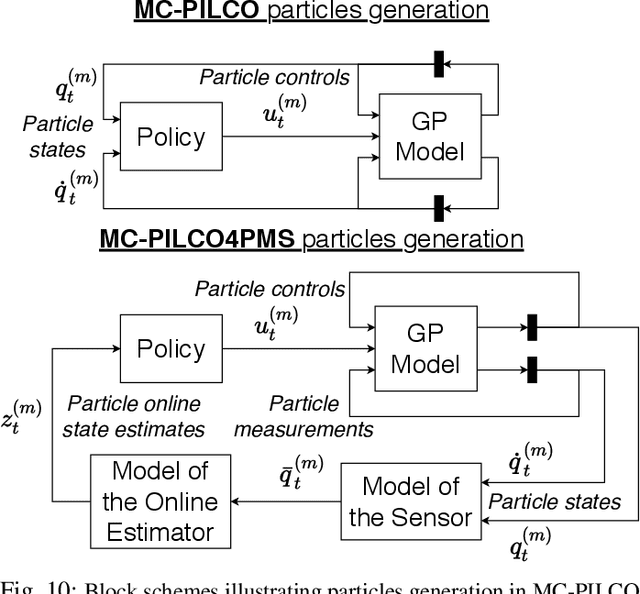
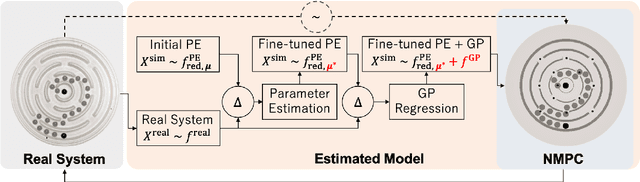
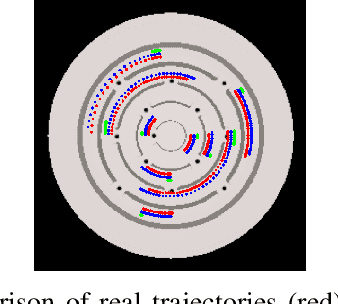
In this paper, we propose a Model-Based Reinforcement Learning (MBRL) algorithm for Partially Measurable Systems (PMS), i.e., systems where the state can not be directly measured, but must be estimated through proper state observers. The proposed algorithm, named Monte Carlo Probabilistic Inference for Learning COntrol for Partially Measurable Systems (MC-PILCO4PMS), relies on Gaussian Processes (GPs) to model the system dynamics, and on a Monte Carlo approach to update the policy parameters. W.r.t. previous GP-based MBRL algorithms, MC-PILCO4PMS models explicitly the presence of state observers during policy optimization, allowing to deal PMS. The effectiveness of the proposed algorithm has been tested both in simulation and in two real systems.
Towards Human-Level Learning of Complex Physical Puzzles
Nov 14, 2020
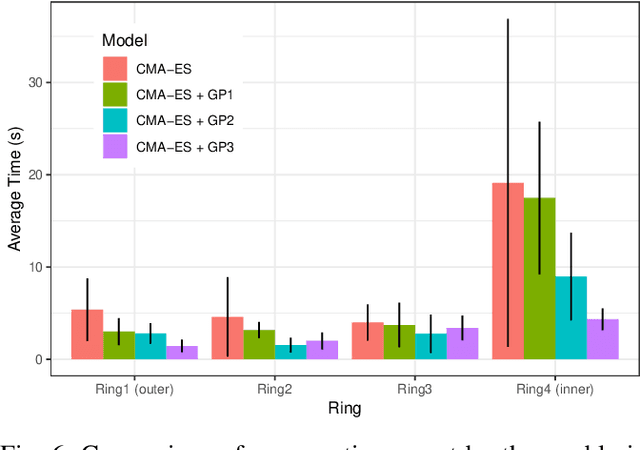
Humans quickly solve tasks in novel systems with complex dynamics, without requiring much interaction. While deep reinforcement learning algorithms have achieved tremendous success in many complex tasks, these algorithms need a large number of samples to learn meaningful policies. In this paper, we present a task for navigating a marble to the center of a circular maze. While this system is very intuitive and easy for humans to solve, it can be very difficult and inefficient for standard reinforcement learning algorithms to learn meaningful policies. We present a model that learns to move a marble in the complex environment within minutes of interacting with the real system. Learning consists of initializing a physics engine with parameters estimated using data from the real system. The error in the physics engine is then corrected using Gaussian process regression, which is used to model the residual between real observations and physics engine simulations. The physics engine equipped with the residual model is then used to control the marble in the maze environment using a model-predictive feedback over a receding horizon. We contrast the learning behavior against the time taken by humans to solve the problem to show comparable behavior. To the best of our knowledge, this is the first time that a hybrid model consisting of a full physics engine along with a statistical function approximator has been used to control a complex physical system in real-time using nonlinear model-predictive control (NMPC). Codes for the simulation environment can be downloaded here https://www.merl.com/research/license/CME . A video describing our method could be found here https://youtu.be/xaxNCXBovpc .
Deep Reactive Planning in Dynamic Environments
Nov 05, 2020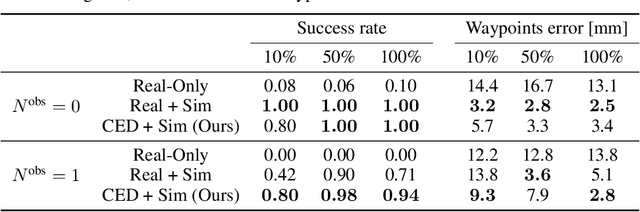
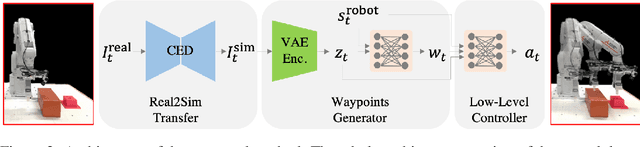


The main novelty of the proposed approach is that it allows a robot to learn an end-to-end policy which can adapt to changes in the environment during execution. While goal conditioning of policies has been studied in the RL literature, such approaches are not easily extended to cases where the robot's goal can change during execution. This is something that humans are naturally able to do. However, it is difficult for robots to learn such reflexes (i.e., to naturally respond to dynamic environments), especially when the goal location is not explicitly provided to the robot, and instead needs to be perceived through a vision sensor. In the current work, we present a method that can achieve such behavior by combining traditional kinematic planning, deep learning, and deep reinforcement learning in a synergistic fashion to generalize to arbitrary environments. We demonstrate the proposed approach for several reaching and pick-and-place tasks in simulation, as well as on a real system of a 6-DoF industrial manipulator. A video describing our work could be found \url{https://youtu.be/hE-Ew59GRPQ}.
Understanding Multi-Modal Perception Using Behavioral Cloning for Peg-In-a-Hole Insertion Tasks
Jul 22, 2020
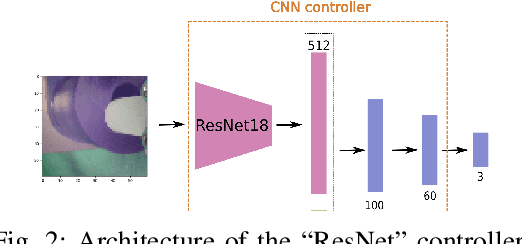
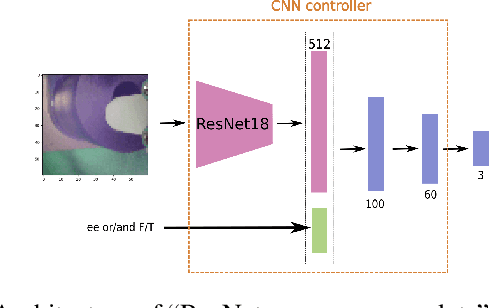
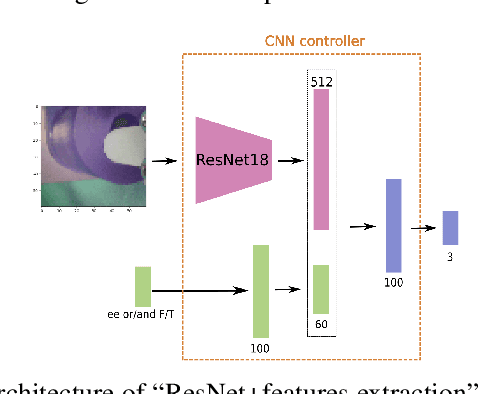
One of the main challenges in peg-in-a-hole (PiH) insertion tasks is in handling the uncertainty in the location of the target hole. In order to address it, high-dimensional sensor inputs from sensor modalities such as vision, force/torque sensing, and proprioception can be combined to learn control policies that are robust to this uncertainty in the target pose. Whereas deep learning has shown success in recognizing objects and making decisions with high-dimensional inputs, the learning procedure might damage the robot when applying directly trial- and-error algorithms on the real system. At the same time, learning from Demonstration (LfD) methods have been shown to achieve compelling performance in real robotic systems by leveraging demonstration data provided by experts. In this paper, we investigate the merits of multiple sensor modalities such as vision, force/torque sensors, and proprioception when combined to learn a controller for real world assembly operation tasks using LfD techniques. The study is limited to PiH insertions; we plan to extend the study to more experiments in the future. Additionally, we propose a multi-step-ahead loss function to improve the performance of the behavioral cloning method. Experimental results on a real manipulator support our findings, and show the effectiveness of the proposed loss function.
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
Mar 03, 2020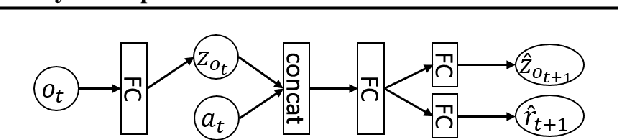

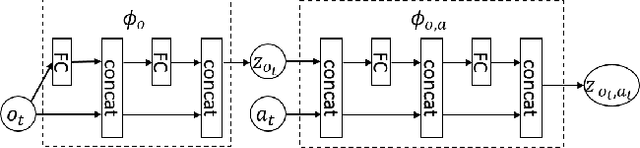
Deep reinforcement learning (RL) algorithms have recently achieved remarkable successes in various sequential decision making tasks, leveraging advances in methods for training large deep networks. However, these methods usually require large amounts of training data, which is often a big problem for real-world applications. One natural question to ask is whether learning good representations for states and using larger networks helps in learning better policies. In this paper, we try to study if increasing input dimensionality helps improve performance and sample efficiency of model-free deep RL algorithms. To do so, we propose an online feature extractor network (OFENet) that uses neural nets to produce good representations to be used as inputs to deep RL algorithms. Even though the high dimensionality of input is usually supposed to make learning of RL agents more difficult, we show that the RL agents in fact learn more efficiently with the high-dimensional representation than with the lower-dimensional state observations. We believe that stronger feature propagation together with larger networks (and thus larger search space) allows RL agents to learn more complex functions of states and thus improves the sample efficiency. Through numerical experiments, we show that the proposed method outperforms several other state-of-the-art algorithms in terms of both sample efficiency and performance.
Model-Based Reinforcement Learning for Physical Systems Without Velocity and Acceleration Measurements
Feb 25, 2020
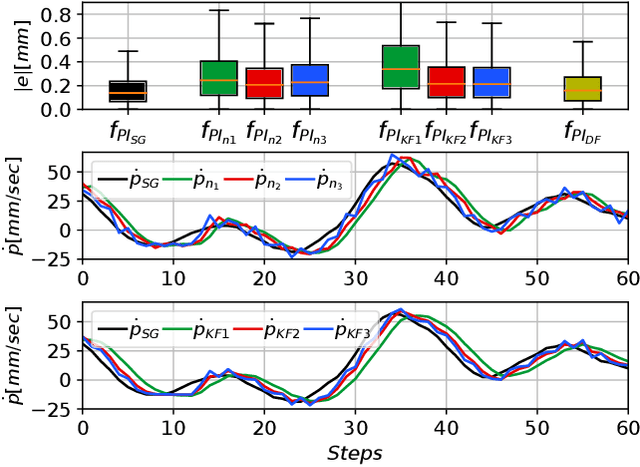
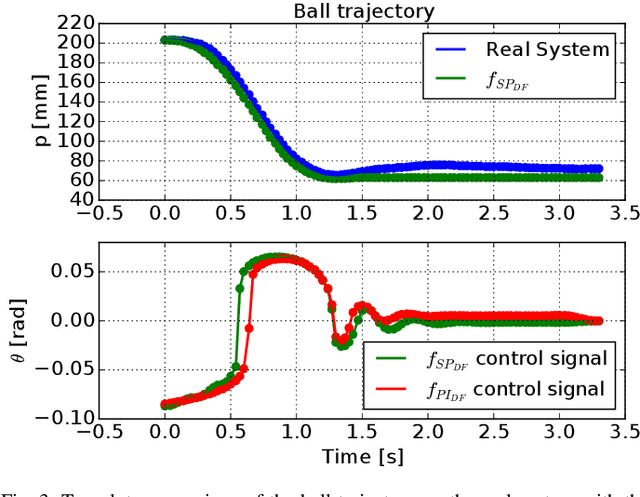
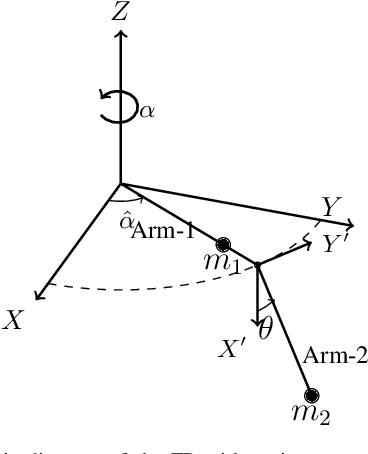
In this paper, we propose a derivative-free model learning framework for Reinforcement Learning (RL) algorithms based on Gaussian Process Regression (GPR). In many mechanical systems, only positions can be measured by the sensing instruments. Then, instead of representing the system state as suggested by the physics with a collection of positions, velocities, and accelerations, we define the state as the set of past position measurements. However, the equation of motions derived by physical first principles cannot be directly applied in this framework, being functions of velocities and accelerations. For this reason, we introduce a novel derivative-free physically-inspired kernel, which can be easily combined with nonparametric derivative-free Gaussian Process models. Tests performed on two real platforms show that the considered state definition combined with the proposed model improves estimation performance and data-efficiency w.r.t. traditional models based on GPR. Finally, we validate the proposed framework by solving two RL control problems for two real robotic systems.
Multi-label Prediction in Time Series Data using Deep Neural Networks
Jan 27, 2020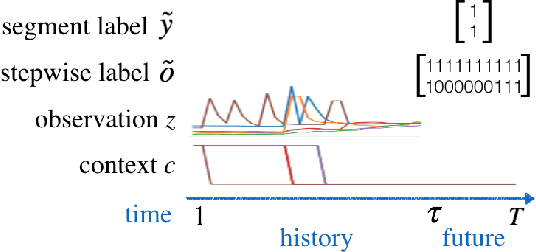

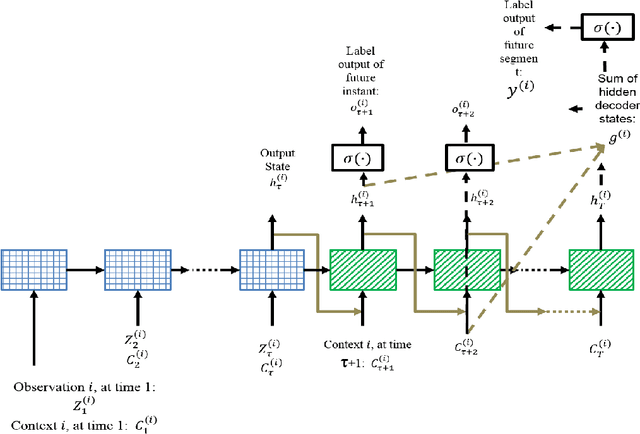
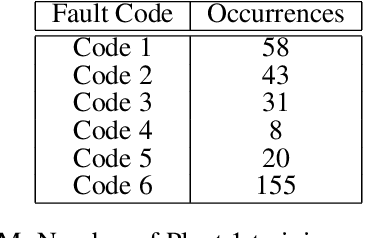
This paper addresses a multi-label predictive fault classification problem for multidimensional time-series data. While fault (event) detection problems have been thoroughly studied in literature, most of the state-of-the-art techniques can't reliably predict faults (events) over a desired future horizon. In the most general setting of these types of problems, one or more samples of data across multiple time series can be assigned several concurrent fault labels from a finite, known set and the task is to predict the possibility of fault occurrence over a desired time horizon. This type of problem is usually accompanied by strong class imbalances where some classes are represented by only a few samples. Importantly, in many applications of the problem such as fault prediction and predictive maintenance, it is exactly these rare classes that are of most interest. To address the problem, this paper proposes a general approach that utilizes a multi-label recurrent neural network with a new cost function that accentuates learning in the imbalanced classes. The proposed algorithm is tested on two public benchmark datasets: an industrial plant dataset from the PHM Society Data Challenge, and a human activity recognition dataset. The results are compared with state-of-the-art techniques for time-series classification and evaluation is performed using the F1-score, precision and recall.
Local Policy Optimization for Trajectory-Centric Reinforcement Learning
Jan 22, 2020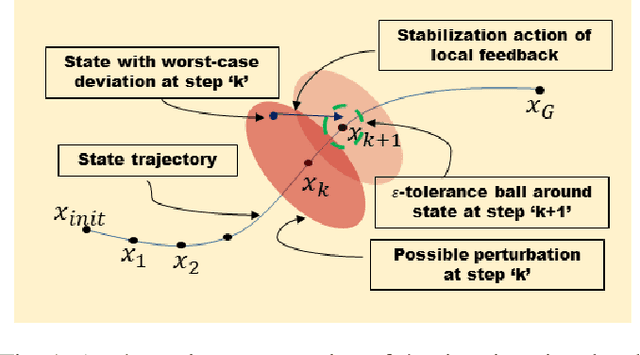
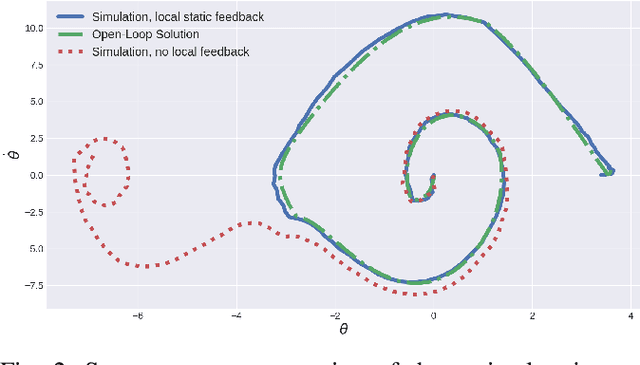
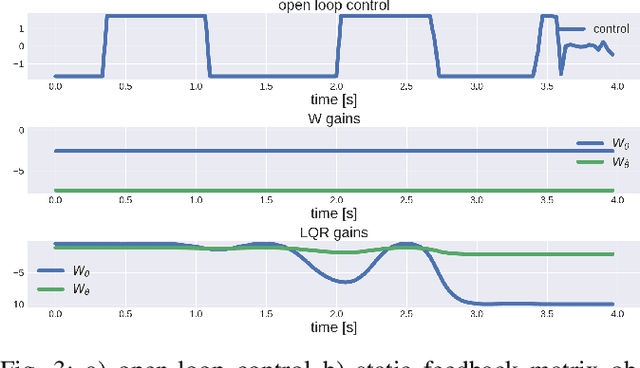
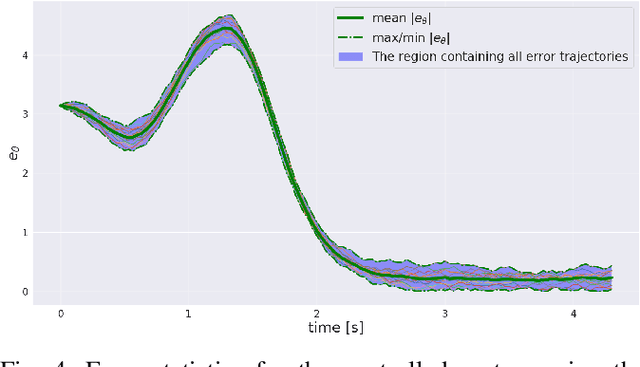
The goal of this paper is to present a method for simultaneous trajectory and local stabilizing policy optimization to generate local policies for trajectory-centric model-based reinforcement learning (MBRL). This is motivated by the fact that global policy optimization for non-linear systems could be a very challenging problem both algorithmically and numerically. However, a lot of robotic manipulation tasks are trajectory-centric, and thus do not require a global model or policy. Due to inaccuracies in the learned model estimates, an open-loop trajectory optimization process mostly results in very poor performance when used on the real system. Motivated by these problems, we try to formulate the problem of trajectory optimization and local policy synthesis as a single optimization problem. It is then solved simultaneously as an instance of nonlinear programming. We provide some results for analysis as well as achieved performance of the proposed technique under some simplifying assumptions.
Learning Deep Parameterized Skills from Demonstration for Re-targetable Visuomotor Control
Oct 23, 2019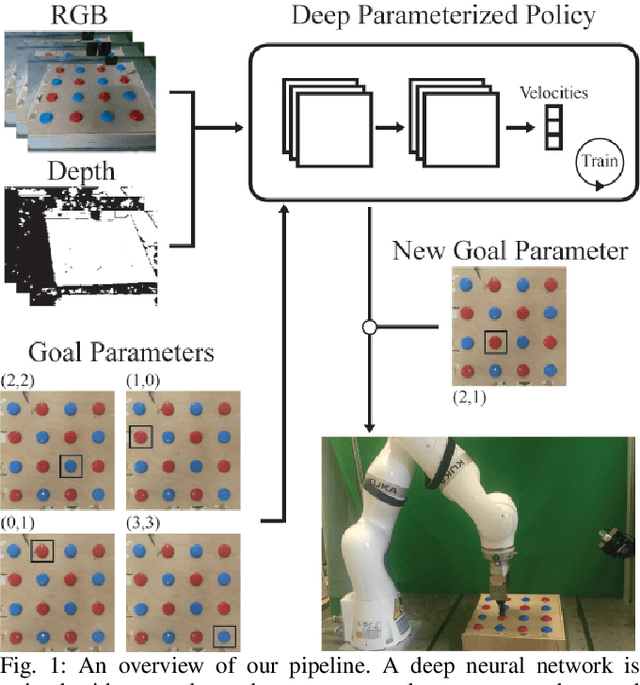
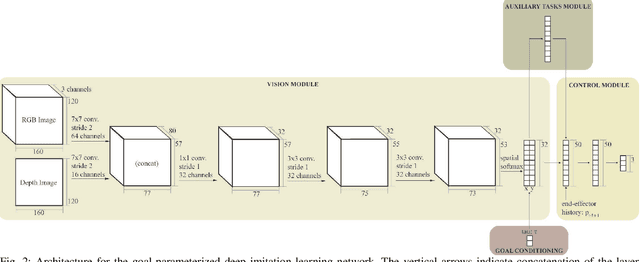
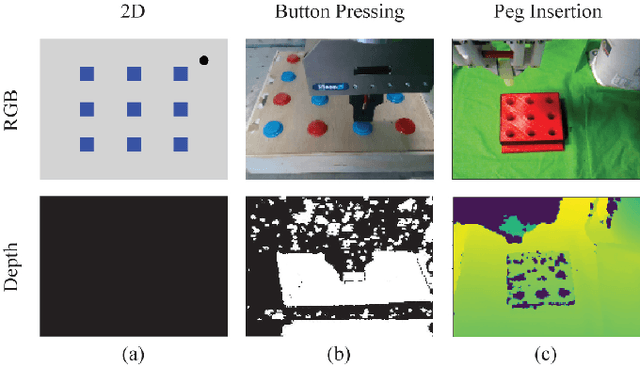
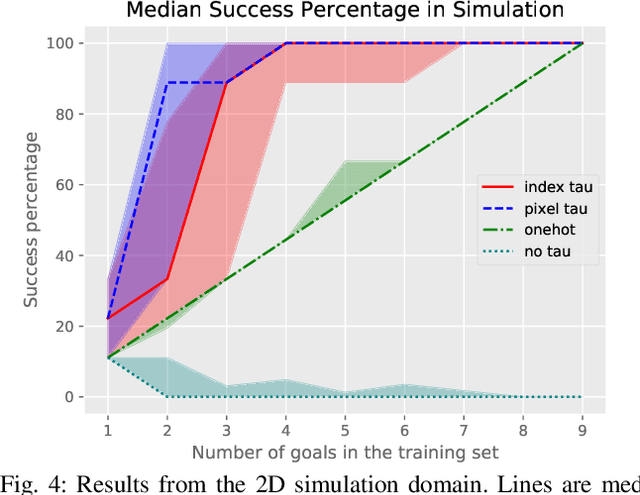
Robots need to learn skills that can not only generalize across similar problems but also be directed to a specific goal. Previous methods either train a new skill for every different goal or do not infer the specific target in the presence of multiple goals from visual data. We introduce an end-to-end method that represents targetable visuomotor skills as a goal-parameterized neural network policy. By training on an informative subset of available goals with the associated target parameters, we are able to learn a policy that can zero-shot generalize to previously unseen goals. We evaluate our method in a representative 2D simulation of a button-grid and on both button-pressing and peg-insertion tasks on two different physical arms. We demonstrate that our model trained on 33% of the possible goals is able to generalize to more than 90% of the targets in the scene for both simulation and robot experiments. We also successfully learn a mapping from target pixel coordinates to a robot policy to complete a specified goal.