 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHistogram of Oriented Gradients Meet Deep Learning: A Novel Multi-task Deep Network for Medical Image Semantic Segmentation
Apr 02, 2022
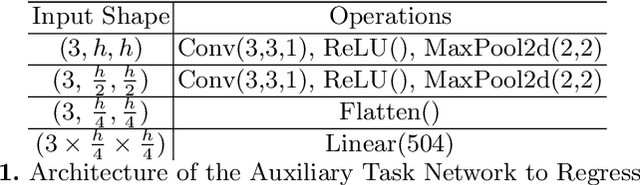
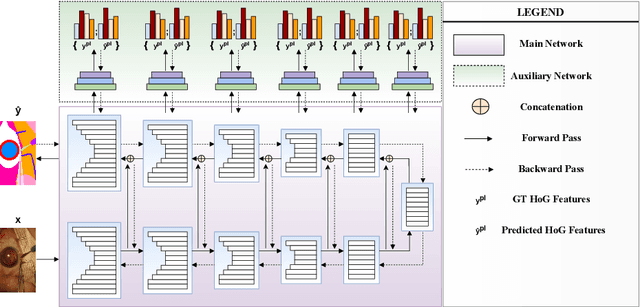
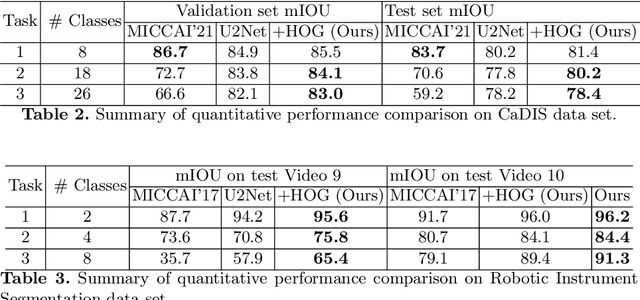
We present our novel deep multi-task learning method for medical image segmentation. Existing multi-task methods demand ground truth annotations for both the primary and auxiliary tasks. Contrary to it, we propose to generate the pseudo-labels of an auxiliary task in an unsupervised manner. To generate the pseudo-labels, we leverage Histogram of Oriented Gradients (HOGs), one of the most widely used and powerful hand-crafted features for detection. Together with the ground truth semantic segmentation masks for the primary task and pseudo-labels for the auxiliary task, we learn the parameters of the deep network to minimise the loss of both the primary task and the auxiliary task jointly. We employed our method on two powerful and widely used semantic segmentation networks: UNet and U2Net to train in a multi-task setup. To validate our hypothesis, we performed experiments on two different medical image segmentation data sets. From the extensive quantitative and qualitative results, we observe that our method consistently improves the performance compared to the counter-part method. Moreover, our method is the winner of FetReg Endovis Sub-challenge on Semantic Segmentation organised in conjunction with MICCAI 2021.
A Temporal Learning Approach to Inpainting Endoscopic Specularities and Its effect on Image Correspondence
Mar 31, 2022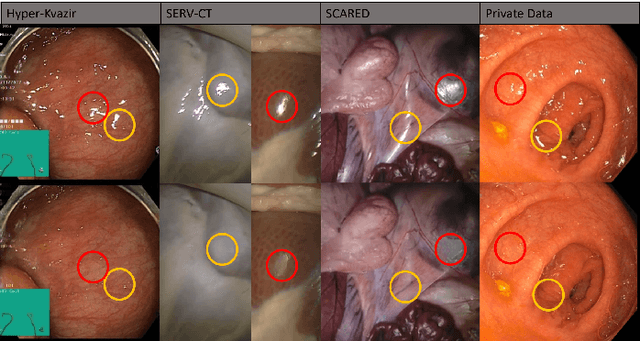
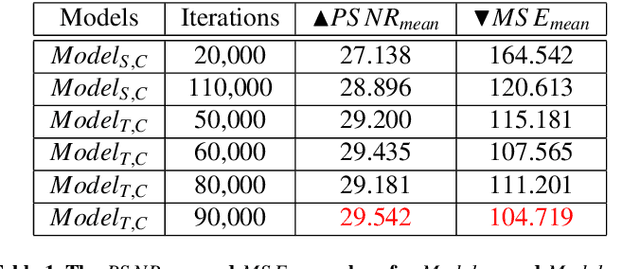
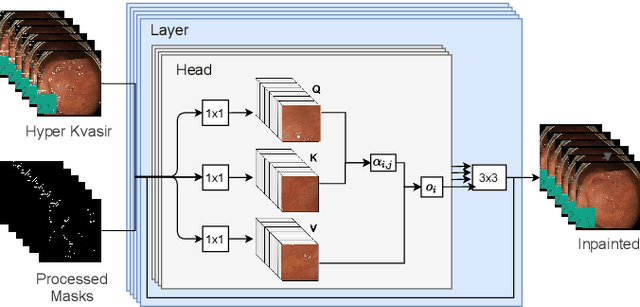
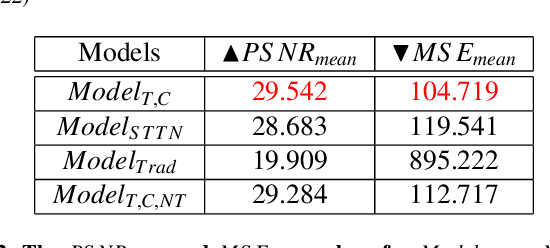
Video streams are utilised to guide minimally-invasive surgery and diagnostic procedures in a wide range of procedures, and many computer assisted techniques have been developed to automatically analyse them. These approaches can provide additional information to the surgeon such as lesion detection, instrument navigation, or anatomy 3D shape modeling. However, the necessary image features to recognise these patterns are not always reliably detected due to the presence of irregular light patterns such as specular highlight reflections. In this paper, we aim at removing specular highlights from endoscopic videos using machine learning. We propose using a temporal generative adversarial network (GAN) to inpaint the hidden anatomy under specularities, inferring its appearance spatially and from neighbouring frames where they are not present in the same location. This is achieved using in-vivo data of gastric endoscopy (Hyper-Kvasir) in a fully unsupervised manner that relies on automatic detection of specular highlights. System evaluations show significant improvements to traditional methods through direct comparison as well as other machine learning techniques through an ablation study that depicts the importance of the network's temporal and transfer learning components. The generalizability of our system to different surgical setups and procedures was also evaluated qualitatively on in-vivo data of gastric endoscopy and ex-vivo porcine data (SERV-CT, SCARED). We also assess the effect of our method in computer vision tasks that underpin 3D reconstruction and camera motion estimation, namely stereo disparity, optical flow, and sparse point feature matching. These are evaluated quantitatively and qualitatively and results show a positive effect of specular highlight inpainting on these tasks in a novel comprehensive analysis.
Exploring Intra- and Inter-Video Relation for Surgical Semantic Scene Segmentation
Mar 29, 2022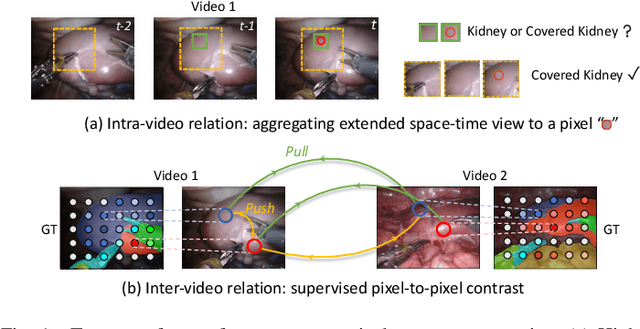
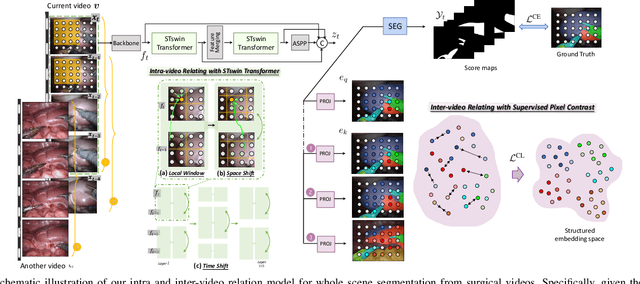
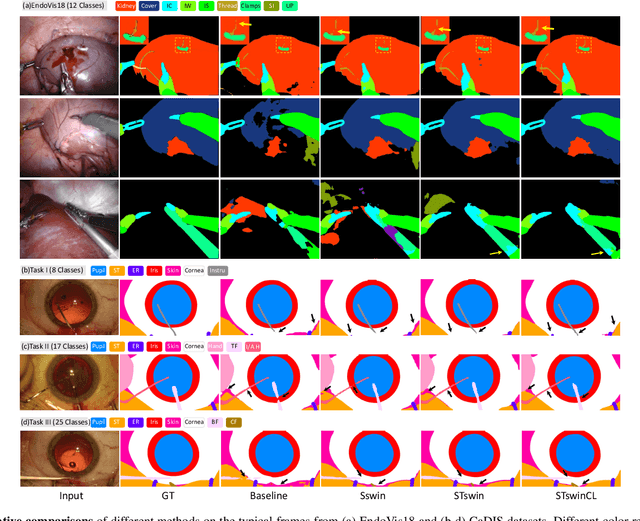

Automatic surgical scene segmentation is fundamental for facilitating cognitive intelligence in the modern operating theatre. Previous works rely on conventional aggregation modules (e.g., dilated convolution, convolutional LSTM), which only make use of the local context. In this paper, we propose a novel framework STswinCL that explores the complementary intra- and inter-video relations to boost segmentation performance, by progressively capturing the global context. We firstly develop a hierarchy Transformer to capture intra-video relation that includes richer spatial and temporal cues from neighbor pixels and previous frames. A joint space-time window shift scheme is proposed to efficiently aggregate these two cues into each pixel embedding. Then, we explore inter-video relation via pixel-to-pixel contrastive learning, which well structures the global embedding space. A multi-source contrast training objective is developed to group the pixel embeddings across videos with the ground-truth guidance, which is crucial for learning the global property of the whole data. We extensively validate our approach on two public surgical video benchmarks, including EndoVis18 Challenge and CaDIS dataset. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches. Code will be available at https://github.com/YuemingJin/STswinCL.
Organ Shape Sensing using Pneumatically Attachable Flexible Rails in Robotic-Assisted Laparoscopic Surgery
Feb 22, 2022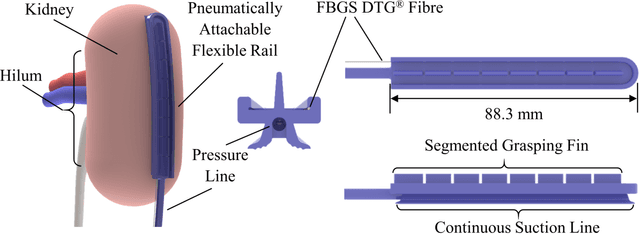
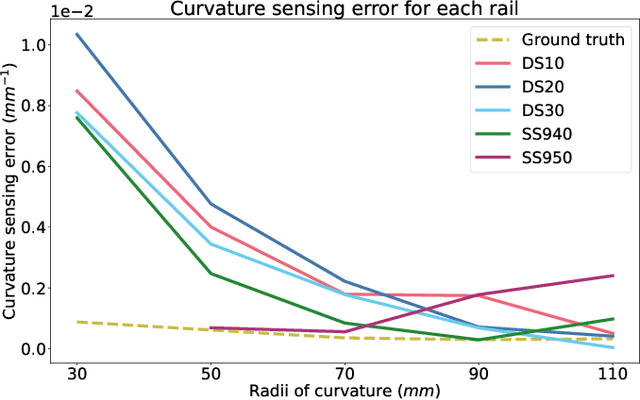
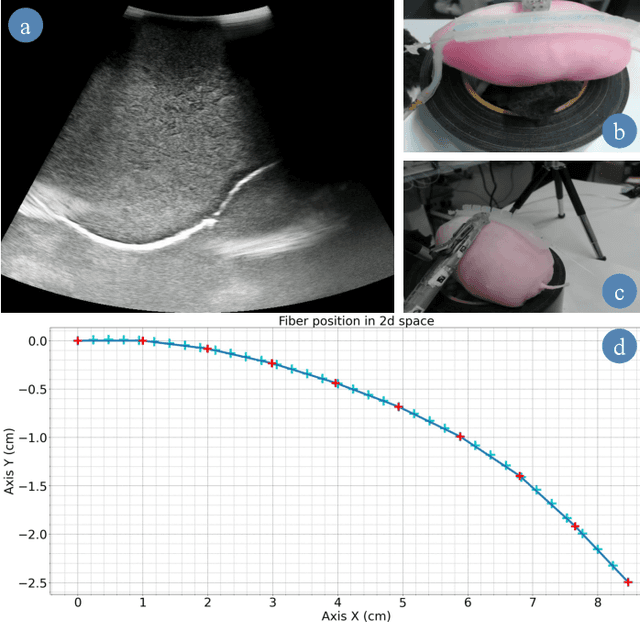
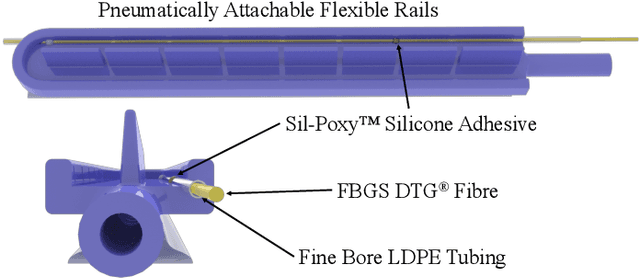
In robotic-assisted partial nephrectomy, surgeons remove a part of a kidney often due to the presence of a mass. A drop-in ultrasound probe paired to a surgical robot is deployed to execute multiple swipes over the kidney surface to localise the mass and define the margins of resection. This sub-task is challenging and must be performed by a highly skilled surgeon. Automating this sub-task may reduce cognitive load for the surgeon and improve patient outcomes. The overall goal of this work is to autonomously move the ultrasound probe on the surface of the kidney taking advantage of the use of the Pneumatically Attachable Flexible (PAF) rail system, a soft robotic device used for organ scanning and repositioning. First, we integrate a shape-sensing optical fibre into the PAF rail system to evaluate the curvature of target organs in robotic-assisted laparoscopic surgery. Then, we investigate the impact of the stiffness of the material of the PAF rail on the curvature sensing accuracy, considering that soft targets are present in the surgical field. Finally, we use shape sensing to plan the trajectory of the da Vinci surgical robot paired with a drop-in ultrasound probe and autonomously generate an Ultrasound scan of a kidney phantom.
A Novel Soft Shape-shifting Robot with Track-based Locomotion for In-pipe Inspection
Feb 22, 2022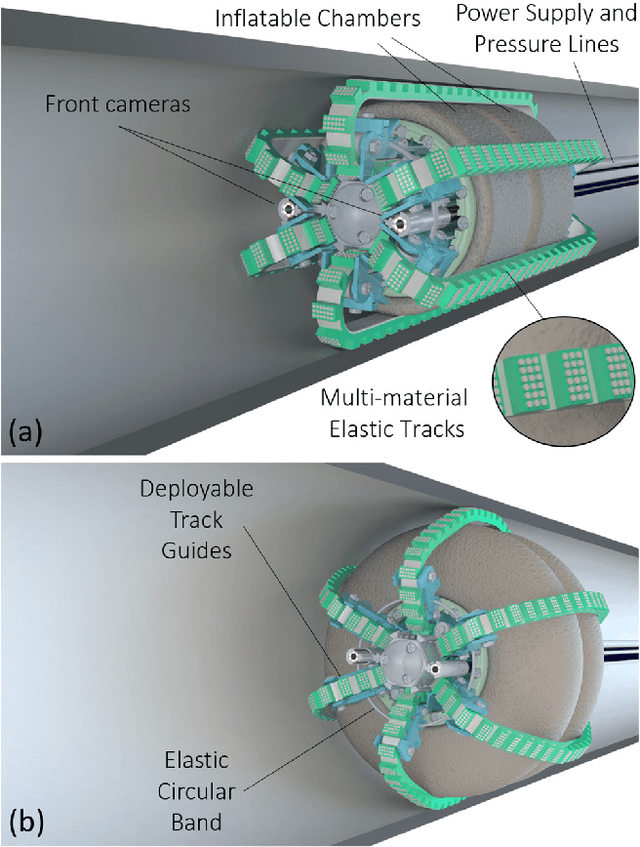
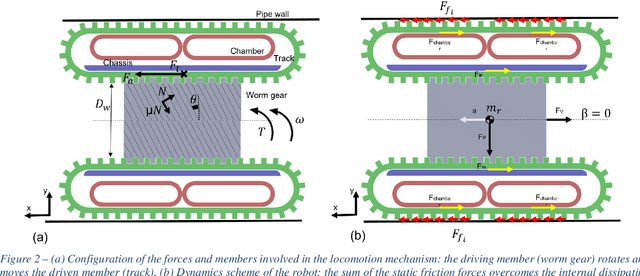
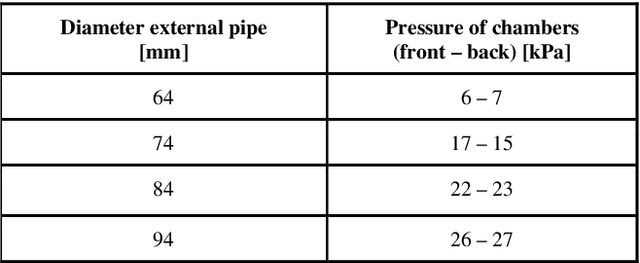
With the advent of soft robotics the research community has been exploring how to exploit the inherent adaptability of soft elastic materials to overcome the limitations of systems based on rigid materials. A proof-of-concept design of a crawling robot for pipe inspection and preliminary analysis of its locomotion capabilities are presented in this work. The novelty of the proposed design is the combination of silicone based elements of different stiffness to enable global shape reconfiguration and whole-body track-based locomotion. The proposed system makes use of a plurality of multi-materials elastic tracks actuated by an on-board motor through a worm gear that pairs with all of them, causing their constant eversion from the inside to the outside of the chassis of the robot. Two toroidal inflatable chambers surround the chassis of the robot while passing through the loops created by the tracks. Upon inflation of the chambers the tracks are deformed, changing the overall diameter of the system. This feature allows the system to adjust to the local diameter of the pipe navigated, enabling also active contact force control between the tracks and the pipe walls. We demonstrate how the proposed system efficiently moves through rigid pipes of different diameters, both straight and curved, incrementing its outer diameter up to 100% of his original size. Maximum navigation speed and stall force applied are evaluated. With two front cameras embedded, the proposed robotic system can represent a cost-effective and easy-to-control solution for inspection applications, when adaptability and compliance are critical requirements.
3D Shape Variational Autoencoder Latent Disentanglement via Mini-Batch Feature Swapping for Bodies and Faces
Nov 25, 2021
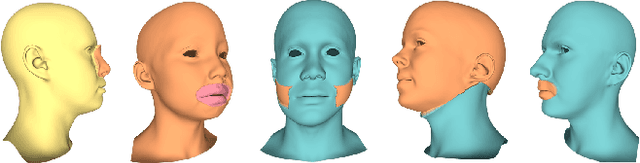

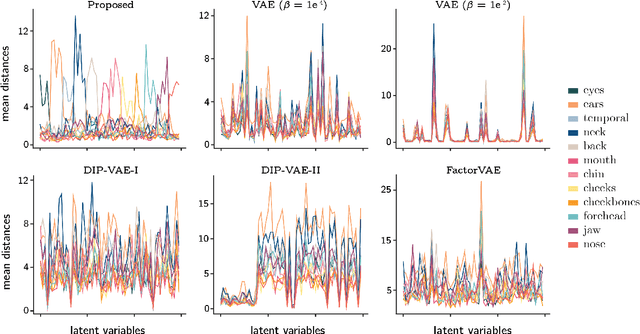
Learning a disentangled, interpretable, and structured latent representation in 3D generative models of faces and bodies is still an open problem. The problem is particularly acute when control over identity features is required. In this paper, we propose an intuitive yet effective self-supervised approach to train a 3D shape variational autoencoder (VAE) which encourages a disentangled latent representation of identity features. Curating the mini-batch generation by swapping arbitrary features across different shapes allows to define a loss function leveraging known differences and similarities in the latent representations. Experimental results conducted on 3D meshes show that state-of-the-art methods for latent disentanglement are not able to disentangle identity features of faces and bodies. Our proposed method properly decouples the generation of such features while maintaining good representation and reconstruction capabilities.
Towards intrinsic force sensing and control in parallel soft robots
Nov 19, 2021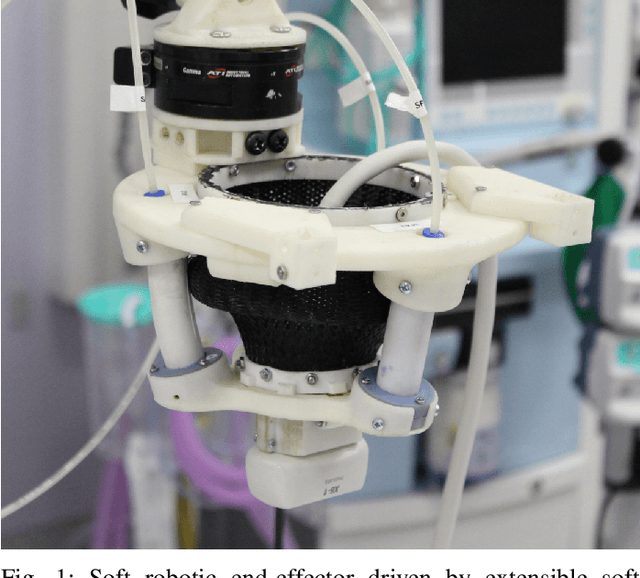
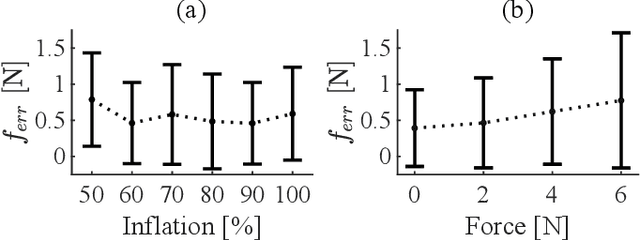
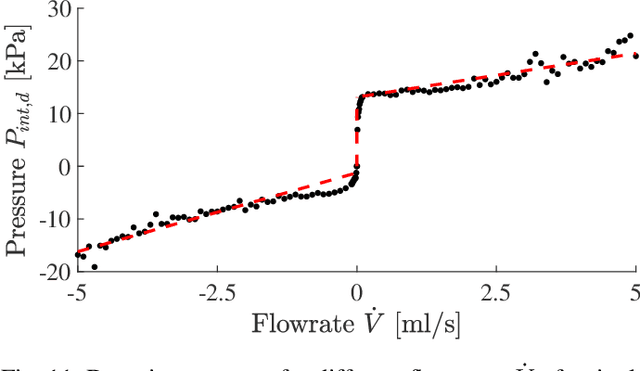
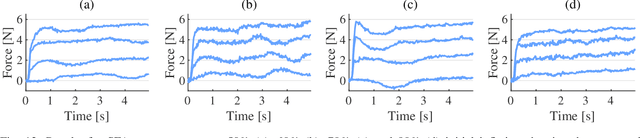
With soft robotics being increasingly employed in settings demanding high and controlled contact forces, recent research has demonstrated the use of soft robots to estimate or intrinsically sense forces without requiring external sensing mechanisms. Whilst this has mainly been shown in tendon-based continuum manipulators or deformable robots comprising of push-pull rod actuation, fluid drives still pose great challenges due to high actuation variability and nonlinear mechanical system responses. In this work we investigate the capabilities of a hydraulic, parallel soft robot to intrinsically sense and subsequently control contact forces. A comprehensive algorithm is derived for static, quasi-static and dynamic force sensing which relies on fluid volume and pressure information of the system. The algorithm is validated for a single degree-of-freedom soft fluidic actuator. Results indicate that axial forces acting on a single actuator can be estimated with an accuracy of 0.56 +- 0.66N within the validated range of 0 to 6N in a quasi-static configuration. The force sensing methodology is applied to force control in a single actuator as well as the coupled parallel robot. It can be seen that forces are accurately controllable for both systems, with the capability of controlling directional contact forces in case of the multi degree-of-freedom parallel soft robot.
2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021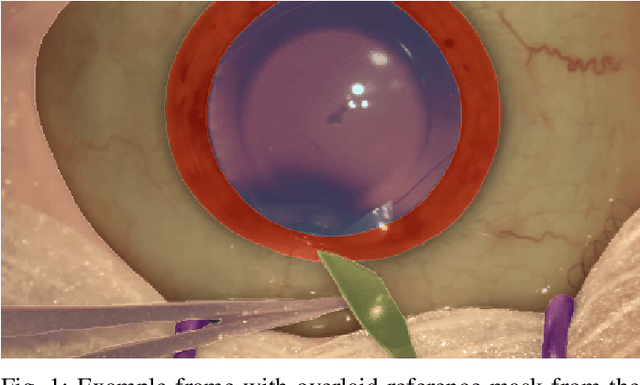
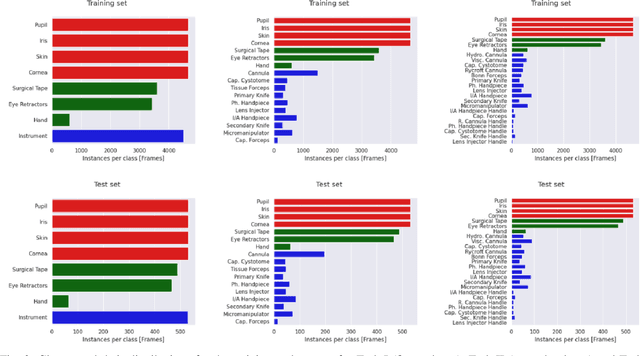
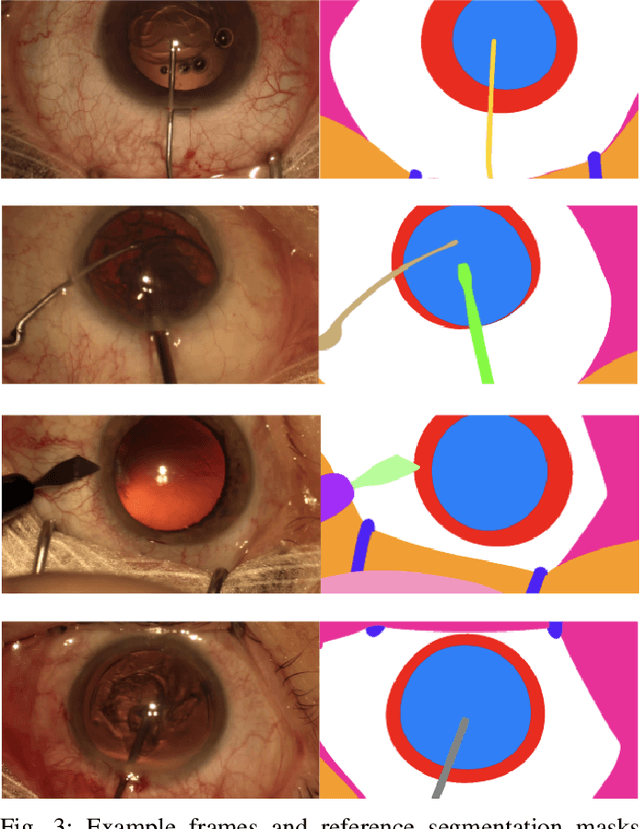
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.
AutoFB: Automating Fetal Biometry Estimation from Standard Ultrasound Planes
Jul 12, 2021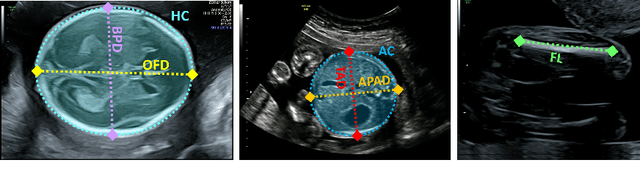
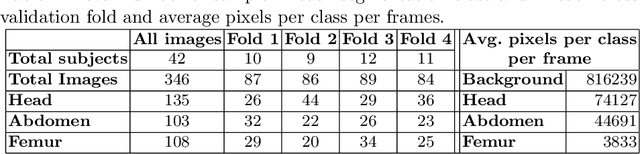
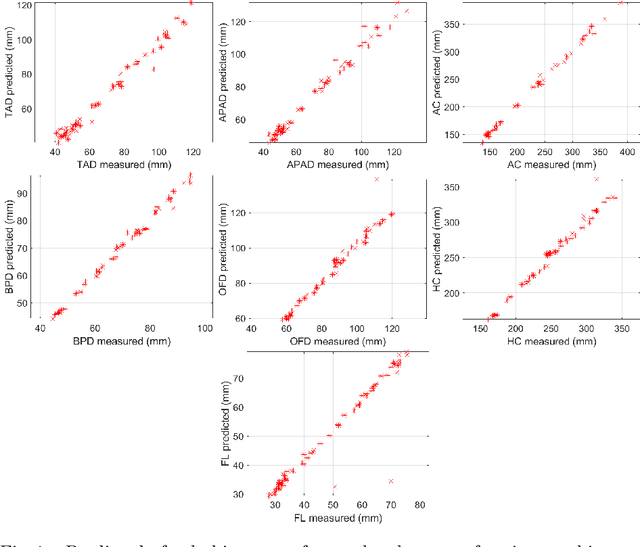
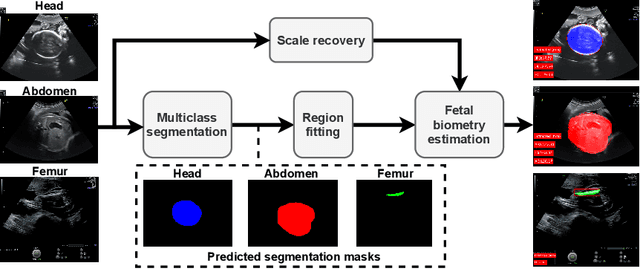
During pregnancy, ultrasound examination in the second trimester can assess fetal size according to standardized charts. To achieve a reproducible and accurate measurement, a sonographer needs to identify three standard 2D planes of the fetal anatomy (head, abdomen, femur) and manually mark the key anatomical landmarks on the image for accurate biometry and fetal weight estimation. This can be a time-consuming operator-dependent task, especially for a trainee sonographer. Computer-assisted techniques can help in automating the fetal biometry computation process. In this paper, we present a unified automated framework for estimating all measurements needed for the fetal weight assessment. The proposed framework semantically segments the key fetal anatomies using state-of-the-art segmentation models, followed by region fitting and scale recovery for the biometry estimation. We present an ablation study of segmentation algorithms to show their robustness through 4-fold cross-validation on a dataset of 349 ultrasound standard plane images from 42 pregnancies. Moreover, we show that the network with the best segmentation performance tends to be more accurate for biometry estimation. Furthermore, we demonstrate that the error between clinically measured and predicted fetal biometry is lower than the permissible error during routine clinical measurements.
FetReg: Placental Vessel Segmentation and Registration in Fetoscopy Challenge Dataset
Jun 16, 2021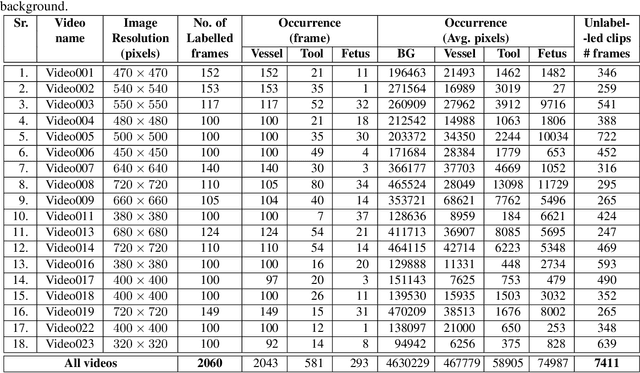

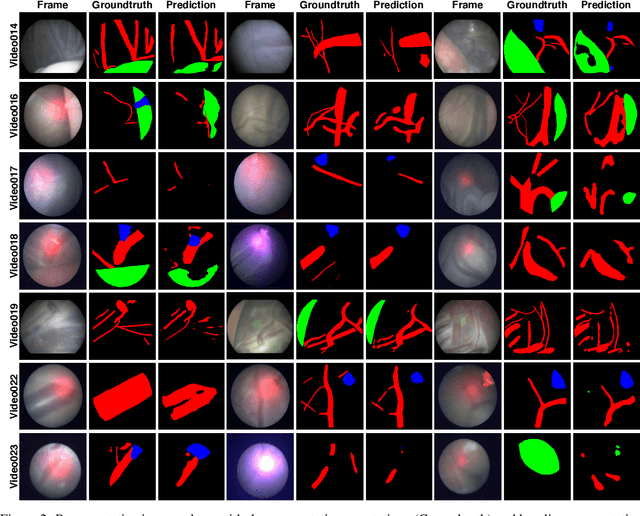
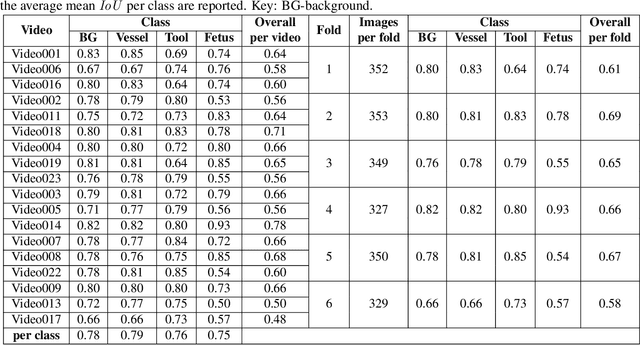
Fetoscopy laser photocoagulation is a widely used procedure for the treatment of Twin-to-Twin Transfusion Syndrome (TTTS), that occur in mono-chorionic multiple pregnancies due to placental vascular anastomoses. This procedure is particularly challenging due to limited field of view, poor manoeuvrability of the fetoscope, poor visibility due to fluid turbidity, variability in light source, and unusual position of the placenta. This may lead to increased procedural time and incomplete ablation, resulting in persistent TTTS. Computer-assisted intervention may help overcome these challenges by expanding the fetoscopic field of view through video mosaicking and providing better visualization of the vessel network. However, the research and development in this domain remain limited due to unavailability of high-quality data to encode the intra- and inter-procedure variability. Through the \textit{Fetoscopic Placental Vessel Segmentation and Registration (FetReg)} challenge, we present a large-scale multi-centre dataset for the development of generalized and robust semantic segmentation and video mosaicking algorithms for the fetal environment with a focus on creating drift-free mosaics from long duration fetoscopy videos. In this paper, we provide an overview of the FetReg dataset, challenge tasks, evaluation metrics and baseline methods for both segmentation and registration. Baseline methods results on the FetReg dataset shows that our dataset poses interesting challenges, offering large opportunity for the creation of novel methods and models through a community effort initiative guided by the FetReg challenge.