 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence-aware Monocular Depth Estimation for Minimally Invasive Surgery
Mar 03, 2026Purpose: Monocular depth estimation (MDE) is vital for scene understanding in minimally invasive surgery (MIS). However, endoscopic video sequences are often contaminated by smoke, specular reflections, blur, and occlusions, limiting the accuracy of MDE models. In addition, current MDE models do not output depth confidence, which could be a valuable tool for improving their clinical reliability. Methods: We propose a novel confidence-aware MDE framework featuring three significant contributions: (i) Calibrated confidence targets: an ensemble of fine-tuned stereo matching models is used to capture disparity variance into pixel-wise confidence probabilities; (ii) Confidence-aware loss: Baseline MDE models are optimized with confidence-aware loss functions, utilizing pixel-wise confidence probabilities such that reliable pixels dominate training; and (iii) Inference-time confidence: a confidence estimation head is proposed with two convolution layers to predict per-pixel confidence at inference, enabling assessment of depth reliability. Results: Comprehensive experimental validation across internal and public datasets demonstrates that our framework improves depth estimation accuracy and can robustly quantify the prediction's confidence. On the internal clinical endoscopic dataset (StereoKP), we improve dense depth estimation accuracy by ~8% as compared to the baseline model. Conclusion: Our confidence-aware framework enables improved accuracy of MDE models in MIS, addressing challenges posed by noise and artifacts in pre-clinical and clinical data, and allows MDE models to provide confidence maps that may be used to improve their reliability for clinical applications.
2020 CATARACTS Semantic Segmentation Challenge
Oct 21, 2021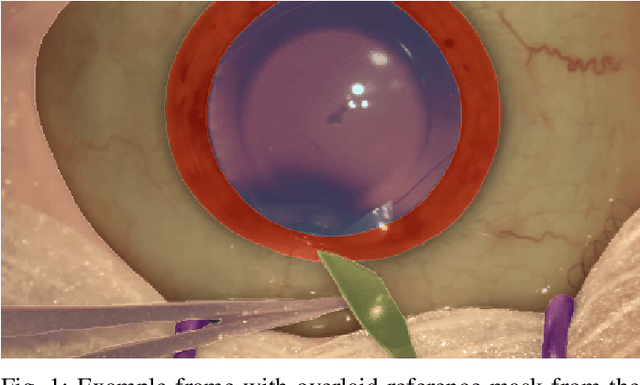
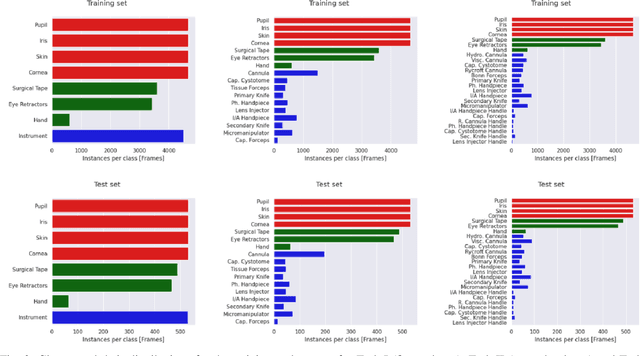
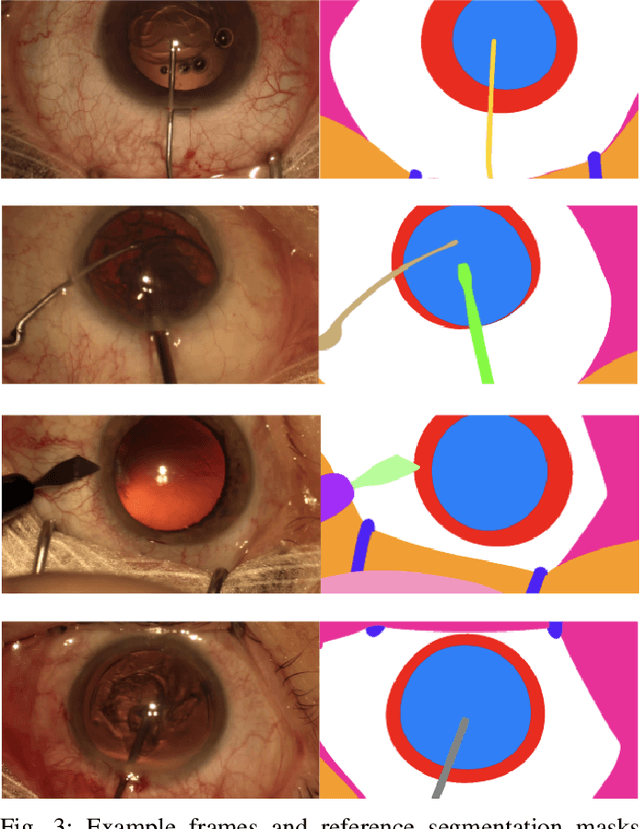
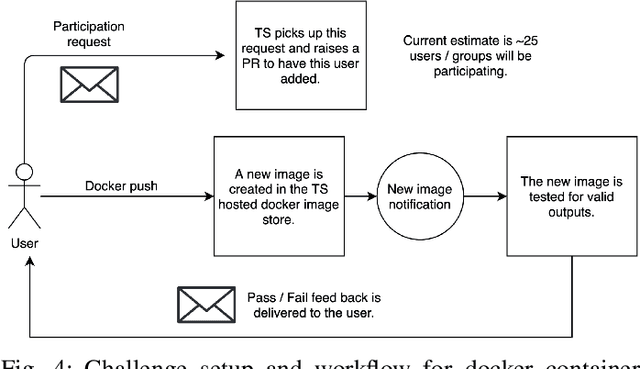
Surgical scene segmentation is essential for anatomy and instrument localization which can be further used to assess tissue-instrument interactions during a surgical procedure. In 2017, the Challenge on Automatic Tool Annotation for cataRACT Surgery (CATARACTS) released 50 cataract surgery videos accompanied by instrument usage annotations. These annotations included frame-level instrument presence information. In 2020, we released pixel-wise semantic annotations for anatomy and instruments for 4670 images sampled from 25 videos of the CATARACTS training set. The 2020 CATARACTS Semantic Segmentation Challenge, which was a sub-challenge of the 2020 MICCAI Endoscopic Vision (EndoVis) Challenge, presented three sub-tasks to assess participating solutions on anatomical structure and instrument segmentation. Their performance was assessed on a hidden test set of 531 images from 10 videos of the CATARACTS test set.