 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAir Quality Downscaling with Station-Guided Pseudo-Supervision
Jul 06, 2026Super-resolving coarse atmospheric fields to local PM$_{2.5}$ variations is uniquely challenged by a mismatch in spatial support: while pixels represent regional averages, ground-truth observations are discrete, unaligned samples of a continuous spatial signal. To bridge this gap, we present a station-guided framework for high-resolution PM$_{2.5}$ downscaling over Europe. Taking coarse CAMS atmospheric composition fields alongside heterogeneous side information (i.e., human activity, land cover, elevation, satellite aerosol observations, and wind fields) our framework jointly super-resolves ($\times 40$, $\approx$ 1 km) and bias-corrects CAMS rasters, without relying on temporal sequence modelling. To address the challenge of densely supervising our multi-scale transformer network with sparse in-situ data, we introduce a time-agnostic propagation strategy that utilises spatial Gaussian blending of interpolated OpenAQ observations. Extensive qualitative and station-level evaluations across Europe demonstrate that our model recovers fine-grained spatial structures and effectively mitigates localised CAMS biases.
Parallelised Differentiable Straightest Geodesics for 3D Meshes
Mar 16, 2026Machine learning has been progressively generalised to operate within non-Euclidean domains, but geometrically accurate methods for learning on surfaces are still falling behind. The lack of closed-form Riemannian operators, the non-differentiability of their discrete counterparts, and poor parallelisation capabilities have been the main obstacles to the development of the field on meshes. A principled framework to compute the exponential map on Riemannian surfaces discretised as meshes is straightest geodesics, which also allows to trace geodesics and parallel-transport vectors as a by-product. We provide a parallel GPU implementation and derive two different methods for differentiating through the straightest geodesics, one leveraging an extrinsic proxy function and one based upon a geodesic finite differences scheme. After proving our parallelisation performance and accuracy, we demonstrate how our differentiable exponential map can improve learning and optimisation pipelines on general geometries. In particular, to showcase the versatility of our method, we propose a new geodesic convolutional layer, a new flow matching method for learning on meshes, and a second-order optimiser that we apply to centroidal Voronoi tessellation. Our code, models, and pip-installable library (digeo) are available at: circle-group.github.io/research/DSG.
Geometric Neural Distance Fields for Learning Human Motion Priors
Sep 11, 2025We introduce Neural Riemannian Motion Fields (NRMF), a novel 3D generative human motion prior that enables robust, temporally consistent, and physically plausible 3D motion recovery. Unlike existing VAE or diffusion-based methods, our higher-order motion prior explicitly models the human motion in the zero level set of a collection of neural distance fields (NDFs) corresponding to pose, transition (velocity), and acceleration dynamics. Our framework is rigorous in the sense that our NDFs are constructed on the product space of joint rotations, their angular velocities, and angular accelerations, respecting the geometry of the underlying articulations. We further introduce: (i) a novel adaptive-step hybrid algorithm for projecting onto the set of plausible motions, and (ii) a novel geometric integrator to "roll out" realistic motion trajectories during test-time-optimization and generation. Our experiments show significant and consistent gains: trained on the AMASS dataset, NRMF remarkably generalizes across multiple input modalities and to diverse tasks ranging from denoising to motion in-betweening and fitting to partial 2D / 3D observations.
UV-free Texture Generation with Denoising and Geodesic Heat Diffusions
Aug 29, 2024



Seams, distortions, wasted UV space, vertex-duplication, and varying resolution over the surface are the most prominent issues of the standard UV-based texturing of meshes. These issues are particularly acute when automatic UV-unwrapping techniques are used. For this reason, instead of generating textures in automatically generated UV-planes like most state-of-the-art methods, we propose to represent textures as coloured point-clouds whose colours are generated by a denoising diffusion probabilistic model constrained to operate on the surface of 3D objects. Our sampling and resolution agnostic generative model heavily relies on heat diffusion over the surface of the meshes for spatial communication between points. To enable processing of arbitrarily sampled point-cloud textures and ensure long-distance texture consistency we introduce a fast re-sampling of the mesh spectral properties used during the heat diffusion and introduce a novel heat-diffusion-based self-attention mechanism. Our code and pre-trained models are available at github.com/simofoti/UV3-TeD.
Latent Disentanglement in Mesh Variational Autoencoders Improves the Diagnosis of Craniofacial Syndromes and Aids Surgical Planning
Sep 05, 2023



The use of deep learning to undertake shape analysis of the complexities of the human head holds great promise. However, there have traditionally been a number of barriers to accurate modelling, especially when operating on both a global and local level. In this work, we will discuss the application of the Swap Disentangled Variational Autoencoder (SD-VAE) with relevance to Crouzon, Apert and Muenke syndromes. Although syndrome classification is performed on the entire mesh, it is also possible, for the first time, to analyse the influence of each region of the head on the syndromic phenotype. By manipulating specific parameters of the generative model, and producing procedure-specific new shapes, it is also possible to simulate the outcome of a range of craniofacial surgical procedures. This opens new avenues to advance diagnosis, aids surgical planning and allows for the objective evaluation of surgical outcomes.
3D Generative Model Latent Disentanglement via Local Eigenprojection
Feb 24, 2023Designing realistic digital humans is extremely complex. Most data-driven generative models used to simplify the creation of their underlying geometric shape do not offer control over the generation of local shape attributes. In this paper, we overcome this limitation by introducing a novel loss function grounded in spectral geometry and applicable to different neural-network-based generative models of 3D head and body meshes. Encouraging the latent variables of mesh variational autoencoders (VAEs) or generative adversarial networks (GANs) to follow the local eigenprojections of identity attributes, we improve latent disentanglement and properly decouple the attribute creation. Experimental results show that our local eigenprojection disentangled (LED) models not only offer improved disentanglement with respect to the state-of-the-art, but also maintain good generation capabilities with training times comparable to the vanilla implementations of the models.
3D Shape Variational Autoencoder Latent Disentanglement via Mini-Batch Feature Swapping for Bodies and Faces
Nov 25, 2021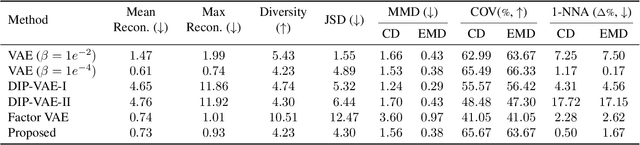
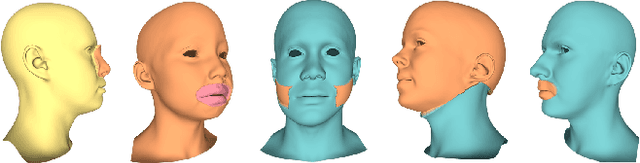

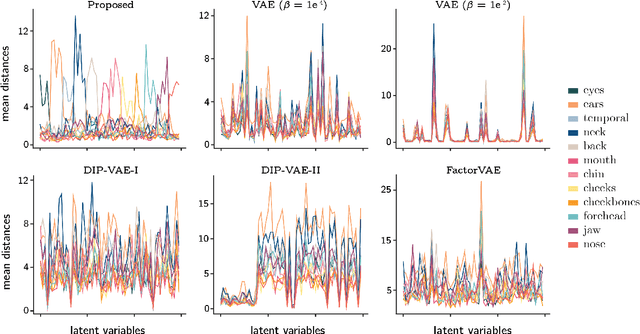
Learning a disentangled, interpretable, and structured latent representation in 3D generative models of faces and bodies is still an open problem. The problem is particularly acute when control over identity features is required. In this paper, we propose an intuitive yet effective self-supervised approach to train a 3D shape variational autoencoder (VAE) which encourages a disentangled latent representation of identity features. Curating the mini-batch generation by swapping arbitrary features across different shapes allows to define a loss function leveraging known differences and similarities in the latent representations. Experimental results conducted on 3D meshes show that state-of-the-art methods for latent disentanglement are not able to disentangle identity features of faces and bodies. Our proposed method properly decouples the generation of such features while maintaining good representation and reconstruction capabilities.
Intraoperative Liver Surface Completion with Graph Convolutional VAE
Sep 08, 2020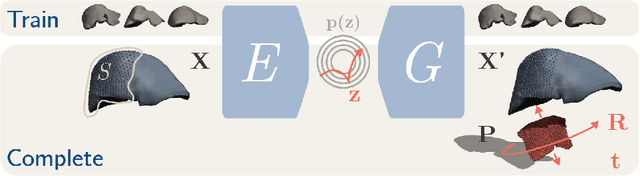

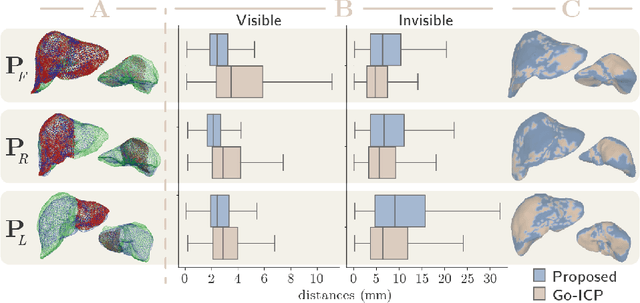
In this work we propose a method based on geometric deep learning to predict the complete surface of the liver, given a partial point cloud of the organ obtained during the surgical laparoscopic procedure. We introduce a new data augmentation technique that randomly perturbs shapes in their frequency domain to compensate the limited size of our dataset. The core of our method is a variational autoencoder (VAE) that is trained to learn a latent space for complete shapes of the liver. At inference time, the generative part of the model is embedded in an optimisation procedure where the latent representation is iteratively updated to generate a model that matches the intraoperative partial point cloud. The effect of this optimisation is a progressive non-rigid deformation of the initially generated shape. Our method is qualitatively evaluated on real data and quantitatively evaluated on synthetic data. We compared with a state-of-the-art rigid registration algorithm, that our method outperformed in visible areas.