 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Heterogeneous Model Reuse by Density Estimation
May 23, 2023



This paper studies multiparty learning, aiming to learn a model using the private data of different participants. Model reuse is a promising solution for multiparty learning, assuming that a local model has been trained for each party. Considering the potential sample selection bias among different parties, some heterogeneous model reuse approaches have been developed. However, although pre-trained local classifiers are utilized in these approaches, the characteristics of the local data are not well exploited. This motivates us to estimate the density of local data and design an auxiliary model together with the local classifiers for reuse. To address the scenarios where some local models are not well pre-trained, we further design a multiparty cross-entropy loss for calibration. Upon existing works, we address a challenging problem of heterogeneous model reuse from a decision theory perspective and take advantage of recent advances in density estimation. Experimental results on both synthetic and benchmark data demonstrate the superiority of the proposed method.
Self-Evolution Learning for Mixup: Enhance Data Augmentation on Few-Shot Text Classification Tasks
May 22, 2023



Text classification tasks often encounter few shot scenarios with limited labeled data, and addressing data scarcity is crucial. Data augmentation with mixup has shown to be effective on various text classification tasks. However, most of the mixup methods do not consider the varying degree of learning difficulty in different stages of training and generate new samples with one hot labels, resulting in the model over confidence. In this paper, we propose a self evolution learning (SE) based mixup approach for data augmentation in text classification, which can generate more adaptive and model friendly pesudo samples for the model training. SE focuses on the variation of the model's learning ability. To alleviate the model confidence, we introduce a novel instance specific label smoothing approach, which linearly interpolates the model's output and one hot labels of the original samples to generate new soft for label mixing up. Through experimental analysis, in addition to improving classification accuracy, we demonstrate that SE also enhances the model's generalize ability.
Dynamic Regularized Sharpness Aware Minimization in Federated Learning: Approaching Global Consistency and Smooth Landscape
May 19, 2023In federated learning (FL), a cluster of local clients are chaired under the coordination of the global server and cooperatively train one model with privacy protection. Due to the multiple local updates and the isolated non-iid dataset, clients are prone to overfit into their own optima, which extremely deviates from the global objective and significantly undermines the performance. Most previous works only focus on enhancing the consistency between the local and global objectives to alleviate this prejudicial client drifts from the perspective of the optimization view, whose performance would be prominently deteriorated on the high heterogeneity. In this work, we propose a novel and general algorithm {\ttfamily FedSMOO} by jointly considering the optimization and generalization targets to efficiently improve the performance in FL. Concretely, {\ttfamily FedSMOO} adopts a dynamic regularizer to guarantee the local optima towards the global objective, which is meanwhile revised by the global Sharpness Aware Minimization (SAM) optimizer to search for the consistent flat minima. Our theoretical analysis indicates that {\ttfamily FedSMOO} achieves fast $\mathcal{O}(1/T)$ convergence rate with low generalization bound. Extensive numerical studies are conducted on the real-world dataset to verify its peerless efficiency and excellent generality.
Prompt-Tuning Decision Transformer with Preference Ranking
May 16, 2023Prompt-tuning has emerged as a promising method for adapting pre-trained models to downstream tasks or aligning with human preferences. Prompt learning is widely used in NLP but has limited applicability to RL due to the complex physical meaning and environment-specific information contained within RL prompts. These factors require supervised learning to imitate the demonstrations and may result in a loss of meaning after learning. Additionally, directly extending prompt-tuning approaches to RL is challenging because RL prompts guide agent behavior based on environmental modeling and analysis, rather than filling in missing information, making it unlikely that adjustments to the prompt format for downstream tasks, as in NLP, can yield significant improvements. In this work, we propose the Prompt-Tuning DT algorithm to address these challenges by using trajectory segments as prompts to guide RL agents in acquiring environmental information and optimizing prompts via black-box tuning to enhance their ability to contain more relevant information, thereby enabling agents to make better decisions. Our approach involves randomly sampling a Gaussian distribution to fine-tune the elements of the prompt trajectory and using preference ranking function to find the optimization direction, thereby providing more informative prompts and guiding the agent towards specific preferences in the target environment. Extensive experiments show that with only 0.03% of the parameters learned, Prompt-Tuning DT achieves comparable or even better performance than full-model fine-tuning in low-data scenarios. Our work contributes to the advancement of prompt-tuning approaches in RL, providing a promising direction for optimizing large RL agents for specific preference tasks.
MMoT: Mixture-of-Modality-Tokens Transformer for Composed Multimodal Conditional Image Synthesis
May 10, 2023



Existing multimodal conditional image synthesis (MCIS) methods generate images conditioned on any combinations of various modalities that require all of them must be exactly conformed, hindering the synthesis controllability and leaving the potential of cross-modality under-exploited. To this end, we propose to generate images conditioned on the compositions of multimodal control signals, where modalities are imperfectly complementary, i.e., composed multimodal conditional image synthesis (CMCIS). Specifically, we observe two challenging issues of the proposed CMCIS task, i.e., the modality coordination problem and the modality imbalance problem. To tackle these issues, we introduce a Mixture-of-Modality-Tokens Transformer (MMoT) that adaptively fuses fine-grained multimodal control signals, a multimodal balanced training loss to stabilize the optimization of each modality, and a multimodal sampling guidance to balance the strength of each modality control signal. Comprehensive experimental results demonstrate that MMoT achieves superior performance on both unimodal conditional image synthesis (UCIS) and MCIS tasks with high-quality and faithful image synthesis on complex multimodal conditions. The project website is available at https://jabir-zheng.github.io/MMoT.
Revolutionizing Agrifood Systems with Artificial Intelligence: A Survey
May 03, 2023



With the world population rapidly increasing, transforming our agrifood systems to be more productive, efficient, safe, and sustainable is crucial to mitigate potential food shortages. Recently, artificial intelligence (AI) techniques such as deep learning (DL) have demonstrated their strong abilities in various areas, including language, vision, remote sensing (RS), and agrifood systems applications. However, the overall impact of AI on agrifood systems remains unclear. In this paper, we thoroughly review how AI techniques can transform agrifood systems and contribute to the modern agrifood industry. Firstly, we summarize the data acquisition methods in agrifood systems, including acquisition, storage, and processing techniques. Secondly, we present a progress review of AI methods in agrifood systems, specifically in agriculture, animal husbandry, and fishery, covering topics such as agrifood classification, growth monitoring, yield prediction, and quality assessment. Furthermore, we highlight potential challenges and promising research opportunities for transforming modern agrifood systems with AI. We hope this survey could offer an overall picture to newcomers in the field and serve as a starting point for their further research.
Scaling-up Remote Sensing Segmentation Dataset with Segment Anything Model
May 03, 2023
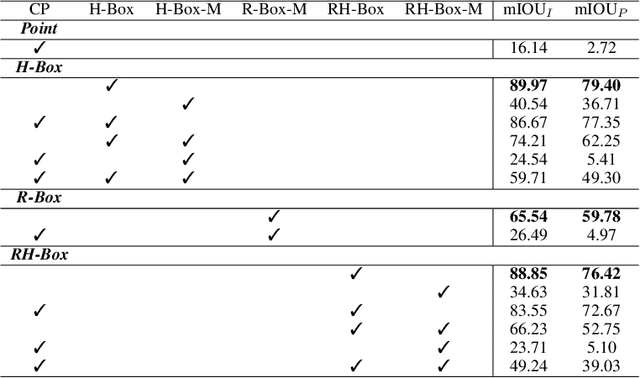


The success of the Segment Anything Model (SAM) demonstrates the significance of data-centric machine learning. However, due to the difficulties and high costs associated with annotating Remote Sensing (RS) images, a large amount of valuable RS data remains unlabeled, particularly at the pixel level. In this study, we leverage SAM and existing RS object detection datasets to develop an efficient pipeline for generating a large-scale RS segmentation dataset, dubbed SAMRS. SAMRS surpasses existing high-resolution RS segmentation datasets in size by several orders of magnitude, and provides object category, location, and instance information that can be used for semantic segmentation, instance segmentation, and object detection, either individually or in combination. We also provide a comprehensive analysis of SAMRS from various aspects. We hope it could facilitate research in RS segmentation, particularly in large model pre-training.
Scalable Mask Annotation for Video Text Spotting
May 02, 2023Video text spotting refers to localizing, recognizing, and tracking textual elements such as captions, logos, license plates, signs, and other forms of text within consecutive video frames. However, current datasets available for this task rely on quadrilateral ground truth annotations, which may result in including excessive background content and inaccurate text boundaries. Furthermore, methods trained on these datasets often produce prediction results in the form of quadrilateral boxes, which limits their ability to handle complex scenarios such as dense or curved text. To address these issues, we propose a scalable mask annotation pipeline called SAMText for video text spotting. SAMText leverages the SAM model to generate mask annotations for scene text images or video frames at scale. Using SAMText, we have created a large-scale dataset, SAMText-9M, that contains over 2,400 video clips sourced from existing datasets and over 9 million mask annotations. We have also conducted a thorough statistical analysis of the generated masks and their quality, identifying several research topics that could be further explored based on this dataset. The code and dataset will be released at \url{https://github.com/ViTAE-Transformer/SAMText}.
Towards the Flatter Landscape and Better Generalization in Federated Learning under Client-level Differential Privacy
May 02, 2023



To defend the inference attacks and mitigate the sensitive information leakages in Federated Learning (FL), client-level Differentially Private FL (DPFL) is the de-facto standard for privacy protection by clipping local updates and adding random noise. However, existing DPFL methods tend to make a sharp loss landscape and have poor weight perturbation robustness, resulting in severe performance degradation. To alleviate these issues, we propose a novel DPFL algorithm named DP-FedSAM, which leverages gradient perturbation to mitigate the negative impact of DP. Specifically, DP-FedSAM integrates Sharpness Aware Minimization (SAM) optimizer to generate local flatness models with improved stability and weight perturbation robustness, which results in the small norm of local updates and robustness to DP noise, thereby improving the performance. To further reduce the magnitude of random noise while achieving better performance, we propose DP-FedSAM-$top_k$ by adopting the local update sparsification technique. From the theoretical perspective, we present the convergence analysis to investigate how our algorithms mitigate the performance degradation induced by DP. Meanwhile, we give rigorous privacy guarantees with R\'enyi DP, the sensitivity analysis of local updates, and generalization analysis. At last, we empirically confirm that our algorithms achieve state-of-the-art (SOTA) performance compared with existing SOTA baselines in DPFL.
Deep Graph Reprogramming
Apr 28, 2023



In this paper, we explore a novel model reusing task tailored for graph neural networks (GNNs), termed as "deep graph reprogramming". We strive to reprogram a pre-trained GNN, without amending raw node features nor model parameters, to handle a bunch of cross-level downstream tasks in various domains. To this end, we propose an innovative Data Reprogramming paradigm alongside a Model Reprogramming paradigm. The former one aims to address the challenge of diversified graph feature dimensions for various tasks on the input side, while the latter alleviates the dilemma of fixed per-task-per-model behavior on the model side. For data reprogramming, we specifically devise an elaborated Meta-FeatPadding method to deal with heterogeneous input dimensions, and also develop a transductive Edge-Slimming as well as an inductive Meta-GraPadding approach for diverse homogenous samples. Meanwhile, for model reprogramming, we propose a novel task-adaptive Reprogrammable-Aggregator, to endow the frozen model with larger expressive capacities in handling cross-domain tasks. Experiments on fourteen datasets across node/graph classification/regression, 3D object recognition, and distributed action recognition, demonstrate that the proposed methods yield gratifying results, on par with those by re-training from scratch.