 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving robustness against common corruptions with frequency biased models
Mar 30, 2021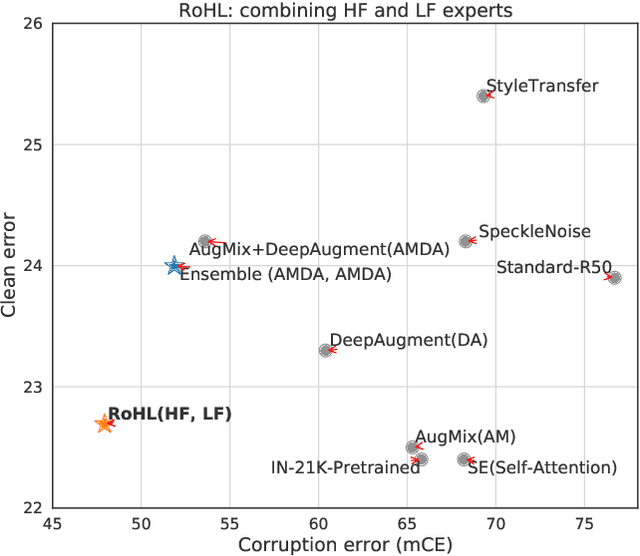
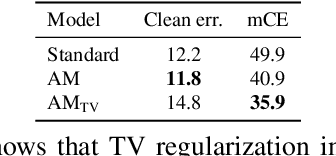
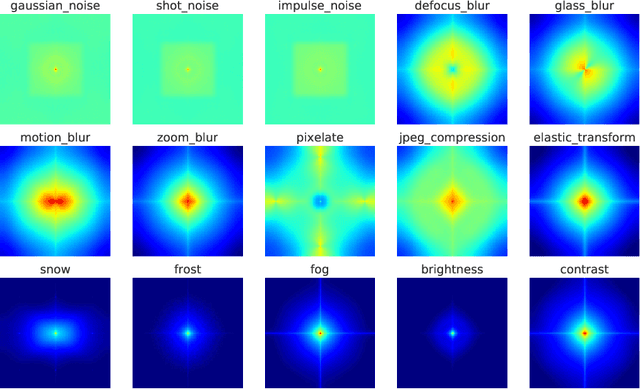
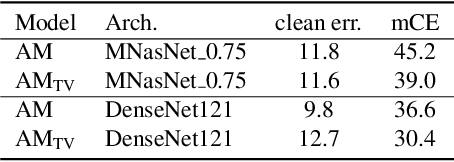
CNNs perform remarkably well when the training and test distributions are i.i.d, but unseen image corruptions can cause a surprisingly large drop in performance. In various real scenarios, unexpected distortions, such as random noise, compression artefacts, or weather distortions are common phenomena. Improving performance on corrupted images must not result in degraded i.i.d performance - a challenge faced by many state-of-the-art robust approaches. Image corruption types have different characteristics in the frequency spectrum and would benefit from a targeted type of data augmentation, which, however, is often unknown during training. In this paper, we introduce a mixture of two expert models specializing in high and low-frequency robustness, respectively. Moreover, we propose a new regularization scheme that minimizes the total variation (TV) of convolution feature-maps to increase high-frequency robustness. The approach improves on corrupted images without degrading in-distribution performance. We demonstrate this on ImageNet-C and also for real-world corruptions on an automotive dataset, both for object classification and object detection.
ViViT: A Video Vision Transformer
Mar 29, 2021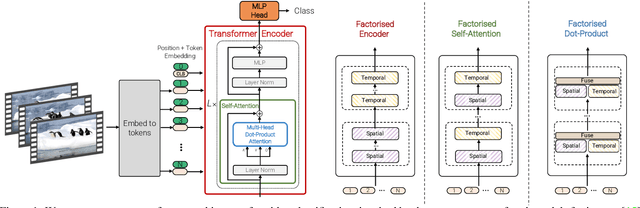
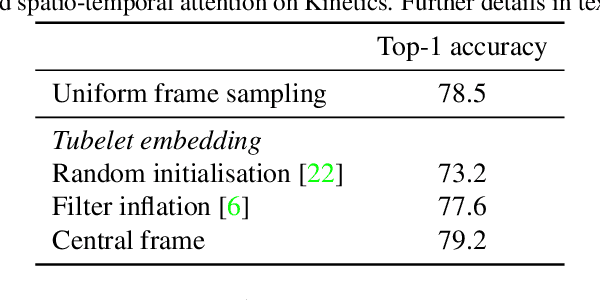
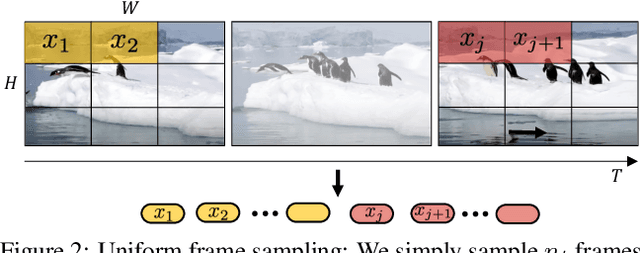
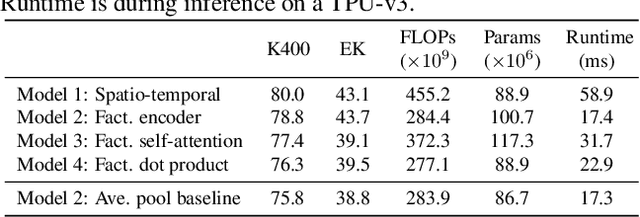
We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatio-temporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks. To facilitate further research, we will release code and models.
Unified Graph Structured Models for Video Understanding
Mar 29, 2021

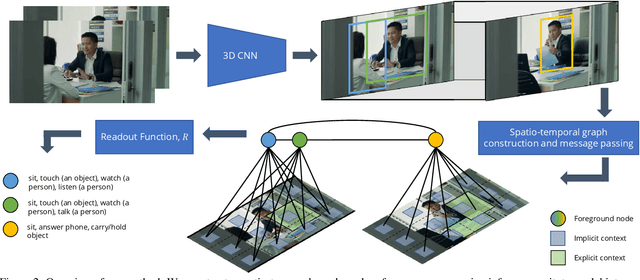
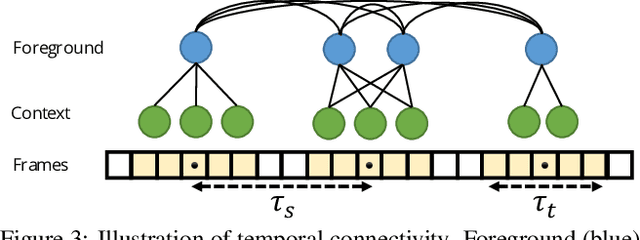
Accurate video understanding involves reasoning about the relationships between actors, objects and their environment, often over long temporal intervals. In this paper, we propose a message passing graph neural network that explicitly models these spatio-temporal relations and can use explicit representations of objects, when supervision is available, and implicit representations otherwise. Our formulation generalises previous structured models for video understanding, and allows us to study how different design choices in graph structure and representation affect the model's performance. We demonstrate our method on two different tasks requiring relational reasoning in videos -- spatio-temporal action detection on AVA and UCF101-24, and video scene graph classification on the recent Action Genome dataset -- and achieve state-of-the-art results on all three datasets. Furthermore, we show quantitatively and qualitatively how our method is able to more effectively model relationships between relevant entities in the scene.
Learning Temporal Dynamics from Cycles in Narrated Video
Jan 07, 2021
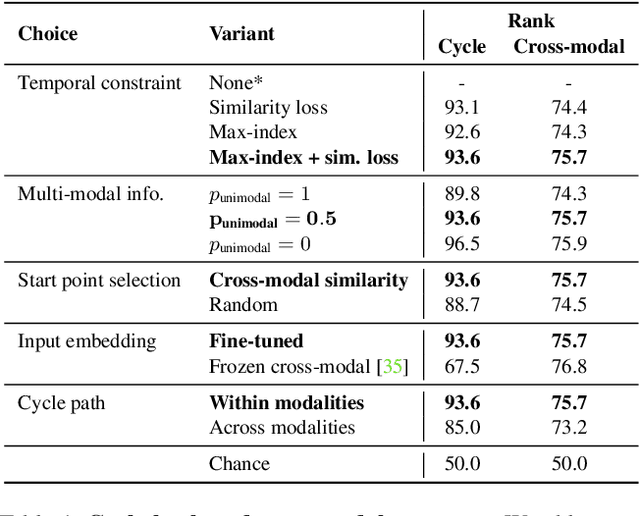
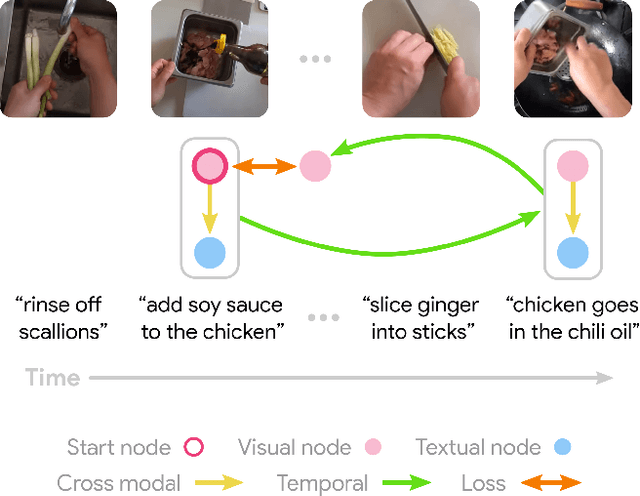
Learning to model how the world changes as time elapses has proven a challenging problem for the computer vision community. We propose a self-supervised solution to this problem using temporal cycle consistency jointly in vision and language, training on narrated video. Our model learns modality-agnostic functions to predict forward and backward in time, which must undo each other when composed. This constraint leads to the discovery of high-level transitions between moments in time, since such transitions are easily inverted and shared across modalities. We justify the design of our model with an ablation study on different configurations of the cycle consistency problem. We then show qualitatively and quantitatively that our approach yields a meaningful, high-level model of the future and past. We apply the learned dynamics model without further training to various tasks, such as predicting future action and temporally ordering sets of images.
Look Before you Speak: Visually Contextualized Utterances
Dec 10, 2020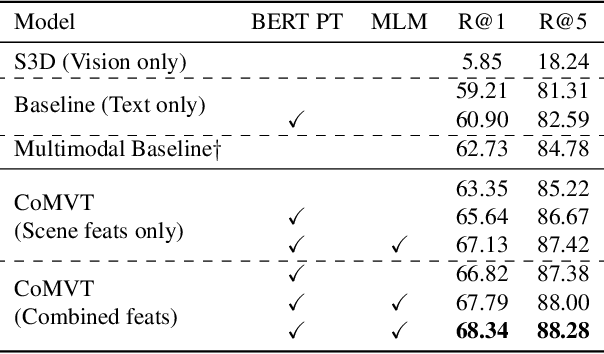
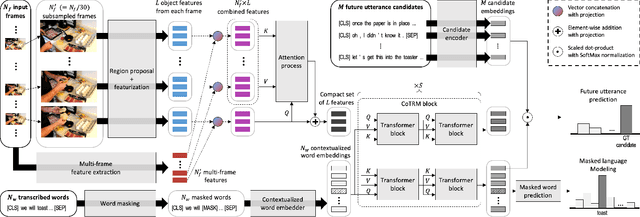
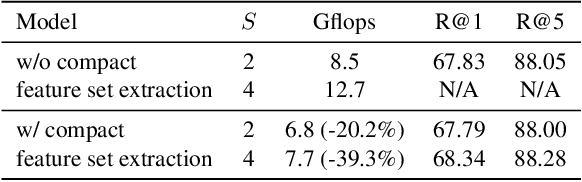

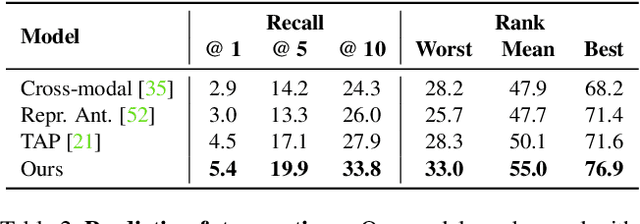
While most conversational AI systems focus on textual dialogue only, conditioning utterances on visual context (when it's available) can lead to more realistic conversations. Unfortunately, a major challenge for incorporating visual context into conversational dialogue is the lack of large-scale labeled datasets. We provide a solution in the form of a new visually conditioned Future Utterance Prediction task. Our task involves predicting the next utterance in a video, using both visual frames and transcribed speech as context. By exploiting the large number of instructional videos online, we train a model to solve this task at scale, without the need for manual annotations. Leveraging recent advances in multimodal learning, our model consists of a novel co-attentional multimodal video transformer, and when trained on both textual and visual context, outperforms baselines that use textual inputs alone. Further, we demonstrate that our model trained for this task on unlabelled videos achieves state-of-the-art performance on a number of downstream VideoQA benchmarks such as MSRVTT-QA, MSVD-QA, ActivityNet-QA and How2QA.
Image Matching with Scale Adjustment
Dec 10, 2020
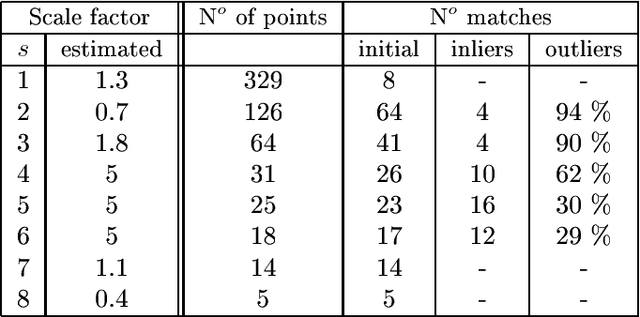

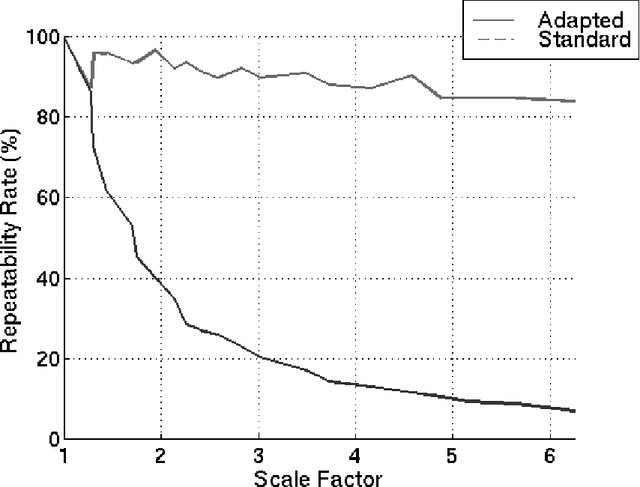
In this paper we address the problem of matching two images with two different resolutions: a high-resolution image and a low-resolution one. The difference in resolution between the two images is not known and without loss of generality one of the images is assumed to be the high-resolution one. On the premise that changes in resolution act as a smoothing equivalent to changes in scale, a scale-space representation of the high-resolution image is produced. Hence the one-to-one classical image matching paradigm becomes one-to-many because the low-resolution image is compared with all the scale-space representations of the high-resolution one. Key to the success of such a process is the proper representation of the features to be matched in scale-space. We show how to represent and extract interest points at variable scales and we devise a method allowing the comparison of two images at two different resolutions. The method comprises the use of photometric- and rotation-invariant descriptors, a geometric model mapping the high-resolution image onto a low-resolution image region, and an image matching strategy based on local constraints and on the robust estimation of this geometric model. Extensive experiments show that our matching method can be used for scale changes up to a factor of 6.
Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Dec 01, 2020
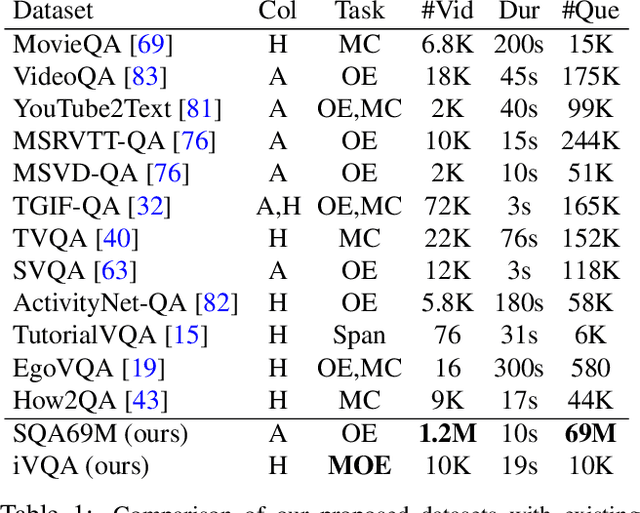


Modern approaches to visual question answering require large annotated datasets for training. Manual annotation of questions and answers for videos, however, is tedious, expensive and prevents scalability. In this work, we propose to avoid manual annotation and to learn video question answering (VideoQA) from millions of readily-available narrated videos. We propose to automatically generate question-answer pairs from transcribed video narrations leveraging a state-of-the-art text transformer pipeline and obtain a new large-scale VideoQA training dataset. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer embedding. We evaluate our model on the zero-shot VideoQA task and show excellent results, in particular for rare answers. Furthermore, we demonstrate that finetuning our model on target datasets significantly outperforms the state of the art on MSRVTT-QA, MSVD-QA and ActivityNet-QA. Finally, for a detailed evaluation we introduce a new manually annotated VideoQA dataset with reduced language biases and high quality annotations. Our code and datasets will be made publicly available at https://www.di.ens.fr/willow/research/just-ask/ .
Learning Obstacle Representations for Neural Motion Planning
Aug 29, 2020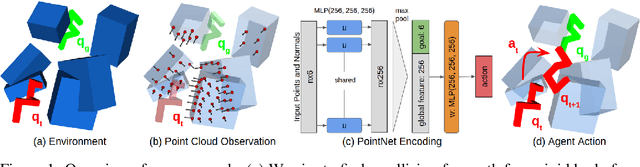
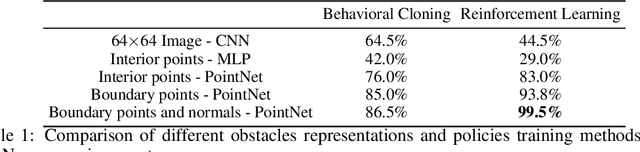

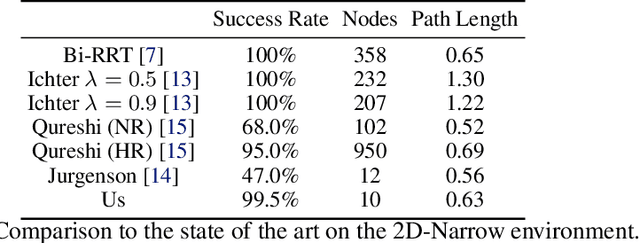
Motion planning and obstacle avoidance is a key challenge in robotics applications. While previous work succeeds to provide excellent solutions for known environments, sensor-based motion planning in new and dynamic environments remains difficult. In this work we address sensor-based motion planning from a learning perspective. Motivated by recent advances in visual recognition, we argue the importance of learning appropriate representations for motion planning. We propose a new obstacle representation based on the PointNet architecture and train it jointly with policies for obstacle avoidance. We experimentally evaluate our approach for rigid body motion planning in challenging environments and demonstrate significant improvements of the state of the art in terms of accuracy and efficiency.
TNT: Target-driveN Trajectory Prediction
Aug 21, 2020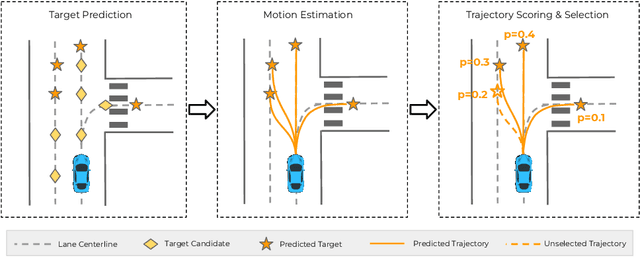
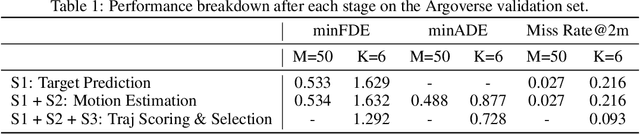
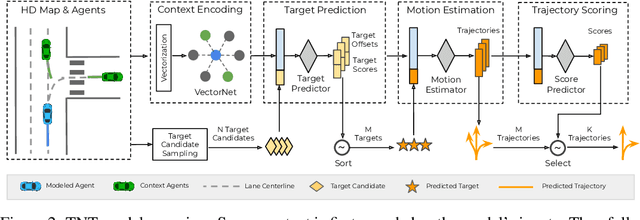
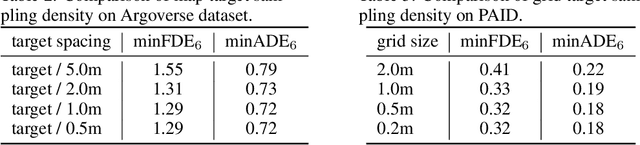
Predicting the future behavior of moving agents is essential for real world applications. It is challenging as the intent of the agent and the corresponding behavior is unknown and intrinsically multimodal. Our key insight is that for prediction within a moderate time horizon, the future modes can be effectively captured by a set of target states. This leads to our target-driven trajectory prediction (TNT) framework. TNT has three stages which are trained end-to-end. It first predicts an agent's potential target states $T$ steps into the future, by encoding its interactions with the environment and the other agents. TNT then generates trajectory state sequences conditioned on targets. A final stage estimates trajectory likelihoods and a final compact set of trajectory predictions is selected. This is in contrast to previous work which models agent intents as latent variables, and relies on test-time sampling to generate diverse trajectories. We benchmark TNT on trajectory prediction of vehicles and pedestrians, where we outperform state-of-the-art on Argoverse Forecasting, INTERACTION, Stanford Drone and an in-house Pedestrian-at-Intersection dataset.
The End-of-End-to-End: A Video Understanding Pentathlon Challenge
Aug 03, 2020
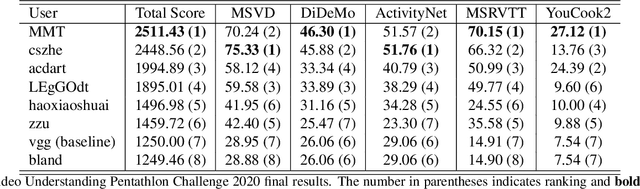
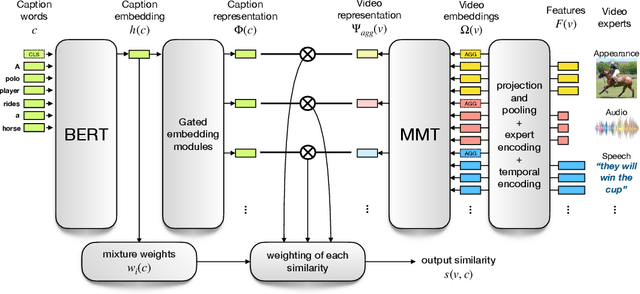
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.