 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Adversarial Training via Learned Optimizer
Apr 25, 2020
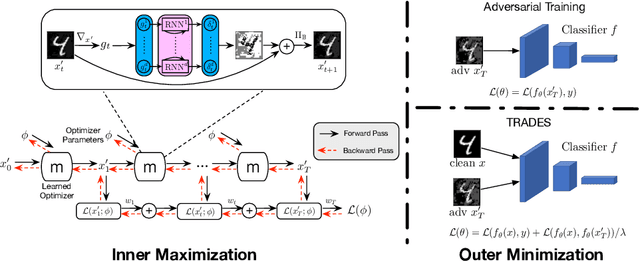
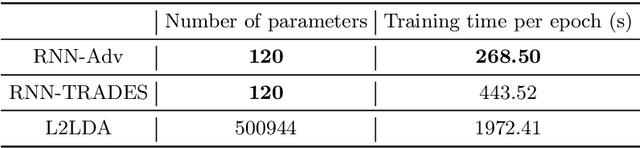
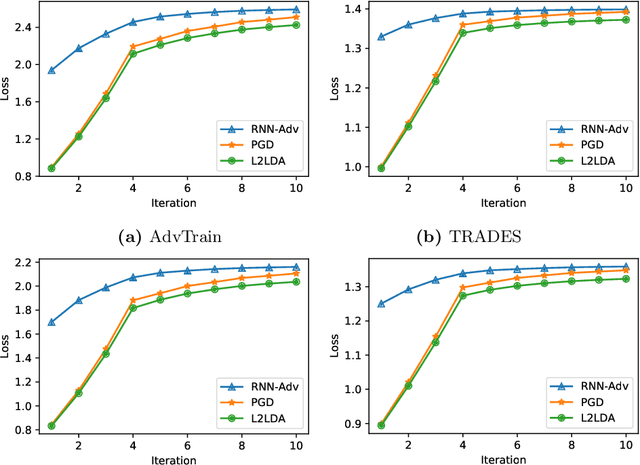
Adversarial attack has recently become a tremendous threat to deep learning models. To improve the robustness of machine learning models, adversarial training, formulated as a minimax optimization problem, has been recognized as one of the most effective defense mechanisms. However, the non-convex and non-concave property poses a great challenge to the minimax training. In this paper, we empirically demonstrate that the commonly used PGD attack may not be optimal for inner maximization, and improved inner optimizer can lead to a more robust model. Then we leverage a learning-to-learn (L2L) framework to train an optimizer with recurrent neural networks, providing update directions and steps adaptively for the inner problem. By co-training optimizer's parameters and model's weights, the proposed framework consistently improves the model robustness over PGD-based adversarial training and TRADES.
Robust Deep Reinforcement Learning against Adversarial Perturbations on Observations
Mar 19, 2020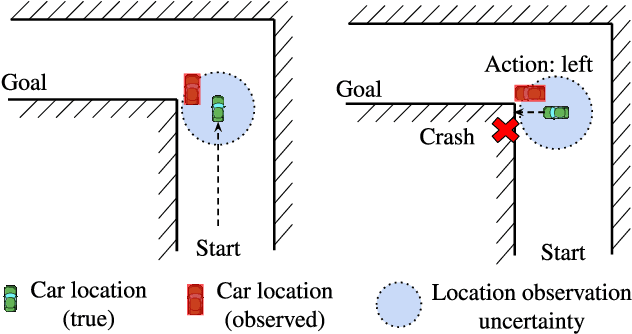

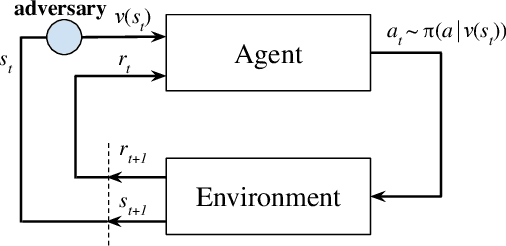
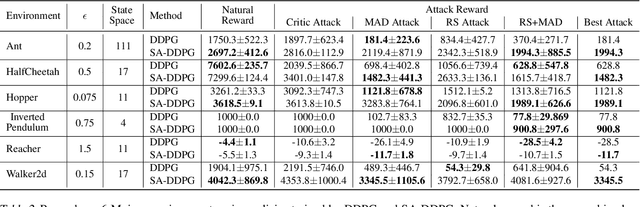
Deep Reinforcement Learning (DRL) is vulnerable to small adversarial perturbations on state observations. These perturbations do not alter the environment directly but can mislead the agent into making suboptimal decisions. We analyze the Markov Decision Process (MDP) under this threat model and utilize tools from the neural net-work verification literature to enable robust train-ing for DRL under observational perturbations. Our techniques are general and can be applied to both Deep Q Networks (DQN) and Deep Deterministic Policy Gradient (DDPG) algorithms for discrete and continuous action control problems. We demonstrate that our proposed training procedure significantly improves the robustness of DQN and DDPG agents under a suite of strong white-box attacks on observations, including a few novel attacks we specifically craft. Additionally, our training procedure can produce provable certificates for the robustness of a Deep RL agent.
Learning to Encode Position for Transformer with Continuous Dynamical Model
Mar 13, 2020
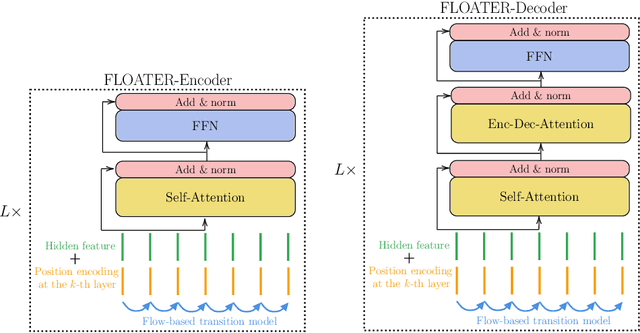
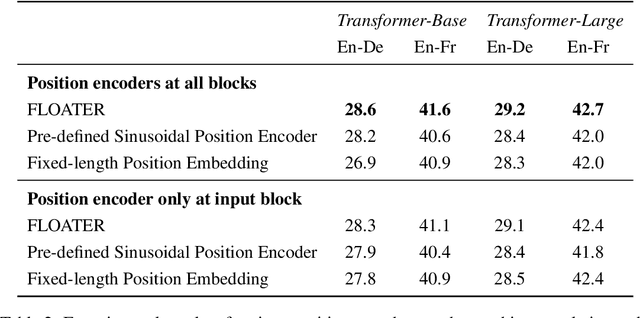
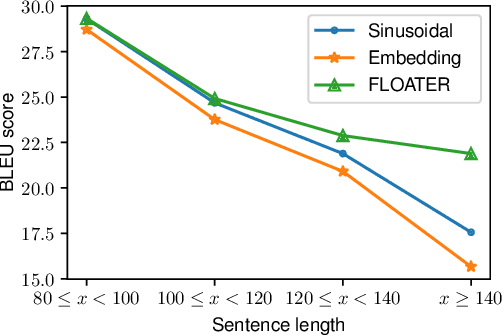
We introduce a new way of learning to encode position information for non-recurrent models, such as Transformer models. Unlike RNN and LSTM, which contain inductive bias by loading the input tokens sequentially, non-recurrent models are less sensitive to position. The main reason is that position information among input units is not inherently encoded, i.e., the models are permutation equivalent; this problem justifies why all of the existing models are accompanied by a sinusoidal encoding/embedding layer at the input. However, this solution has clear limitations: the sinusoidal encoding is not flexible enough as it is manually designed and does not contain any learnable parameters, whereas the position embedding restricts the maximum length of input sequences. It is thus desirable to design a new position layer that contains learnable parameters to adjust to different datasets and different architectures. At the same time, we would also like the encodings to extrapolate in accordance with the variable length of inputs. In our proposed solution, we borrow from the recent Neural ODE approach, which may be viewed as a versatile continuous version of a ResNet. This model is capable of modeling many kinds of dynamical systems. We model the evolution of encoded results along position index by such a dynamical system, thereby overcoming the above limitations of existing methods. We evaluate our new position layers on a variety of neural machine translation and language understanding tasks, the experimental results show consistent improvements over the baselines.
Automatic Perturbation Analysis on General Computational Graphs
Feb 28, 2020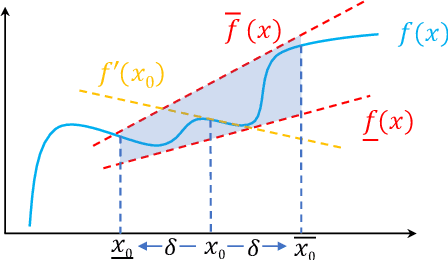

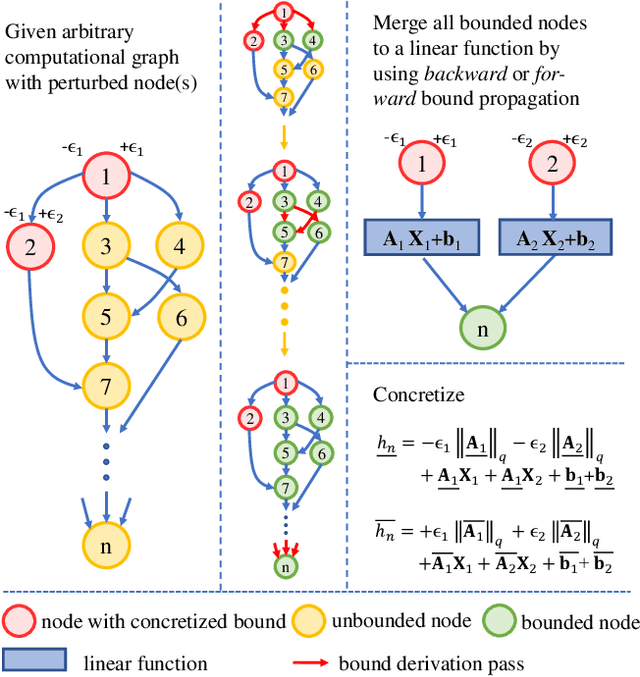

Linear relaxation based perturbation analysis for neural networks, which aims to compute tight linear bounds of output neurons given a certain amount of input perturbation, has become a core component in robustness verification and certified defense. However, the majority of linear relaxation based methods only consider feed-forward ReLU networks. While several works extended them to relatively complicated networks, they often need tedious manual derivations and implementation which are arduous and error-prone. Their limited flexibility makes it difficult to handle more complicated tasks. In this paper, we take a significant leap by developing an automatic perturbation analysis algorithm to enable perturbation analysis on any neural network structure, and its computation can be done automatically in a similar manner as the back-propagation algorithm for gradient computation. The main idea is to express a network as a computational graph and then generalize linear relaxation algorithms such as CROWN as a graph algorithm. Our algorithm itself is differentiable and integrated with PyTorch, which allows to optimize network parameters to reshape bounds into desired specifications, enabling automatic robustness verification and certified defense. In particular, we demonstrate a few tasks that are not easily achievable without an automatic framework. We first perform certified robust training and robustness verification for complex natural language models which could be challenging with manual derivation and implementation. We further show that our algorithm can be used for tasks beyond certified defense - we create a neural network with a provably flat optimization landscape and study its generalization capability, and we show that this network can preserve accuracy better after aggressive weight quantization. Code is available at https://github.com/KaidiXu/auto_LiRPA.
CAT: Customized Adversarial Training for Improved Robustness
Feb 17, 2020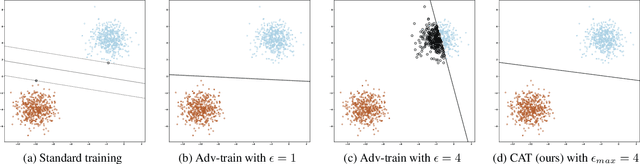
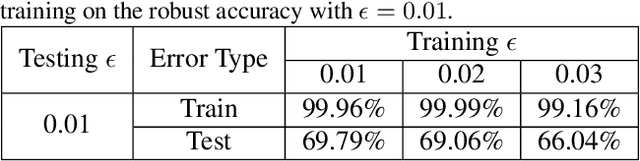

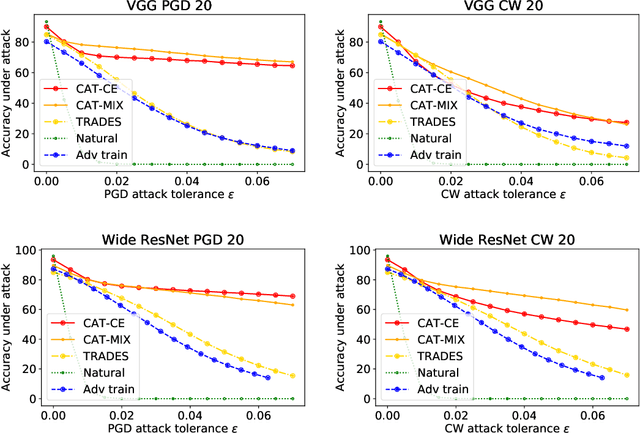
Adversarial training has become one of the most effective methods for improving robustness of neural networks. However, it often suffers from poor generalization on both clean and perturbed data. In this paper, we propose a new algorithm, named Customized Adversarial Training (CAT), which adaptively customizes the perturbation level and the corresponding label for each training sample in adversarial training. We show that the proposed algorithm achieves better clean and robust accuracy than previous adversarial training methods through extensive experiments.
Robustness Verification for Transformers
Feb 16, 2020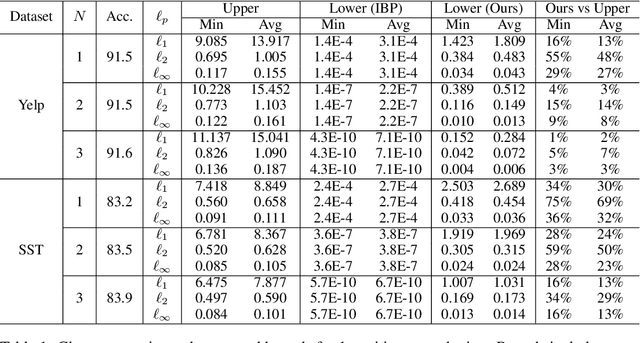
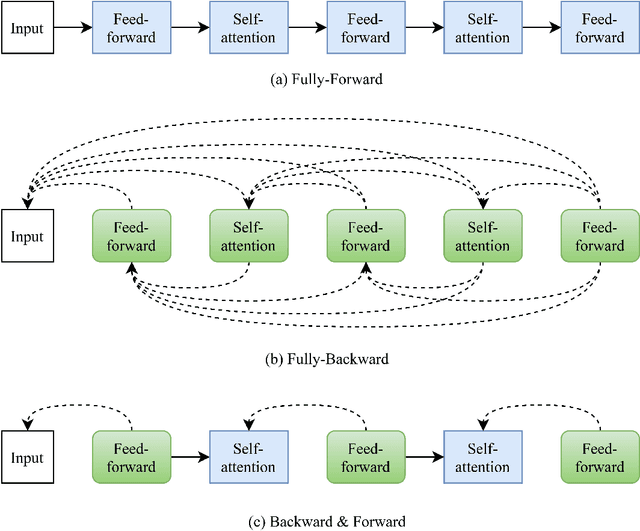
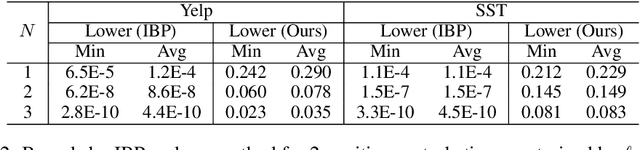
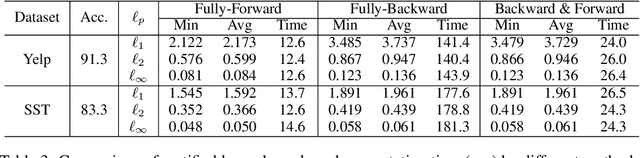
Robustness verification that aims to formally certify the prediction behavior of neural networks has become an important tool for understanding model behavior and obtaining safety guarantees. However, previous methods can usually only handle neural networks with relatively simple architectures. In this paper, we consider the robustness verification problem for Transformers. Transformers have complex self-attention layers that pose many challenges for verification, including cross-nonlinearity and cross-position dependency, which have not been discussed in previous works. We resolve these challenges and develop the first robustness verification algorithm for Transformers. The certified robustness bounds computed by our method are significantly tighter than those by naive Interval Bound Propagation. These bounds also shed light on interpreting Transformers as they consistently reflect the importance of different words in sentiment analysis.
MACER: Attack-free and Scalable Robust Training via Maximizing Certified Radius
Feb 15, 2020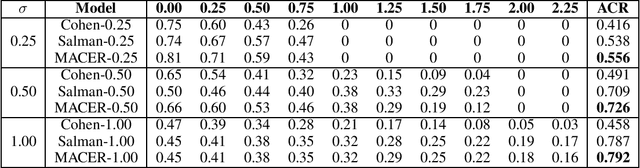
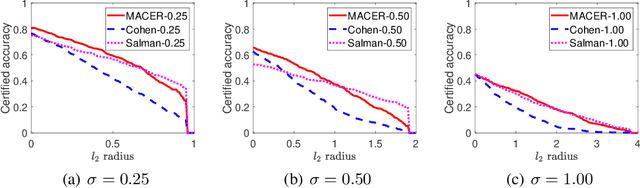
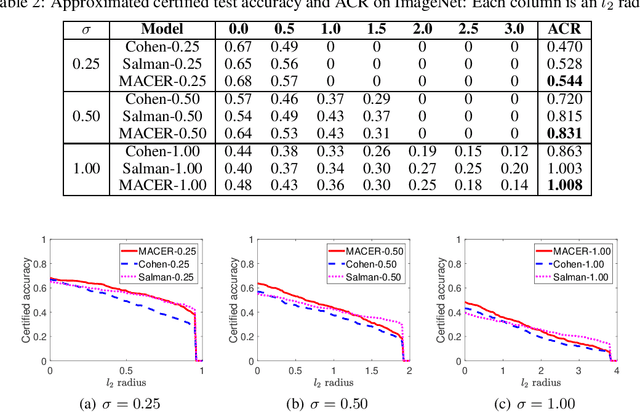
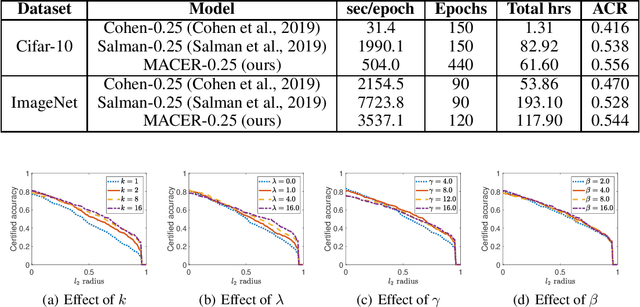
Adversarial training is one of the most popular ways to learn robust models but is usually attack-dependent and time costly. In this paper, we propose the MACER algorithm, which learns robust models without using adversarial training but performs better than all existing provable l2-defenses. Recent work shows that randomized smoothing can be used to provide a certified l2 radius to smoothed classifiers, and our algorithm trains provably robust smoothed classifiers via MAximizing the CErtified Radius (MACER). The attack-free characteristic makes MACER faster to train and easier to optimize. In our experiments, we show that our method can be applied to modern deep neural networks on a wide range of datasets, including Cifar-10, ImageNet, MNIST, and SVHN. For all tasks, MACER spends less training time than state-of-the-art adversarial training algorithms, and the learned models achieve larger average certified radius.
Multiscale Non-stationary Stochastic Bandits
Feb 13, 2020

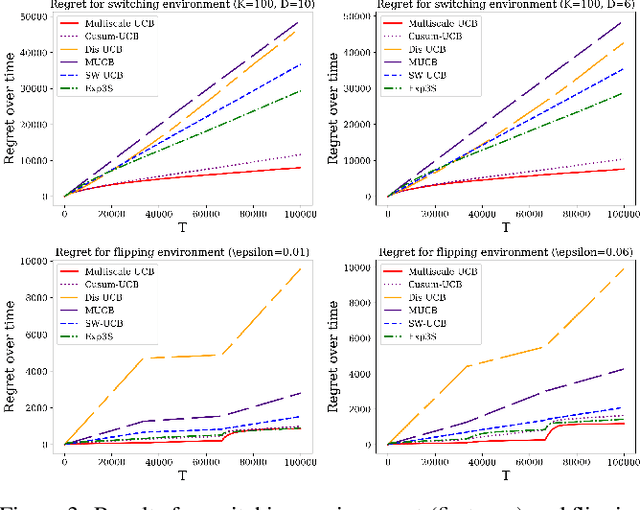
Classic contextual bandit algorithms for linear models, such as LinUCB, assume that the reward distribution for an arm is modeled by a stationary linear regression. When the linear regression model is non-stationary over time, the regret of LinUCB can scale linearly with time. In this paper, we propose a novel multiscale changepoint detection method for the non-stationary linear bandit problems, called Multiscale-LinUCB, which actively adapts to the changing environment. We also provide theoretical analysis of regret bound for Multiscale-LinUCB algorithm. Experimental results show that our proposed Multiscale-LinUCB algorithm outperforms other state-of-the-art algorithms in non-stationary contextual environments.
Stabilizing Differentiable Architecture Search via Perturbation-based Regularization
Feb 12, 2020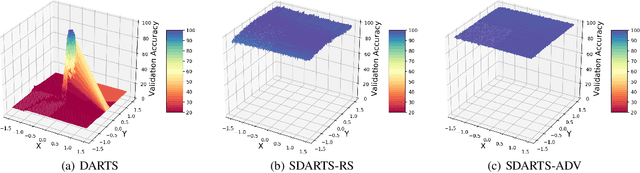
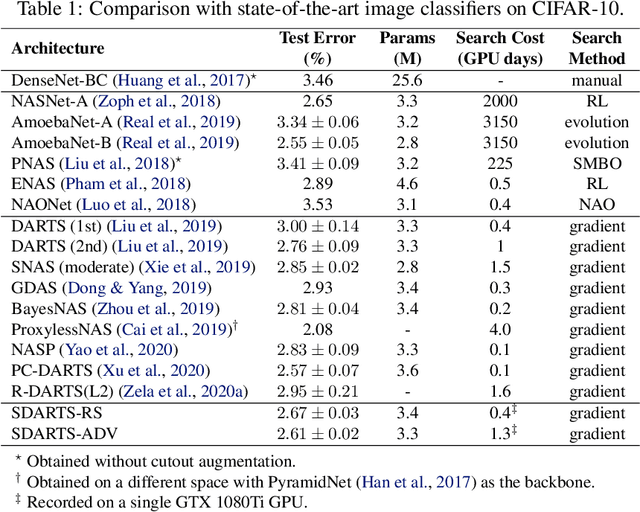
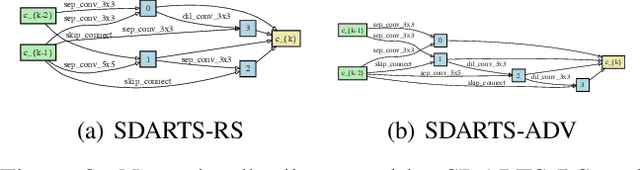
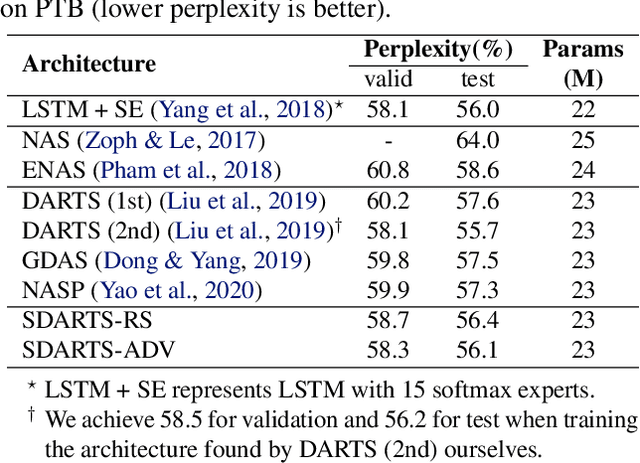
Differentiable architecture search (DARTS) is a prevailing NAS solution to identify architectures. Based on the continuous relaxation of the architecture space, DARTS learns a differentiable architecture weight and largely reduces the search cost. However, its stability and generalizability have been challenged for yielding deteriorating architectures as the search proceeds. We find that the precipitous validation loss landscape, which leads to a dramatic performance drop when distilling the final architecture, is an essential factor that causes instability. Based on this observation, we propose a perturbation-based regularization, named SmoothDARTS (SDARTS), to smooth the loss landscape and improve the generalizability of DARTS. In particular, our new formulations stabilize DARTS by either random smoothing or adversarial attack. The search trajectory on NAS-Bench-1Shot1 demonstrates the effectiveness of our approach and due to the improved stability, we achieve performance gain across various search spaces on 4 datasets. Furthermore, we mathematically show that SDARTS implicitly regularizes the Hessian norm of the validation loss, which accounts for a smoother loss landscape and improved performance. The code is available at https://github.com/xiangning-chen/SmoothDARTS.
GraphDefense: Towards Robust Graph Convolutional Networks
Nov 11, 2019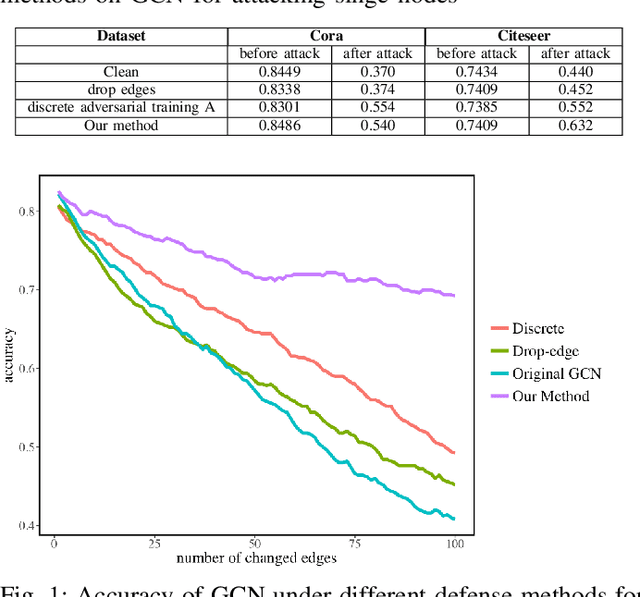
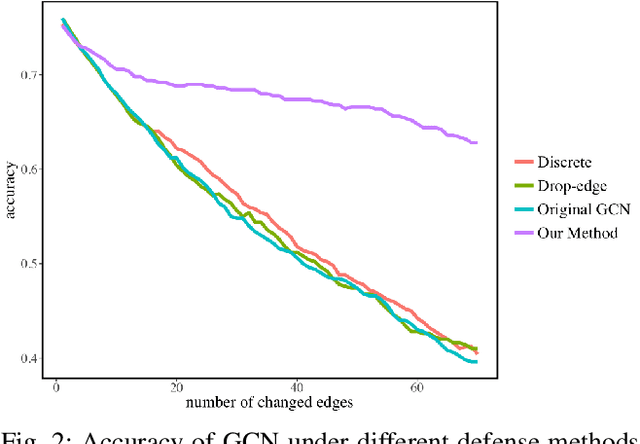
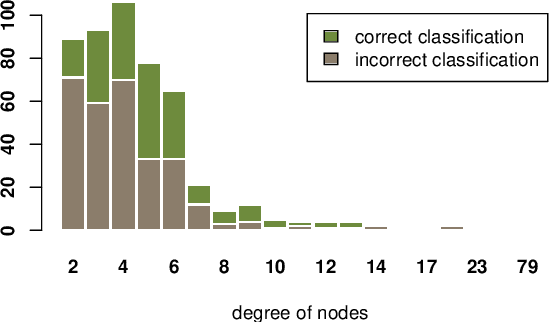
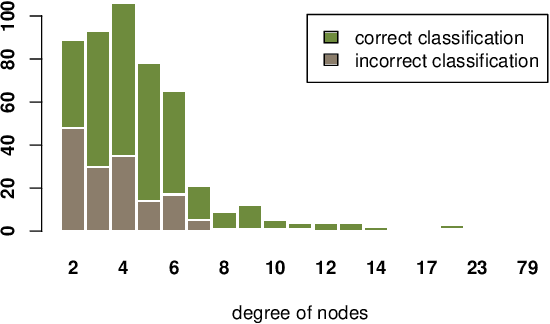
In this paper, we study the robustness of graph convolutional networks (GCNs). Despite the good performance of GCNs on graph semi-supervised learning tasks, previous works have shown that the original GCNs are very unstable to adversarial perturbations. In particular, we can observe a severe performance degradation by slightly changing the graph adjacency matrix or the features of a few nodes, making it unsuitable for security-critical applications. Inspired by the previous works on adversarial defense for deep neural networks, and especially adversarial training algorithm, we propose a method called GraphDefense to defend against the adversarial perturbations. In addition, for our defense method, we could still maintain semi-supervised learning settings, without a large label rate. We also show that adversarial training in features is equivalent to adversarial training for edges with a small perturbation. Our experiments show that the proposed defense methods successfully increase the robustness of Graph Convolutional Networks. Furthermore, we show that with careful design, our proposed algorithm can scale to large graphs, such as Reddit dataset.