 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Adversarial Attack and Defense for Classification Methods
Nov 18, 2021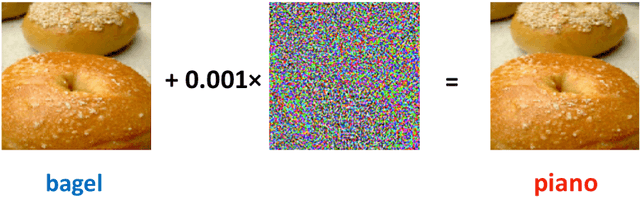
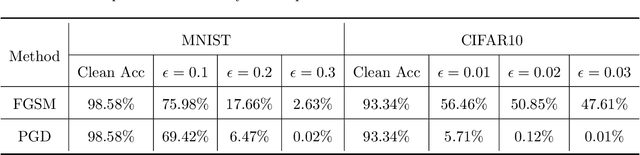
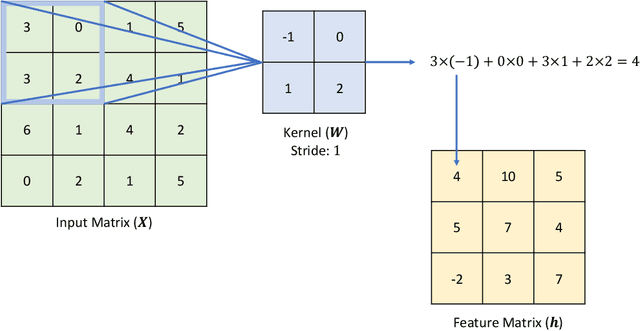
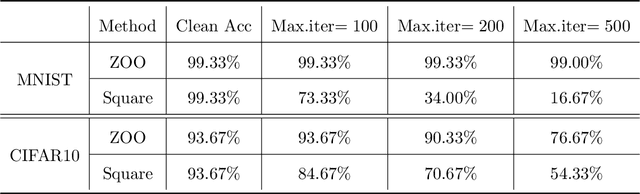
Despite the efficiency and scalability of machine learning systems, recent studies have demonstrated that many classification methods, especially deep neural networks (DNNs), are vulnerable to adversarial examples; i.e., examples that are carefully crafted to fool a well-trained classification model while being indistinguishable from natural data to human. This makes it potentially unsafe to apply DNNs or related methods in security-critical areas. Since this issue was first identified by Biggio et al. (2013) and Szegedy et al.(2014), much work has been done in this field, including the development of attack methods to generate adversarial examples and the construction of defense techniques to guard against such examples. This paper aims to introduce this topic and its latest developments to the statistical community, primarily focusing on the generation and guarding of adversarial examples. Computing codes (in python and R) used in the numerical experiments are publicly available for readers to explore the surveyed methods. It is the hope of the authors that this paper will encourage more statisticians to work on this important and exciting field of generating and defending against adversarial examples.
Can Vision Transformers Perform Convolution?
Nov 03, 2021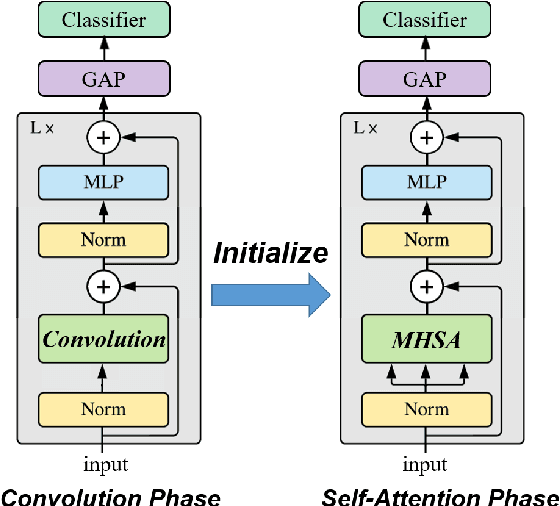
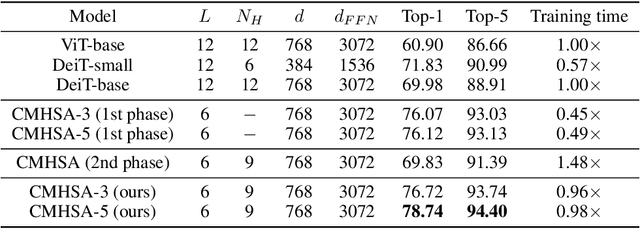
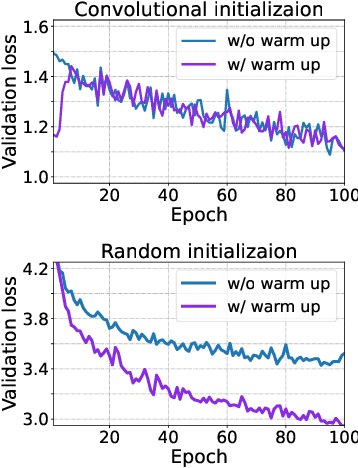
Several recent studies have demonstrated that attention-based networks, such as Vision Transformer (ViT), can outperform Convolutional Neural Networks (CNNs) on several computer vision tasks without using convolutional layers. This naturally leads to the following questions: Can a self-attention layer of ViT express any convolution operation? In this work, we prove that a single ViT layer with image patches as the input can perform any convolution operation constructively, where the multi-head attention mechanism and the relative positional encoding play essential roles. We further provide a lower bound on the number of heads for Vision Transformers to express CNNs. Corresponding with our analysis, experimental results show that the construction in our proof can help inject convolutional bias into Transformers and significantly improve the performance of ViT in low data regimes.
Node Feature Extraction by Self-Supervised Multi-scale Neighborhood Prediction
Oct 29, 2021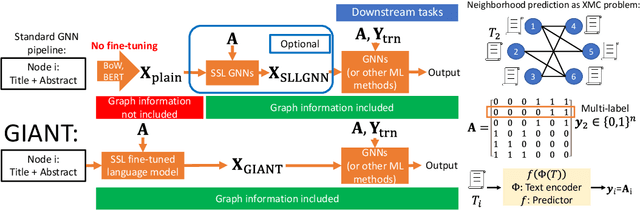

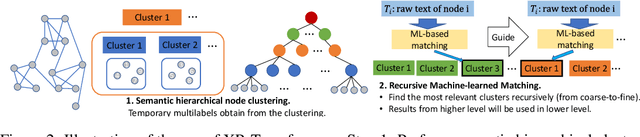
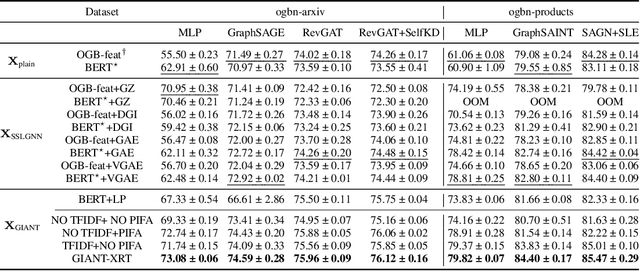
Learning on graphs has attracted significant attention in the learning community due to numerous real-world applications. In particular, graph neural networks (GNNs), which take numerical node features and graph structure as inputs, have been shown to achieve state-of-the-art performance on various graph-related learning tasks. Recent works exploring the correlation between numerical node features and graph structure via self-supervised learning have paved the way for further performance improvements of GNNs. However, methods used for extracting numerical node features from raw data are still graph-agnostic within standard GNN pipelines. This practice is sub-optimal as it prevents one from fully utilizing potential correlations between graph topology and node attributes. To mitigate this issue, we propose a new self-supervised learning framework, Graph Information Aided Node feature exTraction (GIANT). GIANT makes use of the eXtreme Multi-label Classification (XMC) formalism, which is crucial for fine-tuning the language model based on graph information, and scales to large datasets. We also provide a theoretical analysis that justifies the use of XMC over link prediction and motivates integrating XR-Transformers, a powerful method for solving XMC problems, into the GIANT framework. We demonstrate the superior performance of GIANT over the standard GNN pipeline on Open Graph Benchmark datasets: For example, we improve the accuracy of the top-ranked method GAMLP from $68.25\%$ to $69.67\%$, SGC from $63.29\%$ to $66.10\%$ and MLP from $47.24\%$ to $61.10\%$ on the ogbn-papers100M dataset by leveraging GIANT.
How and When Adversarial Robustness Transfers in Knowledge Distillation?
Oct 22, 2021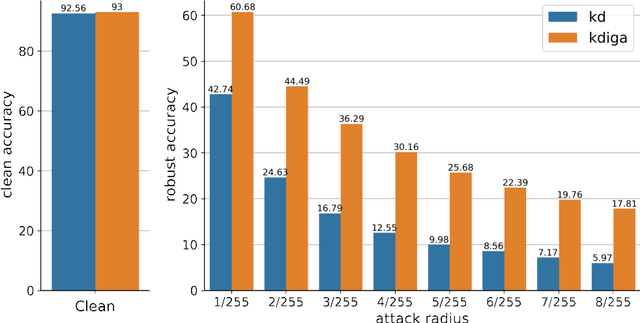
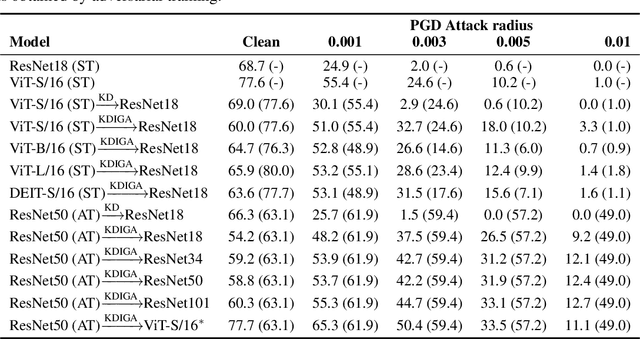
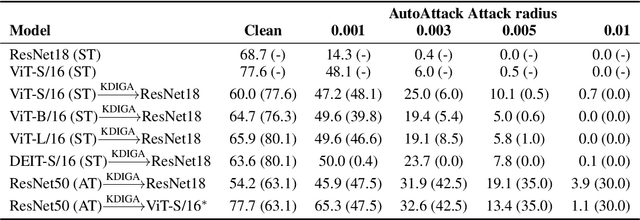
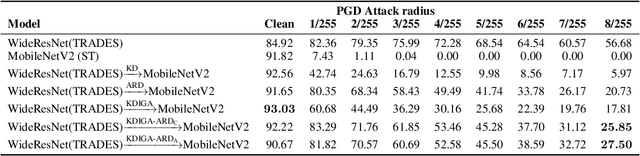
Knowledge distillation (KD) has been widely used in teacher-student training, with applications to model compression in resource-constrained deep learning. Current works mainly focus on preserving the accuracy of the teacher model. However, other important model properties, such as adversarial robustness, can be lost during distillation. This paper studies how and when the adversarial robustness can be transferred from a teacher model to a student model in KD. We show that standard KD training fails to preserve adversarial robustness, and we propose KD with input gradient alignment (KDIGA) for remedy. Under certain assumptions, we prove that the student model using our proposed KDIGA can achieve at least the same certified robustness as the teacher model. Our experiments of KD contain a diverse set of teacher and student models with varying network architectures and sizes evaluated on ImageNet and CIFAR-10 datasets, including residual neural networks (ResNets) and vision transformers (ViTs). Our comprehensive analysis shows several novel insights that (1) With KDIGA, students can preserve or even exceed the adversarial robustness of the teacher model, even when their models have fundamentally different architectures; (2) KDIGA enables robustness to transfer to pre-trained students, such as KD from an adversarially trained ResNet to a pre-trained ViT, without loss of clean accuracy; and (3) Our derived local linearity bounds for characterizing adversarial robustness in KD are consistent with the empirical results.
Adversarial Attack across Datasets
Oct 13, 2021
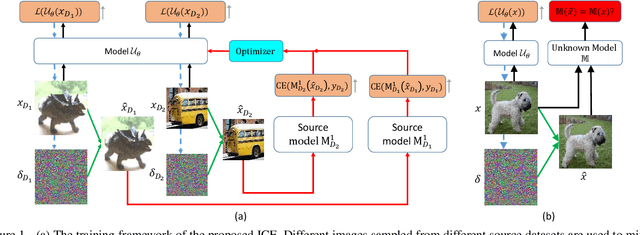
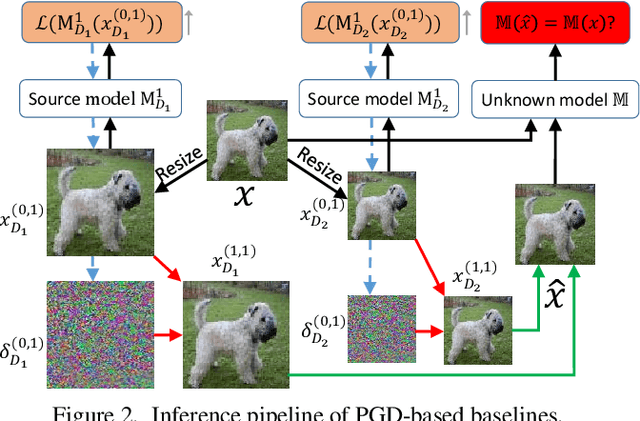
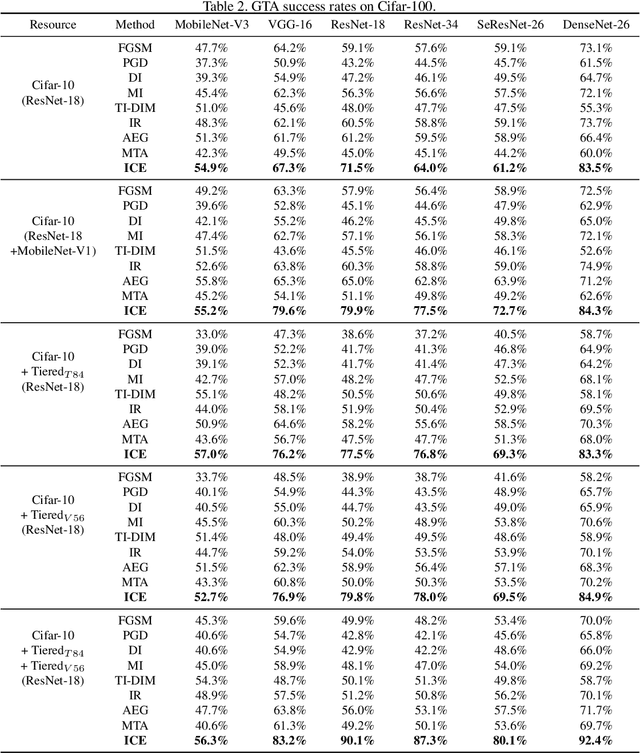
It has been observed that Deep Neural Networks (DNNs) are vulnerable to transfer attacks in the query-free black-box setting. However, all the previous studies on transfer attack assume that the white-box surrogate models possessed by the attacker and the black-box victim models are trained on the same dataset, which means the attacker implicitly knows the label set and the input size of the victim model. However, this assumption is usually unrealistic as the attacker may not know the dataset used by the victim model, and further, the attacker needs to attack any randomly encountered images that may not come from the same dataset. Therefore, in this paper we define a new Generalized Transferable Attack (GTA) problem where we assume the attacker has a set of surrogate models trained on different datasets (with different label sets and image sizes), and none of them is equal to the dataset used by the victim model. We then propose a novel method called Image Classification Eraser (ICE) to erase classification information for any encountered images from arbitrary dataset. Extensive experiments on Cifar-10, Cifar-100, and TieredImageNet demonstrate the effectiveness of the proposed ICE on the GTA problem. Furthermore, we show that existing transfer attack methods can be modified to tackle the GTA problem, but with significantly worse performance compared with ICE.
Training Meta-Surrogate Model for Transferable Adversarial Attack
Sep 07, 2021
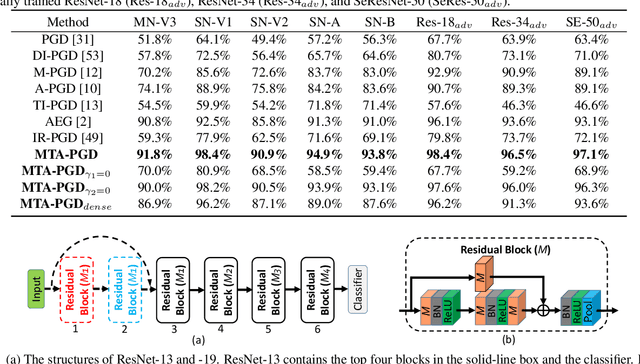
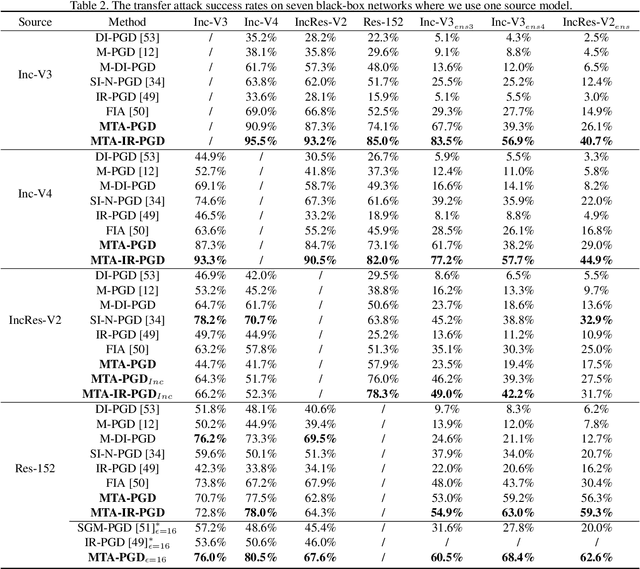
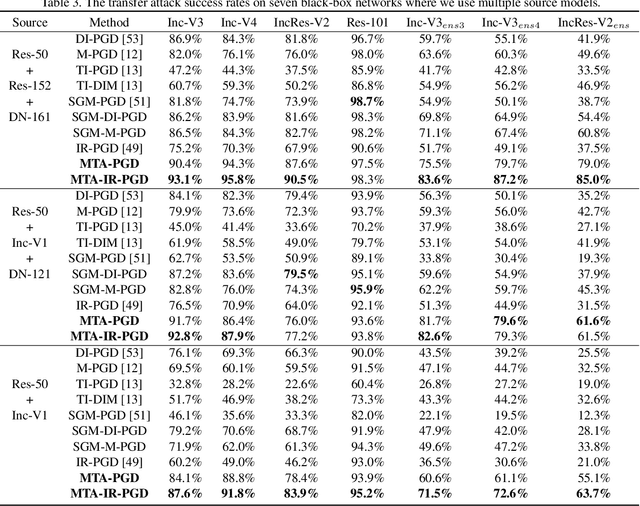
We consider adversarial attacks to a black-box model when no queries are allowed. In this setting, many methods directly attack surrogate models and transfer the obtained adversarial examples to fool the target model. Plenty of previous works investigated what kind of attacks to the surrogate model can generate more transferable adversarial examples, but their performances are still limited due to the mismatches between surrogate models and the target model. In this paper, we tackle this problem from a novel angle -- instead of using the original surrogate models, can we obtain a Meta-Surrogate Model (MSM) such that attacks to this model can be easier transferred to other models? We show that this goal can be mathematically formulated as a well-posed (bi-level-like) optimization problem and design a differentiable attacker to make training feasible. Given one or a set of surrogate models, our method can thus obtain an MSM such that adversarial examples generated on MSM enjoy eximious transferability. Comprehensive experiments on Cifar-10 and ImageNet demonstrate that by attacking the MSM, we can obtain stronger transferable adversarial examples to fool black-box models including adversarially trained ones, with much higher success rates than existing methods. The proposed method reveals significant security challenges of deep models and is promising to be served as a state-of-the-art benchmark for evaluating the robustness of deep models in the black-box setting.
Searching for an Effective Defender: Benchmarking Defense against Adversarial Word Substitution
Aug 29, 2021
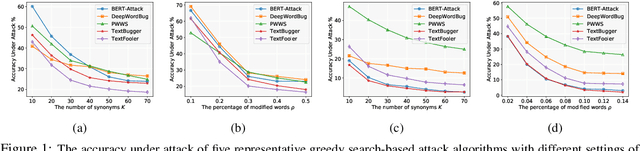
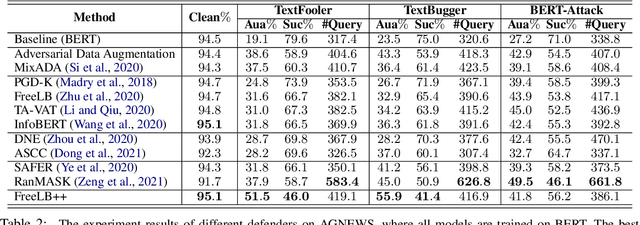
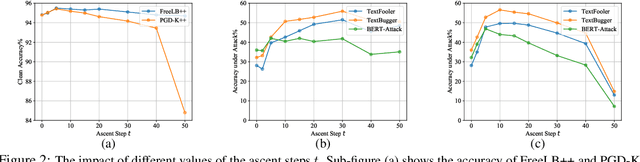
Recent studies have shown that deep neural networks are vulnerable to intentionally crafted adversarial examples, and various methods have been proposed to defend against adversarial word-substitution attacks for neural NLP models. However, there is a lack of systematic study on comparing different defense approaches under the same attacking setting. In this paper, we seek to fill the gap of systematic studies through comprehensive researches on understanding the behavior of neural text classifiers trained by various defense methods under representative adversarial attacks. In addition, we propose an effective method to further improve the robustness of neural text classifiers against such attacks and achieved the highest accuracy on both clean and adversarial examples on AGNEWS and IMDB datasets by a significant margin.
RANK-NOSH: Efficient Predictor-Based Architecture Search via Non-Uniform Successive Halving
Aug 18, 2021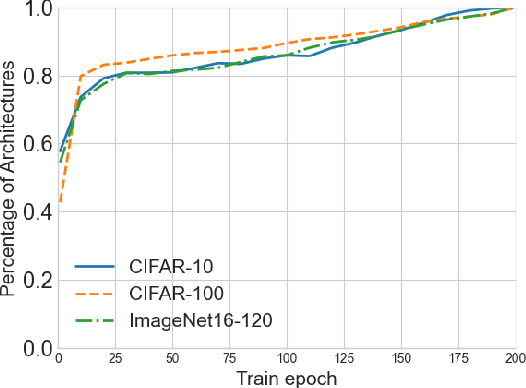
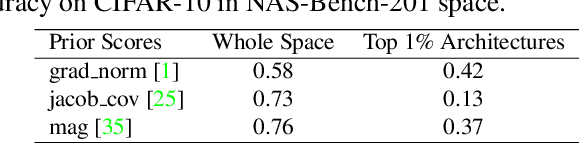
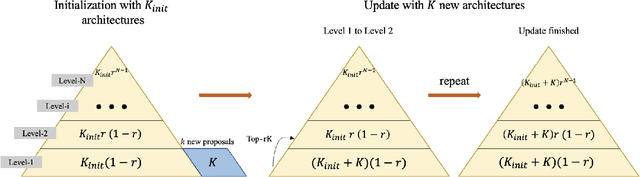
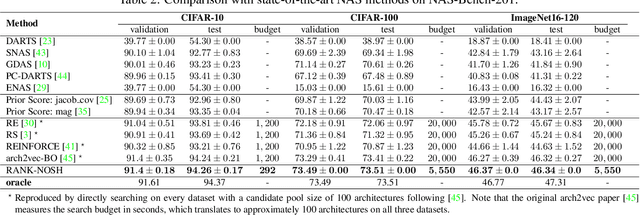
Predictor-based algorithms have achieved remarkable performance in the Neural Architecture Search (NAS) tasks. However, these methods suffer from high computation costs, as training the performance predictor usually requires training and evaluating hundreds of architectures from scratch. Previous works along this line mainly focus on reducing the number of architectures required to fit the predictor. In this work, we tackle this challenge from a different perspective - improve search efficiency by cutting down the computation budget of architecture training. We propose NOn-uniform Successive Halving (NOSH), a hierarchical scheduling algorithm that terminates the training of underperforming architectures early to avoid wasting budget. To effectively leverage the non-uniform supervision signals produced by NOSH, we formulate predictor-based architecture search as learning to rank with pairwise comparisons. The resulting method - RANK-NOSH, reduces the search budget by ~5x while achieving competitive or even better performance than previous state-of-the-art predictor-based methods on various spaces and datasets.
RandomRooms: Unsupervised Pre-training from Synthetic Shapes and Randomized Layouts for 3D Object Detection
Aug 17, 2021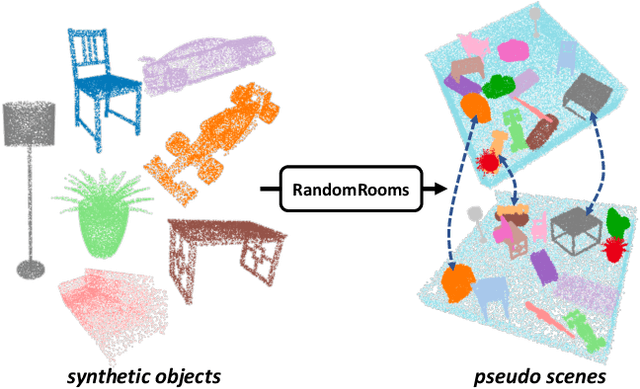

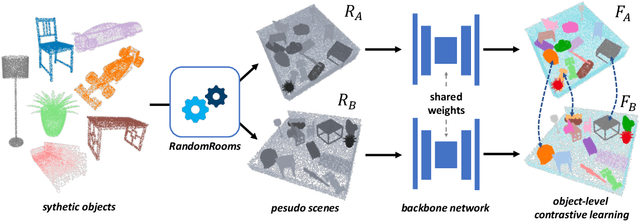
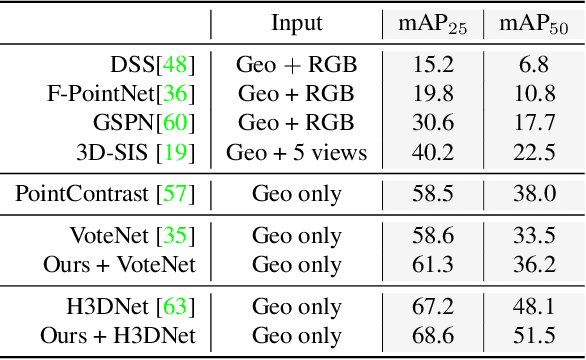
3D point cloud understanding has made great progress in recent years. However, one major bottleneck is the scarcity of annotated real datasets, especially compared to 2D object detection tasks, since a large amount of labor is involved in annotating the real scans of a scene. A promising solution to this problem is to make better use of the synthetic dataset, which consists of CAD object models, to boost the learning on real datasets. This can be achieved by the pre-training and fine-tuning procedure. However, recent work on 3D pre-training exhibits failure when transfer features learned on synthetic objects to other real-world applications. In this work, we put forward a new method called RandomRooms to accomplish this objective. In particular, we propose to generate random layouts of a scene by making use of the objects in the synthetic CAD dataset and learn the 3D scene representation by applying object-level contrastive learning on two random scenes generated from the same set of synthetic objects. The model pre-trained in this way can serve as a better initialization when later fine-tuning on the 3D object detection task. Empirically, we show consistent improvement in downstream 3D detection tasks on several base models, especially when less training data are used, which strongly demonstrates the effectiveness and generalization of our method. Benefiting from the rich semantic knowledge and diverse objects from synthetic data, our method establishes the new state-of-the-art on widely-used 3D detection benchmarks ScanNetV2 and SUN RGB-D. We expect our attempt to provide a new perspective for bridging object and scene-level 3D understanding.
Rethinking Architecture Selection in Differentiable NAS
Aug 10, 2021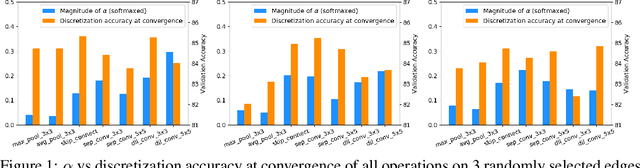
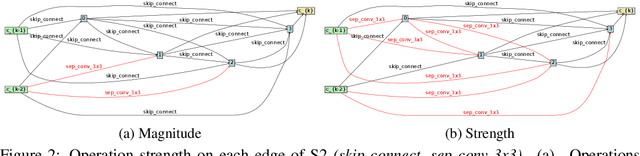
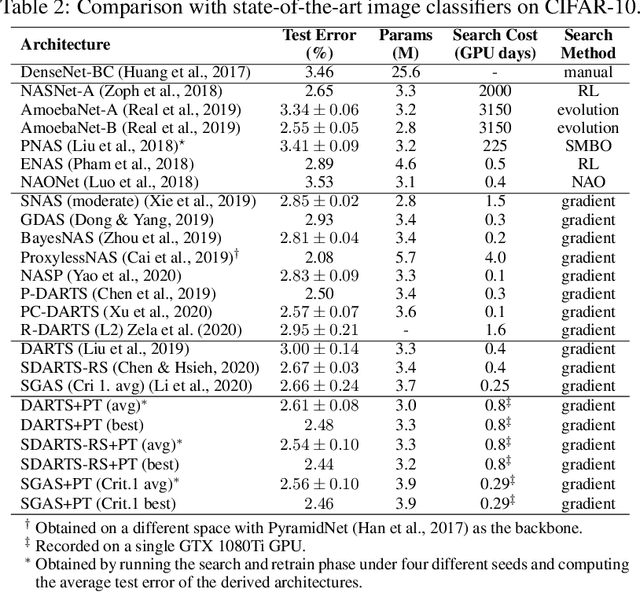

Differentiable Neural Architecture Search is one of the most popular Neural Architecture Search (NAS) methods for its search efficiency and simplicity, accomplished by jointly optimizing the model weight and architecture parameters in a weight-sharing supernet via gradient-based algorithms. At the end of the search phase, the operations with the largest architecture parameters will be selected to form the final architecture, with the implicit assumption that the values of architecture parameters reflect the operation strength. While much has been discussed about the supernet's optimization, the architecture selection process has received little attention. We provide empirical and theoretical analysis to show that the magnitude of architecture parameters does not necessarily indicate how much the operation contributes to the supernet's performance. We propose an alternative perturbation-based architecture selection that directly measures each operation's influence on the supernet. We re-evaluate several differentiable NAS methods with the proposed architecture selection and find that it is able to extract significantly improved architectures from the underlying supernets consistently. Furthermore, we find that several failure modes of DARTS can be greatly alleviated with the proposed selection method, indicating that much of the poor generalization observed in DARTS can be attributed to the failure of magnitude-based architecture selection rather than entirely the optimization of its supernet.