 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
DeSTA2.5-Audio: Toward General-Purpose Large Audio Language Model with Self-Generated Cross-Modal Alignment
Jul 03, 2025We introduce DeSTA2.5-Audio, a general-purpose Large Audio Language Model (LALM) designed for robust auditory perception and instruction-following, without requiring task-specific audio instruction-tuning. Recent LALMs typically augment Large Language Models (LLMs) with auditory capabilities by training on large-scale, manually curated or LLM-synthesized audio-instruction datasets. However, these approaches have often suffered from the catastrophic forgetting of the LLM's original language abilities. To address this, we revisit the data construction pipeline and propose DeSTA, a self-generated cross-modal alignment strategy in which the backbone LLM generates its own training targets. This approach preserves the LLM's native language proficiency while establishing effective audio-text alignment, thereby enabling zero-shot generalization without task-specific tuning. Using DeSTA, we construct DeSTA-AQA5M, a large-scale, task-agnostic dataset containing 5 million training samples derived from 7,000 hours of audio spanning 50 diverse datasets, including speech, environmental sounds, and music. DeSTA2.5-Audio achieves state-of-the-art or competitive performance across a wide range of audio-language benchmarks, including Dynamic-SUPERB, MMAU, SAKURA, Speech-IFEval, and VoiceBench. Comprehensive comparative studies demonstrate that our self-generated strategy outperforms widely adopted data construction and training strategies in both auditory perception and instruction-following capabilities. Our findings underscore the importance of carefully designed data construction in LALM development and offer practical insights for building robust, general-purpose LALMs.
Fusion of Discrete Representations and Self-Augmented Representations for Multilingual Automatic Speech Recognition
Nov 27, 2024



Self-supervised learning (SSL) models have shown exceptional capabilities across various speech-processing tasks. Continuous SSL representations are effective but suffer from high computational and storage demands. On the other hand, discrete SSL representations, although with degraded performance, reduce transmission and storage costs, and improve input sequence efficiency through de-duplication and subword-modeling. To boost the performance of discrete representations for ASR, we introduce a novel fusion mechanism that integrates two discrete representations. The fusion mechanism preserves all the benefits of discrete representation while enhancing the model's performance by integrating complementary information. Additionally, we explore "self-augmented'' discrete representations, which apply transformations to a single continuous SSL representation, eliminating the fusion mechanism's dependency on multiple SSL models and further decreasing its inference costs. Experimental results on benchmarks, including LibriSpeech and ML-SUPERB, indicate up to 19% and 24% relative character error rate improvement compared with the non-fusion baseline, validating the effectiveness of our proposed methods.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
SpeechCaps: Advancing Instruction-Based Universal Speech Models with Multi-Talker Speaking Style Captioning
Aug 25, 2024



Instruction-based speech processing is becoming popular. Studies show that training with multiple tasks boosts performance, but collecting diverse, large-scale tasks and datasets is expensive. Thus, it is highly desirable to design a fundamental task that benefits other downstream tasks. This paper introduces a multi-talker speaking style captioning task to enhance the understanding of speaker and prosodic information. We used large language models to generate descriptions for multi-talker speech. Then, we trained our model with pre-training on this captioning task followed by instruction tuning. Evaluation on Dynamic-SUPERB shows our model outperforming the baseline pre-trained only on single-talker tasks, particularly in speaker and emotion recognition. Additionally, tests on a multi-talker QA task reveal that current models struggle with attributes such as gender, pitch, and speaking rate. The code and dataset are available at https://github.com/cyhuang-tw/speechcaps.
Prompting and Adapter Tuning for Self-supervised Encoder-Decoder Speech Model
Oct 04, 2023



Prompting and adapter tuning have emerged as efficient alternatives to fine-tuning (FT) methods. However, existing studies on speech prompting focused on classification tasks and failed on more complex sequence generation tasks. Besides, adapter tuning is primarily applied with a focus on encoder-only self-supervised models. Our experiments show that prompting on Wav2Seq, a self-supervised encoder-decoder model, surpasses previous works in sequence generation tasks. It achieves a remarkable 53% relative improvement in word error rate for ASR and a 27% in F1 score for slot filling. Additionally, prompting competes with the FT method in the low-resource scenario. Moreover, we show the transferability of prompting and adapter tuning on Wav2Seq in cross-lingual ASR. When limited trainable parameters are involved, prompting and adapter tuning consistently outperform conventional FT across 7 languages. Notably, in the low-resource scenario, prompting consistently outperforms adapter tuning.
Dynamic-SUPERB: Towards A Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark for Speech
Sep 18, 2023



Text language models have shown remarkable zero-shot capability in generalizing to unseen tasks when provided with well-formulated instructions. However, existing studies in speech processing primarily focus on limited or specific tasks. Moreover, the lack of standardized benchmarks hinders a fair comparison across different approaches. Thus, we present Dynamic-SUPERB, a benchmark designed for building universal speech models capable of leveraging instruction tuning to perform multiple tasks in a zero-shot fashion. To achieve comprehensive coverage of diverse speech tasks and harness instruction tuning, we invite the community to collaborate and contribute, facilitating the dynamic growth of the benchmark. To initiate, Dynamic-SUPERB features 55 evaluation instances by combining 33 tasks and 22 datasets. This spans a broad spectrum of dimensions, providing a comprehensive platform for evaluation. Additionally, we propose several approaches to establish benchmark baselines. These include the utilization of speech models, text language models, and the multimodal encoder. Evaluation results indicate that while these baselines perform reasonably on seen tasks, they struggle with unseen ones. We also conducted an ablation study to assess the robustness and seek improvements in the performance. We release all materials to the public and welcome researchers to collaborate on the project, advancing technologies in the field together.
Toward Degradation-Robust Voice Conversion
Oct 14, 2021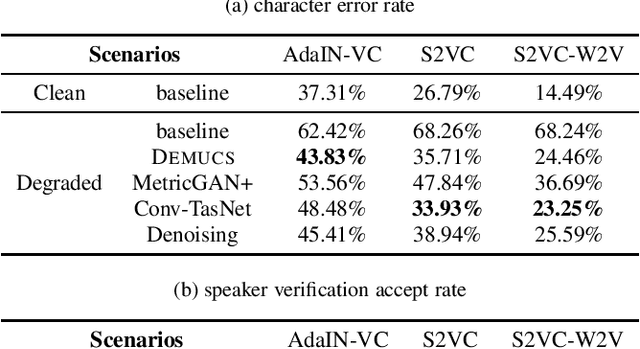
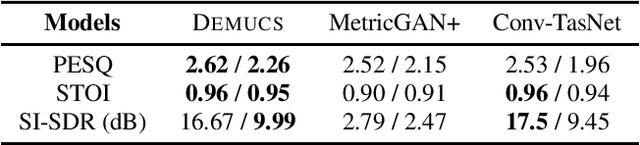


Any-to-any voice conversion technologies convert the vocal timbre of an utterance to any speaker even unseen during training. Although there have been several state-of-the-art any-to-any voice conversion models, they were all based on clean utterances to convert successfully. However, in real-world scenarios, it is difficult to collect clean utterances of a speaker, and they are usually degraded by noises or reverberations. It thus becomes highly desired to understand how these degradations affect voice conversion and build a degradation-robust model. We report in this paper the first comprehensive study on the degradation robustness of any-to-any voice conversion. We show that the performance of state-of-the-art models nowadays was severely hampered given degraded utterances. To this end, we then propose speech enhancement concatenation and denoising training to improve the robustness. In addition to common degradations, we also consider adversarial noises, which alter the model output significantly yet are human-imperceptible. It was shown that both concatenations with off-the-shelf speech enhancement models and denoising training on voice conversion models could improve the robustness, while each of them had pros and cons.
Improving Cross-Lingual Reading Comprehension with Self-Training
May 08, 2021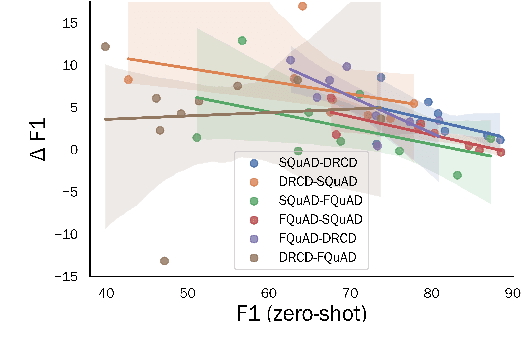

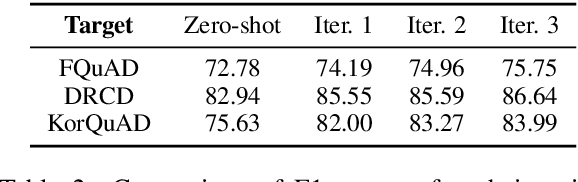
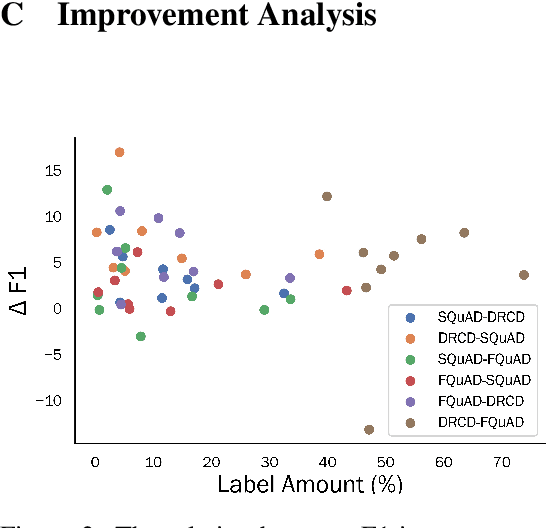
Substantial improvements have been made in machine reading comprehension, where the machine answers questions based on a given context. Current state-of-the-art models even surpass human performance on several benchmarks. However, their abilities in the cross-lingual scenario are still to be explored. Previous works have revealed the abilities of pre-trained multilingual models for zero-shot cross-lingual reading comprehension. In this paper, we further utilized unlabeled data to improve the performance. The model is first supervised-trained on source language corpus, and then self-trained with unlabeled target language data. The experiment results showed improvements for all languages, and we also analyzed how self-training benefits cross-lingual reading comprehension in qualitative aspects.
Utilizing Self-supervised Representations for MOS Prediction
Apr 21, 2021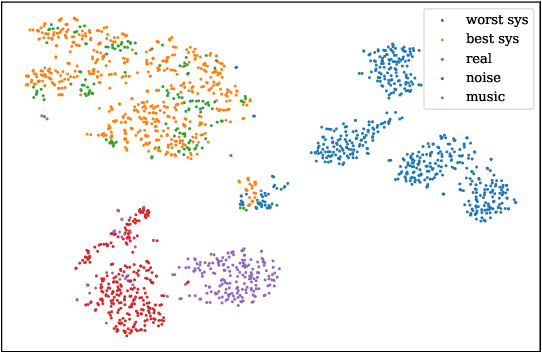
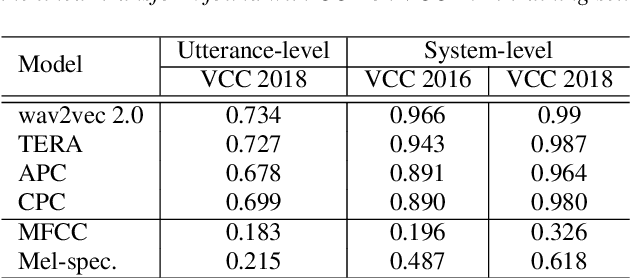
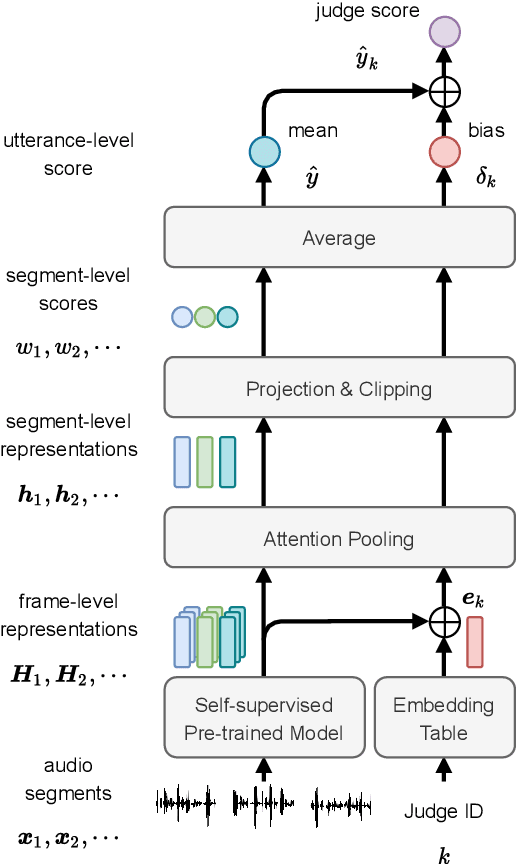
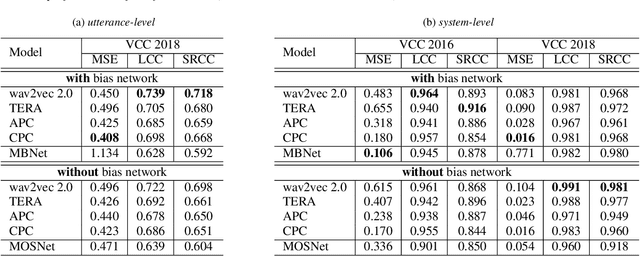
Speech quality assessment has been a critical issue in speech processing for decades. Existing automatic evaluations usually require clean references or parallel ground truth data, which is infeasible when the amount of data soars. Subjective tests, on the other hand, do not need any additional clean or parallel data and correlates better to human perception. However, such a test is expensive and time-consuming because crowd work is necessary. It thus becomes highly desired to develop an automatic evaluation approach that correlates well with human perception while not requiring ground truth data. In this paper, we use self-supervised pre-trained models for MOS prediction. We show their representations can distinguish between clean and noisy audios. Then, we fine-tune these pre-trained models followed by simple linear layers in an end-to-end manner. The experiment results showed that our framework outperforms the two previous state-of-the-art models by a significant improvement on Voice Conversion Challenge 2018 and achieves comparable or superior performance on Voice Conversion Challenge 2016. We also conducted an ablation study to further investigate how each module benefits the task. The experiment results are implemented and reproducible with publicly available toolkits.