 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Zero-Shot Dense Retrievers with Plug-in Mixture-of-Memories
Feb 07, 2023



In this paper we improve the zero-shot generalization ability of language models via Mixture-Of-Memory Augmentation (MoMA), a mechanism that retrieves augmentation documents from multiple information corpora ("external memories"), with the option to "plug in" new memory at inference time. We develop a joint learning mechanism that trains the augmentation component with latent labels derived from the end retrieval task, paired with hard negatives from the memory mixture. We instantiate the model in a zero-shot dense retrieval setting by augmenting a strong T5-based retriever with MoMA. Our model, MoMA, obtains strong zero-shot retrieval accuracy on the eighteen tasks included in the standard BEIR benchmark. It outperforms systems that seek generalization from increased model parameters and computation steps. Our analysis further illustrates the necessity of augmenting with mixture-of-memory for robust generalization, the benefits of augmentation learning, and how MoMA utilizes the plug-in memory at inference time without changing its parameters. We plan to open source our code.
ClueWeb22: 10 Billion Web Documents with Visual and Semantic Information
Dec 02, 2022



ClueWeb22, the newest iteration of the ClueWeb line of datasets, provides 10 billion web pages affiliated with rich information. Its design was influenced by the need for a high quality, large scale web corpus to support a range of academic and industry research, for example, in information systems, retrieval-augmented AI systems, and model pretraining. Compared with earlier ClueWeb corpora, the ClueWeb22 corpus is larger, more varied, of higher-quality, and aligned with the document distributions in commercial web search. Besides raw HTML, ClueWeb22 includes rich information about the web pages provided by industry-standard document understanding systems, including the visual representation of pages rendered by a web browser, parsed HTML structure information from a neural network parser, and pre-processed cleaned document text to lower the barrier to entry. Many of these signals have been widely used in industry but are available to the research community for the first time at this scale.
Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives
Oct 31, 2022



In this paper, we investigate the instability in the standard dense retrieval training, which iterates between model training and hard negative selection using the being-trained model. We show the catastrophic forgetting phenomena behind the training instability, where models learn and forget different negative groups during training iterations. We then propose ANCE-Tele, which accumulates momentum negatives from past iterations and approximates future iterations using lookahead negatives, as "teleportations" along the time axis to smooth the learning process. On web search and OpenQA, ANCE-Tele outperforms previous state-of-the-art systems of similar size, eliminates the dependency on sparse retrieval negatives, and is competitive among systems using significantly more (50x) parameters. Our analysis demonstrates that teleportation negatives reduce catastrophic forgetting and improve convergence speed for dense retrieval training. Our code is available at https://github.com/OpenMatch/ANCE-Tele.
COCO-DR: Combating Distribution Shifts in Zero-Shot Dense Retrieval with Contrastive and Distributionally Robust Learning
Oct 27, 2022



We present a new zero-shot dense retrieval (ZeroDR) method, COCO-DR, to improve the generalization ability of dense retrieval by combating the distribution shifts between source training tasks and target scenarios. To mitigate the impact of document differences, COCO-DR continues pretraining the language model on the target corpora to adapt the model to target distributions via COtinuous COtrastive learning. To prepare for unseen target queries, COCO-DR leverages implicit Distributionally Robust Optimization (iDRO) to reweight samples from different source query clusters for improving model robustness over rare queries during fine-tuning. COCO-DR achieves superior average performance on BEIR, the zero-shot retrieval benchmark. At BERT Base scale, COCO-DR Base outperforms other ZeroDR models with 60x larger size. At BERT Large scale, COCO-DR Large outperforms the giant GPT-3 embedding model which has 500x more parameters. Our analysis show the correlation between COCO-DR's effectiveness in combating distribution shifts and improving zero-shot accuracy. Our code and model can be found at \url{https://github.com/OpenMatch/COCO-DR}.
* EMNLP 2022 Main Conference (Code and Model can be found at https://github.com/OpenMatch/COCO-DR)
Dimension Reduction for Efficient Dense Retrieval via Conditional Autoencoder
May 06, 2022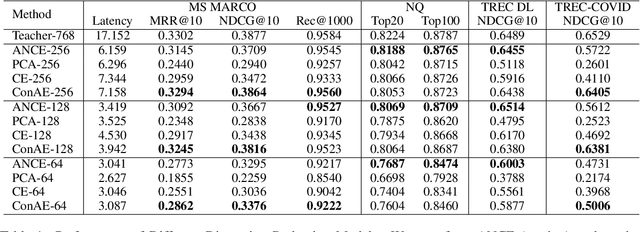
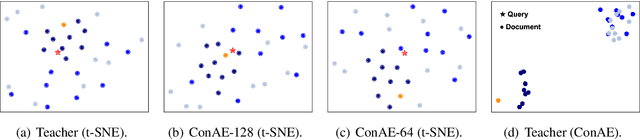
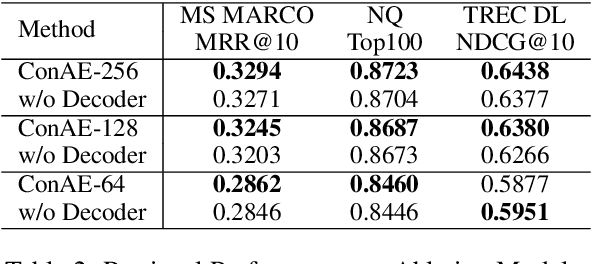
Dense retrievers encode texts and map them in an embedding space using pre-trained language models. These embeddings are critical to keep high-dimensional for effectively training dense retrievers, but lead to a high cost of storing index and retrieval. To reduce the embedding dimensions of dense retrieval, this paper proposes a Conditional Autoencoder (ConAE) to compress the high-dimensional embeddings to maintain the same embedding distribution and better recover the ranking features. Our experiments show the effectiveness of ConAE in compressing embeddings by achieving comparable ranking performance with the raw ones, making the retrieval system more efficient. Our further analyses show that ConAE can mitigate the redundancy of the embeddings of dense retrieval with only one linear layer. All codes of this work are available at https://github.com/NEUIR/ConAE.
P^3 Ranker: Mitigating the Gaps between Pre-training and Ranking Fine-tuning with Prompt-based Learning and Pre-finetuning
May 05, 2022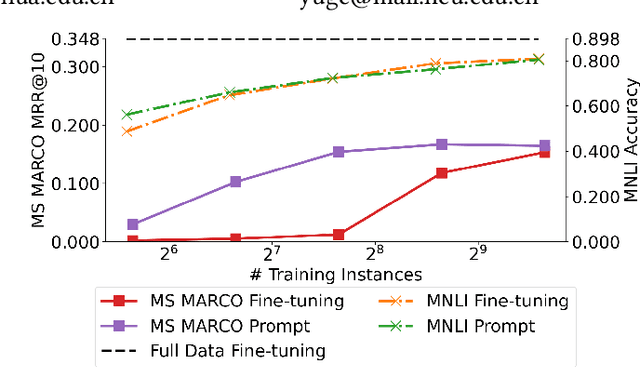
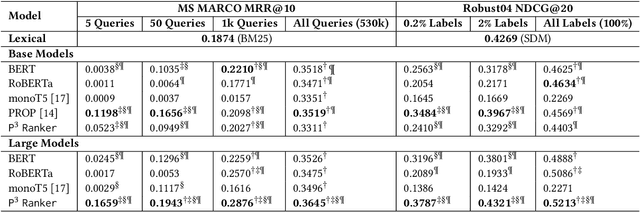
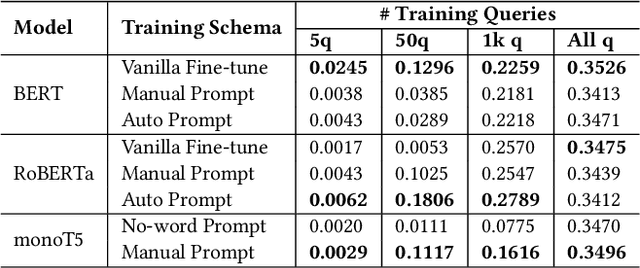
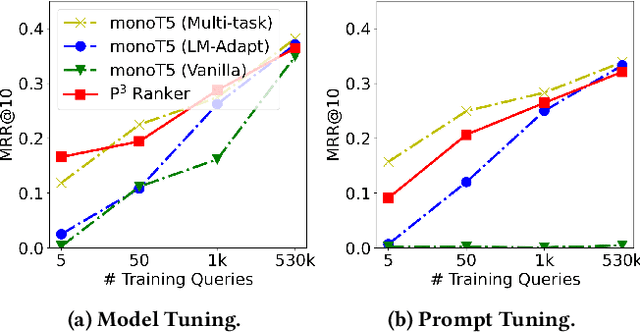
Compared to other language tasks, applying pre-trained language models (PLMs) for search ranking often requires more nuances and training signals. In this paper, we identify and study the two mismatches between pre-training and ranking fine-tuning: the training schema gap regarding the differences in training objectives and model architectures, and the task knowledge gap considering the discrepancy between the knowledge needed in ranking and that learned during pre-training. To mitigate these gaps, we propose Pre-trained, Prompt-learned and Pre-finetuned Neural Ranker (P^3 Ranker). P^3 Ranker leverages prompt-based learning to convert the ranking task into a pre-training like schema and uses pre-finetuning to initialize the model on intermediate supervised tasks. Experiments on MS MARCO and Robust04 show the superior performances of P^3 Ranker in few-shot ranking. Analyses reveal that P^3 Ranker is able to better accustom to the ranking task through prompt-based learning and retrieve necessary ranking-oriented knowledge gleaned in pre-finetuning, resulting in data-efficient PLM adaptation. Our code is available at https://github.com/NEUIR/P3Ranker.
METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals
Apr 16, 2022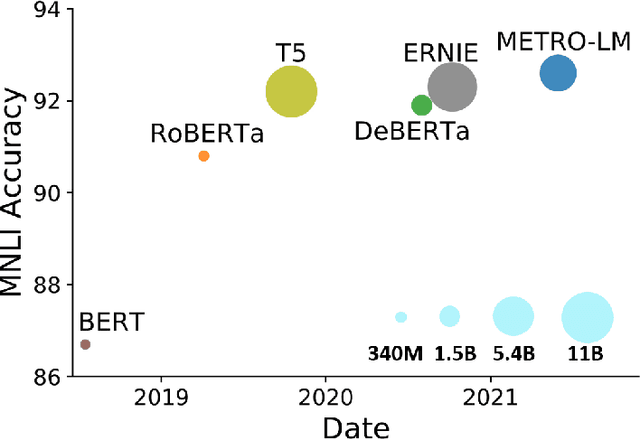
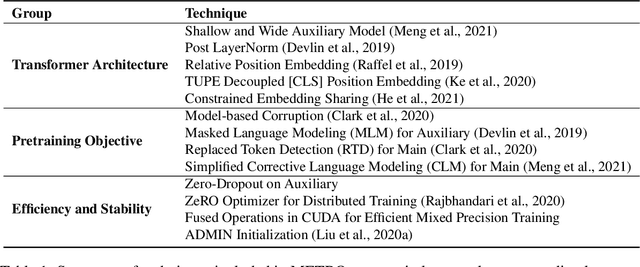
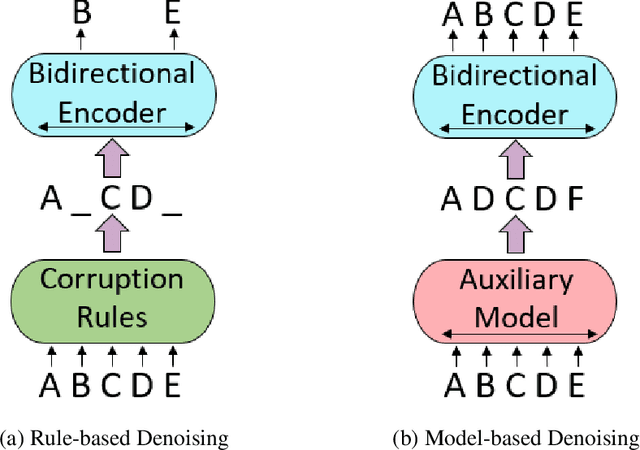
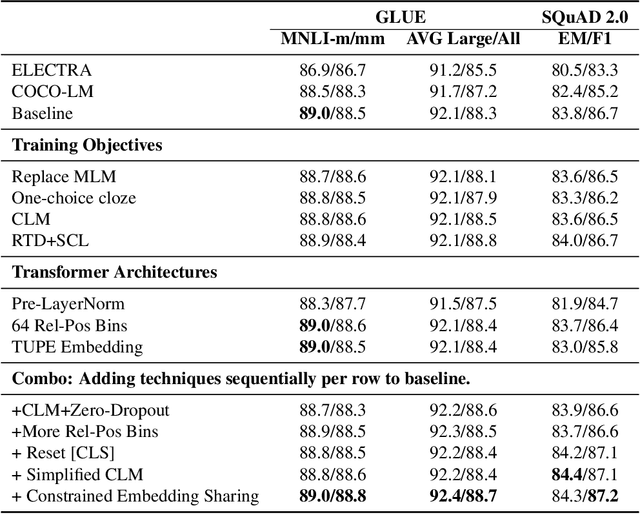
We present an efficient method of pretraining large-scale autoencoding language models using training signals generated by an auxiliary model. Originated in ELECTRA, this training strategy has demonstrated sample-efficiency to pretrain models at the scale of hundreds of millions of parameters. In this work, we conduct a comprehensive empirical study, and propose a recipe, namely "Model generated dEnoising TRaining Objective" (METRO), which incorporates some of the best modeling techniques developed recently to speed up, stabilize, and enhance pretrained language models without compromising model effectiveness. The resultant models, METRO-LM, consisting of up to 5.4 billion parameters, achieve new state-of-the-art on the GLUE, SuperGLUE, and SQuAD benchmarks. More importantly, METRO-LM are efficient in that they often outperform previous large models with significantly smaller model sizes and lower pretraining cost.
Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
Apr 07, 2022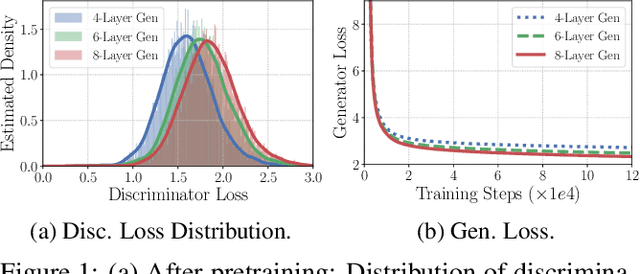
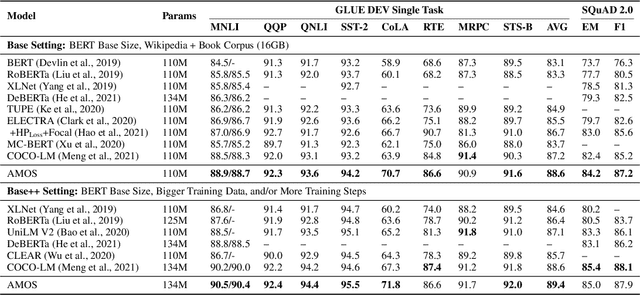
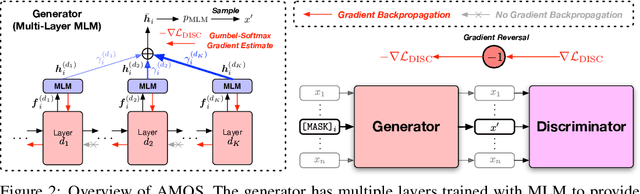
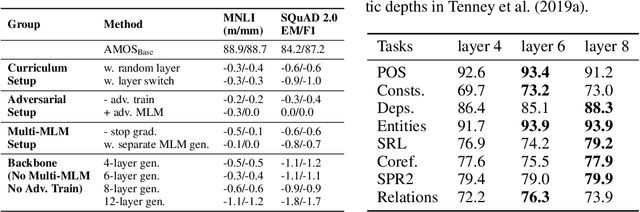
We present a new framework AMOS that pretrains text encoders with an Adversarial learning curriculum via a Mixture Of Signals from multiple auxiliary generators. Following ELECTRA-style pretraining, the main encoder is trained as a discriminator to detect replaced tokens generated by auxiliary masked language models (MLMs). Different from ELECTRA which trains one MLM as the generator, we jointly train multiple MLMs of different sizes to provide training signals at various levels of difficulty. To push the discriminator to learn better with challenging replaced tokens, we learn mixture weights over the auxiliary MLMs' outputs to maximize the discriminator loss by backpropagating the gradient from the discriminator via Gumbel-Softmax. For better pretraining efficiency, we propose a way to assemble multiple MLMs into one unified auxiliary model. AMOS outperforms ELECTRA and recent state-of-the-art pretrained models by about 1 point on the GLUE benchmark for BERT base-sized models.
Neural Approaches to Conversational Information Retrieval
Jan 13, 2022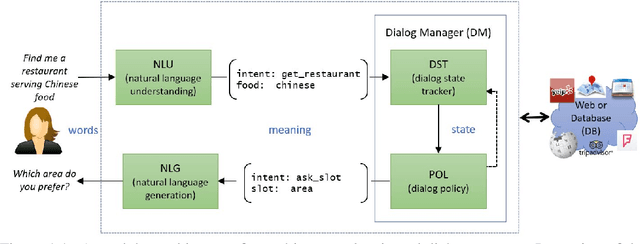
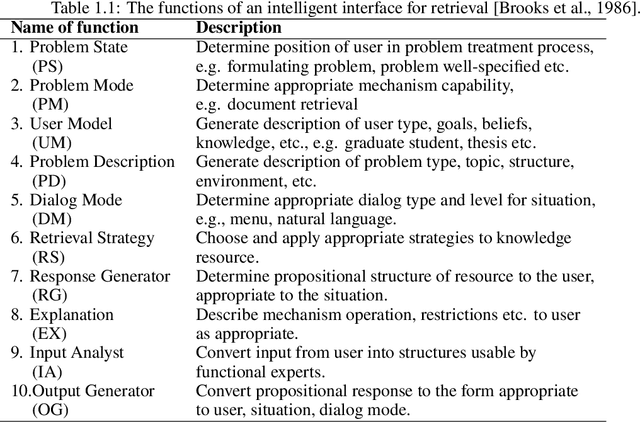
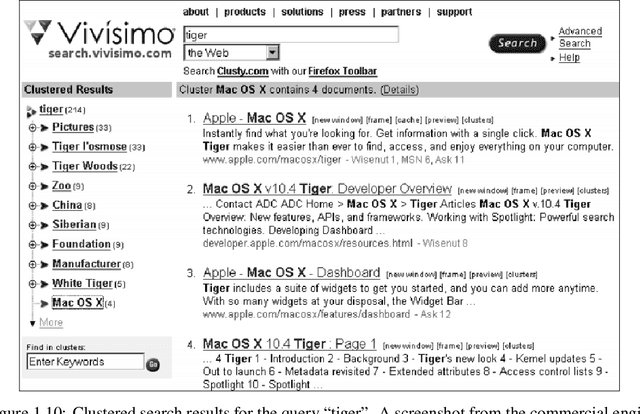

A conversational information retrieval (CIR) system is an information retrieval (IR) system with a conversational interface which allows users to interact with the system to seek information via multi-turn conversations of natural language, in spoken or written form. Recent progress in deep learning has brought tremendous improvements in natural language processing (NLP) and conversational AI, leading to a plethora of commercial conversational services that allow naturally spoken and typed interaction, increasing the need for more human-centric interactions in IR. As a result, we have witnessed a resurgent interest in developing modern CIR systems in both research communities and industry. This book surveys recent advances in CIR, focusing on neural approaches that have been developed in the last few years. This book is based on the authors' tutorial at SIGIR'2020 (Gao et al., 2020b), with IR and NLP communities as the primary target audience. However, audiences with other background, such as machine learning and human-computer interaction, will also find it an accessible introduction to CIR. We hope that this book will prove a valuable resource for students, researchers, and software developers. This manuscript is a working draft. Comments are welcome.
Zero-Shot Dense Retrieval with Momentum Adversarial Domain Invariant Representations
Oct 14, 2021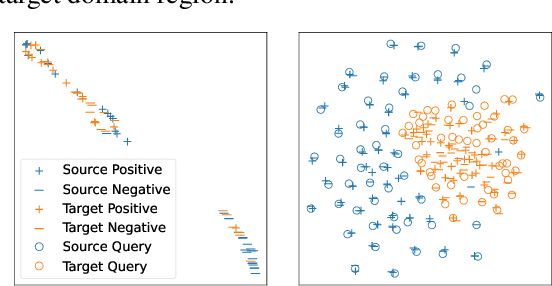
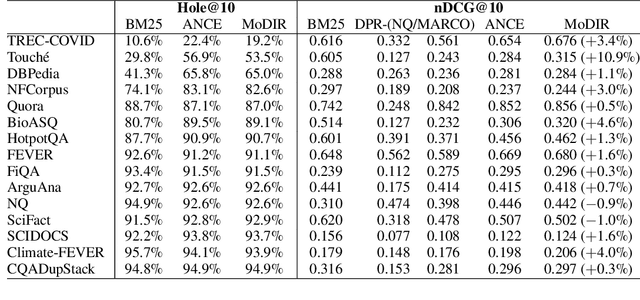
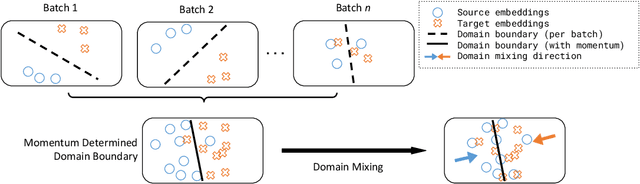

Dense retrieval (DR) methods conduct text retrieval by first encoding texts in the embedding space and then matching them by nearest neighbor search. This requires strong locality properties from the representation space, i.e, the close allocations of each small group of relevant texts, which are hard to generalize to domains without sufficient training data. In this paper, we aim to improve the generalization ability of DR models from source training domains with rich supervision signals to target domains without any relevant labels, in the zero-shot setting. To achieve that, we propose Momentum adversarial Domain Invariant Representation learning (MoDIR), which introduces a momentum method in the DR training process to train a domain classifier distinguishing source versus target, and then adversarially updates the DR encoder to learn domain invariant representations. Our experiments show that MoDIR robustly outperforms its baselines on 10+ ranking datasets from the BEIR benchmark in the zero-shot setup, with more than 10% relative gains on datasets with enough sensitivity for DR models' evaluation. Source code of this paper will be released.