 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Active Learning via Improving Test Performance
Dec 10, 2021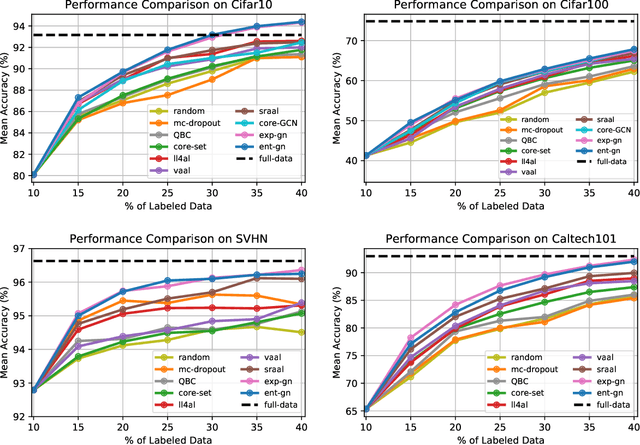

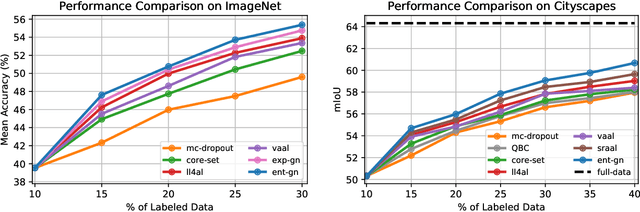
Central to active learning (AL) is what data should be selected for annotation. Existing works attempt to select highly uncertain or informative data for annotation. Nevertheless, it remains unclear how selected data impacts the test performance of the task model used in AL. In this work, we explore such an impact by theoretically proving that selecting unlabeled data of higher gradient norm leads to a lower upper bound of test loss, resulting in a better test performance. However, due to the lack of label information, directly computing gradient norm for unlabeled data is infeasible. To address this challenge, we propose two schemes, namely expected-gradnorm and entropy-gradnorm. The former computes the gradient norm by constructing an expected empirical loss while the latter constructs an unsupervised loss with entropy. Furthermore, we integrate the two schemes in a universal AL framework. We evaluate our method on classical image classification and semantic segmentation tasks. To demonstrate its competency in domain applications and its robustness to noise, we also validate our method on a cellular imaging analysis task, namely cryo-Electron Tomography subtomogram classification. Results demonstrate that our method achieves superior performance against the state-of-the-art. Our source code is available at https://github.com/xulabs/aitom
* 13 pages
SenseMag: Enabling Low-Cost Traffic Monitoring using Non-invasive Magnetic Sensing
Oct 24, 2021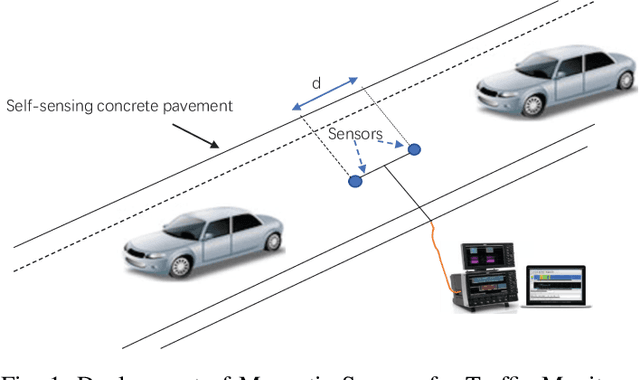

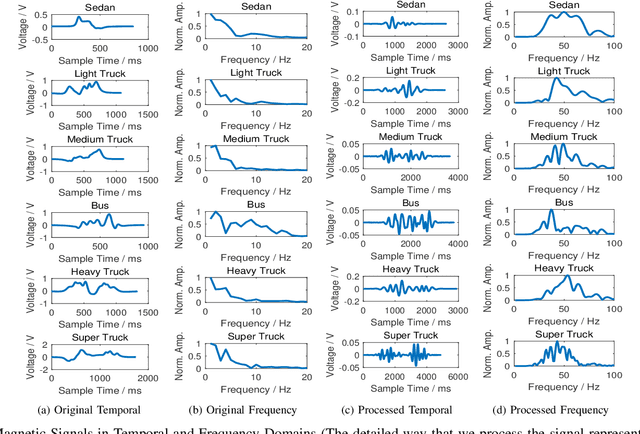
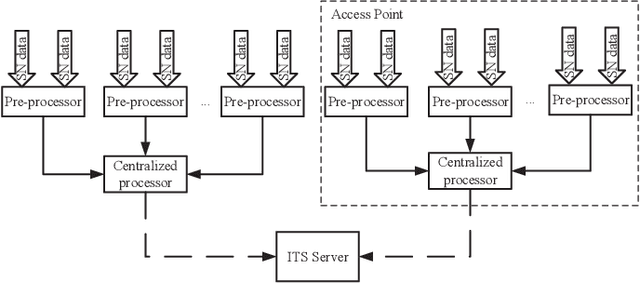
The operation and management of intelligent transportation systems (ITS), such as traffic monitoring, relies on real-time data aggregation of vehicular traffic information, including vehicular types (e.g., cars, trucks, and buses), in the critical roads and highways. While traditional approaches based on vehicular-embedded GPS sensors or camera networks would either invade drivers' privacy or require high deployment cost, this paper introduces a low-cost method, namely SenseMag, to recognize the vehicular type using a pair of non-invasive magnetic sensors deployed on the straight road section. SenseMag filters out noises and segments received magnetic signals by the exact time points that the vehicle arrives or departs from every sensor node. Further, SenseMag adopts a hierarchical recognition model to first estimate the speed/velocity, then identify the length of vehicle using the predicted speed, sampling cycles, and the distance between the sensor nodes. With the vehicle length identified and the temporal/spectral features extracted from the magnetic signals, SenseMag classify the types of vehicles accordingly. Some semi-automated learning techniques have been adopted for the design of filters, features, and the choice of hyper-parameters. Extensive experiment based on real-word field deployment (on the highways in Shenzhen, China) shows that SenseMag significantly outperforms the existing methods in both classification accuracy and the granularity of vehicle types (i.e., 7 types by SenseMag versus 4 types by the existing work in comparisons). To be specific, our field experiment results validate that SenseMag is with at least $90\%$ vehicle type classification accuracy and less than 5\% vehicle length classification error.
Noise Stability Regularization for Improving BERT Fine-tuning
Jul 10, 2021
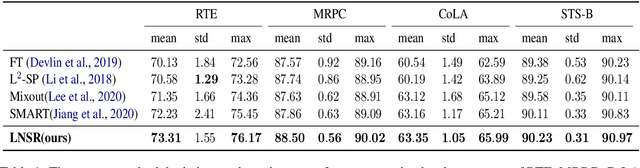

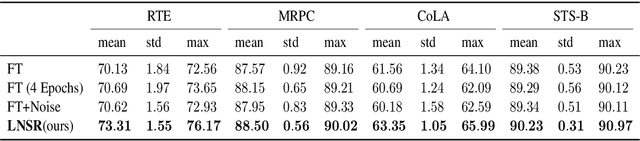
Fine-tuning pre-trained language models such as BERT has become a common practice dominating leaderboards across various NLP tasks. Despite its recent success and wide adoption, this process is unstable when there are only a small number of training samples available. The brittleness of this process is often reflected by the sensitivity to random seeds. In this paper, we propose to tackle this problem based on the noise stability property of deep nets, which is investigated in recent literature (Arora et al., 2018; Sanyal et al., 2020). Specifically, we introduce a novel and effective regularization method to improve fine-tuning on NLP tasks, referred to as Layer-wise Noise Stability Regularization (LNSR). We extend the theories about adding noise to the input and prove that our method gives a stabler regularization effect. We provide supportive evidence by experimentally confirming that well-performing models show a low sensitivity to noise and fine-tuning with LNSR exhibits clearly higher generalizability and stability. Furthermore, our method also demonstrates advantages over other state-of-the-art algorithms including L2-SP (Li et al., 2018), Mixout (Lee et al., 2020) and SMART (Jiang et al., 2020).
Federated Noisy Client Learning
Jun 24, 2021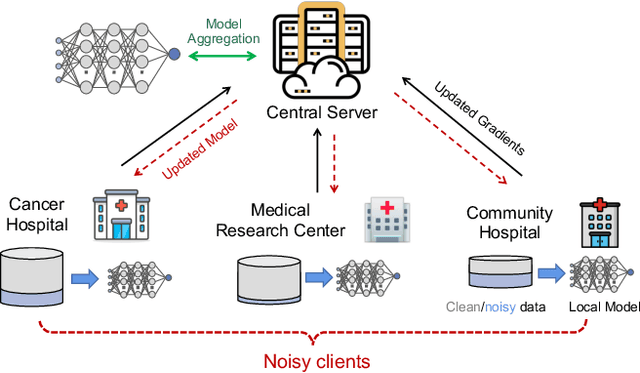
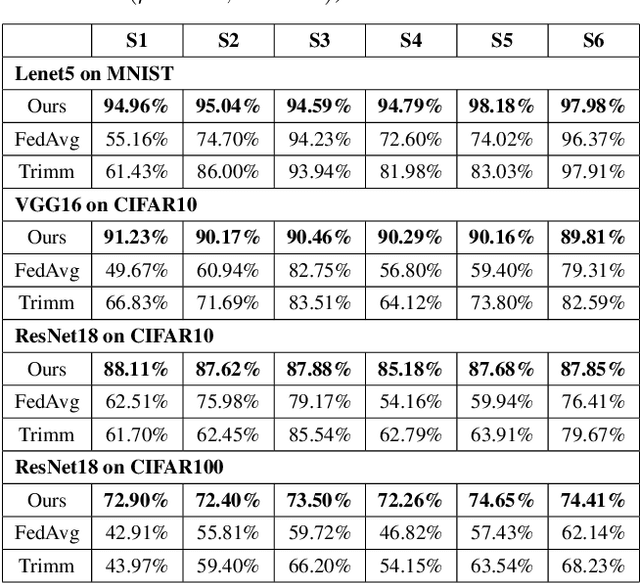
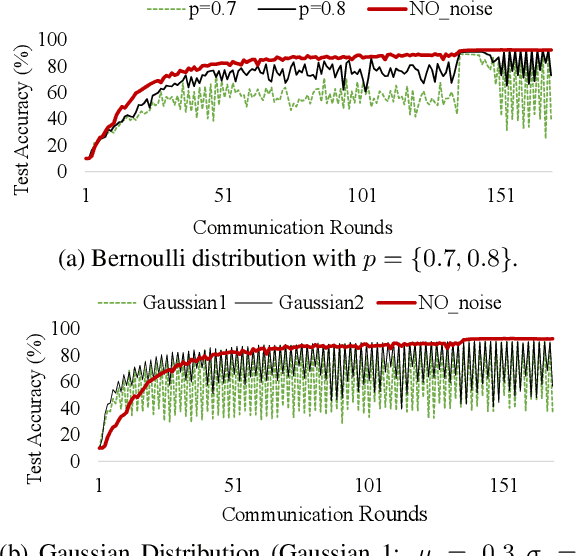
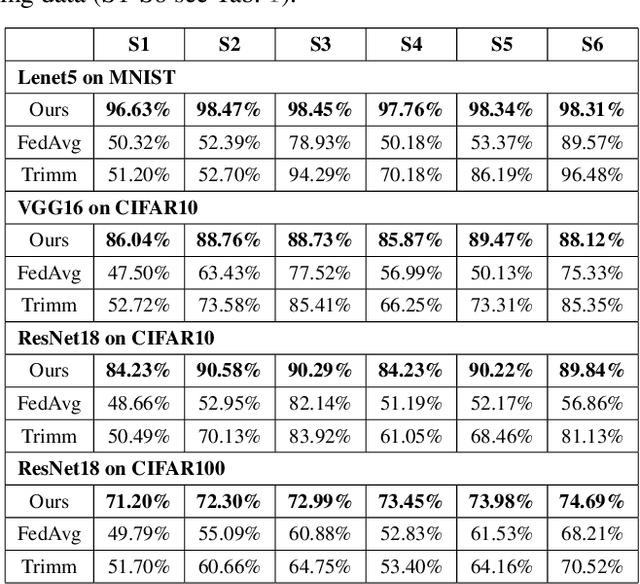
Federated learning (FL) collaboratively aggregates a shared global model depending on multiple local clients, while keeping the training data decentralized in order to preserve data privacy. However, standard FL methods ignore the noisy client issue, which may harm the overall performance of the aggregated model. In this paper, we first analyze the noisy client statement, and then model noisy clients with different noise distributions (e.g., Bernoulli and truncated Gaussian distributions). To learn with noisy clients, we propose a simple yet effective FL framework, named Federated Noisy Client Learning (Fed-NCL), which is a plug-and-play algorithm and contains two main components: a data quality measurement (DQM) to dynamically quantify the data quality of each participating client, and a noise robust aggregation (NRA) to adaptively aggregate the local models of each client by jointly considering the amount of local training data and the data quality of each client. Our Fed-NCL can be easily applied in any standard FL workflow to handle the noisy client issue. Experimental results on various datasets demonstrate that our algorithm boosts the performances of different state-of-the-art systems with noisy clients.
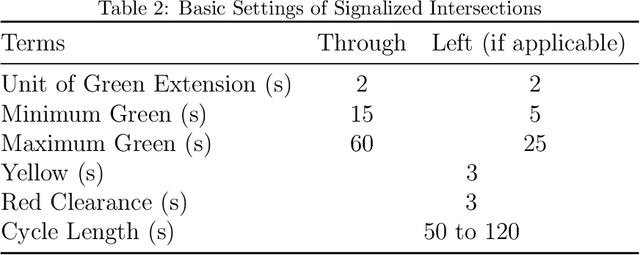
Network-wide traffic signal control optimization using a multi-agent deep reinforcement learning
Apr 20, 2021
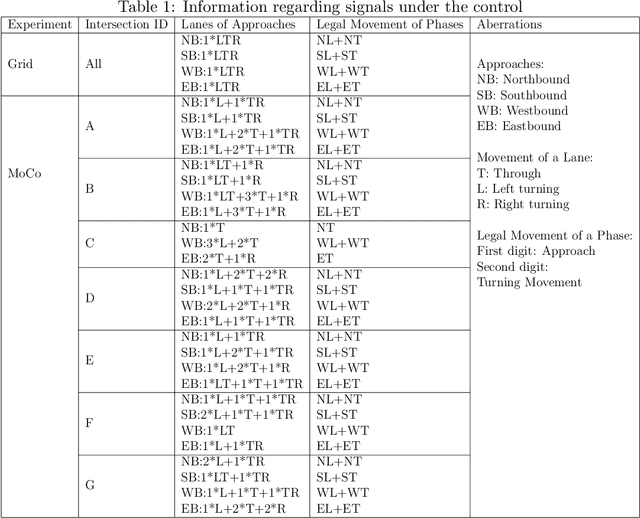
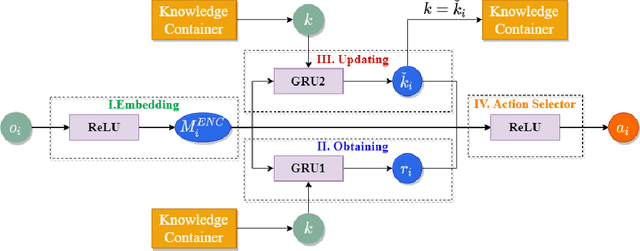
Inefficient traffic control may cause numerous problems such as traffic congestion and energy waste. This paper proposes a novel multi-agent reinforcement learning method, named KS-DDPG (Knowledge Sharing Deep Deterministic Policy Gradient) to achieve optimal control by enhancing the cooperation between traffic signals. By introducing the knowledge-sharing enabled communication protocol, each agent can access to the collective representation of the traffic environment collected by all agents. The proposed method is evaluated through two experiments respectively using synthetic and real-world datasets. The comparison with state-of-the-art reinforcement learning-based and conventional transportation methods demonstrate the proposed KS-DDPG has significant efficiency in controlling large-scale transportation networks and coping with fluctuations in traffic flow. In addition, the introduced communication mechanism has also been proven to speed up the convergence of the model without significantly increasing the computational burden.
LAFEAT: Piercing Through Adversarial Defenses with Latent Features
Apr 20, 2021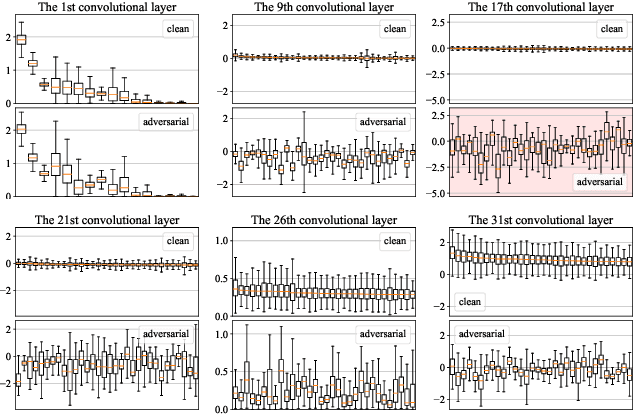
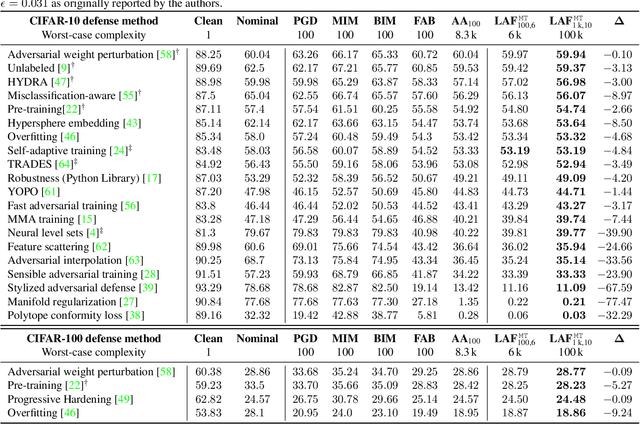
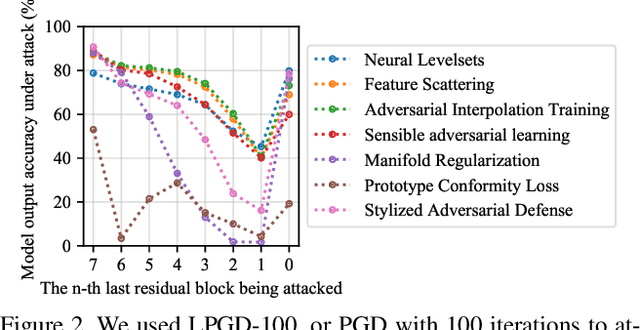

Deep convolutional neural networks are susceptible to adversarial attacks. They can be easily deceived to give an incorrect output by adding a tiny perturbation to the input. This presents a great challenge in making CNNs robust against such attacks. An influx of new defense techniques have been proposed to this end. In this paper, we show that latent features in certain "robust" models are surprisingly susceptible to adversarial attacks. On top of this, we introduce a unified $\ell_\infty$-norm white-box attack algorithm which harnesses latent features in its gradient descent steps, namely LAFEAT. We show that not only is it computationally much more efficient for successful attacks, but it is also a stronger adversary than the current state-of-the-art across a wide range of defense mechanisms. This suggests that model robustness could be contingent on the effective use of the defender's hidden components, and it should no longer be viewed from a holistic perspective.
Adaptive Consistency Regularization for Semi-Supervised Transfer Learning
Mar 03, 2021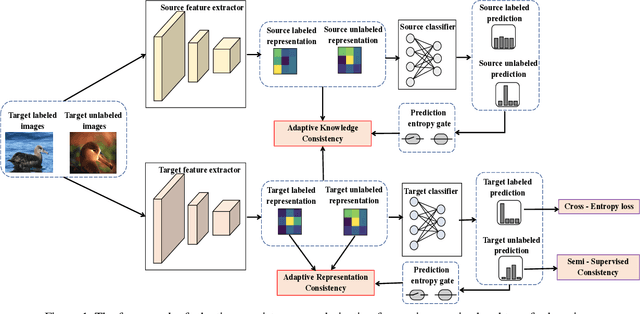
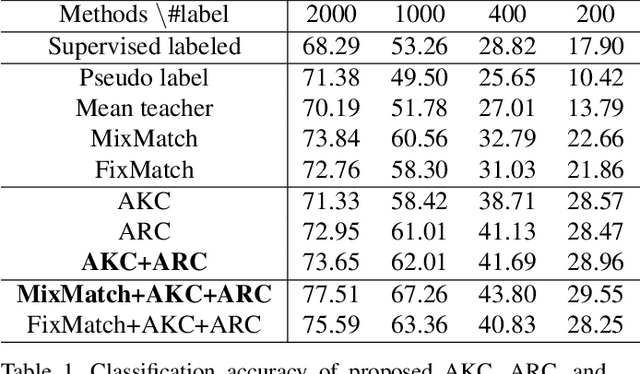
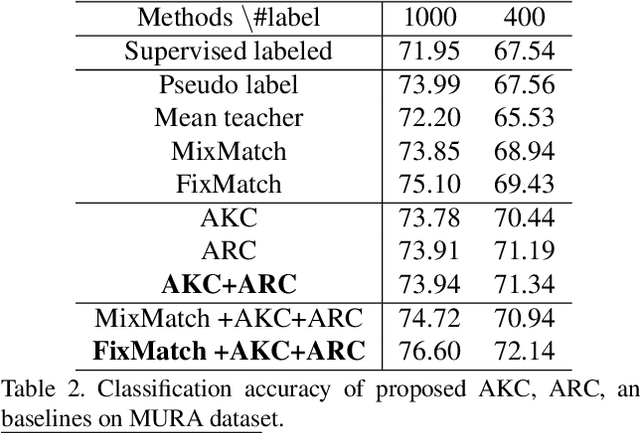
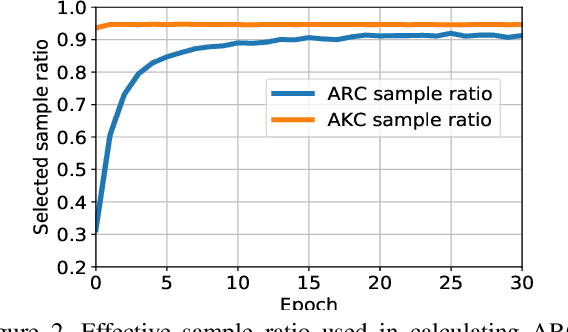
While recent studies on semi-supervised learning have shown remarkable progress in leveraging both labeled and unlabeled data, most of them presume a basic setting of the model is randomly initialized. In this work, we consider semi-supervised learning and transfer learning jointly, leading to a more practical and competitive paradigm that can utilize both powerful pre-trained models from source domain as well as labeled/unlabeled data in the target domain. To better exploit the value of both pre-trained weights and unlabeled target examples, we introduce adaptive consistency regularization that consists of two complementary components: Adaptive Knowledge Consistency (AKC) on the examples between the source and target model, and Adaptive Representation Consistency (ARC) on the target model between labeled and unlabeled examples. Examples involved in the consistency regularization are adaptively selected according to their potential contributions to the target task. We conduct extensive experiments on several popular benchmarks including CUB-200-2011, MIT Indoor-67, MURA, by fine-tuning the ImageNet pre-trained ResNet-50 model. Results show that our proposed adaptive consistency regularization outperforms state-of-the-art semi-supervised learning techniques such as Pseudo Label, Mean Teacher, and MixMatch. Moreover, our algorithm is orthogonal to existing methods and thus able to gain additional improvements on top of MixMatch and FixMatch. Our code is available at https://github.com/SHI-Labs/Semi-Supervised-Transfer-Learning.
Peer-Assisted Robotic Learning: A Data-Driven Collaborative Learning Approach for Cloud Robotic Systems
Oct 16, 2020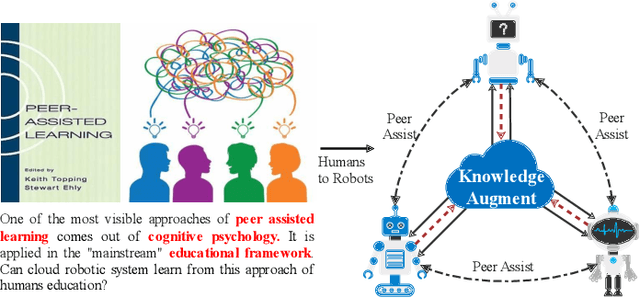
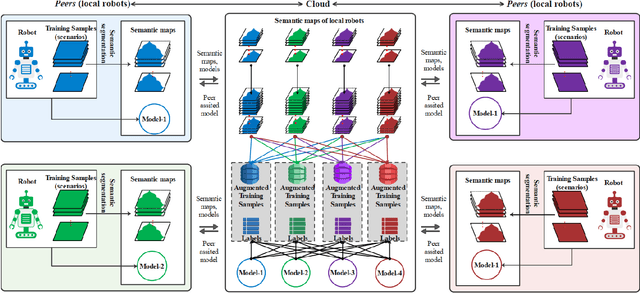
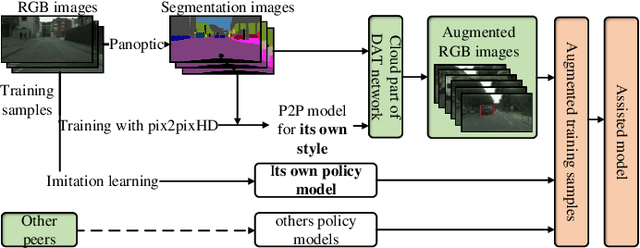
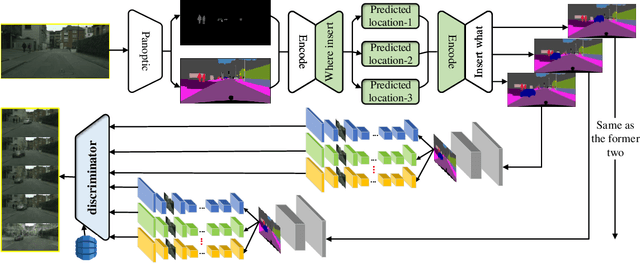
A technological revolution is occurring in the field of robotics with the data-driven deep learning technology. However, building datasets for each local robot is laborious. Meanwhile, data islands between local robots make data unable to be utilized collaboratively. To address this issue, the work presents Peer-Assisted Robotic Learning (PARL) in robotics, which is inspired by the peer-assisted learning in cognitive psychology and pedagogy. PARL implements data collaboration with the framework of cloud robotic systems. Both data and models are shared by robots to the cloud after semantic computing and training locally. The cloud converges the data and performs augmentation, integration, and transferring. Finally, fine tune this larger shared dataset in the cloud to local robots. Furthermore, we propose the DAT Network (Data Augmentation and Transferring Network) to implement the data processing in PARL. DAT Network can realize the augmentation of data from multi-local robots. We conduct experiments on a simplified self-driving task for robots (cars). DAT Network has a significant improvement in the augmentation in self-driving scenarios. Along with this, the self-driving experimental results also demonstrate that PARL is capable of improving learning effects with data collaboration of local robots.
Frontier Detection and Reachability Analysis for Efficient 2D Graph-SLAM Based Active Exploration
Sep 07, 2020
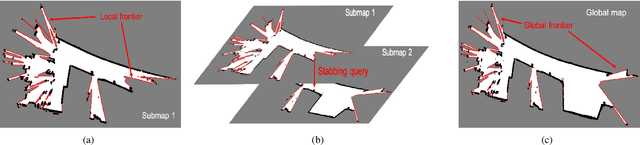
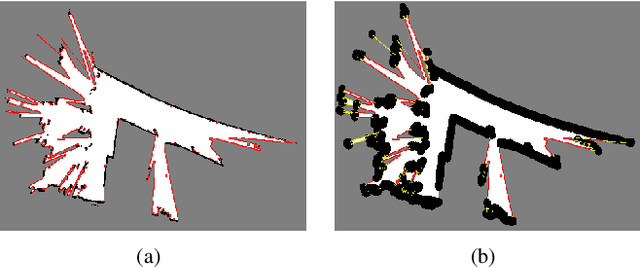
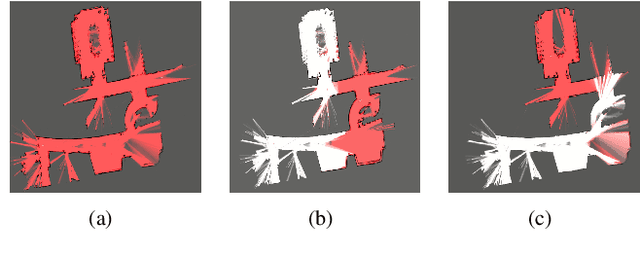
We propose an integrated approach to active exploration by exploiting the Cartographer method as the base SLAM module for submap creation and performing efficient frontier detection in the geometrically co-aligned submaps induced by graph optimization. We also carry out analysis on the reachability of frontiers and their clusters to ensure that the detected frontier can be reached by robot. Our method is tested on a mobile robot in real indoor scene to demonstrate the effectiveness and efficiency of our approach.
Federated Imitation Learning: A Novel Framework for Cloud Robotic Systems with Heterogeneous Sensor Data
Dec 24, 2019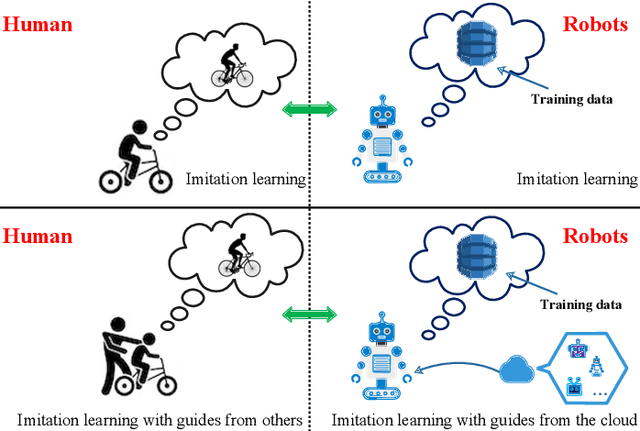
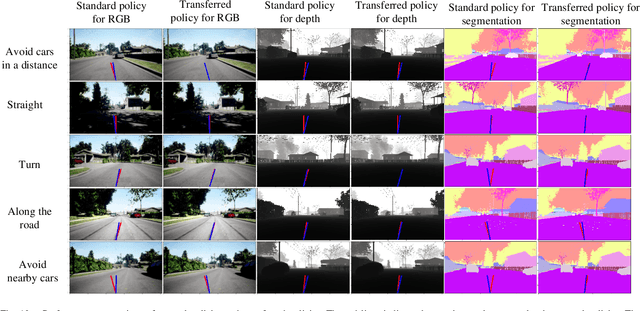
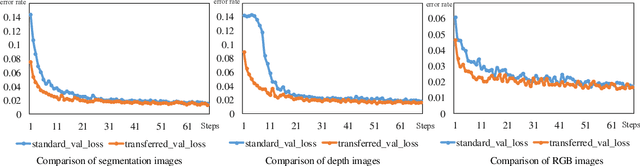

Humans are capable of learning a new behavior by observing others to perform the skill. Similarly, robots can also implement this by imitation learning. Furthermore, if with external guidance, humans can master the new behavior more efficiently. So, how can robots achieve this? To address the issue, we present a novel framework named FIL. It provides a heterogeneous knowledge fusion mechanism for cloud robotic systems. Then, a knowledge fusion algorithm in FIL is proposed. It enables the cloud to fuse heterogeneous knowledge from local robots and generate guide models for robots with service requests. After that, we introduce a knowledge transfer scheme to facilitate local robots acquiring knowledge from the cloud. With FIL, a robot is capable of utilizing knowledge from other robots to increase its imitation learning in accuracy and efficiency. Compared with transfer learning and meta-learning, FIL is more suitable to be deployed in cloud robotic systems. Finally, we conduct experiments of a self-driving task for robots (cars). The experimental results demonstrate that the shared model generated by FIL increases imitation learning efficiency of local robots in cloud robotic systems.