 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLEAN: Generative Latent Bank for Image Super-Resolution and Beyond
Jul 29, 2022
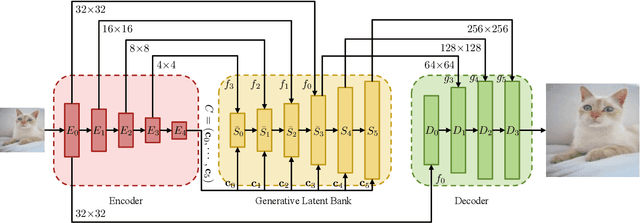
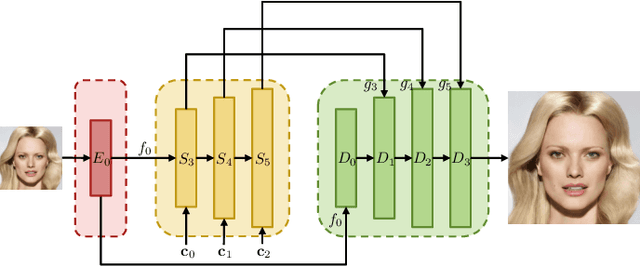
We show that pre-trained Generative Adversarial Networks (GANs) such as StyleGAN and BigGAN can be used as a latent bank to improve the performance of image super-resolution. While most existing perceptual-oriented approaches attempt to generate realistic outputs through learning with adversarial loss, our method, Generative LatEnt bANk (GLEAN), goes beyond existing practices by directly leveraging rich and diverse priors encapsulated in a pre-trained GAN. But unlike prevalent GAN inversion methods that require expensive image-specific optimization at runtime, our approach only needs a single forward pass for restoration. GLEAN can be easily incorporated in a simple encoder-bank-decoder architecture with multi-resolution skip connections. Employing priors from different generative models allows GLEAN to be applied to diverse categories (\eg~human faces, cats, buildings, and cars). We further present a lightweight version of GLEAN, named LightGLEAN, which retains only the critical components in GLEAN. Notably, LightGLEAN consists of only 21% of parameters and 35% of FLOPs while achieving comparable image quality. We extend our method to different tasks including image colorization and blind image restoration, and extensive experiments show that our proposed models perform favorably in comparison to existing methods. Codes and models are available at https://github.com/open-mmlab/mmediting.
StyleLight: HDR Panorama Generation for Lighting Estimation and Editing
Jul 29, 2022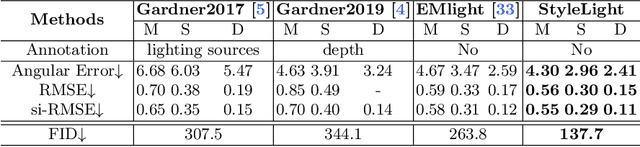
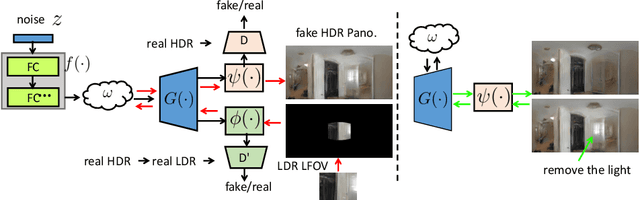


We present a new lighting estimation and editing framework to generate high-dynamic-range (HDR) indoor panorama lighting from a single limited field-of-view (LFOV) image captured by low-dynamic-range (LDR) cameras. Existing lighting estimation methods either directly regress lighting representation parameters or decompose this problem into LFOV-to-panorama and LDR-to-HDR lighting generation sub-tasks. However, due to the partial observation, the high-dynamic-range lighting, and the intrinsic ambiguity of a scene, lighting estimation remains a challenging task. To tackle this problem, we propose a coupled dual-StyleGAN panorama synthesis network (StyleLight) that integrates LDR and HDR panorama synthesis into a unified framework. The LDR and HDR panorama synthesis share a similar generator but have separate discriminators. During inference, given an LDR LFOV image, we propose a focal-masked GAN inversion method to find its latent code by the LDR panorama synthesis branch and then synthesize the HDR panorama by the HDR panorama synthesis branch. StyleLight takes LFOV-to-panorama and LDR-to-HDR lighting generation into a unified framework and thus greatly improves lighting estimation. Extensive experiments demonstrate that our framework achieves superior performance over state-of-the-art methods on indoor lighting estimation. Notably, StyleLight also enables intuitive lighting editing on indoor HDR panoramas, which is suitable for real-world applications. Code is available at https://style-light.github.io.
CuDi: Curve Distillation for Efficient and Controllable Exposure Adjustment
Jul 28, 2022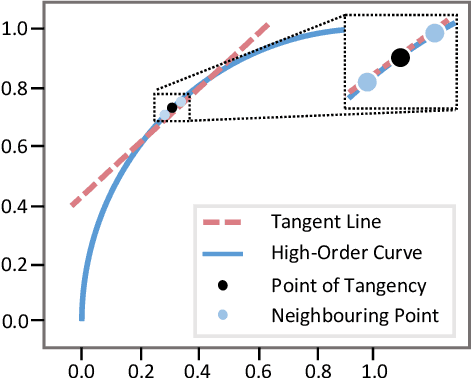


We present Curve Distillation, CuDi, for efficient and controllable exposure adjustment without the requirement of paired or unpaired data during training. Our method inherits the zero-reference learning and curve-based framework from an effective low-light image enhancement method, Zero-DCE, with further speed up in its inference speed, reduction in its model size, and extension to controllable exposure adjustment. The improved inference speed and lightweight model are achieved through novel curve distillation that approximates the time-consuming iterative operation in the conventional curve-based framework by high-order curve's tangent line. The controllable exposure adjustment is made possible with a new self-supervised spatial exposure control loss that constrains the exposure levels of different spatial regions of the output to be close to the brightness distribution of an exposure map serving as an input condition. Different from most existing methods that can only correct either underexposed or overexposed photos, our approach corrects both underexposed and overexposed photos with a single model. Notably, our approach can additionally adjust the exposure levels of a photo globally or locally with the guidance of an input condition exposure map, which can be pre-defined or manually set in the inference stage. Through extensive experiments, we show that our method is appealing for its fast, robust, and flexible performance, outperforming state-of-the-art methods in real scenes. Project page: https://li-chongyi.github.io/CuDi_files/.
Exploring CLIP for Assessing the Look and Feel of Images
Jul 25, 2022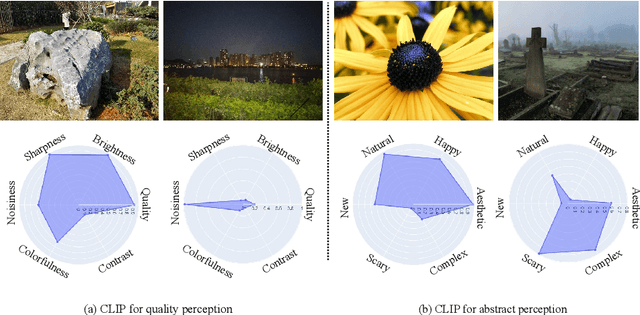
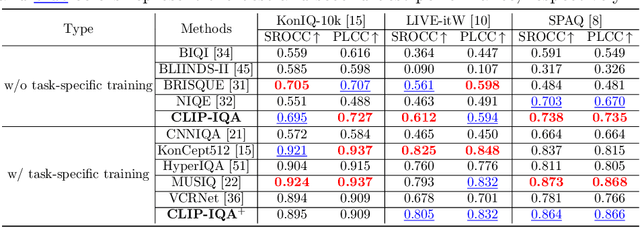
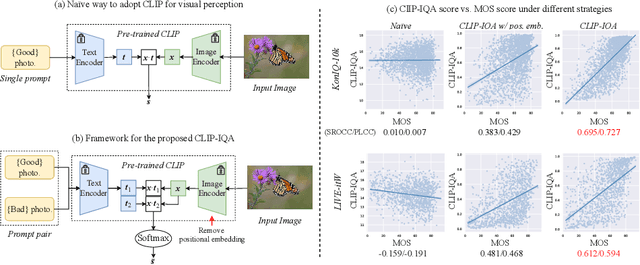
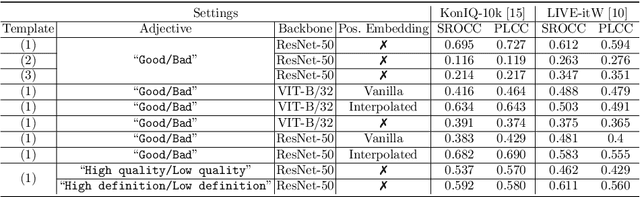
Measuring the perception of visual content is a long-standing problem in computer vision. Many mathematical models have been developed to evaluate the look or quality of an image. Despite the effectiveness of such tools in quantifying degradations such as noise and blurriness levels, such quantification is loosely coupled with human language. When it comes to more abstract perception about the feel of visual content, existing methods can only rely on supervised models that are explicitly trained with labeled data collected via laborious user study. In this paper, we go beyond the conventional paradigms by exploring the rich visual language prior encapsulated in Contrastive Language-Image Pre-training (CLIP) models for assessing both the quality perception (look) and abstract perception (feel) of images in a zero-shot manner. In particular, we discuss effective prompt designs and show an effective prompt pairing strategy to harness the prior. We also provide extensive experiments on controlled datasets and Image Quality Assessment (IQA) benchmarks. Our results show that CLIP captures meaningful priors that generalize well to different perceptual assessments. Code will be avaliable at https://github.com/IceClear/CLIP-IQA.
CelebV-HQ: A Large-Scale Video Facial Attributes Dataset
Jul 25, 2022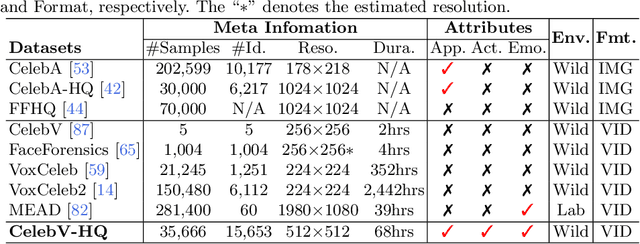

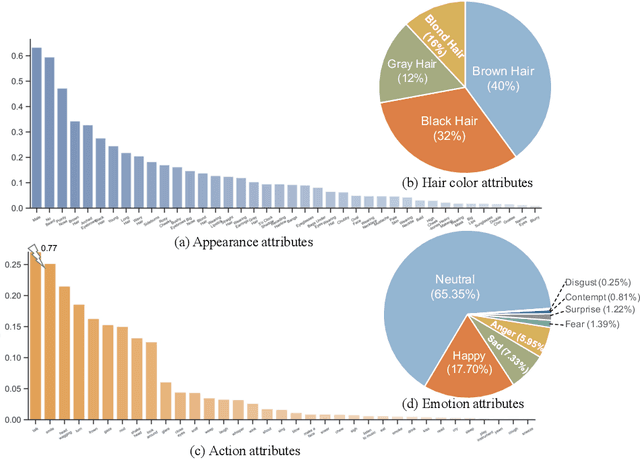
Large-scale datasets have played indispensable roles in the recent success of face generation/editing and significantly facilitated the advances of emerging research fields. However, the academic community still lacks a video dataset with diverse facial attribute annotations, which is crucial for the research on face-related videos. In this work, we propose a large-scale, high-quality, and diverse video dataset with rich facial attribute annotations, named the High-Quality Celebrity Video Dataset (CelebV-HQ). CelebV-HQ contains 35,666 video clips with the resolution of 512x512 at least, involving 15,653 identities. All clips are labeled manually with 83 facial attributes, covering appearance, action, and emotion. We conduct a comprehensive analysis in terms of age, ethnicity, brightness stability, motion smoothness, head pose diversity, and data quality to demonstrate the diversity and temporal coherence of CelebV-HQ. Besides, its versatility and potential are validated on two representative tasks, i.e., unconditional video generation and video facial attribute editing. Furthermore, we envision the future potential of CelebV-HQ, as well as the new opportunities and challenges it would bring to related research directions. Data, code, and models are publicly available. Project page: https://celebv-hq.github.io.
BRACE: The Breakdancing Competition Dataset for Dance Motion Synthesis
Jul 22, 2022
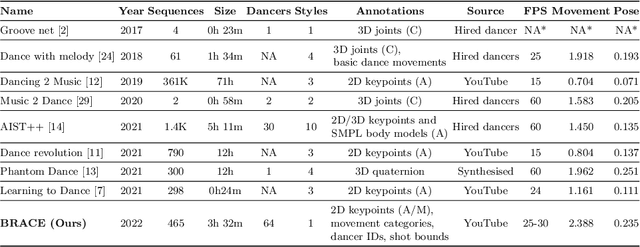


Generative models for audio-conditioned dance motion synthesis map music features to dance movements. Models are trained to associate motion patterns to audio patterns, usually without an explicit knowledge of the human body. This approach relies on a few assumptions: strong music-dance correlation, controlled motion data and relatively simple poses and movements. These characteristics are found in all existing datasets for dance motion synthesis, and indeed recent methods can achieve good results.We introduce a new dataset aiming to challenge these common assumptions, compiling a set of dynamic dance sequences displaying complex human poses. We focus on breakdancing which features acrobatic moves and tangled postures. We source our data from the Red Bull BC One competition videos. Estimating human keypoints from these videos is difficult due to the complexity of the dance, as well as the multiple moving cameras recording setup. We adopt a hybrid labelling pipeline leveraging deep estimation models as well as manual annotations to obtain good quality keypoint sequences at a reduced cost. Our efforts produced the BRACE dataset, which contains over 3 hours and 30 minutes of densely annotated poses. We test state-of-the-art methods on BRACE, showing their limitations when evaluated on complex sequences. Our dataset can readily foster advance in dance motion synthesis. With intricate poses and swift movements, models are forced to go beyond learning a mapping between modalities and reason more effectively about body structure and movements.
Transformer with Implicit Edges for Particle-based Physics Simulation
Jul 22, 2022
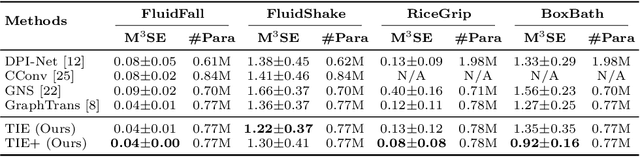
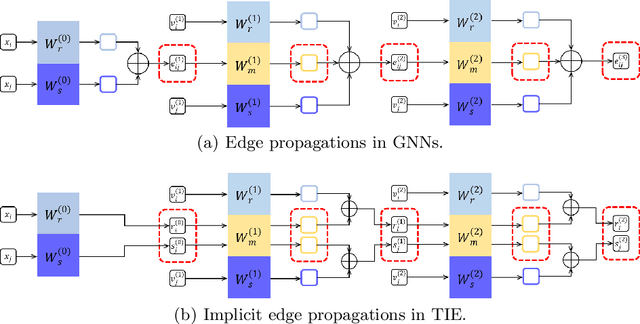
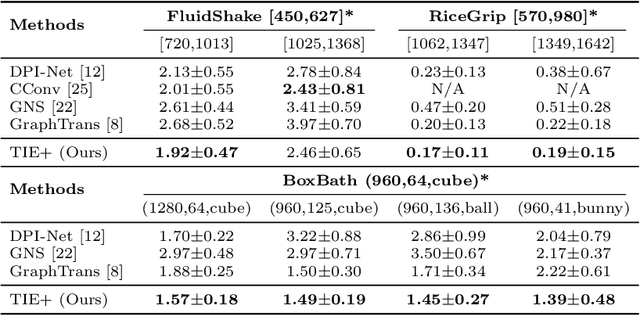
Particle-based systems provide a flexible and unified way to simulate physics systems with complex dynamics. Most existing data-driven simulators for particle-based systems adopt graph neural networks (GNNs) as their network backbones, as particles and their interactions can be naturally represented by graph nodes and graph edges. However, while particle-based systems usually contain hundreds even thousands of particles, the explicit modeling of particle interactions as graph edges inevitably leads to a significant computational overhead, due to the increased number of particle interactions. Consequently, in this paper we propose a novel Transformer-based method, dubbed as Transformer with Implicit Edges (TIE), to capture the rich semantics of particle interactions in an edge-free manner. The core idea of TIE is to decentralize the computation involving pair-wise particle interactions into per-particle updates. This is achieved by adjusting the self-attention module to resemble the update formula of graph edges in GNN. To improve the generalization ability of TIE, we further amend TIE with learnable material-specific abstract particles to disentangle global material-wise semantics from local particle-wise semantics. We evaluate our model on diverse domains of varying complexity and materials. Compared with existing GNN-based methods, without bells and whistles, TIE achieves superior performance and generalization across all these domains. Codes and models are available at https://github.com/ftbabi/TIE_ECCV2022.git.
Monocular 3D Object Reconstruction with GAN Inversion
Jul 20, 2022
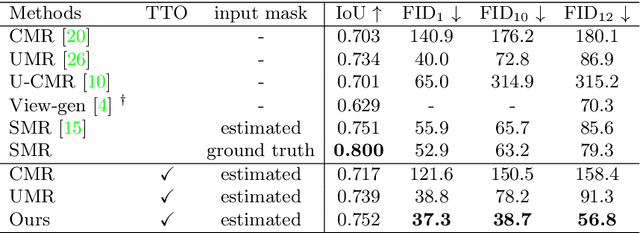
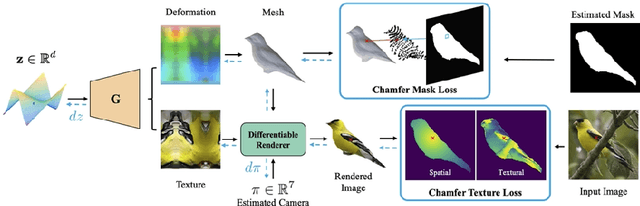

Recovering a textured 3D mesh from a monocular image is highly challenging, particularly for in-the-wild objects that lack 3D ground truths. In this work, we present MeshInversion, a novel framework to improve the reconstruction by exploiting the generative prior of a 3D GAN pre-trained for 3D textured mesh synthesis. Reconstruction is achieved by searching for a latent space in the 3D GAN that best resembles the target mesh in accordance with the single view observation. Since the pre-trained GAN encapsulates rich 3D semantics in terms of mesh geometry and texture, searching within the GAN manifold thus naturally regularizes the realness and fidelity of the reconstruction. Importantly, such regularization is directly applied in the 3D space, providing crucial guidance of mesh parts that are unobserved in the 2D space. Experiments on standard benchmarks show that our framework obtains faithful 3D reconstructions with consistent geometry and texture across both observed and unobserved parts. Moreover, it generalizes well to meshes that are less commonly seen, such as the extended articulation of deformable objects. Code is released at https://github.com/junzhezhang/mesh-inversion
Towards Robust Blind Face Restoration with Codebook Lookup Transformer
Jun 22, 2022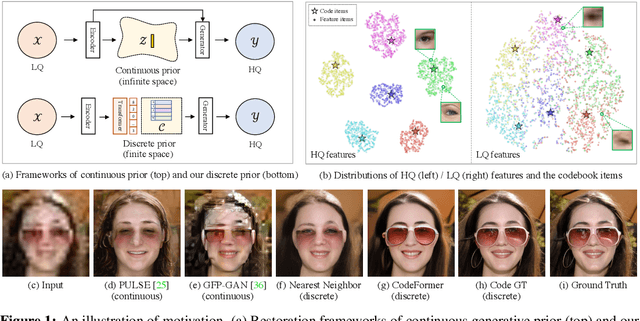
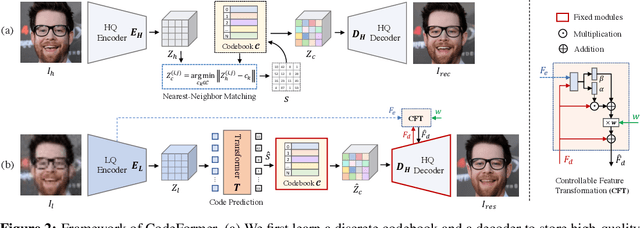
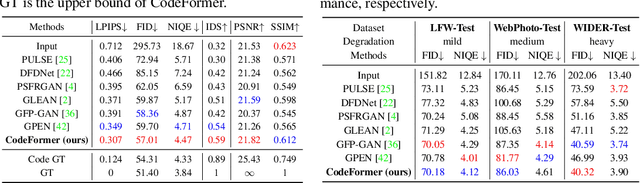

Blind face restoration is a highly ill-posed problem that often requires auxiliary guidance to 1) improve the mapping from degraded inputs to desired outputs, or 2) complement high-quality details lost in the inputs. In this paper, we demonstrate that a learned discrete codebook prior in a small proxy space largely reduces the uncertainty and ambiguity of restoration mapping by casting blind face restoration as a code prediction task, while providing rich visual atoms for generating high-quality faces. Under this paradigm, we propose a Transformer-based prediction network, named CodeFormer, to model global composition and context of the low-quality faces for code prediction, enabling the discovery of natural faces that closely approximate the target faces even when the inputs are severely degraded. To enhance the adaptiveness for different degradation, we also propose a controllable feature transformation module that allows a flexible trade-off between fidelity and quality. Thanks to the expressive codebook prior and global modeling, CodeFormer outperforms state of the arts in both quality and fidelity, showing superior robustness to degradation. Extensive experimental results on synthetic and real-world datasets verify the effectiveness of our method.
Masked Frequency Modeling for Self-Supervised Visual Pre-Training
Jun 15, 2022



We present Masked Frequency Modeling (MFM), a unified frequency-domain-based approach for self-supervised pre-training of visual models. Instead of randomly inserting mask tokens to the input embeddings in the spatial domain, in this paper, we shift the perspective to the frequency domain. Specifically, MFM first masks out a portion of frequency components of the input image and then predicts the missing frequencies on the frequency spectrum. Our key insight is that predicting masked components in the frequency domain is more ideal to reveal underlying image patterns rather than predicting masked patches in the spatial domain, due to the heavy spatial redundancy. Our findings suggest that with the right configuration of mask-and-predict strategy, both the structural information within high-frequency components and the low-level statistics among low-frequency counterparts are useful in learning good representations. For the first time, MFM demonstrates that, for both ViT and CNN, a simple non-Siamese framework can learn meaningful representations even using none of the following: (i) extra data, (ii) extra model, (iii) mask token. Experimental results on ImageNet and several robustness benchmarks show the competitive performance and advanced robustness of MFM compared with recent masked image modeling approaches. Furthermore, we also comprehensively investigate the effectiveness of classical image restoration tasks for representation learning from a unified frequency perspective and reveal their intriguing relations with our MFM approach. Project page: https://www.mmlab-ntu.com/project/mfm/index.html.