 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
You Only Judge Once: Multi-response Reward Modeling in a Single Forward Pass
Apr 13, 2026We present a discriminative multimodal reward model that scores all candidate responses in a single forward pass. Conventional discriminative reward models evaluate each response independently, requiring multiple forward passes, one for each potential response. Our approach concatenates multiple responses with separator tokens and applies cross-entropy over their scalar scores, enabling direct comparative reasoning and efficient $N$-way preference learning. The multi-response design also yields up to $N\times$ wall-clock speedup and FLOPs reduction over conventional single-response scoring. To enable $N$-way reward evaluation beyond existing pairwise benchmarks, we construct two new benchmarks: (1) MR$^2$Bench-Image contains human-annotated rankings over responses from 8 diverse models; (2) MR$^2$Bench-Video is a large-scale video-based reward benchmark derived from 94K crowdsourced pairwise human judgments over video question-answering spanning 19 models, denoised via preference graph ensemble. Both benchmarks provide 4-response evaluation variants sampled from the full rankings. Built on a 4B vision-language backbone with LoRA fine-tuning and a lightweight MLP value head, our model achieves state-of-the-art results on six multimodal reward benchmarks, including MR$^2$Bench-Image, MR$^2$Bench-Video, and four other existing benchmarks. Our model outperforms existing larger generative and discriminative reward models. We further demonstrate that our reward model, when used in reinforcement learning with GRPO, produces improved policy models that maintain performance across standard multimodal benchmarks while substantially improving open-ended generation quality, outperforming a single-response discriminative reward model (RM) baseline by a large margin in both training stability and open-ended generation quality.
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Jan 15, 2026Today's strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding -- either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for fine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
RLHF Fine-Tuning of LLMs for Alignment with Implicit User Feedback in Conversational Recommenders
Aug 07, 2025Conversational recommender systems (CRS) based on Large Language Models (LLMs) need to constantly be aligned to the user preferences to provide satisfying and context-relevant item recommendations. The traditional supervised fine-tuning cannot capture the implicit feedback signal, e.g., dwell time, sentiment polarity, or engagement patterns. In this paper, we share a fine-tuning solution using human feedback reinforcement learning (RLHF) to maximize implied user feedback (IUF) in a multi-turn recommendation context. We specify a reward model $R_{\phi}$ learnt on weakly-labelled engagement information and maximize user-centric utility by optimizing the foundational LLM M_{\theta} through a proximal policy optimization (PPO) approach. The architecture models conversational state transitions $s_t \to a_t \to s_{t +1}$, where the action $a_t$ is associated with LLM-generated item suggestions only on condition of conversation history in the past. The evaluation across synthetic and real-world datasets (e.g.REDIAL, OpenDialKG) demonstrates that our RLHF-fine-tuned models can perform better in terms of top-$k$ recommendation accuracy, coherence, and user satisfaction compared to (arrow-zero-cmwrquca-teja-falset ensuite 2Round group-deca States penalty give up This paper shows that implicit signal alignment can be efficient in achieving scalable and user-adaptive design of CRS.
Meta-Learning for Cold-Start Personalization in Prompt-Tuned LLMs
Jul 22, 2025Generative, explainable, and flexible recommender systems, derived using Large Language Models (LLM) are promising and poorly adapted to the cold-start user situation, where there is little to no history of interaction. The current solutions i.e. supervised fine-tuning and collaborative filtering are dense-user-item focused and would be expensive to maintain and update. This paper introduces a meta-learning framework, that can be used to perform parameter-efficient prompt-tuning, to effectively personalize LLM-based recommender systems quickly at cold-start. The model learns soft prompt embeddings with first-order (Reptile) and second-order (MAML) optimization by treating each of the users as the tasks. As augmentations to the input tokens, these learnable vectors are the differentiable control variables that represent user behavioral priors. The prompts are meta-optimized through episodic sampling, inner-loop adaptation, and outer-loop generalization. On MovieLens-1M, Amazon Reviews, and Recbole, we can see that our adaptive model outperforms strong baselines in NDCG@10, HR@10, and MRR, and it runs in real-time (i.e., below 300 ms) on consumer GPUs. Zero-history personalization is also supported by this scalable solution, and its 275 ms rate of adaptation allows successful real-time risk profiling of financial systems by shortening detection latency and improving payment network stability. Crucially, the 275 ms adaptation capability can enable real-time risk profiling for financial institutions, reducing systemic vulnerability detection latency significantly versus traditional compliance checks. By preventing contagion in payment networks (e.g., Fedwire), the framework strengthens national financial infrastructure resilience.
Unfolding Spatial Cognition: Evaluating Multimodal Models on Visual Simulations
Jun 05, 2025Spatial cognition is essential for human intelligence, enabling problem-solving through visual simulations rather than solely relying on verbal reasoning. However, existing AI benchmarks primarily assess verbal reasoning, neglecting the complexities of non-verbal, multi-step visual simulation. We introduce STARE(Spatial Transformations and Reasoning Evaluation), a benchmark designed to rigorously evaluate multimodal large language models on tasks better solved through multi-step visual simulation. STARE features 4K tasks spanning foundational geometric transformations (2D and 3D), integrated spatial reasoning (cube net folding and tangram puzzles), and real-world spatial reasoning (perspective and temporal reasoning), reflecting practical cognitive challenges like object assembly, mechanical diagram interpretation, and everyday spatial navigation. Our evaluations show that models excel at reasoning over simpler 2D transformations, but perform close to random chance on more complex tasks like 3D cube net folding and tangram puzzles that require multi-step visual simulations. Humans achieve near-perfect accuracy but take considerable time (up to 28.9s) on complex tasks, significantly speeding up (down by 7.5 seconds on average) with intermediate visual simulations. In contrast, models exhibit inconsistent performance gains from visual simulations, improving on most tasks but declining in specific cases like tangram puzzles (GPT-4o, o1) and cube net folding (Claude-3.5, Gemini-2.0 Flash), indicating that models may not know how to effectively leverage intermediate visual information.
StyleLight: HDR Panorama Generation for Lighting Estimation and Editing
Jul 29, 2022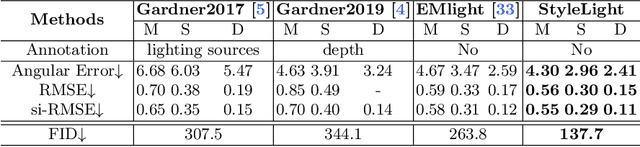
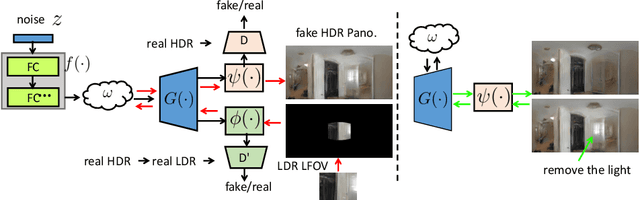


We present a new lighting estimation and editing framework to generate high-dynamic-range (HDR) indoor panorama lighting from a single limited field-of-view (LFOV) image captured by low-dynamic-range (LDR) cameras. Existing lighting estimation methods either directly regress lighting representation parameters or decompose this problem into LFOV-to-panorama and LDR-to-HDR lighting generation sub-tasks. However, due to the partial observation, the high-dynamic-range lighting, and the intrinsic ambiguity of a scene, lighting estimation remains a challenging task. To tackle this problem, we propose a coupled dual-StyleGAN panorama synthesis network (StyleLight) that integrates LDR and HDR panorama synthesis into a unified framework. The LDR and HDR panorama synthesis share a similar generator but have separate discriminators. During inference, given an LDR LFOV image, we propose a focal-masked GAN inversion method to find its latent code by the LDR panorama synthesis branch and then synthesize the HDR panorama by the HDR panorama synthesis branch. StyleLight takes LFOV-to-panorama and LDR-to-HDR lighting generation into a unified framework and thus greatly improves lighting estimation. Extensive experiments demonstrate that our framework achieves superior performance over state-of-the-art methods on indoor lighting estimation. Notably, StyleLight also enables intuitive lighting editing on indoor HDR panoramas, which is suitable for real-world applications. Code is available at https://style-light.github.io.