 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Convolutional Networks against Degree-Related Biases
Jun 28, 2020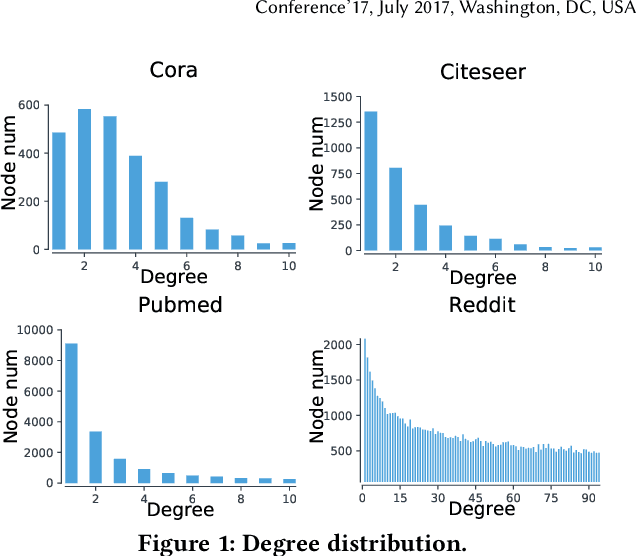
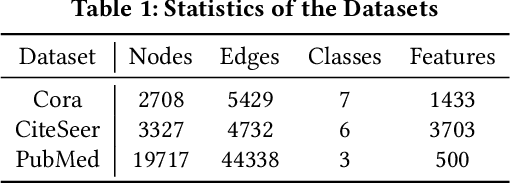
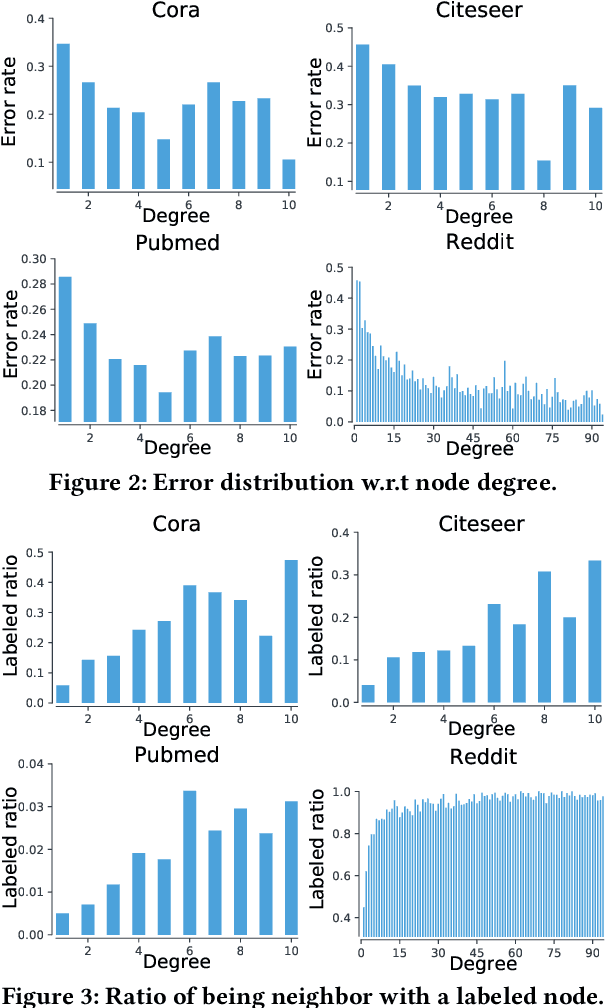
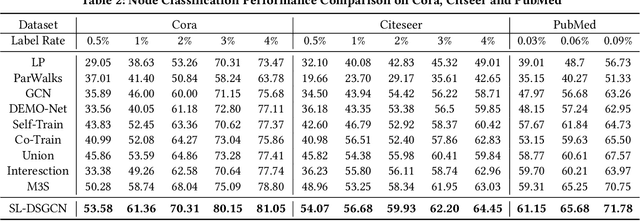
In recent years, Graph Convolutional Networks (GCNs) show competitive performance in different domains, such as social network analysis, recommendation, and smart city. However, training GCNs with insufficient supervision is very difficult. The performance of GCNs becomes unsatisfying with few labeled data. Although some pioneering work try to understand why GCNs work or fail, their analysis focus more on the entire model level. Profiling GCNs on different nodes is still underexplored. To address the limitations, we study GCNs with respect to the node degree distribution. We show that GCNs have a higher accuracy on nodes with larger degrees even if they are underrepresented in most graphs, with both empirical observation and theoretical proof. We then propose Self-Supervised-Learning Degree-Specific GCN (SL-DSGCN) which handles the degree-related biases of GCNs from model and data aspects. Firstly, we design a degree-specific GCN layer that models both discrepancies and similarities of nodes with different degrees, and reduces the inner model-aspect biases of GCNs caused by sharing the same parameters with all nodes. Secondly, we develop a self-supervised-learning algorithm that assigns pseudo labels with uncertainty scores on unlabeled nodes using a Bayesian neural network. Pseudo labels increase the chance of connecting to labeled neighbors for low-degree nodes, thus reducing the biases of GCNs from the data perspective. We further exploit uncertainty scores as dynamic weights on pseudo labels in the stochastic gradient descent for SL-DSGCN. We validate \ours on three benchmark datasets, and confirm SL-DSGCN not only outperforms state-of-the-art self-training/self-supervised-learning GCN methods, but also improves GCN accuracy dramatically for low-degree nodes.
MALOnt: An Ontology for Malware Threat Intelligence
Jun 20, 2020
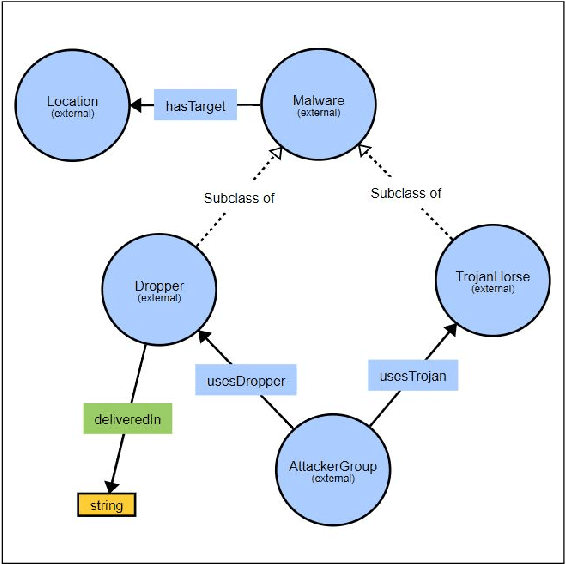
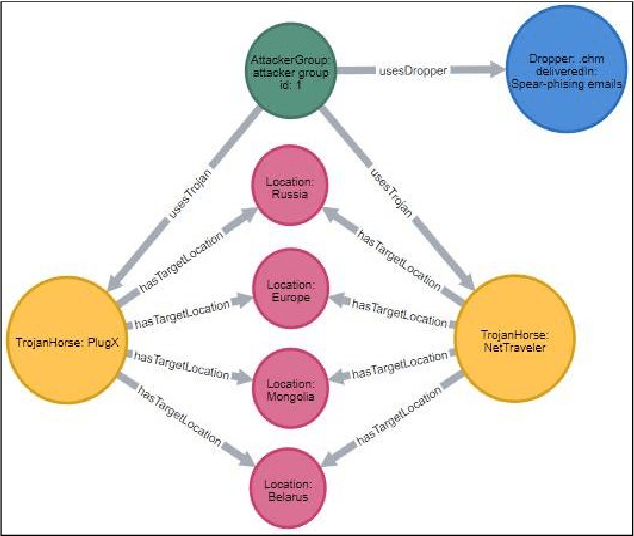
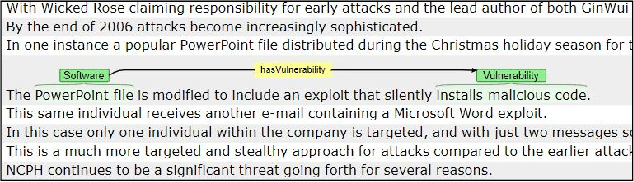
Malware threat intelligence uncovers deep information about malware, threat actors, and their tactics, Indicators of Compromise(IoC), and vulnerabilities in different platforms from scattered threat sources. This collective information can guide decision making in cyber defense applications utilized by security operation centers(SoCs). In this paper, we introduce an open-source malware ontology - MALOnt that allows the structured extraction of information and knowledge graph generation, especially for threat intelligence. The knowledge graph that uses MALOnt is instantiated from a corpus comprising hundreds of annotated malware threat reports. The knowledge graph enables the analysis, detection, classification, and attribution of cyber threats caused by malware. We also demonstrate the annotation process using MALOnt on exemplar threat intelligence reports. A work in progress, this research is part of a larger effort towards auto-generation of knowledge graphs (KGs)for gathering malware threat intelligence from heterogeneous online resources.
Non-IID Graph Neural Networks
May 22, 2020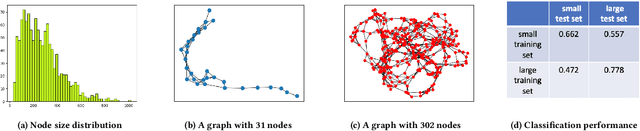
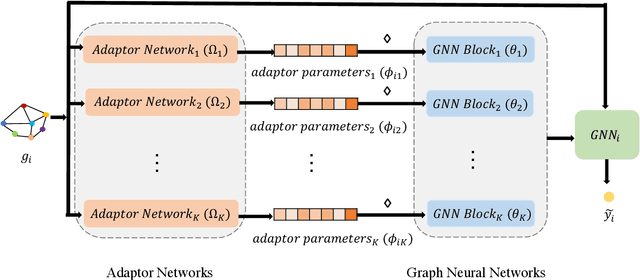

Graph classification is an important task on graph-structured data with many real-world applications. The goal of graph classification task is to train a classifier using a set of training graphs. Recently, Graph Neural Networks (GNNs) have greatly advanced the task of graph classification. When building a GNN model for graph classification, the graphs in the training set are usually assumed to be identically distributed. However, in many real-world applications, graphs in the same dataset could have dramatically different structures, which indicates that these graphs are likely non-identically distributed. Therefore, in this paper, we aim to develop graph neural networks for graphs that are not non-identically distributed. Specifically, we propose a general non-IID graph neural network framework, i.e., Non-IID-GNN. Given a graph, Non-IID-GNN can adapt any existing graph neural network model to generate a sample-specific model for this graph. Comprehensive experiments on various graph classification benchmarks demonstrate the effectiveness of the proposed framework. We will release the code of the proposed framework upon the acceptance of the paper.
Efficient Global String Kernel with Random Features: Beyond Counting Substructures
Nov 25, 2019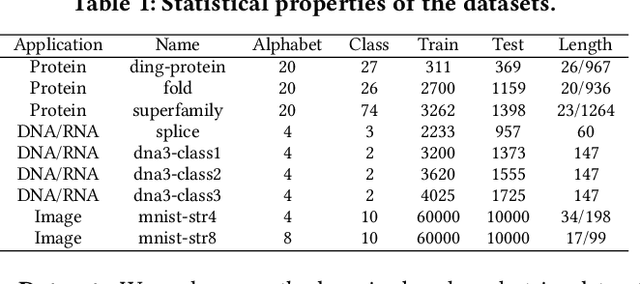
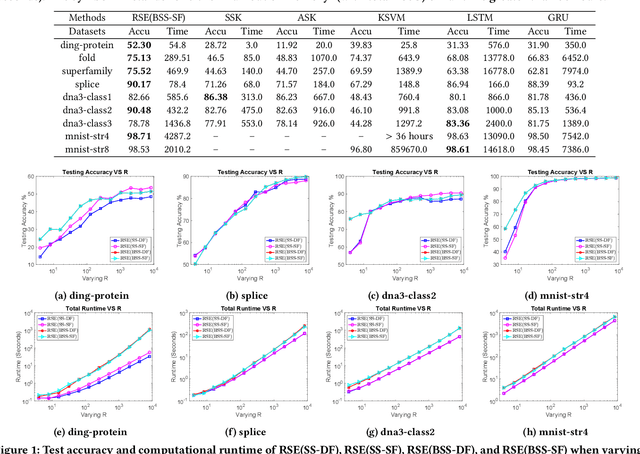
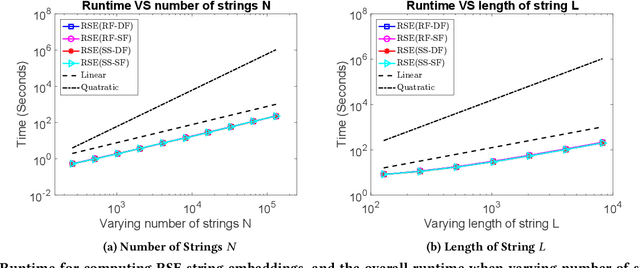
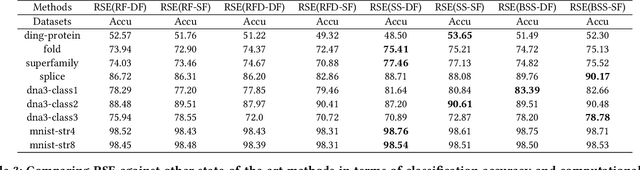
Analysis of large-scale sequential data has been one of the most crucial tasks in areas such as bioinformatics, text, and audio mining. Existing string kernels, however, either (i) rely on local features of short substructures in the string, which hardly capture long discriminative patterns, (ii) sum over too many substructures, such as all possible subsequences, which leads to diagonal dominance of the kernel matrix, or (iii) rely on non-positive-definite similarity measures derived from the edit distance. Furthermore, while there have been works addressing the computational challenge with respect to the length of string, most of them still experience quadratic complexity in terms of the number of training samples when used in a kernel-based classifier. In this paper, we present a new class of global string kernels that aims to (i) discover global properties hidden in the strings through global alignments, (ii) maintain positive-definiteness of the kernel, without introducing a diagonal dominant kernel matrix, and (iii) have a training cost linear with respect to not only the length of the string but also the number of training string samples. To this end, the proposed kernels are explicitly defined through a series of different random feature maps, each corresponding to a distribution of random strings. We show that kernels defined this way are always positive-definite, and exhibit computational benefits as they always produce \emph{Random String Embeddings (RSE)} that can be directly used in any linear classification models. Our extensive experiments on nine benchmark datasets corroborate that RSE achieves better or comparable accuracy in comparison to state-of-the-art baselines, especially with the strings of longer lengths. In addition, we empirically show that RSE scales linearly with the increase of the number and the length of string.
Scalable Global Alignment Graph Kernel Using Random Features: From Node Embedding to Graph Embedding
Nov 25, 2019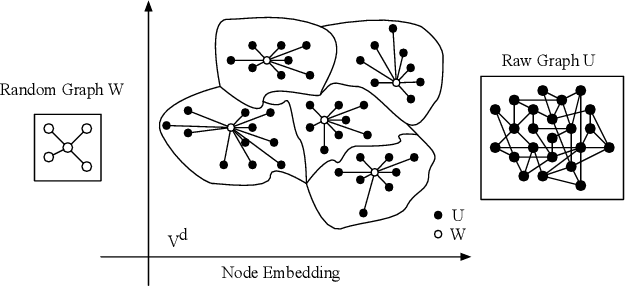
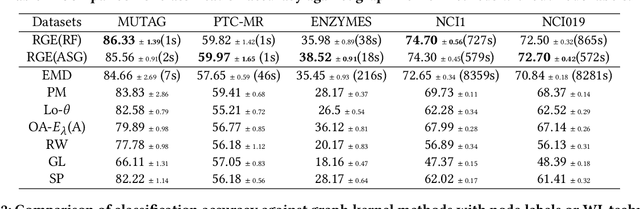
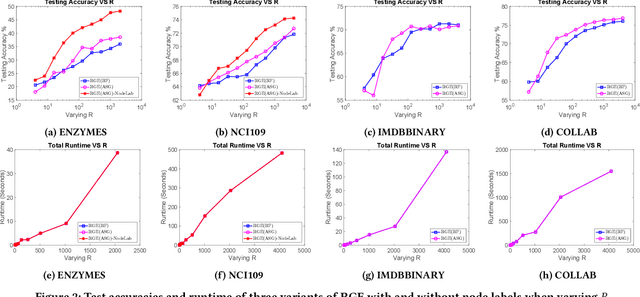
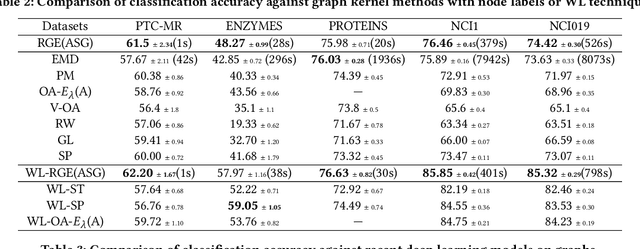
Graph kernels are widely used for measuring the similarity between graphs. Many existing graph kernels, which focus on local patterns within graphs rather than their global properties, suffer from significant structure information loss when representing graphs. Some recent global graph kernels, which utilizes the alignment of geometric node embeddings of graphs, yield state-of-the-art performance. However, these graph kernels are not necessarily positive-definite. More importantly, computing the graph kernel matrix will have at least quadratic {time} complexity in terms of the number and the size of the graphs. In this paper, we propose a new family of global alignment graph kernels, which take into account the global properties of graphs by using geometric node embeddings and an associated node transportation based on earth mover's distance. Compared to existing global kernels, the proposed kernel is positive-definite. Our graph kernel is obtained by defining a distribution over \emph{random graphs}, which can naturally yield random feature approximations. The random feature approximations lead to our graph embeddings, which is named as "random graph embeddings" (RGE). In particular, RGE is shown to achieve \emph{(quasi-)linear scalability} with respect to the number and the size of the graphs. The experimental results on nine benchmark datasets demonstrate that RGE outperforms or matches twelve state-of-the-art graph classification algorithms.
Joint Modeling of Local and Global Temporal Dynamics for Multivariate Time Series Forecasting with Missing Values
Nov 22, 2019
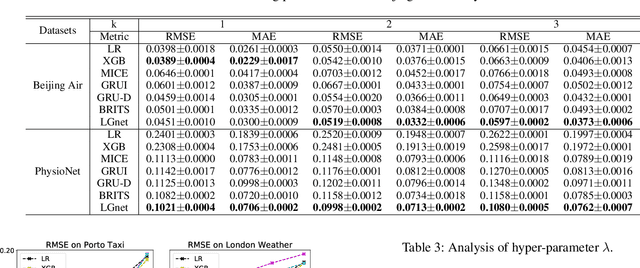
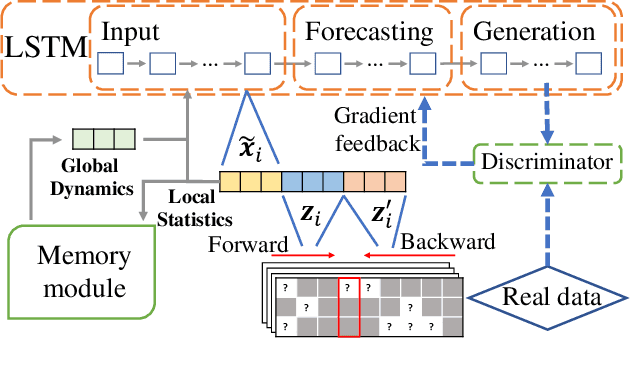
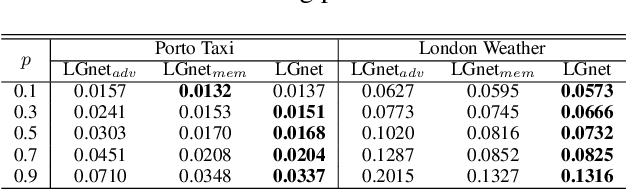
Multivariate time series (MTS) forecasting is widely used in various domains, such as meteorology and traffic. Due to limitations on data collection, transmission, and storage, real-world MTS data usually contains missing values, making it infeasible to apply existing MTS forecasting models such as linear regression and recurrent neural networks. Though many efforts have been devoted to this problem, most of them solely rely on local dependencies for imputing missing values, which ignores global temporal dynamics. Local dependencies/patterns would become less useful when the missing ratio is high, or the data have consecutive missing values; while exploring global patterns can alleviate such problems. Thus, jointly modeling local and global temporal dynamics is very promising for MTS forecasting with missing values. However, work in this direction is rather limited. Therefore, we study a novel problem of MTS forecasting with missing values by jointly exploring local and global temporal dynamics. We propose a new framework LGnet, which leverages memory network to explore global patterns given estimations from local perspectives. We further introduce adversarial training to enhance the modeling of global temporal distribution. Experimental results on real-world datasets show the effectiveness of LGnet for MTS forecasting with missing values and its robustness under various missing ratios.
How can AI Automate End-to-End Data Science?
Oct 22, 2019
Data science is labor-intensive and human experts are scarce but heavily involved in every aspect of it. This makes data science time consuming and restricted to experts with the resulting quality heavily dependent on their experience and skills. To make data science more accessible and scalable, we need its democratization. Automated Data Science (AutoDS) is aimed towards that goal and is emerging as an important research and business topic. We introduce and define the AutoDS challenge, followed by a proposal of a general AutoDS framework that covers existing approaches but also provides guidance for the development of new methods. We categorize and review the existing literature from multiple aspects of the problem setup and employed techniques. Then we provide several views on how AI could succeed in automating end-to-end AutoDS. We hope this survey can serve as insightful guideline for the AutoDS field and provide inspiration for future research.
Scalable Spectral Clustering Using Random Binning Features
Aug 11, 2018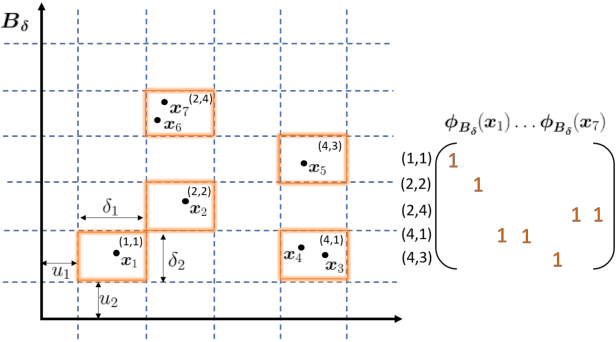
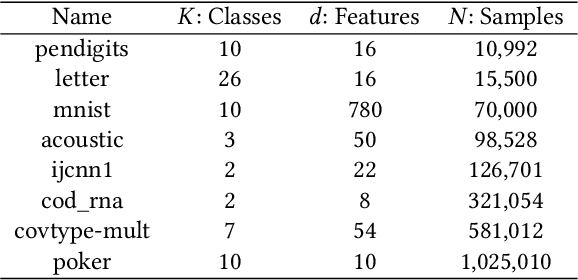
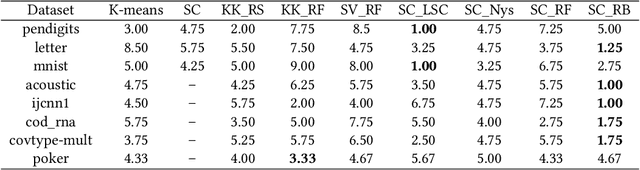
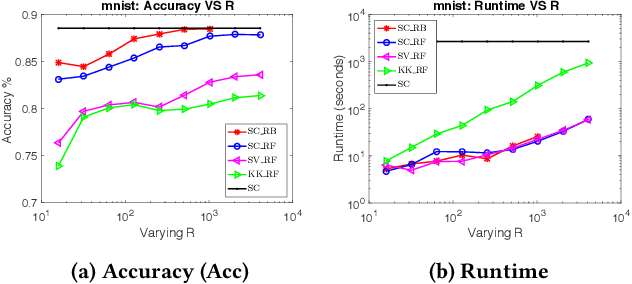
Spectral clustering is one of the most effective clustering approaches that capture hidden cluster structures in the data. However, it does not scale well to large-scale problems due to its quadratic complexity in constructing similarity graphs and computing subsequent eigendecomposition. Although a number of methods have been proposed to accelerate spectral clustering, most of them compromise considerable information loss in the original data for reducing computational bottlenecks. In this paper, we present a novel scalable spectral clustering method using Random Binning features (RB) to simultaneously accelerate both similarity graph construction and the eigendecomposition. Specifically, we implicitly approximate the graph similarity (kernel) matrix by the inner product of a large sparse feature matrix generated by RB. Then we introduce a state-of-the-art SVD solver to effectively compute eigenvectors of this large matrix for spectral clustering. Using these two building blocks, we reduce the computational cost from quadratic to linear in the number of data points while achieving similar accuracy. Our theoretical analysis shows that spectral clustering via RB converges faster to the exact spectral clustering than the standard Random Feature approximation. Extensive experiments on 8 benchmarks show that the proposed method either outperforms or matches the state-of-the-art methods in both accuracy and runtime. Moreover, our method exhibits linear scalability in both the number of data samples and the number of RB features.
REMIX: Automated Exploration for Interactive Outlier Detection
May 17, 2017



Outlier detection is the identification of points in a dataset that do not conform to the norm. Outlier detection is highly sensitive to the choice of the detection algorithm and the feature subspace used by the algorithm. Extracting domain-relevant insights from outliers needs systematic exploration of these choices since diverse outlier sets could lead to complementary insights. This challenge is especially acute in an interactive setting, where the choices must be explored in a time-constrained manner. In this work, we present REMIX, the first system to address the problem of outlier detection in an interactive setting. REMIX uses a novel mixed integer programming (MIP) formulation for automatically selecting and executing a diverse set of outlier detectors within a time limit. This formulation incorporates multiple aspects such as (i) an upper limit on the total execution time of detectors (ii) diversity in the space of algorithms and features, and (iii) meta-learning for evaluating the cost and utility of detectors. REMIX provides two distinct ways for the analyst to consume its results: (i) a partitioning of the detectors explored by REMIX into perspectives through low-rank non-negative matrix factorization; each perspective can be easily visualized as an intuitive heatmap of experiments versus outliers, and (ii) an ensembled set of outliers which combines outlier scores from all detectors. We demonstrate the benefits of REMIX through extensive empirical validation on real-world data.
Joint Intermodal and Intramodal Label Transfers for Extremely Rare or Unseen Classes
Mar 22, 2017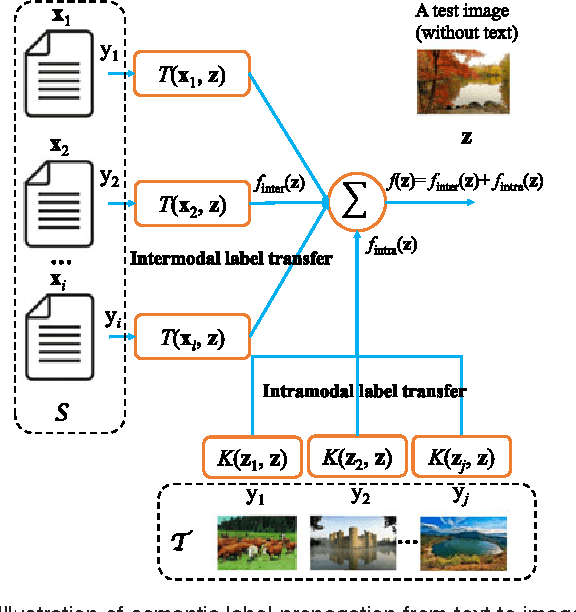
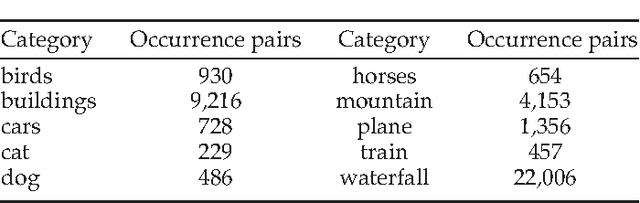
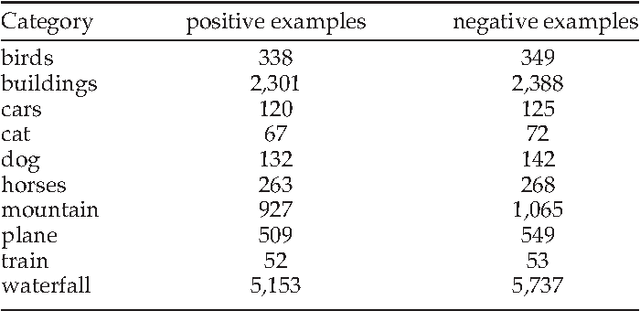
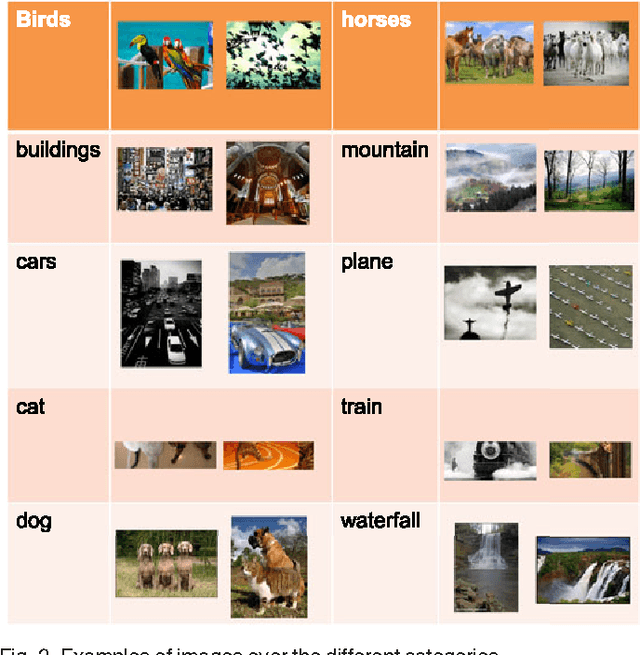
In this paper, we present a label transfer model from texts to images for image classification tasks. The problem of image classification is often much more challenging than text classification. On one hand, labeled text data is more widely available than the labeled images for classification tasks. On the other hand, text data tends to have natural semantic interpretability, and they are often more directly related to class labels. On the contrary, the image features are not directly related to concepts inherent in class labels. One of our goals in this paper is to develop a model for revealing the functional relationships between text and image features as to directly transfer intermodal and intramodal labels to annotate the images. This is implemented by learning a transfer function as a bridge to propagate the labels between two multimodal spaces. However, the intermodal label transfers could be undermined by blindly transferring the labels of noisy texts to annotate images. To mitigate this problem, we present an intramodal label transfer process, which complements the intermodal label transfer by transferring the image labels instead when relevant text is absent from the source corpus. In addition, we generalize the inter-modal label transfer to zero-shot learning scenario where there are only text examples available to label unseen classes of images without any positive image examples. We evaluate our algorithm on an image classification task and show the effectiveness with respect to the other compared algorithms.